現在,GAN不僅能畫出二次元妹子,還能精準調節五官、表情、姿勢和繪畫風格。

而且在調控某個因素的時候,其他條件能儘量保持不變。
這就是香港中文大學周博磊團隊提出的SeFa(語義分解,Semantics Factorization),該論文最近入選了CVPR 2021(Oral)。
SeFa適用於PGGAN、StyleGAN、BigGAN和StyleGAN2等常見GAN模型,不僅對二次元妹子有效,甚至還能調控貓咪上下左右不同方向。

通過這種方法分離出映射矩陣的各個本徵值,即可實現對不同圖像元素的精準調控

更重要的是,SeFa無需對GAN生成的數據進行標註,它能自己找到這些元素變化對應的編碼。也就說SeFa是一種無監督方法。
目前,SeFa相關代碼已經開源。
周博磊教授團隊的這一成果還得到了母校CSAIL實驗室的轉發。

無監督方法調節GAN
這些年,GAN在圖像合成上取得了巨大的成功。如果想要更好的操控GAN,就需要正確識別其中語義。
但是,由於潛在空間的高維性以及圖像語義的多樣性,在潛在空間中尋找有效的語義非常具有挑戰性。
現有一些基於監督學習的方法,通常首先對大量的潛在編碼進行隨機採樣,然後合成大量圖像,並使用一些預定義的標籤對其進行註釋,最後使用這些標記樣本來學習潛在空間中的分離邊界。
這種對大量GAN生成圖片進行標註的方法,耗時耗力。
因此,作者沒有直接利用合成樣本作爲中間步驟,而是直接研究了GAN的生成機制以解釋其內部表示。

更具體地說,對於所有基於神經網絡的GAN架構,都是將全連接層用作將輸入潛在編碼帶入生成器的第一步。
這種變換實際上會濾除潛在空間中一些可忽略的因素,突顯對於圖像合成關鍵的因素。如果我們能夠識別出這些重要的潛在方向,就可以控制圖像生成過程。
SeFa對圖像的操作,可以看做是將d維潛在空間中的對應向量z沿着n的方向進行移動。
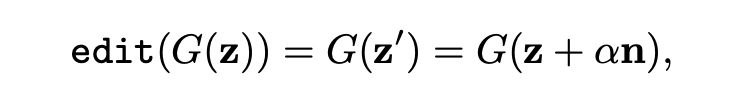
而GAN還會將z映射到另一個m維空間的y。
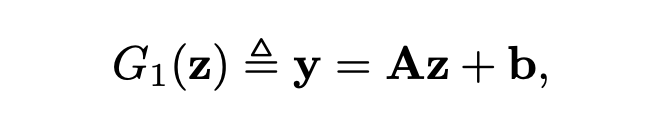
最終,作者將這一問題轉化爲:
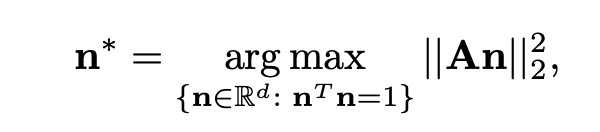
與其他方法對比
與現有的監督和無監督方法相比,SeFa方法能夠更準確,更廣泛地識別可解釋的維度。而且該方法靈活通用,可適用於不同的GAN。
在下圖中,SeFa(b)和無監督的GANSpace(a)、有監督的InterFaceGAN進行了定性對比。SeFa已經接近於有監督方法的效果。
和InfoGAN(a)對比發現,SeFa(b)對不同語義因素的分解程度更高,因爲前者在變換人臉姿勢時,髮色發生了明顯的變化。
SeFa不僅能處理GAN製造的圖片,對真實照片也有效。利用之前周博磊團隊提出的GAN反演方法,將真實照片反向投影到潛在空間,就能改變真實照片。
作者簡介
這篇論文的第一作者是香港中文大學多媒體實驗室的在讀博士生Shen Yujun,本科畢業於清華大學。
他的研究方向是計算機視覺、深度學習、生成模型、網絡解釋、可解釋人工智能(XAI)。
今年他已有3篇論文被CVPR 2021接收,其中兩篇爲Oral。之前他還在CVPR 2020上發表了2篇論文,在CVPR 2018上發表了1篇論文,總計發表了6篇CVPR。
論文的通訊作者是香港中文大學助理教授周博磊。

周博磊是MIT CSAIL實驗室博士,他的研究涉及計算機視覺和機器學習,尤其是視覺場景理解和可解釋AI系統。
論文地址: https://arxiv.org/abs/2007.06600
代碼地址: https://github.com/genforce/sefa
Colab地址: https://colab.research.google.com/github/genforce/sefa/blob/master/docs/SeFa.ipynb
—完—
@量子位 · 追蹤AI技術和產品新動態
深有感觸的朋友,歡迎贊同、關注、分享三連վ'ᴗ' ի ❤