1 . 引言
近年來,預訓練模型在自然語言處理(Natural Language Processing, NLP)領域大放異彩,其中最重要的工作之一就是Google於2018年發佈的BERT預訓練模型[1]。自被髮布以來,BERT預訓練模型就在多項自然語言理解任務上取得了優異的效果,並開啓了預訓練-微調的NLP範式時代,啓發了NLP領域後續一系列的預訓練模型工作。與此同時,BERT模型在NLP相關工業領域也得到了廣泛應用,並取得了良好的效果。但由於工業領域相關業務的數據格式的複雜性,以及工業應用對推理性能的要求,BERT模型往往不能簡單直接地被應用於NLP業務之中,需要根據具體場景和數據對BERT模型加以調整和改造,以適應業務的現實需求。
小米AI實驗室NLP團隊自創建以來,就積極探索NLP前沿領域,致力於將先進的NLP技術應用於公司的核心業務中,支撐信息流、搜索推薦、語音交互等業務對NLP技術的需求。近期,我們對BERT預訓練模型在各項業務中的應用進行了探索研究工作,使用各項深度學習技術利用和改造強大的BERT預訓練模型,以適應業務的數據形態和性能需求,取得了良好的效果,並應用到了對話理解、語音交互、NLP基礎算法等多個領域。下面,我們將具體介紹BERT在小米NLP業務中的實戰探索,主要分爲三個部分:第一部分是BERT預訓練模型簡介,第二部分是BERT模型實戰探索,第三部分是總結與思考。
2. BERT預訓練模型簡介
BERT預訓練模型的全稱是基於Transformer的雙向編碼表示(Bidirectional Encoder Representations from Transformers, BERT),其主要思想是:採用Transformer網絡[2]作爲模型基本結構,在大規模無監督語料上通過掩蔽語言模型和下句預測兩個預訓練任務進行預訓練(Pre-training),得到預訓練BERT模型。再以預訓練模型爲基礎,在下游相關NLP任務上進行模型微調(Fine-tuning)。BERT預訓練模型能夠充分利用無監督預訓練時學習到的語言先驗知識,在微調時將其遷移到下游NLP任務上,在11項下游自然語言處理任務上取得了優異的效果,開啓了自然語言處理的預訓練新範式。接下來,我們具體介紹BERT模型的模型結構、預訓練方法和微調方法。
2.1 模型結構
BERT 模型的結構主要由三部分構成:輸入層、編碼層和任務相關層,其中輸入層和編碼層是通用的結構,對於每一個任務都適用,因此我們主要介紹這兩個部分。
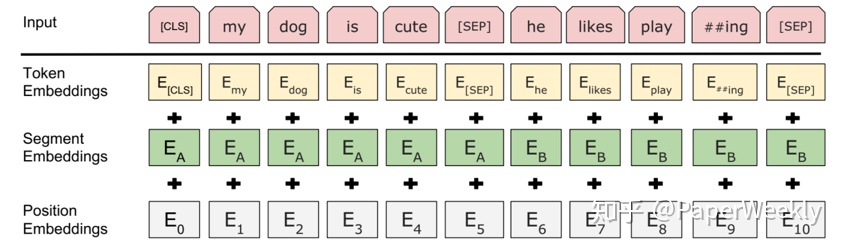
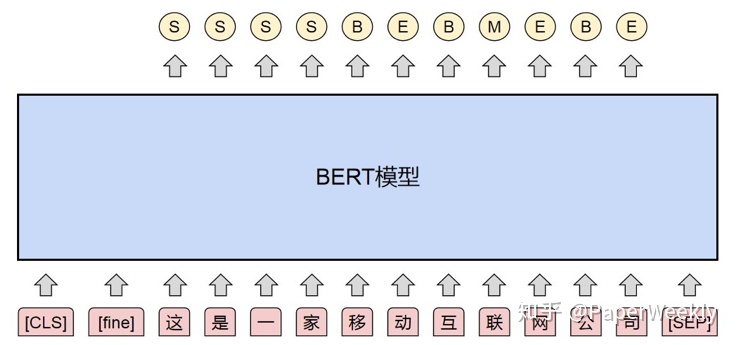
BERT 模型的輸入層包括詞嵌入(token embedding)、位置嵌入(position embedding)段嵌入(segment embedding)。與原始Transformer不同的是, BERT模型的位置嵌入是可學習的參數,最大支持長度爲 512 個位置。同時, BERT模型的段嵌入用於在輸入序列包含兩個句子時區分兩個句子。具體來說, BERT 模型在第一個句子上使用段A嵌入,在第二個句子上使用段B嵌入。另外, BERT模型在輸入序列的第一個位置加上一個特殊的[CLS] 標記用於聚合句子表示信息,並在兩個句子之間使用特殊標記[SEP] 用於分隔兩個句子。 BERT 的輸入層將每個詞的詞嵌入、位置嵌入和段嵌入相加得到每個詞的輸入表示,如圖1所示。
BERT模型的編碼層直接使用了Transformer編碼器[2]來編碼輸入序列的表示,將編碼層的層數記爲L,把隱藏層的維度記爲H,把多頭注意力的頭數記爲A,多頭注意力中的每個頭的子空間維度設爲H/A,前饋神經網絡的中間層維度設爲4H。這樣BERT模型的Transformer編碼層就由L, H, A三個超參數決定。Devlin et al.[1]定義了兩種尺寸的BERT模型:
:L=12, H=768, A=12
:L=24, H=1024, A=16
BERT模型的任務相關層則根據下游任務不同而有所不同,如對於文本分類任務,任務相關層通常爲帶softmax的線性分類器。
2.2 預訓練方法
BERT 模型採用了兩個預訓練任務:一是掩蔽語言模型(Masked Language Model, MLM),二是下句預測(Next Sentence Prediction, NSP)。通過這兩個預訓練任務,BERT模型能夠學習到先驗的語言知識,並在後面遷移給下游任務。BERT模型的預訓練方法如圖2所示。

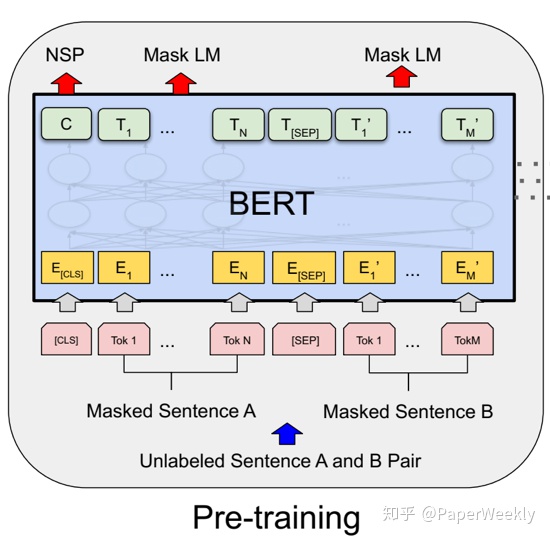
BERT 模型的第一個預訓練任務是掩蔽語言模型。掩蔽語言模型(MLM)的原理是:隨機選取輸入序列中的一定比例(15%)的詞,其中80%的概率用掩蔽標記[MASK]替換,10%的概率隨機替換成其他詞,10%的概率保持不變,然後根據雙向上下文的詞預測這些被掩蔽的詞。預訓練時BERT模型通過最大化被掩蔽詞的概率來預訓練掩蔽語言模型。
BERT 模型的第二個預訓練任務是下句預測。下句預測(NSP)任務的主要目標是:根據輸入的兩個句子 A 和 B,預測出句子 B 是否是句子 A 的下一個句子。下句預測任務使用 BERT 模型編碼後第一個位置([CLS])對應的向量表示,來得到句子 B 是句子 A 下一個句子的概率 。預訓練時,若句子 B 是句子 A 在語料中的下一個句子,BERT模型最大化如上所述的下句概率;否則最小化該下句概率。
BERT模型預訓練的目標函數,是兩個預訓練任務的似然概率之和。
2.3 微調方法
經過預訓練的 BERT 模型可以用於下游的自然語言處理任務。在使用時,主要是在預訓練 BERT 模型的基礎上加入任務相關部分,再在特定任務上進行微調(fine-tuning), BERT 模型在幾個下游自然語言處理任務上的微調方法如圖3所示。

通常,我們取出 BERT 模型最後一層的向量表示,送入任務相關層中(通常是簡單的線性變換層),就可以得到任務所要建模的目標概率。例如,在文本分類任務中,我們取出最後一層[CLS] 標記對應的向量表示,再進行線性變換和 softmax 歸一化就可以得到分類概率。在微調時, BERT 模型和任務相關層的所有參數都一起更新,最優化當前下游任務的損失函數。
基於預訓練-微調範式的 BERT 模型具有許多優點。通過在大規模無監督語料上的預訓練, BERT 模型可以引入豐富的先驗語義知識,爲下游任務提供更好的初始化,減輕在下游任務上的過擬合,並降低下游任務對大規模數據的依賴。同時, BERT 模型使用的深層 Transformer 編碼層具有很強的表徵能力,因此下游任務不需要太複雜的任務相關層,這簡化了下游任務的模型設計,爲各項不同的自然語言處理任務提供一個統一的框架。
3. BERT模型實戰探索
在BERT模型的實際應用中,往往需要根據具體業務形態對BERT模型進行調整。原始的BERT模型只能對文本序列進行建模,缺乏對其他特徵的建模能力;同時BERT模型的參數過多,推理速度較慢,不能滿足業務上線性能需求;另外,BERT模型需要針對每個細分任務都各自進行微調,缺乏通用性,也不能很好地利用任務之間的共享信息。在實踐過程中,我們使用了特徵融合、注意力機制、集成學習、知識蒸餾、多任務學習等多種深度學習技術對BERT模型進行增強或改造,將BERT模型應用到了多項具體任務之中,取得了良好的業務效果。下面,我們主要介紹BERT模型在對話系統意圖識別、語音交互Query判不停、小米NLP平臺多粒度分詞這三項業務中的實戰探索。
3.1 對話系統意圖識別
意圖識別是任務型對話系統的重要組成部分,對於用戶對話的自然語言理解起着非常重要的作用。給定一個用戶Query,意圖識別模塊能夠將用戶所要表達的意圖識別出來,從而爲後續的對話反饋提供重要的意圖標籤信息。但在意圖識別的過程中,由於實體槽位知識稀疏性的問題,完全基於用戶Query文本的意圖識別模型很難進一步提升效果。在對Query文本進行建模時,如果能夠融合槽位知識特徵,模型的意圖識別效果可能會得到進一步提升。因此,我們構建的意圖識別模塊的輸入是用戶Query文本和槽位標籤,輸出是意圖類別,如下面的例子所示。
- Query文本/槽位標籤:播 放 張/b-music_artist/b-mobileVideo_artist 傑/i-music_artist/i-mobileVideo_artist 的 歌
- 意圖類別:music
不同於一般的意圖識別只有Query文本特徵,我們的融合槽位特徵的意圖識別模型輸入還包括槽位標籤特徵,而且每一個位置還可能包括不止一個槽位標籤。在嘗試將BERT模型應用於意圖識別任務時,如何將槽位標籤特徵合適地與BERT模型結合起來就成爲一個需要解決的重要問題。由於BERT預訓練模型在預訓練時並沒有輸入槽位信息,如果直接將槽位標籤特徵直接放入BERT模型的輸入中,將會擾亂BERT預訓練模型的輸入,使得預訓練模型過程失去意義。因此,我們需要考慮更合理的方式融合槽位標籤特徵。經過探索和實驗,最終我們採取了槽位注意力和融合門控機制的方法來融合槽位特徵,融合了槽位特徵的意圖識別模型結構如圖4所示。
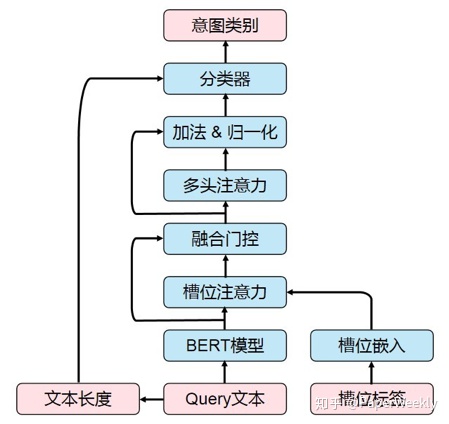
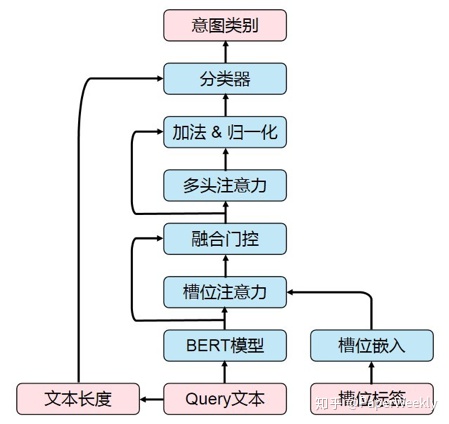
首先,我們使用預訓練BERT模型編碼Query文本,得到融合了預訓練先驗知識的文本向量Q。
接着,我們將槽位標籤進行嵌入,得到槽位嵌入ES。由於每個位置可能有多個槽位標籤,我們需要對槽位嵌入進行池化操作,這裏我們採用了槽位注意力機制對多個槽位嵌入進行加權求和。我們採用了縮放點積注意力(Scaled Dot-Product Attention)[2]作爲我們的槽位注意力機制,同時,在應用點積注意力機制之前,我們先對文本向量和槽位嵌入進行線性變換,將其映射到同一個維度的子空間。經過槽位注意力之後,多個槽位嵌入被加權平均爲一個槽位向量S。

然後,我們使用融合門控機制對文本向量Q和槽位向量S進行融合,得到融合後的向量F。這裏的融合門控機制類似長短期記憶網絡(Long Short-Term Memory, LSTM)中的門控機制。
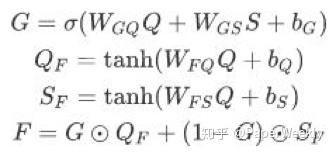
融合後的向量F表示每個位置的文本信息和槽位信息,但是由於融合門控機制是在每個位置上進行的,因此,單個位置上的融合向量缺乏其他位置的槽位上下文信息。爲了對上下文信息進行編碼,我們又使用了一個帶殘差連接和層歸一化的多頭注意力機制(Multi-Head Attention)[2]編碼融合向量F,得到最終的輸出向量O。
最後,我們取出第一個位置([CLS]標記對應位置)的輸出向量,拼接上文本長度特徵,送入帶softmax的線性分類器中,得到每個意圖類別上的概率,進而預測出Query對應的意圖類別標籤。
在業務數據上的微調實驗表明,融合了槽位特徵的BERT意圖識別模型比只使用文本信息的BERT模型能夠實現更好的效果。
3.2 語音交互Query判不停
用戶在語音輸入過程中會有停頓、語句不完整的現象,經過ASR識別後,得到的query文本存在不完整的情況,會影響到後續的意圖識別和槽位提取。因此在送入中臺之前,需要經過判不停模塊識別,對於不完整query返回給ASR繼續接收輸入,完整query才進入中臺。我們提出的語音交互query判不停模塊,就是用於判斷用戶query是否完整的重要模塊。判不停模塊輸入用戶query文本,輸出一個判不停標籤,表明該query是否完整,其中'incomplete'表示query不完整,'normal'表示query完整,如下例所示。
- Query文本:播放張傑的
- 判不停標籤:incomplete
判不停模型的主要難點在於線上用戶query請求量大,對模型推理速度有比較嚴格的限制,因此普通的BERT模型無法滿足判不停業務的線上性能需求。但是,能夠滿足性能需求的小模型由於結構過於簡單,模型的準確度往往不如BERT模型。因此,我們經過思考,採取了「集成學習+知識蒸餾」的判不停系統框架,先通過集成學習,集成BERT等業務效果好的模型,實現較高的準確度。再使用知識蒸餾的方法,將集成模型的知識遷移給Albert Tiny小模型[3],從而在保證推理速度的基礎上,大幅提升模型效果。「集成學習+知識蒸餾」的判不停框架如圖5所示。
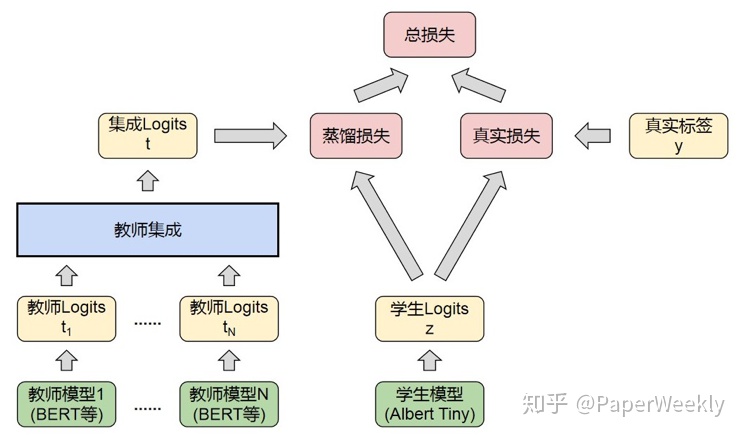
判不停框架的第一步是集成學習。目的是通過融合多個模型,減緩過擬合的問題,提升集成模型的效果。首先,我們在判不停業務數據集上訓練BERT模型等多個效果好的大模型,這些效果好的大模型稱之爲教師模型。接着,對於每個教師模型,我們都使用它預測出每條數據對應的logits,logits本質上是softmax之前的2維向量,代表了教師模型在數據上的知識。最後,對於每條數據,我們對多個教師模型預測的logits進行集成,得到的集成logits就對應了一個集多個教師模型優點於一身的集成模型,這樣的集成模型具有比單個BERT教師模型更好的效果。
判不停框架的第二步是知識蒸餾。由於推理性能限制,集成模型無法直接應用於線上判不停業務。因此我們使用知識蒸餾[4]的方法,把集成模型的知識遷移給能滿足線上性能需求的小模型Albert Tiny模型,這樣的小模型也被稱爲學生模型。蒸餾學生模型時,我們同時使用集成logits和真實標籤訓練學生模型,使得學生模型能夠學到集成模型的知識,進一步提升學生模型的效果。具體來說,對於第i條訓練數據,我們先使用Albert Tiny模型預測出該條數據對應的學生logits,記爲z。另外,該條數據對應的集成模型logits記爲t,對應的真實標籤記爲y。我們使用真實標籤y和學生logits z得到通常的交叉熵損失函數,同時,我們使用集成logits t和學生logits z得到帶溫度平滑的蒸餾交叉熵損失函數,最終的損失函數是兩種損失函數的加權求和。
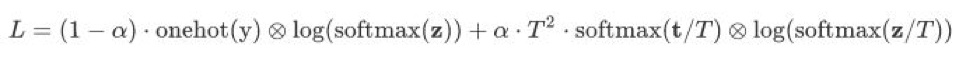

最終,經過「集成學習+知識蒸餾」的判不停框架得到的Albert Tiny小模型能夠達到BERT單模型的效果,同時也能很好地滿足線上的推理性能需求。
3.3 小米NLP平臺多粒度分詞
中文分詞已經成爲了衆多NLP任務的基礎需求,爲下游任務提供基礎分詞服務。小米NLP平臺(MiNLP平臺)也開發了中文分詞功能,爲公司內其他NLP相關業務提供中文分詞服務支撐。在實踐中我們發現,不同業務對中文分詞的粒度需求有所差異,短文本相關業務往往需要粒度較細的分詞服務,而長文本相關業務則希望分詞的粒度能夠更粗一些。針對不同業務對不同粒度分詞的需求,我們開發了多粒度分詞算法,能夠支持粗/細兩種粒度的中文分詞服務。多粒度分詞的示例如下:
- 文本:這是一家移動互聯網公司
- 粗粒度分詞:這/是/一家/移動互聯網/公司
- 細粒度分詞:這/是/一/家/移動/互聯網/公司
我們在開發基於BERT模型的多粒度分詞算法時,發現如果分別在每個粒度分詞的數據集上進行微調,則需要訓練並部署多個不同粒度的BERT分詞模型,總的模型資源消耗量與粒度的數量成線性相關。同時,不同粒度的分詞結果雖然有一些差異,但依然有着很大的共性,各自訓練不同粒度的BERT分詞模型不能充分利用這些共性知識來提升分詞效果。爲了充分利用不同粒度分詞的共性信息,並減少訓練和部署成本,我們基於多任務學習的思路,提出了一種「基於BERT的統一多粒度分詞模型"[5],用一個統一的BERT模型訓練了支持多個粒度的中文分詞器。
我們提出的統一多粒度分詞模型如圖6所示,其主要思想是:先在輸入文本中加入一個特殊的粒度標記表示粒度信息,如[fine]表示細粒度,[coarse]表示粗粒度。然後把加入了粒度標記的文本字符送入BERT模型中,再經過一個帶softmax的線性分類器,把每個位置的表示映射爲BMES四個分詞標籤上的概率。四個分詞標籤的含義分別是:B-詞的開始,M-詞的中間,E-詞的結束,S-單獨成詞。如上面的文本得到的細粒度分詞標籤序列就是:
- 細粒度分詞標籤:這/S 是/S 一/S 家/S 移/B 動/E 互/B 聯/M 網/E 公/B 司/E
最後對整個文本序列的分詞標籤進行解碼就得到了最終的分詞結果。
我們提出的統一多粒度分詞模型,不僅在公司內部的多粒度分詞數據上取得了更好的效果,同時也在公開多標準分詞數據集上取得了SOTA(State-of-the-Art)的性能,實驗結果可以參見參考文獻[5]。
4 總結與思考
小米AI實驗室NLP團隊通過BERT模型在具體業務中的實戰探索,使用特徵融合、集成學習、知識蒸餾、多任務學習等深度學習技術,改造和增強了BERT預訓練模型,並在對話系統意圖識別、語音交互Query判不停、小米NLP平臺多粒度分詞等多個任務上取得了良好的效果。
同時,我們對如何進一步應用BERT模型提出一些簡單的想法,留待於未來的探索和研究。首先,如何將非文本特徵尤其是外部知識特徵更有效地融入BERT模型之中,是一個值得深入研究的問題。另外,有些具體業務對線上推理性能有着嚴格的要求,這種場景下BERT模型往往不能直接進行應用,我們需要進一步探究大模型到小模型的知識遷移或模型壓縮,在保證推理性能的基礎之上提升模型效果。最後,公司內部的各項業務往往各自爲戰,在使用BERT模型時存在一些重複工作,並且不能很好地利用多個任務的共性信息,在多任務學習的基礎上,打造一個各業務充分共享的BERT模型平臺,服務並助益多項業務需求,是我們下一步需要努力的方向。
5. 參考文獻
[1] Devlin. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL. 2019.
[2] Vaswani. Attention is all you need. NIPS. 2017.
[3] Lan. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. ICLR. 2020.
[4] Hinton. Distilling the Knowledge in a Neural Network. NIPS. 2014.
[5] Ke. Unified Multi-Criteria Chinese Word Segmentation with BERT. 2020.
#投 稿 通 道#
如何才能讓更多的優質內容以更短路徑到達讀者羣體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成爲一座橋樑,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
來稿標準:
• 稿件確係個人原創作品,來稿需註明作者個人信息(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已發佈鏈接
• PaperWeekly 默認每篇文章都是首發,均會添加「原創」標誌
投稿方式:
• 方法一:在PaperWeekly知乎專欄頁面點擊「投稿」,即可遞交文章
• 方法二:發送郵件至:hr@paperweekly.site ,所有文章配圖,請單獨在附件中發送
• 請留下即時聯繫方式(微信或手機),以便我們在編輯發佈時和作者溝通
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智能前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公衆號後臺點擊「交流羣」,小助手將把你帶入 PaperWeekly 的交流羣裏。
加入社區:http://paperweek.ly
微信公衆號:PaperWeekly
新浪微博:@PaperWeekly