過去幾年,大語言模型的能力提升主要依賴引數和資料規模的擴張。但當模型逐步被用於研究助理、網頁搜尋和複雜決策支援等真實任務時,這條路徑開始顯露邊界。
這類場景往往要求模型在開放環境中進行多輪搜尋與推理,使搜尋增強推理成為主流正規化,同時也暴露出一個核心問題:模型在長鏈搜尋推理中的失敗,往往不是因為推理能力不足,而是無法有效處理錯誤在推理過程中的出現與傳播。
在現實任務中,搜索結果不可避免地包含噪聲,一旦早期某次檢索或資訊採信出現偏差,後續推理就可能在錯誤語義空間中不斷自洽,最終生成看似合理卻偏離問題的答案。然而,現有訓練方法通常只依據最終答案是否正確進行優化,使「偶然成功」的軌跡與「搜尋路徑可靠」的軌跡獲得相同反饋,長期來看反而削弱了模型對中途錯誤和搜尋質量的約束。這也是多輪搜尋、多跳推理任務中效能崩潰呈現系統性特徵的重要原因。
在這一背景下,MBZUAI 、港中文和騰訊混元組成的聯合團隊提出了《Search-R2: Enhancing Search-Integrated Reasoning via Actor-Refiner Collaboration》。
這項工作直指搜尋增強推理中的長鏈推理信用分配與中途糾錯缺失,通過將推理生成、軌跡判斷和錯誤定位納入統一的強化學習框架,使訓練訊號能夠回傳至錯誤首次發生的位置,從而抑制錯誤傳播。
在智慧體系統逐漸從「展示能力」走向「承擔任務」的當下,這項研究的意義不在於提出一種更復雜的工程技巧,而在於為搜尋型智慧體提供了一種更接近真實失敗模式的學習正規化:不是假設推理過程天然可靠,而是承認錯誤不可避免,並讓模型在訓練中學會與錯誤共處、定位並修正它們。

論文地址:https://arxiv.org/pdf/2602.03647
完整閉環,而不是單一技巧
在實驗結果方面,研究團隊發現該方法的優勢並不僅體現在整體平均效能的提升上,而是在任務難度最高、錯誤最容易累積的場景中表現得尤為突出。
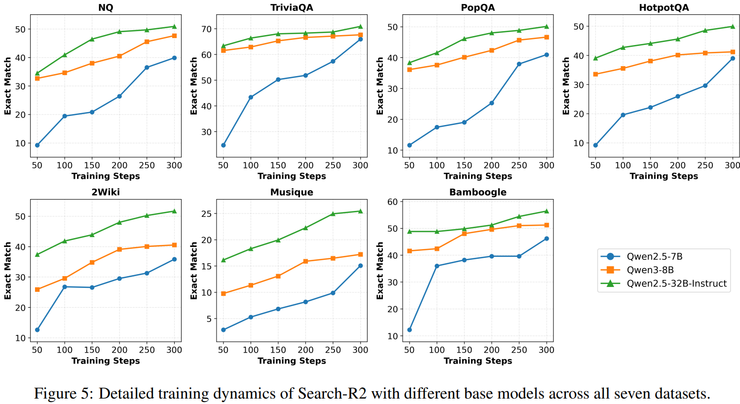
實驗評測覆蓋了普通事實型問答任務和多跳推理問答任務兩大類,其中前者通常只需要一到兩次檢索即可完成,而後者必須經歷多輪「搜尋—推理—再搜尋」,中間任何一步出現偏差都會在後續推理中被不斷放大。
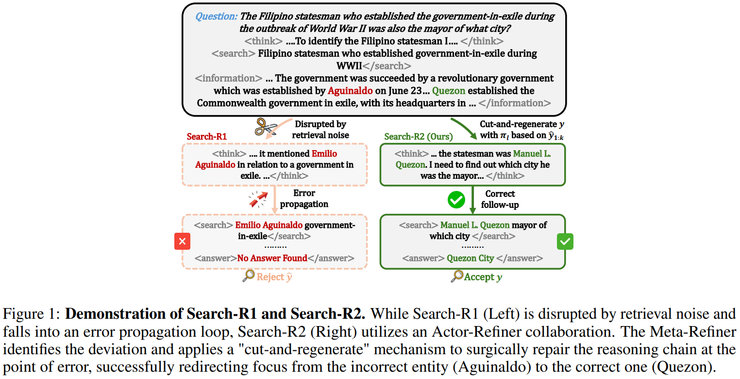
實驗結果表明,該方法在兩類任務上均取得穩定提升,但在多跳推理任務上的提升幅度明顯更大,尤其是在 HotpotQA、2WikiMultiHopQA 和 Bamboogle 等需要多輪檢索協同推理的資料集上,相較基線方法帶來了數個百分點到十餘個百分點不等的準確率提升,其中在 Bamboogle 資料集上的相對提升幅度超過二十個百分點。
這一現象表明,其優勢並非來源於更強的引數記憶能力,而是源於對長鏈推理過程中錯誤傳播的有效抑制。研究人員指出,多跳推理任務的失敗往往並不是由於模型無法生成最終答案,而是由於中途某一次搜尋引入了錯誤或無關資訊,使推理方向發生偏移,之後即便繼續搜尋和推理,也只能在錯誤語義空間中反覆迭代,這個方法正是針對這一失敗模式進行設計,因此在此類任務中的優勢被顯著放大。
在與拒絕取樣策略的對比實驗中,研究團隊進一步提高了基線方法的取樣預算,將每個問題的取樣次數提升至原來的兩倍甚至更多,但實驗結果顯示,即便在這種條件下,基線方法的整體效能仍然低於該方法在較小取樣預算下所取得的結果。
這一對比表明,該方法的效能提升並非來自「多試幾次總能蒙對」的概率收益,其關鍵不在於整體軌跡質量分佈的上限,而在於是否能夠準確識別錯誤首次出現的位置並進行鍼對性處理。拒絕取樣在生成失敗後會直接丟棄整條推理軌跡並重新生成,而該方法則認為失敗軌跡的前半部分往往仍然是正確且有價值的,真正導致失敗的通常是某一次具體的搜尋步驟,這次搜尋所引入的噪聲會在後續推理中持續放大,從而使兩種策略在長鏈推理任務中的樣本效率產生數量級差異。
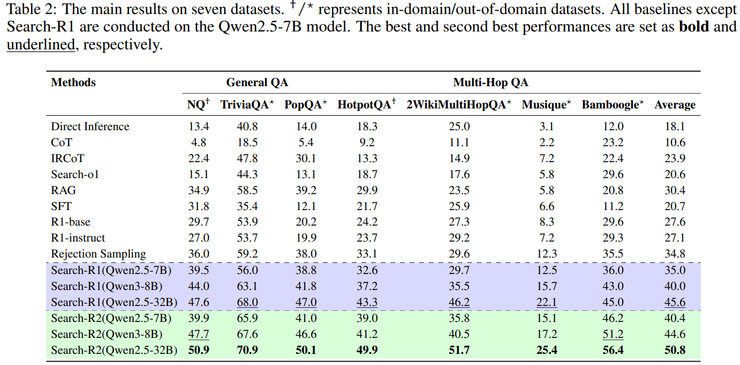
為進一步分析效能提升的來源,研究團隊通過消融實驗系統性地評估了各個組成模組的作用。實驗結果顯示,在僅引入中途糾錯機制而不加入過程獎勵的情況下,模型在多個數據集上的效能已經出現顯著提升,表明對推理過程中關鍵錯誤進行定位和修復本身就能解決搜尋增強推理中的核心瓶頸。雷峰網
在此基礎上,加入用於衡量搜索結果資訊密度的過程獎勵後,模型效能進一步提升,說明顯式區分高質量搜尋與低質量搜尋能夠為訓練過程提供更加穩定的優化方向。
最終,在對推理生成模組與糾錯模組進行聯合優化的完整設定下,模型在所有評測資料集上均取得最優結果,這表明糾錯能力並非靜態規則,而是一種需要在訓練過程中被逐步學習和內化的行為策略。
整體來看,該方法的效能提升並非來源於單一技巧或額外計算量的堆疊,而是由中途糾錯、搜尋質量建模和聯合優化共同構成的完整機制所帶來的結果。
把糾錯本身納入策略空間
在實驗方法設計方面,研究團隊首先指出,僅依賴最終答案是否正確作為強化學習的獎勵訊號,在搜尋增強推理任務中會系統性失效。
研究人員分析認為,在此類任務中,模型實際上需要連續做出多尺度決策,包括是否發起搜尋、搜尋的具體內容、搜尋發生的時機,以及在獲得檢索結果後是否應當信任並使用這些資訊。
然而傳統強化學習只提供「最終答對或答錯」的單一反饋訊號,無法區分這些中間決策的質量差異,從而導致依靠運氣在最後階段拼湊出正確答案的推理軌跡,與邏輯結構嚴密、搜尋路徑合理的軌跡獲得完全相同的獎勵。
長期訓練後,模型會逐漸學到搜尋行為可以隨意展開、早期錯誤不會受到實質性懲罰,只要最終答案能夠生成即可,這正是現有搜尋增強方法在長鏈推理任務中容易發生效能崩潰的根本原因。
基於這一問題,研究團隊在方法中對不同功能進行了明確分工。其中,推理生成模組負責像常規搜尋增強方法一樣,完整生成一條包含推理與搜尋行為的軌跡,該模組被允許在生成過程中犯錯甚至進行探索,不承擔中途自檢或修復的職責。
隨後,引入的糾錯模組首先對整條推理軌跡進行判斷,其關注重點並非最終答案是否正確,而是推理過程是否仍然圍繞原始問題展開,是否出現明顯的實體偏移、主題漂移或證據錯位等現象。這一判斷決定了軌跡是否值得繼續修復,若標準過於寬鬆,錯誤軌跡會被放過,若過於嚴格,則高質量軌跡會被反覆打斷,因此這一接受與拒絕之間的平衡並非人工設定,而是通過強化學習過程自動習得。
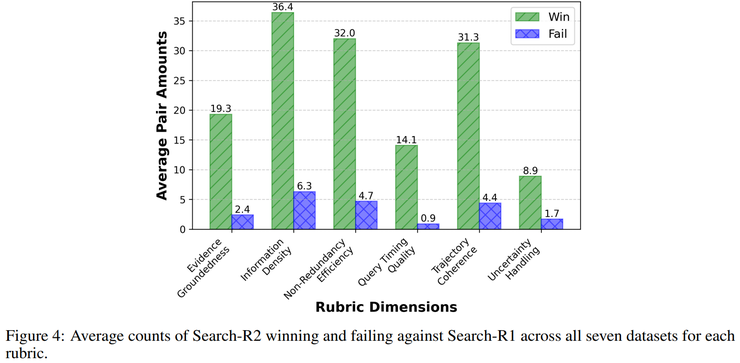
當軌跡被判定為需要修復時,系統進一步定位推理過程中第一次發生實質性偏離的位置,即具體是哪一次搜尋或推理操作將系統帶離了正確的推理空間。雷峰網(公眾號:雷峰網)
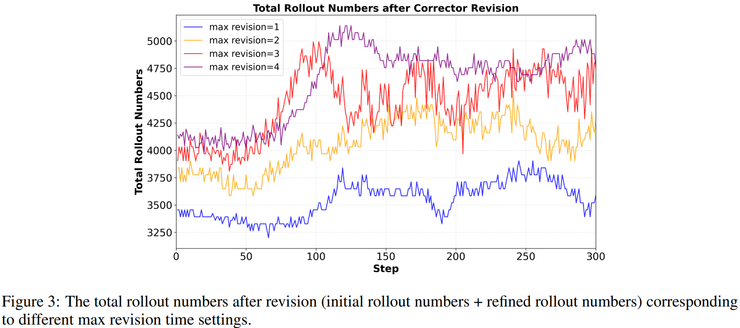
一旦該位置被識別,系統會完整保留此前已經生成的推理字首,丟棄其後的內容,並從該點重新生成後續推理,從而避免浪費已有的正確推理資訊,同時使獎勵訊號能夠精確回傳至錯誤發生的位置,促使模型逐漸學會哪些搜尋錯誤最具破壞性並應當被避免。研究人員在理論分析中將這一錯誤定位能力形式化為修剪能力,並證明其是整體效能提升的必要條件。
為防止模型出現「只修正結果而忽視錯誤根源」的投機行為,研究團隊在訓練過程中進一步引入了過程層面的獎勵訊號,用於衡量檢索到的證據中有多少是真正支援最終答案的資訊而非噪聲內容,並明確規定該過程獎勵僅在最終答案正確的前提下才會生效,從而保證搜尋質量成為達成正確答案的必要條件,但不足以單獨驅動優化目標。
最後,推理生成模組、軌跡判斷模組和錯誤定位模組並非相互獨立,而是共享同一套引數,並在同一強化學習目標下進行聯合優化,將是否觸發糾錯以及在何處糾錯都視為策略決策的一部分,使模型在訓練完成後,即便不顯式觸發多次修復,其初始生成的推理軌跡質量本身也能夠得到顯著提升。
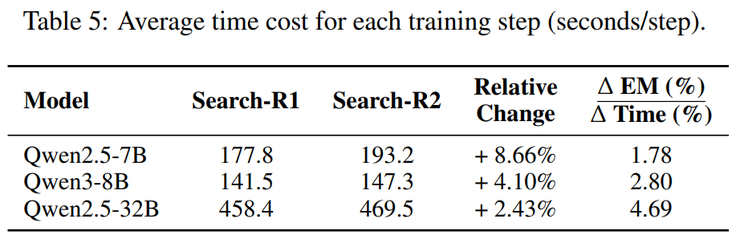
一種更貼近失敗模式的學習思路
從強化學習的角度來看,這項研究解決的並不是單一模組或訓練技巧的問題,而是搜尋推理中長期存在的信用分配難題。在長鏈搜尋推理過程中,模型需要在多個時間尺度上連續做出決策,而傳統方法只能依據最終答案是否正確進行回報分配,導致無法區分高質量推理軌跡與依賴偶然性的成功軌跡。
研究團隊通過引入軌跡篩選、錯誤定位和受控糾錯三種機制,將原本難以處理的信用分配問題拆解為可操作的學習目標,並在理論分析中證明,只有當模型能夠區分哪些軌跡值得保留、能夠定位導致推理偏離的關鍵錯誤位置,並在訓練過程中觸發數量適當的糾錯操作時,整體效能纔會穩定提升。
這一結論並非經驗歸納,而是通過形式化分析給出的必要條件。在方法層面,該研究進一步改變了以往反思與修正僅依賴人工提示的做法,將是否進行反思以及在何處進行修正納入策略空間,使其成為可以通過強化學習直接優化的決策行為,從而避免了人工提示不可學習、效果不穩定的問題。
與此同時,這個方法的設計直接針對真實智慧體任務中常見的失敗模式,即搜索結果本身存在噪聲、推理過程依賴較長的決策鏈條,以及早期一次錯誤可能對後續推理產生不可逆影響。
通過在推理過程中顯式建模錯誤傳播並提供中途干預機制,該研究為搜尋型智慧體在複雜任務中的穩定執行提供了一種更具針對性的解決思路。
Search-R2 的研究者們
這篇論文的一作是何博威,目前在 MBZUAI 的機器學習系擔任博士後研究員,合作導師為劉學教授。在此之前,他是香港城市大學電腦科學系的博士研究生,師從馬辰教授,研究方向包括 Data Mining,Language Model,AI for Science(和清華/香港城市大學馬維英教授團隊合作),和 Agentic AI。
他最近主要關注圍繞 AI Agent 的一系列前沿探索性課題,包括智慧體強化學習,智慧體記憶,長時程智慧體,智慧體終身演化,智慧體世界模型,和智慧體資料 Scaling Laws 等。

參考連結:https://scholar.google.com/citations?user=1cH0A9cAAAAJ&hl=en&oi=ao
這篇文章的共同一作為 Minda Hu,目前是香港中文大學電腦科學與工程系的博士研究生,並在 MISC Lab 從事研究工作,導師為金國慶教授。
他的研究興趣主要包括資料探勘、機器學習和自然語言處理,並關注機器學習、社會計算與自然語言處理等方向的交叉問題,當前的研究重點在於探索如何更高效、有效地利用大語言模型,以提升模型在實際應用場景中的推理能力與整體效能。

參考連結:https://misc-lab.cse.cuhk.edu.hk/sciencex_teams/minda-hu/
除此之外,該項工作得到了麥吉爾大學,香港城市大學,和愛丁堡大學等多位研究者的參與和貢獻。而該 paper 標題 Search-R2 還得到了來自 UIUC 和 Google 的 Search-R1 作者團隊的官方授權
雷峰網原創文章,未經授權禁止轉載。詳情見轉載須知。