圖神經網絡是近來發展較快的機器學習分支領域。通過將非結構數據轉換爲結構化的節點和邊的圖,然後採用圖神經網絡進行學習,往往能夠取得更好的效果。
然而,圖神經網絡發展到現在,尚無一個公認的基準測試數據集。許多論文采用的方法往往是針對較小的、缺乏節點和邊特徵的數據集上進行的。因此,在這些數據集上取得的模型性能很難說是最好的,也不一定可靠,這對進一步發展造成阻礙。
在 NeurlPS 2019 大會的圖表示學習演講中,Jure Leskovec 宣佈開源圖神經網絡的通用性能評價基準數據集 OGB(Open Graph Benchmark)。通過這一數據集,可以更好地評估模型性能等方面的指標。
項目地址:http://ogb.stanford.edu
圖表示學習演講合集:https://slideslive.com/38921872/graph-representation-learning-3

本次演講的嘉賓爲 Jure Leskovec,是斯坦福大學計算機科學的副教授。他主要的研究興趣是社會信息網絡的挖掘和建模等,特別是針對大規模數據、網絡和媒體數據。
值得注意的是,OGB 數據集也支持了 PYG 和 DGL 這兩個常用的圖神經網絡框架。DGL 項目的發起人之一、AWS 上海 AI 研究院院長,上海紐約大學張崢教授(學術休假中)說:「現階段,我認爲 OGB 的最大作用是促成學界走出玩具型數據集。一個統一的、更復雜、更多樣的數據集會使得研究人員重新聚集力量,雖然還會有模型過擬合標準數據集帶來的弊端,但對提升模型和算法效果、提高 DGL 等平臺的能力有着重要作用。」
張崢教授表示,Open Graph Benchmark 這種多樣與統一的基準,對於圖神經網絡來說,是非常有必要的一步。
首個統一的圖神經網絡開放基準
在演講中,Jure Leskovec 表示,目前常用的節點分類數據集也有 2k~3k 個節點,4k 到 5k 條邊,這實在是太小了。我們急需一種多樣性、具有挑戰性,且同時又非常接近真實業務的數據基準。
Open Graph Benchmark 就是這樣背景下提出的一項工作,它包含了各種圖數據、加載與處理圖數據的代碼庫,以及度量圖模型的代碼庫。整個實驗流程,研究者只需要關注最核心的模型搭建就可以了,剩下的都可以交給 Open Graph Benchmark。
如下是 Jure Leskovec 在 NeurIPS 研討會上介紹的 OGB:
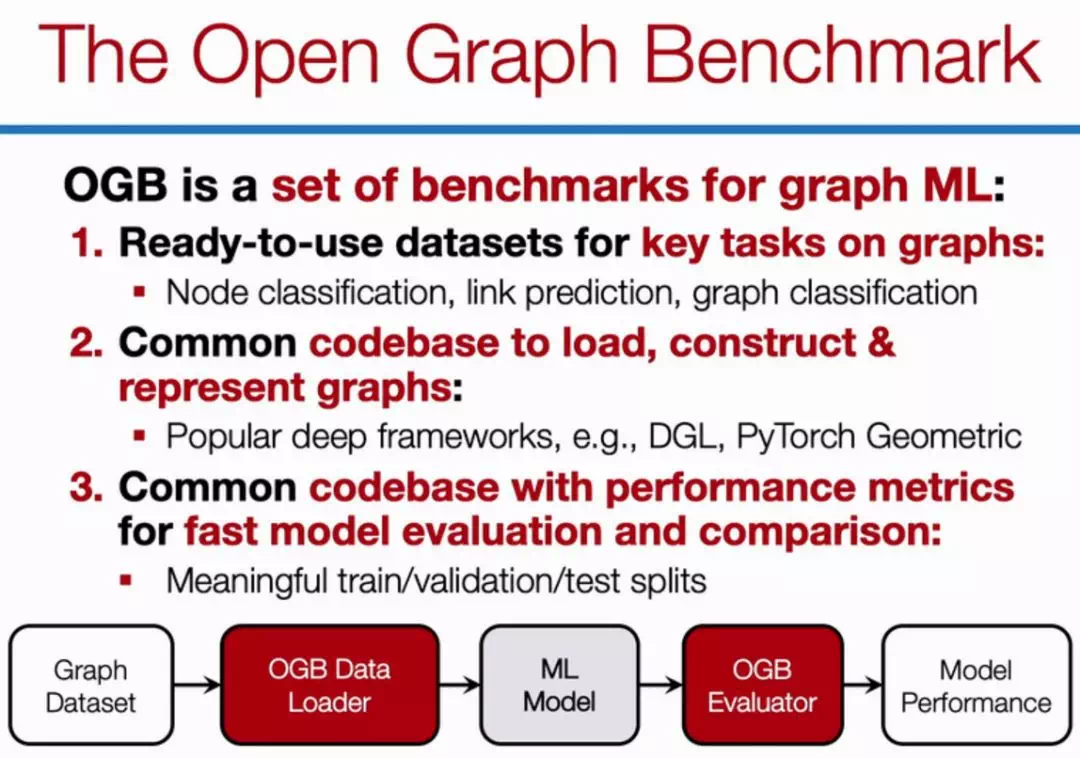
OGB 能支持 PyG 和 DGL 等主流圖神經網絡框架,也能支持新穎的數據集切分。其中在圖神經網絡中,數據集的切分特別重要,它和一般的機器學習任務有很大的不同。
「我認爲隨着研究的發展,OGB 還會繼續滾動,目前它類似於視覺領域的 CIFAR。」,張崢教授說:「OGB 數據在異構圖的佔比還太小,任務侷限在點、邊、圖的分類,而在圖上做推理、時間這個重要的維度等都還沒有考慮。總之,我期待 OGB 還有非常大的發展空間。」
OGB 的數據是什麼
畢竟是一個基準測試數據集,OGB 的數據自然是重中之重。根據官網提供的資料,OGB 的數據按照任務要求分爲以下幾類:
節點預測;
連接預測(邊)預測;
圖預測;
以下爲每個任務中包含的數據集:
節點預測
odbn-proteins:蛋白質數據集,有着蛋白質之間的關聯網絡,而且包括了多種生物;
odbn-wiki:維基百科數據形成的網絡;
ogbn-products:亞馬遜客戶同時購買的商品的網絡。
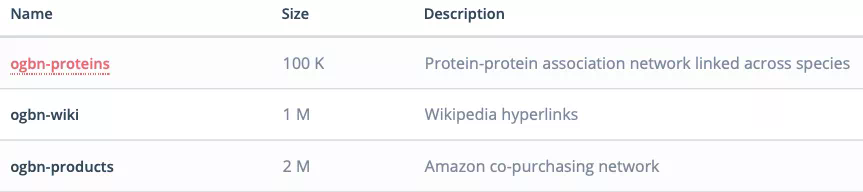
目前該基準測試所包含的數據集。
從數據集的類型來看,涵蓋了現有的幾大需要圖表示學習的領域:生物學/分子化學、自然語言處理,以及商品推薦系統網絡等。此外,這些圖數據的量也非常大。例如,ogbn-wiki 的數據量已達到百萬級別(節點),而最小的 ogbn-proteins 也有 100K 了。這和之前的很多圖數據相比都顯得更加龐大,因此也能更好地評價模型的性能表現。
連接預測
連接預測中的數據集則更多一些,包括:
ogbi-ddi:藥物相互作用網絡;
ogbi-biomed:人類生物醫藥知識圖譜;
ogbi-ppa:蛋白質之間的關係網絡;
ogbi-reviews:亞馬遜的用戶-商品評論數據集;
ogbi-citations:微軟學術的引用關係網絡圖譜。
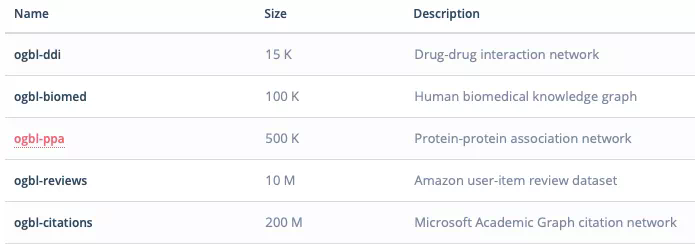
相比節點數據集來說,連接預測的數據集更多一些,類型也更爲多樣。
圖預測
OGB 同時也提供了對圖進行預測的任務數據集,分別有:
ogbg-mol:對分子進行預測,來自 MoleculeNet;
ogbg-code:代碼段的語法樹結構網絡;
ogbg-ppi:蛋白質之間的交互網絡;
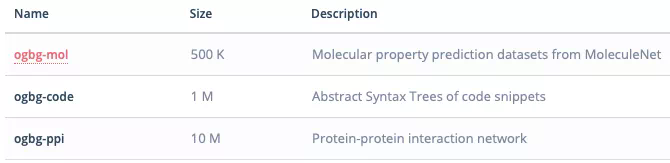
從總體來看,數據集中偏向醫藥和生物的數據集很多。張崢教授認爲,這可能有兩個原因,首先是項目主導者 Jure 等在這一領域做了比較多的工作,因此推動這些數據集開源順理成章。另一個原因是藥分子的圖數據相對乾淨,噪聲少。而藥品的結構是 3D 的,可能需要比較複雜、層數更深的模型解決相關的問題。
對於未來會有哪些數據集加入,張教授認爲現在關於異構圖的數據還不夠多,而現實中的很多數據都是異構圖表示的。但是,OGB 的作用依然明顯,它能夠很好地提升開源圖神經網絡框架的能力,推動開源社區集中力量解決實際問題。
另外,OGB 數據集中缺少金融、徵信等領域的數據集,特別是反欺詐類的。這可能是因爲反欺詐數據集脫敏後特徵丟失過多的問題所致,但瑕不掩瑜,OGB 無疑幫助圖神經網絡脫離了所謂的「玩具模型」階段,開始逐漸進入工業應用。
數據加載與評估
OGB 如此龐大的數據量需要專門的代碼進行提取。據悉,所有開源的數據集都可以用特定的代碼進行提取和加載,使用過程和深度學習框架中的 data_loader 相似。不過在使用前,我們還需要簡單地使用「pip install ogb」完成安裝。目前 OGB 庫主要依賴於 PyTorch、NumPy 和 Scikit-Learn 等常用建模庫,當然圖神經網絡庫也可以自由選擇 DGL 或 PyTorch Geometric。
DGL:https://github.com/dmlc/dgl
PyG:https://github.com/rusty1s/pytorch_geometric
現在以節點預測爲例,OGB 同時支持 PYG 和 DGL 兩個圖表示學習框架中的數據加載方法,加載代碼如下:
1. PYG
from ogb.nodeproppred.dataset_pyg import PygNodePropPredDatasetdataset = PygNodePropPredDataset(name = d_name)num_tasks = dataset.num_tasks # obtaining number of prediction tasks in a datasetsplitted_idx = dataset.get_idx_split()train_idx, valid_idx, test_idx = splitted_idx["train"], splitted_idx["valid"], splitted_idx["test"]graph = dataset[0] # pyg graph object
2. DGL
from ogb.nodeproppred.dataset_dgl import DglNodePropPredDatasetdataset = DglNodePropPredDataset(name = d_name)num_tasks = dataset.num_tasks # obtaining number of prediction tasks in a datasetsplitted_idx = dataset.get_idx_split()train_idx, valid_idx, test_idx = splitted_idx["train"], splitted_idx["valid"], splitted_idx["test"]graph, label = dataset[0] # graph: dgl graph object, label: torch tensor of shape (num_nodes, num_tasks)
可以看出,代碼非常簡單,使用簡便。其中「d_name」可以被替換成任何一個數據集的名字。
同時,項目提供了一些示例代碼,以對每個數據集進行評估。如下所示:
from ogb.nodeproppred import Evaluatorevaluator = Evaluator(name = d_name)print(evaluator.expected_input_format)print(evaluator.expected_output_format)
這裏,用戶可以瞭解到針對這一數據集的輸入和輸出的特定格式。
然後,用戶可以將輸入字典(input dictionary)傳遞進評估器中,瞭解實際的性能:
# In most cases, input_dict is# input_dict = {"y_true": y_true, "y_pred": y_pred}result_dict = evaluator.eval(input_dict)
據悉,OGB 官方已指明上海 AWS AI 研究院主打的開源框架 DGL 作爲數據導入的平臺之一。目前 DGL 兼容 PyTorch、MxNet 作爲後端引擎,TensorFlow 也在開發中。實際上 DGL 在異構圖和可擴展性已經做了很久,因此下一步可能會和 OGB 在相關領域進行新的技術結合,推動開源框架的發展。
張崢說:「DGL 目前在製藥領域已有了一個效果不錯的模型庫,有了 OGB 數據集對模型庫進行迭代,之後應當可以進一步提升。」
爲什麼說分割圖數據是個問題?
在 Jure Leskovec 的演講中,他特意強調了 OGB 所採用的數據分割方法,它能構建更合理的評估方案。他表示,似乎隨機數據分割並不是一件值得關注的事,但當我們將數據隨機分割爲訓練、驗證和測試集時,很可能預測準確率看上去非常不錯。但實際上,採用隨機分割的模型驗證,其效果是過於高估的。
Jure Leskovec 舉了個例子,比如說自然科學研究者,他們每次收集的數據肯定不是重複的,他們每次都需要做一系列新實驗,因此模型每次都在做分佈外的預測。這就要求數據的分割方式需要非常合理,需要模型的泛化能力足夠強大以處理這些分佈外的數據預測。

談及數據分割問題,張崢教授說:「我們在和製藥行業的研究人員討論時,都被提醒在訓練集上做隨機切分是不可取的,因爲分子圖樣本有結構性質,獨立同分布假設會對模型的泛化能力有影響,我認爲其他領域也有同樣的問題。」
爲了處理這種情況,OGB 採用的數據分割方法也非常有意思。例如對於分子圖數據集,分割方法可以是分子支架(scaffold),具體而言,我們可以通過分子的子結構做聚類,然後將常用的集羣作爲訓練集,將其它非常見集羣作爲驗證與測試集。這種處理方式會迫使神經網絡獲得更高的泛化性,不然它完全無法預測那些子結構不同的分子。
按物種分割或按代碼庫分割也是相同的道理,本質上這些數據分割都嘗試把某一小部分整體移出來做測試。

最後,Jure Leskovec 也表明,他們預想 OGB 不僅能作爲一種廣泛使用的研究資源,同時也能作爲各種新任務或新模型的真實測試環境。在不久的將來,OGB 將進一步支持更多的圖數據集、更多的圖建模任務,並同時提供一份開放的 LeadBoard。有了這樣的 LeadBoard,我們就能更直觀地評估各種圖神經網絡的特點,瞭解哪種情況下它們的效果是最好的。