本文介紹了多輪對話存在指代和信息省略的問題,同時提出了一種新方法-抽取式多輪對話改寫,可以更加實用的部署於線上對話系統,並且提升對話效果。
1 背景
在日常的交流對話中,30%的對話會包含指代詞。比如「它」用來指代物,「那邊」用來指代地址;同時有50%以上的對話會有信息省略。具體可以看下面的示例。
因此在對話系統中需要結合對話的上下文才可以更好的對用戶輸入的語句做語義理解。
前幾天有一篇論文介紹中文多輪對話的數據集[crosswoz數據集]。文中提出了一種BertContext nlu的方法利用對話歷史向量增強對多輪對話語句的語義理解能力,效果非常好。但是這種方法需要大量的意圖和槽的標註工作。多輪對話的數據標註工作是比較困難的,同時該方法對語句中指代槽的提取也無能爲力,只能根據對話狀態獲取。
對於任務型對話,是可以對用戶狀態進行追蹤。然後根據用戶狀態結合當前用戶的輸入知道用戶的真實目的。目前用戶狀態追蹤用規則做比較穩定。但是這種方法就需要我們去寫很多狀態機做狀態之間的轉移,比較繁瑣。同時指代消岐和信息省略的處理能力也很低。
對於聊天系統,用戶的狀態就更難進行標註。
因此考慮起充分利用上下文來增強對話的語義理解能力就是一個很好的選項。其中一個有前途有實際落地效果的就是對話改寫。
改寫就是根據用戶的聊天內容,把用戶此時此刻說的話補全。輸入是用戶A和系統B的對話歷史,然後對用戶下一句說的話utterance改寫爲label。改寫之後label裏面包含了用戶表達的完整信息。再通過檢索信息或者語義理解引擎就可以更好的執行相應的對話策略。
去年有一篇論文介紹多輪對話改寫[1],使用的方法是基於PointNetwork的生成方法,利用copy機制取得了很好的效果。這篇論文將會成爲本文 的baseline。這裏復現的時候沒有和原論文一樣分割輸入,而是把輸入全部連接做attention。
基於生成的方法有兩個主要缺點。1是速度慢,beamsearch部分解碼套路多[參考文章];2是對訓練數據需求量大。Baseline論文還有一個重要的貢獻是放出了一批一萬多條的改寫數據集,本文的實驗數據也主要基於它。
2 方法
通過分析用戶的對話數據,可以發現大部分的對話數據要麼是正常的不用改寫,要麼就是用了信息省略或者指代詞。因此對話改寫的任務有兩個:1這句話要不要改寫;2 把信息省略和指代識別出來。對於baseline論文放出的數據集,有90%的數據都是簡單改寫,也就是滿足任務2,只有信息省略或者指代詞。少數改寫語句比較複雜,本文訓練集剔除他們,但是驗證集保留。
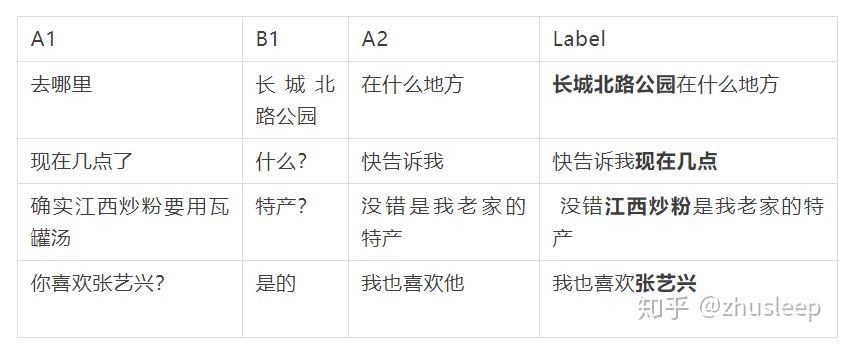
對於用戶和系統的對話歷史,本文用A1/B1來分別表示用戶說的話和系統的回覆。對於用戶說的話A2,本文要將它改寫爲label。
首先需要根據訓練集裏面label對A2做的操作進行有格式的還原。我發現90%的改寫數據都滿足以下兩種模式之一。


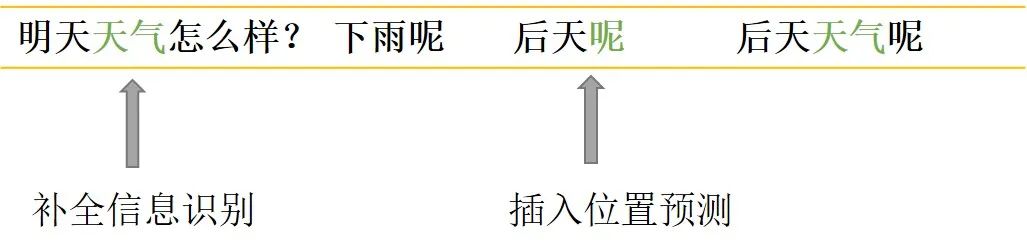
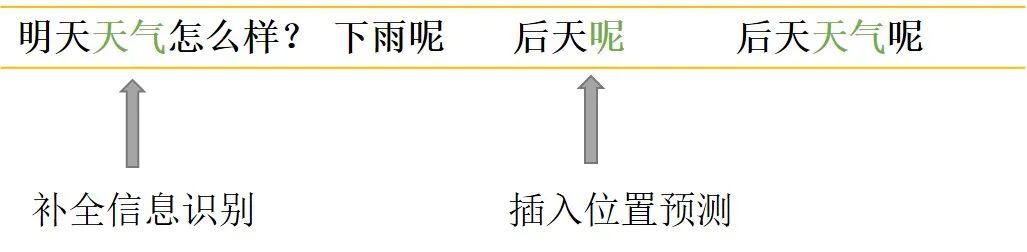
對於指代消岐類,先是識別A2中的指代詞「他」,同時識別出上下文中的關鍵信息「張藝興」,然後替換掉「他「。

對於信息補全類,先是識別出上下文中的關鍵信息「天氣」,然後識別出A2中需要補全信息的位置在"呢"之前。
因此對於文本改寫,我們可以理解爲就是完成上述兩個任務(可以準確覆蓋90%的改寫)。這裏我們(微信公衆號:樸素人工智能)使用了五個指針來做改寫任務的預測。首先把用戶輸入A1和系統回覆B1連接起來,再和用戶輸入A2(待改寫語句)一起作爲模型輸入。中間採用transformers結構進行特徵提取,也可以使用預訓練的transformers比如bert或者rbt3。
Transformers結構可以通過attention機制有效提取指代詞和上下文中關鍵信息的配對,最近也有一篇很好的工作專門用Bert來做指代消岐[2]。經過transformer結構提取文本特徵後,模型結構及輸出如下圖。
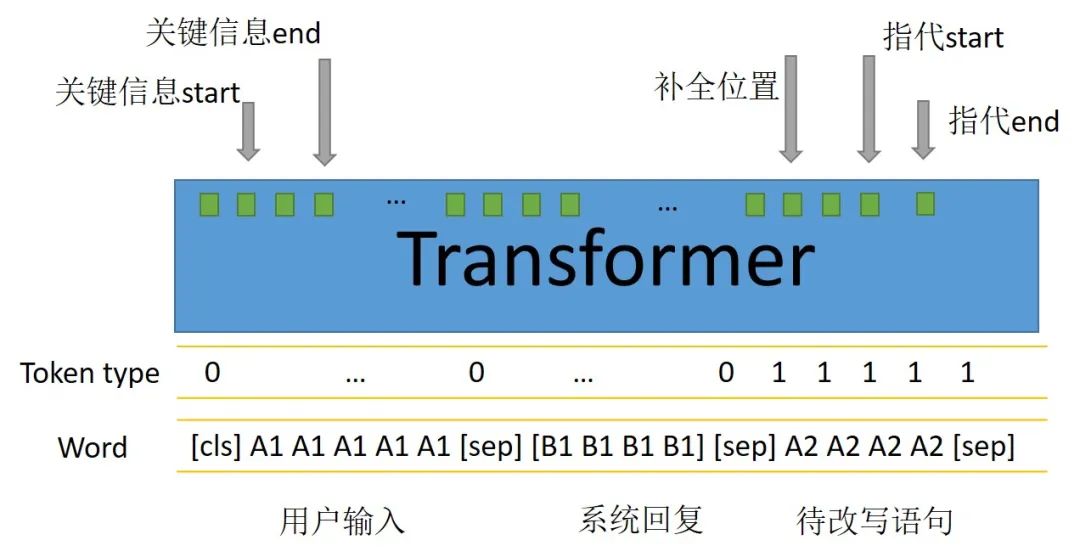
輸出五個指針中:
關鍵信息的start和end專門用來識別需要爲下文做信息補全或者指代的詞;
補全位置用來預測關鍵信息(start-end)插入在待改寫語句的位置,實驗中用插入位置的下一個token來表示;
指代start和end用來識別帶改寫語句出現的指代詞。
當待改寫語句中不存在指代詞或者關鍵信息的補全時,指代的start和end將會指向cls,同理補全位置也這樣。如同閱讀理解任務中不存在答案一樣,這樣的操作在做預測任務時,當指代和補全位置的預測最大概率都位於cls時就可以避免改寫,從而保證了改寫的穩定性。
3 實驗結果與分析
本文對其中github中多輪對話改寫數據中取了15000條做訓練集,剩下2000條做驗證集觀察模型訓練效果。本文和baseline模型用的encoder都是3層transformer的rbt3預訓練模型。
3.1驗證集上效果比較


Baseline基於完全copy機制的生成方法效果也非常好,本文所採用的抽取式效果相當。
備註:
1)Rouge-1
rouge-1 比較生成文本和參考文本之間的重疊詞(字)數量
2) Rouge-2
rouge-2 比較生成文本和參考文本之間的 2-gram 重疊的數量
3) Rouge-L
rouge-l 根據生成文本和參考文本之間的最長公共子序列得出
3.2預測時間消耗(2000條)

在小破卡上,baseline模型需要一個一個解碼,預測速度慢。本文的方法採用指針預測法速度很快,具備大規模上線應用的可能性。
3.3對訓練樣本數的依賴
訓練集樣本數依次選擇15000,5000,1000,500條,觀察文本改寫效果。驗證集同上仍爲2000條。
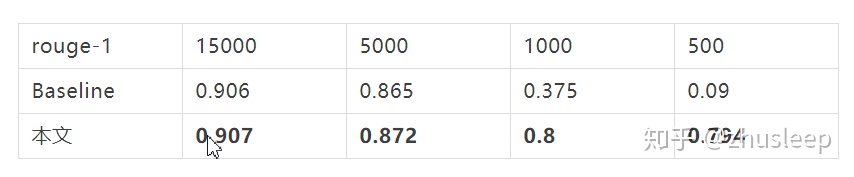
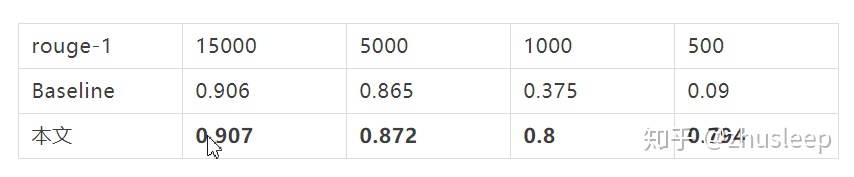
生成式改寫任務對數據依賴比較高,即使baseline模型採用的是完全copy的機制。抽取式文本改寫在小數據集上也可以產生很好的效果。這和基於序列標註的文本生成模型LaserTagger得出的結論是一致的。
3.4對負樣本(不需要改寫樣本)的識別
本文將驗證集的label作爲輸入給模型做改寫,改寫後的結果和原label進行比較。

基於指針抽取的方法對負樣本的識別效果會更好。同時根據對長文本的改寫效果觀察,生成式改寫效果較差。
3.5 改寫效果一覽
(從左到右依次是A1|B1|A2|算法改寫結果|用戶標註label)
你知道板泉井水嗎 | 知道 | 她是歌手 | 板泉井水是歌手 | 板泉井水是歌手
烏龍茶 | 烏龍茶好喝嗎 | 嗯好喝 | 嗯烏龍茶好喝 | 嗯烏龍茶好喝
武林外傳 | 超愛武林外傳的 | 它的導演是誰 | 武林外傳的導演是誰 | 武林外傳的導演是誰
李文雯你愛我嗎 | 李文雯是哪位啊 | 她是我女朋友 | 李文雯是我女朋友 | 李文雯是我女朋友
舒馬赫 | 舒馬赫看球了麼 | 看了 | 舒馬赫看了 | 舒馬赫看球了
4 小結
通過大量實驗,可以得出如下結論。
- 抽取式文本改寫和生成式改寫效果相當
- 抽取式文本改寫速度上絕對優於生成式
- 抽取式文本改寫對訓練數據依賴少
- 抽取式文本改寫對負樣本識別準確率略高於生成式
因此本文設計的方法更加適合線上多輪對話的改寫。後續我們也會開源多種方法實現對話改寫的代碼。
主要參考文章:
[1]Improving Multi-turn Dialogue Modelling with Utterance ReWriter
[2]Coreference Resolution as Query-based Span Prediction
[3] https://github.com/chin-gyou/dialogue-utterance-rewriter

