問耕 發自 凹非寺
量子位 出品 | 公衆號 QbitAI

Team OG,Dota2世界冠軍戰隊。
在人工智能OpenAI Five面前,OG不堪一擊。五個人類組成的戰隊,此前全程毫無懸念地以0:2敗下陣來,兩局加在一起,OG只推掉了兩座外塔。
不過,這還不是AI的巔峯。
現在OpenAI又訓練出了一個全新的AI,名叫Rerun。面對碾壓OG的OpenAI Five,Rerun的勝率達到了……呃……98%。

聽到這個消息,一位推特網友發圖明志。
主要依靠自學,就能在Dota2這麼複雜的遊戲中稱雄,人工智能是怎麼做到的?今天,有關於此的答案揭曉。
沒錯,OpenAI不單發佈了Rerun,還把自己三年多來對於Dota2項目的研究,通過一篇論文,正式公佈出來。
在這篇論文中,OpenAI解釋了整套系統的原理、架構、計算量、參數等等諸多方面的內容。OpenAI指出通過增加batch size和總訓練時間等方法,擴展了計算規模,進而表明當今的強化學習技術可以在複雜的電子競技遊戲中,達到超越人類的水平。
這些研究,可以進一步應用於各種兩個對手持續的零和博弈中。

(可能是閱讀之後)OG戰隊發推:「Wow!這篇論文看起來太棒了!」
此情此景,有網友無深情的感嘆道:Wow!OG戰隊誇了一篇論文好看?真是活久見……
這篇論文到底說了什麼?
我們總結了幾個要點。
要點一:Dota2比下圍棋更復雜
與棋類對弈相比,電子競技遊戲要更復雜。
攻克這一難題的關鍵是,把現有的強化學習系統規模,擴展到前所未有的水平,這耗費了數千塊GPU和好幾個月的時間。OpenAI爲此構建了一個分佈式的訓練系統。
訓練中的一個挑戰是,環境和代碼會不斷變化。爲了在每次更改後無需從頭開始,OpenAI開發了一套工具,可以在不損失性能的情況下恢復訓練,這套工具稱爲:surgery。

每局Dota2比賽時長大約45分鐘,每秒鐘會生成30幀的遊戲畫面。OpenAI Five每4幀做出一個動作。國際象棋一局下約80步,圍棋下一局約150步,作爲對比,Dota2打一局,AI需要「下」大概20000步。
而且由於戰爭迷霧的存在,Dota2中對戰的雙方,只能看到全盤遊戲中的局部情況,其他部分的信息都是隱藏狀態。
與下圍棋的AlphaGo相比,打Dota2的AI系統,batch size要大50-150倍,模型大20倍,訓練時間長25倍。
要點二:AI如何學會打Dota2
人類玩Dota2通過鍵盤鼠標等,實時作出決定。剛纔提到,OpenAI Five每4幀做出一個動作,這被稱爲一個timestep。每個timestep期間,OpenAI會接收血量、位置等數據。
同樣的信息,人類和OpenAI Five接收的方式完全不同。

人工智能系統發出動作指令時,大概可以想成這個樣子。

AI背後是一套神經網絡。policy (π) 被定義爲從觀察數據到動作概率分佈的函數,這是一個有1.59億個參數的RNN神經網絡。這個網絡主要由一個單層、4096-unit的LSTM構成。
結構如下圖所示:
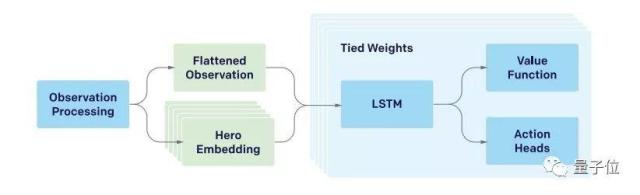
LSTM貢獻了這個模型中84%的參數。
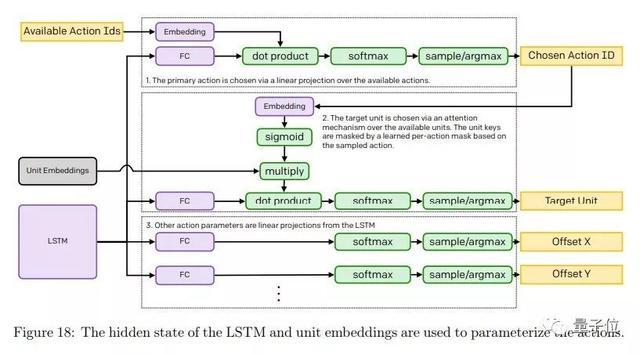
選手們的訓練,使用的是擴展版的近端策略優化(PPO)方法,這也是OpenAI現在默認的強化學習訓練方法。這些智能體的目標是最大化未來獎勵的指數衰減和。
在訓練策略的過程中,OpenAI Five沒有用到人類遊戲數據,而是通過自我博弈。在圍棋、象棋等問題上,也應用了類似的方式訓練。
其中,80%的戰鬥中對手是使用了最新參數的分身,而20%的對手是老參數的分身。每經過10次迭代之後,新訓練出的分身就被標爲老前輩。如果當前正訓練的AI擊敗了新秀或者老前輩,系統就會根據學習率更新參數。
按照OpenAI CTO此前的說法,擊敗OG前OpenAI Five已經練習了相當於45000年Dota。AI每天的訓練量相當於人類打180年遊戲。
要點三:計算量和超參數
訓練這麼複雜的AI系統,肯定要耗費大量的資源。
OpenAI預估了用於優化的GPU消耗量,最後的結論,OpenAI Five的GPU計算用量在770±50~820±50 PFlops/s·days左右,而今天新提到的、更強的Rerun,在隨後兩個月的訓練中,GPU計算量消耗大概是150 ± 5 PFlops/s·days。

再說一下,OpenAI公佈的只是用於優化的計算量,只是訓練中所有開銷的一小部分,大約佔30%。
此前,OpenAI也曾透露過OpenAI Five的日常訓練,需要256塊P100 GPU和12.8萬個CPU核心。
至於整個神經網絡的超參數,在論文中,OpenAI表示在訓練Rerun的時候,已經根據經驗進一步簡化了超參數。最後,他們只更改了四個關鍵的超參數:
• Learning Rate
• Entropy penalty coefficient
• Team Spirit
• GAE time horizon

當然,OpenAI也表示這些超參數還有進一步的優化空間。
要點四:並不全是自學
最後,還有一點需要強調。
OpenAI在論文中明確指出,AI系統在學習Dota2的過程中,並非完全依靠強化學習自學,啓示也使用了一些人類的知識。這跟後來的AlphaGo Zero有所區別。
有一些遊戲機制是腳本編寫好的程序。比方,英雄購買裝備和學習技能的順序,信使的控制等等。OpenAI在論文中表示,使用這些腳本有一些歷史原因,也有成本和時間方面的考慮。不過論文也指出,這些最終也可以通過自學完成。
論文全文

在這篇名爲Dota 2 with Large Scale Deep Reinforcement Learning的論文中,OpenAI公佈了更多的詳細信息,如果你感興趣,下面是傳送門:
https://cdn.openai.com/dota-2.pdf
對戰回顧
最後,我們回顧一下OpenAI Five連下兩局擊敗OG的比賽全程吧。

第一局

AI(天輝):火槍、飛機、冰女、死亡先知、斯溫
人類(夜魘):小牛、巫醫、毒龍、隱刺、影魔
選完陣容,OpenAI Five認爲自己有67.6%的勝率。

剛剛開局,OpenAI Five拿下一血,而人類軍團也很快殺掉了AI方的冰女。之後,雙方前期在人頭數上一直不相上下。AI一直在經濟上保持總體領先,但最富有的英雄,卻一直是人類的大哥影魔。
這也能看出雙方策略上的明顯區別:OG是3核心+2輔助的傳統人類打法,而AI的5個英雄經濟分配相對平均,比較「大鍋飯」。

經過幾番激烈的推進和團戰,遊戲進行到19分鐘左右,AI對自身勝率的預測已經超過了90%。自信心爆棚的AI一鼓作氣攻上了人類的高地。

OG緊接着選擇了分路推進,幾位解說推測,這是爲了儘可能分散AI,防止它們抱團推進,然而並沒有奏效太長時間。
然而,堅持到38分鐘,人類方的小牛剛剛買活,AI的最後一波總攻已經推掉了人類的基地。

OpenAI Five贏下第一局。現場,也是一片掌聲。

這場比賽中,AI展現了清奇的思路:出門裝就選擇兩個大藥,後續的裝備也更傾向於買補給品,而不是提高自身屬性。
另外,我們前邊提到的「大鍋飯」政策,以及在比賽前期就頻繁買活,都和人類職業選手的習慣大不相同。
第二局

AI(天輝):冰女、飛機、斯溫、巫醫、毒龍
人類(夜魘):火槍、小牛、死亡先知、小魚人、萊恩
選完英雄,AI對自身勝率的預測是60.8%,略低於上一局的陣容。
比賽前兩分鐘,雙方都在一片祥和中各自帶線,然而沒想到,人類中單Topson很快就送出了一血。

之後,人類代表們以驚人的速度潰敗。
5分鐘時,AI的信心就已經大幅上升,預測自己有80%的勝率;7分鐘,AI推掉了上路一塔;10分鐘,AI就已經領先人類4000金幣,多推了兩座塔,還爲自己預估了95%的勝率。

11分鐘,AI已經攻上了OG的高地。
僅僅21分鐘,OG的基地被推掉,OpenAI Five輕鬆拿下第二局。直到比賽結束,OG拿下人頭還是個位數,被AI打成了46:6。

雖然這一局贏得異常輕鬆,不過對局過程中還是能看出AI在細節上有一些不足。比如說面對在複雜樹林中繞來繞去的人類,AI就無能爲力。今天的比賽中,Ceb就靠繞樹林救了自己一命。

最後,祝大家週末快樂。
— 完 —