0 簡介
yolov4論文名稱:YOLOv4: Optimal Speed and Accuracy of Object Detectio
arxiv地址:https://arxiv.org/abs/2004.10934
github源碼地址:https://github.com/AlexeyAB/darknet
YOLOV4的發佈,可以想象到大家的激動,但是論文其實是一個結合了大量前人研究技術,加以組合並進行適當創新的高水平論文,實現了速度和精度的完美平衡。很多yolov4的分析文章都會說其中應用了哪些技術?但是我暫時沒有看到對其中用到的各種技術進行詳細分析的文章,本文的目的就是如此,希望通過YOLOV4提到的各種新技術進行分析,明白YOLOV4後面的功臣算法。
文中將前人的工作主要分爲Bag of freebies和Bag of specials,前者是指不會顯著影響模型測試速度和模型複雜度的技巧,主要就是數據增強操作,對應的Bag of specials就是會稍微增加模型複雜度和速度的技巧,但是如果不大幅增加複雜度且精度有明顯提升,那也是不錯的技巧。本文按照論文講的順序進行分析。由於每篇論文其實內容非常多,我主要是分析思想和一些核心細節。
本篇文章分析如下技術:random erasing、cutout、hide-and-seek、grid mask、Adversarial Erasing、mixup、cutmix、mosaic、Stylized-ImageNet、label smooth、dropout和dropblock。 下一篇分析網絡結構、各種層歸一化技術、以及其他相關技術。
由於本人水平有限,如有分析不對的地方,歡迎指正和交流。
1 數據增強相關
1.1 Random erasing data augmentation
論文名稱:Random erasing data augmentation
論文地址:https://arxiv.org/pdf/1708.04896v2.pdf
github: https://github.com/zhunzhong07/Random-Erasing
隨機擦除增強,非常容易理解。作者提出的目的主要是模擬遮擋,從而提高模型泛化能力,這種操作其實非常make sense,因爲我把物體遮擋一部分後依然能夠分類正確,那麼肯定會迫使網絡利用局部未遮擋的數據進行識別,加大了訓練難度,一定程度會提高泛化能力。其也可以被視爲add noise的一種,並且與隨機裁剪、隨機水平翻轉具有一定的互補性,綜合應用他們,可以取得更好的模型表現,尤其是對噪聲和遮擋具有更好的魯棒性。具體操作就是:隨機選擇一個區域,然後採用隨機值進行覆蓋,模擬遮擋場景。

在細節上,可以通過參數控制擦除的面積比例和寬高比,如果隨機到指定數目還無法滿足設置條件,則強制返回。 一些可視化效果如下:


對於目標檢測,作者還實現了3種做法,如下圖所示(然而我打開開源代碼,發現只實現了分類的隨機擦除而已,尷尬)。

當然隨機擦除可以和其他數據增強聯合使用,如下所示。


torchvision已經實現了:https://pytorch.org/docs/master/_modules/torchvision/transforms/transforms.html#RandomErasing
注意:torchvision的實現僅僅針對分類而言,如果想用於檢測,還需要自己改造。調用如下所示:
torchvision.transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False)
1.2 Cutout
論文名稱:Improved Regularization of Convolutional Neural Networks with Cutout
論文地址:https://arxiv.org/abs/1708.04552v2
github: https://github.com/uoguelph-mlrg/Cutout
出發點和隨機擦除一樣,也是模擬遮擋,目的是提高泛化能力,實現上比random erasing簡單,隨機選擇一個固定大小的正方形區域,然後採用全0填充就OK了,當然爲了避免填充0值對訓練的影響,應該要對數據進行中心歸一化操作,norm到0。
本文和隨機擦除幾乎同時發表,難分高下(不同場景下誰好難說),區別在於在cutout中,擦除矩形區域存在一定概率不完全在原圖像中的。而在Random Erasing中,擦除矩形區域一定在原圖像內。Cutout變相的實現了任意大小的擦除,以及保留更多重要區域。
需要注意的是作者發現cutout區域的大小比形狀重要,所以cutout只要是正方形就行,非常簡單。具體操作是利用固定大小的矩形對圖像進行遮擋,在矩形範圍內,所有的值都被設置爲0,或者其他純色值。而且擦除矩形區域存在一定概率不完全在原圖像中的(文中設置爲50%)
論文中有一個細節可以看看:作者其實開發了一個早期做法,具體是:在訓練的每個epoch過程中,保存每張圖片對應的最大激活特徵圖(以resnet爲例,可以是layer4層特徵圖),在下一個訓練回合,對每張圖片的最大激活圖進行上採樣到和原圖一樣大,然後使用閾值切分爲二值圖,蓋在原圖上再輸入到cnn中進行訓練,有點自適應的意味。但是有個小疑問:訓練的時候不是有數據增強嗎?下一個回合再用前一次增強後的數據有啥用?我不太清楚作者的實現細節。如果是驗證模式下進行到是可以。 這種做法效果蠻好的,但是最後發現這種方法和隨機選一個區域遮擋效果差別不大,而且帶來了額外的計算量,得不償失,便捨去。就變成了現在的cutout了。
可能和任務有關吧,按照我的理解,早期做法非常make sense,效果居然和cutout一樣,比較奇怪。並且實際上考慮目標檢測和語義分割,應該還需要具體考慮,不能照搬實現。
學習這類論文我覺得最重要的是思想,能不能推廣到不同領域上面?是否可以在訓練中自適應改變?是否可以結合特徵圖聯合操作?

1.3 Hide-and-Seek
論文名稱:Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization and Beyond
論文地址:https://arxiv.org/abs/1811.02545
github地址:https://github.com/kkanshul/Hide-and-Seek
可以認爲是random earsing的推廣。核心思想就是去掉一些區域,使得其他區域也可以識別出物體,增加特徵可判別能力。和大部分細粒度論文思想類型,如下所示:
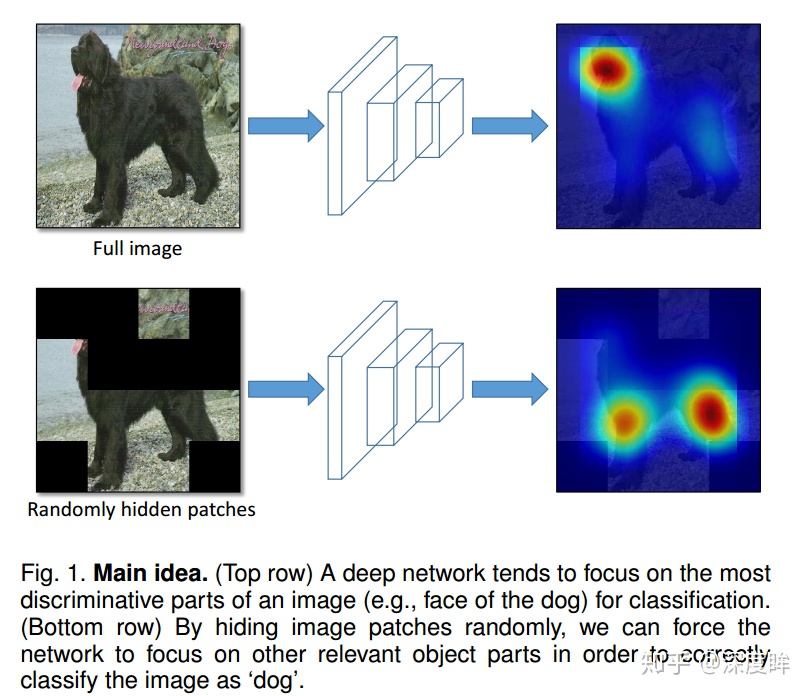
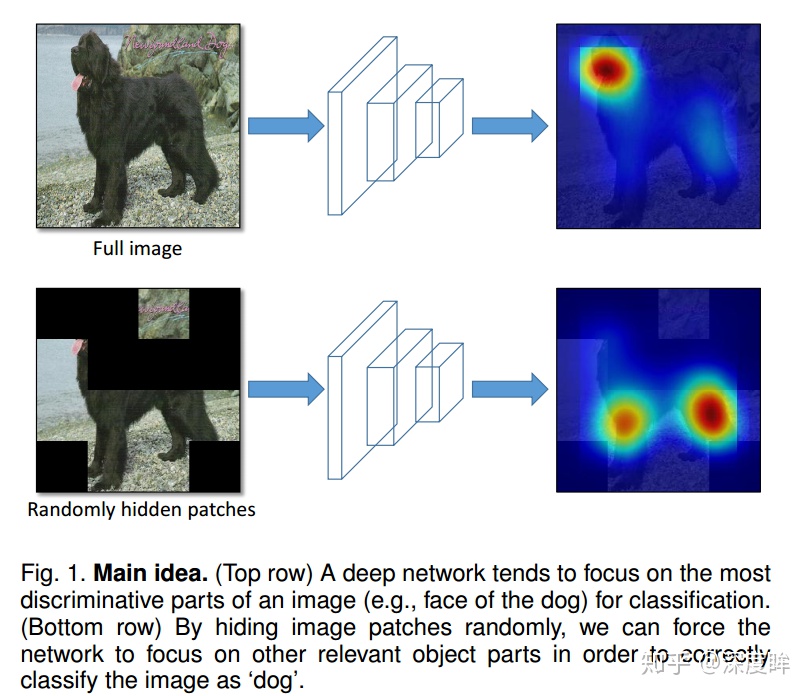
數據增強僅僅用於訓練階段,測試還是整圖,不遮擋,如下所示。
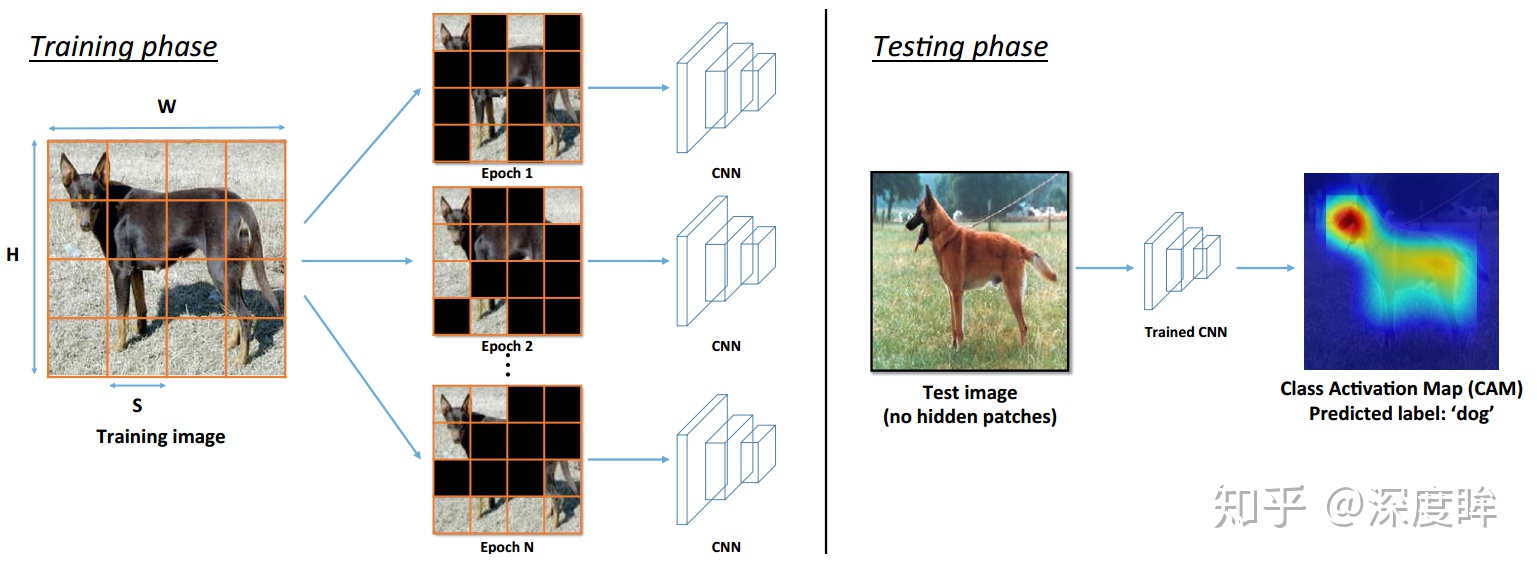
做法是將圖片切分爲sxs個網格,每個網格採用一定概率進行遮擋,可以模擬出隨機擦除和cutout效果。
至於隱藏值設置爲何值,作者認爲比較關鍵,因爲可能會改變訓練數據的分佈。如果暴力填黑,認爲會出現訓練和測試數據分佈不一致問題,可能不好,特別是對於第一層卷積而言。作者採用了一些理論計算,最後得到採用整個數據集的均值來填充造成的影響最小(如果採用均值,那麼輸入網絡前,數據預處理減掉均值,那其實還是接近0)。
1.4 GridMask Data Augmentation
論文名稱:GridMask Data Augmentation
論文地址:https://arxiv.org/abs/2001.04086v2
本文可以認爲是前面3篇文章的改進版本。本文的出發點是:刪除信息和保留信息之間要做一個平衡,而隨機擦除、cutout和hide-seek方法都可能會出現可判別區域全部刪除或者全部保留,引入噪聲,可能不好。如下所示:


要實現上述平衡,作者發現非常簡單,只需要結構化drop操作,例如均勻分佈似的刪除正方形區域即可。並且可以通過密度和size參數控制,達到平衡。如下所示:

其包括4個超參,如下所示:
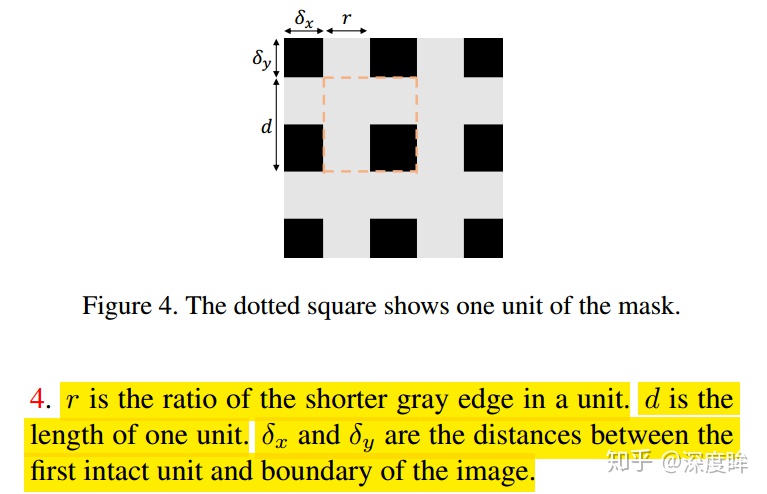
首先定義k,即圖像信息的保留比例,其中H和W分別是原圖的高和寬,M是保留下來的像素數,保留比例k如下,該參數k和上述的4個參數無直接關係,但是該參數間接定義了r:


d決定了一個dropped square的大小, 參數 x和 y的取值有一定隨機性.


其實看起來,就是兩個參數: r和d,r通過k計算而來,用於計算保留比例(核心參數),d用了控制每個塊的大小。d越大,每個黑色塊面積就越大,黑色塊的個數就越少,d越小,黑色塊越小,個數就越多。xy僅僅用於控制第一個黑色塊的偏移而已。
對於應用概率的選擇,可以採用固定值或者線性增加操作,作者表示線性增加會更好,例如首先選擇r = 0.6,然後隨着訓練epoch的增加,概率從0增加到0.8,達到240th epoch後固定,這種操作也是非常make sense,爲了模擬更多場景,在應用於圖片前,還可以對mask進行旋轉。這種策略當然也可以應用於前3種數據增強策略上。
1.5 object Region Mining with Adversarial Erasing
論文地址:https://arxiv.org/pdf/1703.08448.pdf
本文在yolov4中僅僅是提了一下,不是重點,但是我覺得思想不錯,所以還是寫一下。
本文要解決的問題是使用分類做法來做分割任務(弱監督分割),思想比較有趣。如下所示:
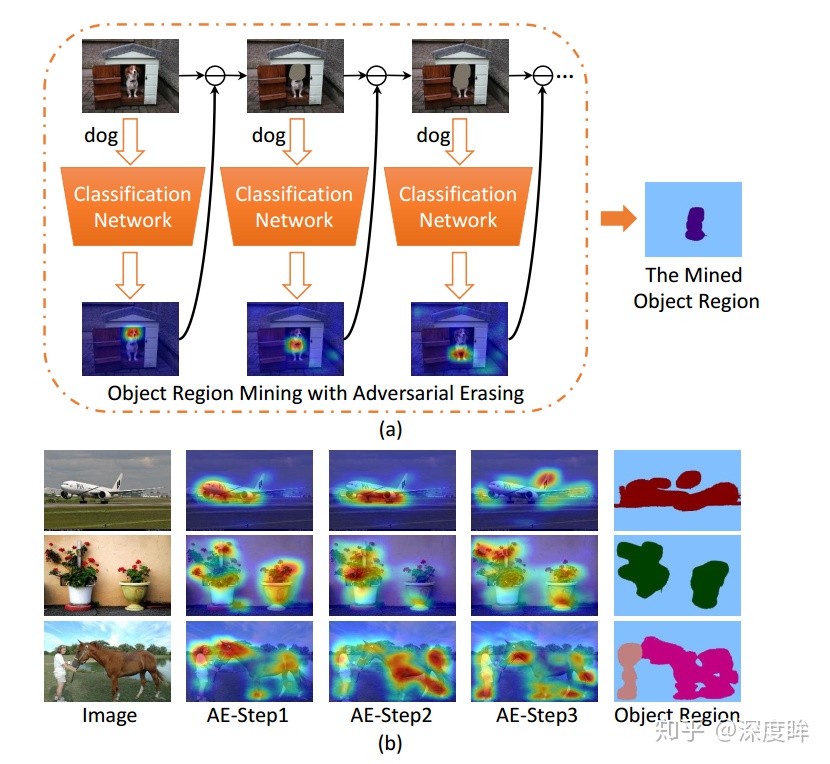
通過迭代訓練的方式不斷挖掘不同的可判別區域,最終組合得到完整的分割結果。第t次訓練迭代(一次迭代就是指的一次完整的訓練過程),對於每張圖片都可以得到cam圖(類別激活圖),將cam圖二值化然後蓋在原圖上,進行下一次迭代訓練,每次迭代都是學習一個不同的可判別區域,迭代結束條件就是分類性能不行了,因爲可判別區域全部被蓋住了(由於該參數其實很難設置,故實驗直接取3)。最後的分割結果就是多次迭代的cam圖疊加起來即可。
本文是cvpr2017的論文,放在現在來看,做法其實超級麻煩,現在而言我肯定直接採用細粒度方法,採用特徵擦除技術,端到端訓練,學習出所有可判別區域。應該不會比這種做法效果差,但是在當時還是不錯的思想。
但是其也提供了一種思路:是否可以採用分類預測出來的cam,結合弱監督做法,把cam的輸出也引入某種監督,在提升分類性能的同時,提升可判別學習能力。
1.6 mixup
論文題目:mixup: BEYOND EMPIRICAL RISK MINIMIZATION
論文地址:https://arxiv.org/abs/1710.09412
mixup由於非常有名,我想大家都應該知道,而且網上各種解答非常多,故這裏就不重點說了。
其核心操作是:兩張圖片採用比例混合,label也需要混合。


論文中提到的一些關鍵的Insight:
1 也考慮過三個或者三個以上的標籤做混合,但是效果幾乎和兩個一樣,而且增加了mixup過程的時間。
2 當前的mixup使用了一個單一的loader獲取minibatch,對其隨機打亂後,mixup對同一個minibatch內的數據做混合。這樣的策略和在整個數據集隨機打亂效果是一樣的,而且還減少了IO的開銷。
3 在同種標籤的數據中使用mixup不會造成結果的顯著增強
1.7 cutmix和Mosaic
論文名稱:CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
論文地址:https://arxiv.org/abs/1905.04899
開源地址:https://github.com/clovaai/CutMix-PyTorch
簡單來說cutmix相當於cutout+mixup的結合,可以應用於各種任務中。
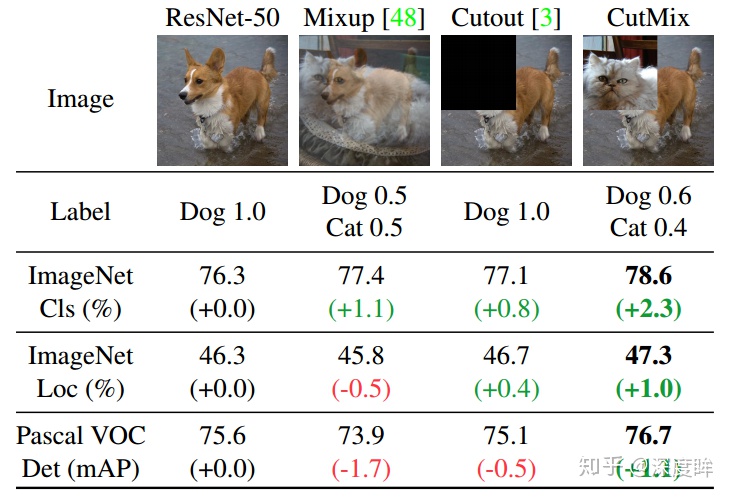
mixup相當於是全圖融合,cutout僅僅對圖片進行增強,不改變label,而cutmix則是採用了cutout的局部融合思想,並且採用了mixup的混合label策略,看起來比較make sense。
cutmix和mixup的區別是,其混合位置是採用hard 0-1掩碼,而不是soft操作,相當於新合成的兩張圖是來自兩張圖片的hard結合,而不是Mixup的線性組合。但是其label還是和mixup一樣是線性組合。作者認爲mixup的缺點是:Mixup samples suffer from the fact that they are locally ambiguous and unnatural, and therefore confuses the model, especially for localization。
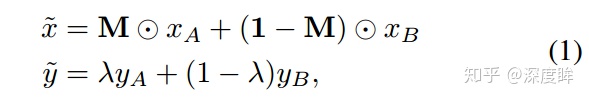
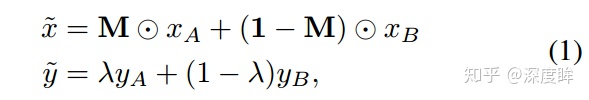
M是和原圖大小一樣的矩陣,只有0-1值,$\lambda$ 用於控制線性混合度,通過$\lambda$ 參數可以控制裁剪矩形大小,
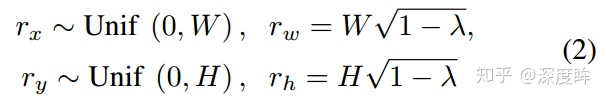
僞代碼如下:


而Mosaic增強是本文提出的,屬於cutmix的擴展,cutmix是兩張圖混合,而馬賽克增強是4張圖混合,好處非常明顯是一張圖相當於4張圖,等價於batch增加了,可以顯著減少訓練需要的batch size大小。

1.8 Stylized-ImageNet
論文名稱:ImageNet-trained cnns are biased towards texture; increasing shape bias improves accuracy and robustness
本文非常有意思,得到的結論非常有意義,可以指導我們對於某些場景測試失敗的分析。本質上本文屬於數據增強論文,做的唯一一件事就是:對ImageNet數據集進行風格化。
本文結論是:CNN訓練學習到的實際是紋理特徵(texture bias)而不是形狀特徵,這和人類的認知方式有所區別,如論文題目所言,存在紋理偏置。而本文引入風格化imagenet數據集,平衡紋理和形狀偏置,提高泛化能力。
本文指出在ImageNet上訓練的CNN強烈的偏向於識別紋理而不是形狀,這和人的行爲是極爲不同的,存在紋理偏差,所以提出了Stylized-ImageNet數據,混合原始數據訓練就可以實現既關注紋理,也關注形狀(也就是論文標題提到的減少紋理偏向,增加形狀偏向)。從而不僅更適合人類的行爲,更驚訝的是提升了目標檢測的精度,以及魯棒性,更加體現了基於形狀表示的優勢。
文章從一隻披着象皮的貓究竟會被識別爲大象還是貓這個問題入手,揭示了神經網絡根據物體的texture進行識別而非我們以爲的根據物體的形狀。
作者準備了6份數據,分別是正常的圖片,灰色圖,只包含輪廓的,只包含邊緣的,只有紋理沒有形狀,紋理和形狀相互矛盾(大象的紋理,貓的形狀),對於第六份數據(紋理和形狀衝突的數據),作者採用Stylized-ImageNet隨機地將物體的紋理替換掉(也就是本文創新點),如下(c)所示:


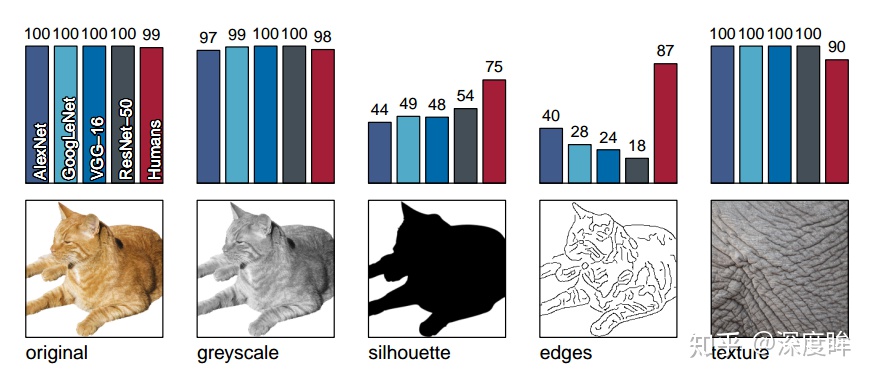
採用了4個主流網絡,加上人類直觀評估。原圖其實是作者除了物體外,其餘都是白色背景的數據集,目的是去除干擾。 對於前面5份數據,採用原圖和灰度圖,神經網絡都可以取得非常高的準確率,而對於只包含輪廓和只包含邊緣的圖片,神經網絡的預測準確率則顯著降低。更有意思的是,對於只包含紋理的圖片,神經網絡取得特別高的準確率。因而不難推斷出,神經網絡在識別中,主要是參考紋理信息而不是形狀信息。
作者先構造數據集,然後再進行後面的深入實驗,IN就是指的ImageNet,SIN是指的風格化的ImageNet,如下所示


SIN的特點是保留shape,但是故意混淆掉紋理信息。
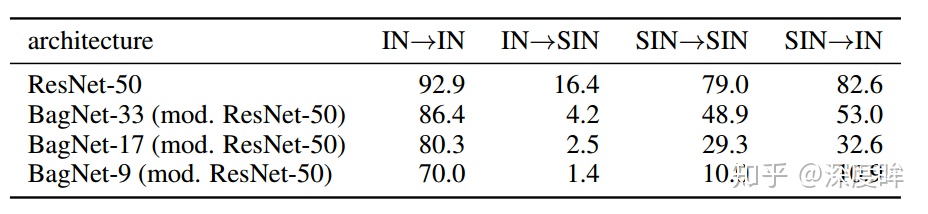
從上表的第一行可以看出,在原始圖片IN上訓練的模型不能適應去除紋理SIN的圖片(IN-SIN),而使用去除紋理的圖片進行訓練和測試效果會差於使用原始圖片進行訓練和測試(SIN-SIN),這說明紋理信息在圖像識別中確實起到了一定的作用,去除了紋理信息會提高模型識別的難度。最後,當我們使用去除紋理的圖片進行訓練而在原圖進行測試的時候(SIN-IN),效果比在去除紋理的圖片上面效果好(SIN-SIN)。
後面三行的實驗採用的是第一行resnet的網絡結構,其主要特徵是限制模型的感受野,從而讓模型無法學習到空間的信息,其對應的感受野分別是33*33, 17 * 17,9*9,對於訓練原始的圖片,其結果測試誤差跟沒有加上感受野限制的誤差差別不大,從而說明紋理信息起到主導作用(IN-IN),而對應去除掉紋理信息的圖片,其測試結果下降十分明顯(SIN-SIN),說明形狀信息起到主要的作用,證明了SIN的模型確實在學習形狀的信息而不是紋理的信息。這個實驗是要說明提出的SIN數據集由於強制抹掉了固定紋理,網絡訓練難度增大,在沒有限制感受野情況下可以學的蠻好,但是一旦限制了感受野就不行了,說明SIN模型學習到的不僅僅是紋理(因爲紋理是局部的,如果依靠紋理來分類,那麼準確率應該下降不了這麼多),更多的是依靠shape分類,因爲感受野外限制了,導致無法看到整個shape,並且通過更加限制感受野,SIN-SIN準確率下降更多可以發現。 也就是說SIN數據集由於替換掉了紋理,迫使網絡學習shape和紋理,達到了本文目的。SIN上訓練的ResNet50展示出更強的形狀偏向,符合人類常理。
增強形狀偏向也改變了表示,那麼影響了CNN的性能和魯棒性了嗎?我們設置了兩個訓練方案:
1 同時在SIN和IN上訓練
2 同時在SIN和IN上訓練,在IN上微調。稱爲Shape-ResNet。


作者把去掉紋理的數據和原圖一起放進去模型中進行訓練,最後用原圖進行finetune,發現這種方法可以提高模型的性能。Shape-ResNet超過了原始ResNet的準確率,說明SIN是有用的圖像增強。
總結:CNN識別強烈依賴於紋理,而不是全局的形狀,但是這是不好的,爲了突出形狀bias,可以採用本文的SIN做法進行數據增強,SIN混合原始數據訓練就可以實現既關注紋理,也關注形狀,不僅符合人類直觀,也可以提高各種任務的準確率和魯邦性。所以本文其實是提出了一種新的數據增強策略。是不是很有意思的結論?
1.9 label smooth
論文題目:Rethinking the inception architecture for computer vision
label smooth是一個非常有名的正則化手段,防止過擬合,我想基本上沒有人不知道,故不詳說了,核心就是對label進行soft操作,不要給0或者1的標籤,而是有一個偏移,相當於在原label上增加噪聲,讓模型的預測值不要過度集中於概率較高的類別,把一些概率放在概率較低的類別。
2 特徵增強相關
2.1 DropBlock
論文題目:DropBlock: A regularization method for convolutional networks
論文地址:https://arxiv.org/abs/1810.12890
開源代碼:https://github.com/miguelvr/dropblock
由於dropBlock其實是dropout在卷積層上的推廣,故很有必須先說明下dropout操作。
dropout,訓練階段在每個mini-batch中,依概率P隨機屏蔽掉一部分神經元,只訓練保留下來的神經元對應的參數,屏蔽掉的神經元梯度爲0,參數不參數與更新。而測試階段則又讓所有神經元都參與計算。
dropout操作流程:參數是丟棄率p
1)在訓練階段,每個mini-batch中,按照伯努利概率分佈(採樣得到0或者1的向量,0表示丟棄)隨機的丟棄一部分神經元(即神經元置零)。用一個mask向量與該層神經元對應元素相乘,mask向量維度與輸入神經一致,元素爲0或1。
2)然後對神經元rescale操作,即每個神經元除以保留概率1-P,也即乘上1/(1-P)。
3)反向傳播只對保留下來的神經元對應參數進行更新。
4)測試階段,Dropout層不對神經元進行丟棄,保留所有神經元直接進行前向過程。
爲啥要rescale呢?是爲了保證訓練和測試分佈儘量一致,或者輸出能量一致。可以試想,如果訓練階段隨機丟棄,那麼其實dropout輸出的向量,有部分被屏蔽掉了,可以等下認爲輸出變了,如果dropout大量應用,那麼其實可以等價爲進行模擬遮擋的數據增強,如果增強過度,導致訓練分佈都改變了,那麼測試時候肯定不好,引入rescale可以有效的緩解,保證訓練和測試時候,經過dropout後數據分佈能量相似。
上面的截圖來自:https://www.pianshen.com/article/2769164511/
dropout方法多是作用在全連接層上,在卷積層應用dropout方法意義不大。文章認爲是因爲每個feature map的位置都有一個感受野範圍,僅僅對單個像素位置進行dropout並不能降低feature map學習的特徵範圍,也就是說網絡仍可以通過該位置的相鄰位置元素去學習對應的語義信息,也就不會促使網絡去學習更加魯邦的特徵。
既然單獨的對每個位置進行dropout並不能提高網絡的泛化能力,那麼很自然的,如果我們按照一塊一塊的去dropout,就自然可以促使網絡去學習更加魯邦的特徵。思路很簡單,就是在feature map上去一塊一塊的找,進行歸零操作,類似於dropout,叫做dropblock。


綠色陰影區域是語義特徵,b圖是模擬dropout的做法,隨機丟棄一些位置的特徵,但是作者指出這中做法沒啥用,因爲網絡還是可以推斷出來,(c)是本文做法。
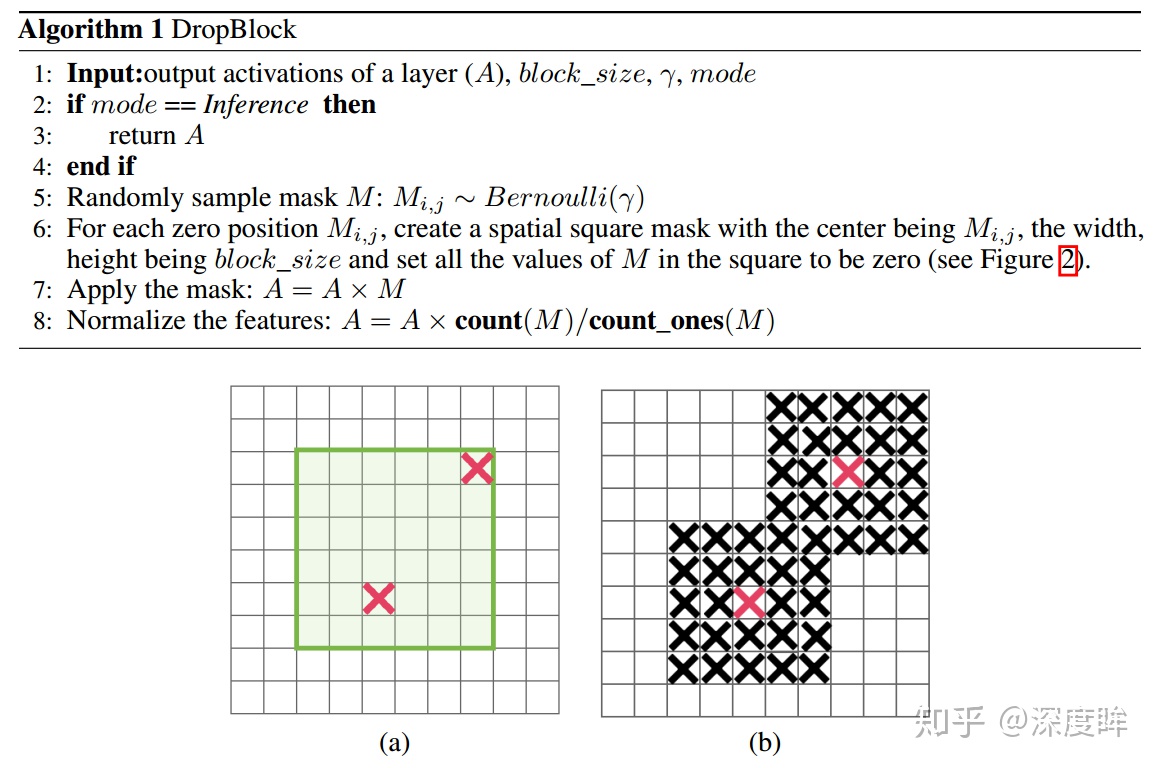
dropblock有三個比較重要的參數,一個是block_size,用來控制進行歸零的block大小;一個是γ,用來控制每個卷積結果中,到底有多少個channel要進行dropblock;最後一個是keep_prob,作用和dropout裏的參數一樣。
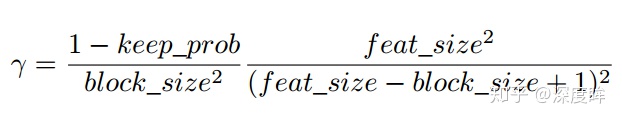
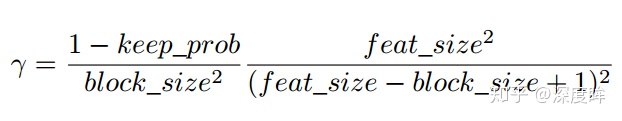
M大小和輸出特徵圖大小一致,非0即1,爲了保證訓練和測試能量一致,需要和dropout一樣,進行rescale。
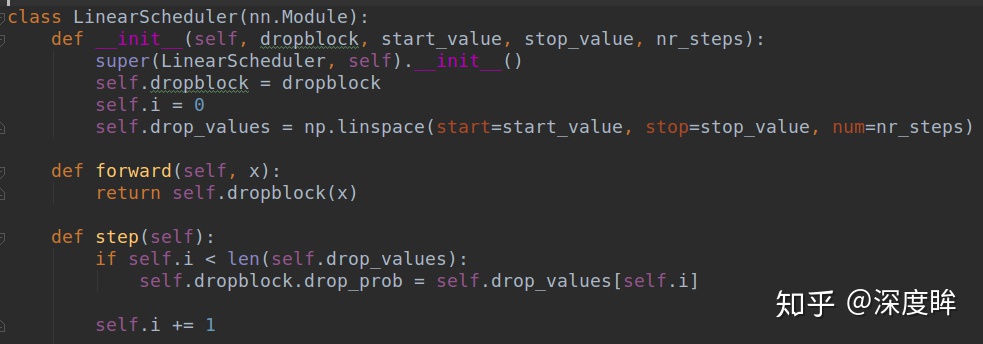
上述是理論分析,在做實驗時候發現,block_size控制爲7*7效果最好,對於所有的feature map都一樣,γ通過一個公式來控制,keep_prob則是一個線性衰減過程,從最初的1到設定的閾值(具體實現是dropout率從0增加到指定值爲止),論文通過實驗表明這種方法效果最好。如果固定prob效果好像不好。
實踐中,並沒有顯式的設置 的值,而是根據keep_prob(具體實現是反的,是丟棄概率)來調整。
DropBlock in ResNet-50 DropBlock加在哪?最佳的DropBlock配置是block_size=7,在group3和group4上都用。將DropBlock用在skip connection比直接用在卷積層後要好,具體咋用,可以看代碼。
class DropBlock2D(nn.Module): r"""Randomly zeroes 2D spatial blocks of the input tensor. As described in the paper `DropBlock: A regularization method for convolutional networks`_ , dropping whole blocks of feature map allows to remove semantic information as compared to regular dropout. Args: drop_prob (float): probability of an element to be dropped. block_size (int): size of the block to drop Shape: - Input: `(N, C, H, W)` - Output: `(N, C, H, W)` .. _DropBlock: A regularization method for convolutional networks: https://arxiv.org/abs/1810.12890 """ def __init__(self, drop_prob, block_size): super(DropBlock2D, self).__init__() self.drop_prob = drop_prob self.block_size = block_size def forward(self, x): # shape: (bsize, channels, height, width) assert x.dim() == 4, \ "Expected input with 4 dimensions (bsize, channels, height, width)" if not self.training or self.drop_prob == 0.: return x else: # get gamma value gamma = self._compute_gamma(x) # sample mask mask = (torch.rand(x.shape[0], *x.shape[2:]) < gamma).float() # place mask on input device mask = mask.to(x.device) # compute block mask block_mask = self._compute_block_mask(mask) # apply block mask out = x * block_mask[:, None, :, :] # scale output out = out * block_mask.numel() / block_mask.sum() return out def _compute_block_mask(self, mask): # 比較巧妙的實現,用max pool來實現基於一點來得到全0區域 block_mask = F.max_pool2d(input=mask[:, None, :, :], kernel_size=(self.block_size, self.block_size), stride=(1, 1), padding=self.block_size // 2) if self.block_size % 2 == 0: block_mask = block_mask[:, :, :-1, :-1] block_mask = 1 - block_mask.squeeze(1) return block_mask def _compute_gamma(self, x): return self.drop_prob / (self.block_size ** 2)聯合線性調度一起使用,如下所示: