機器學習領域一個最令人着迷的任務,就是訓練機器理解人類交流能力的進步。在機器學習領域,這一分支被稱爲自然語言處理(Natural Language Processing)。
在我們深入研究之前,有必要了解一些基礎知識。
語言是什麼?
計算機如何理解語言?
計算機要處理任何概念,都必須以一種數學模型的形式表達這些概念。
什麼是自然語言處理?
自然語言處理,或簡稱爲NLP,被廣泛地定義爲通過軟件對自然語言(如語音和文本)的自動操作。
基本的轉換
分詞,詞幹提取,詞形還原
由於詞幹提取是基於一組規則發生的,因此詞幹返回的詞根可能並不總是英語單詞。 另一方面,詞形還原可以適當地減少變形詞,確保詞根屬於英語。
N-grams(N元模型)
將一門自然語言分解成n-gram是保持句子中出現的單詞數量的關鍵,而句子是自然語言處理中使用的傳統數學過程的主幹。
轉換方法
TF-IDF
TF-IDF是一種對詞彙進行評分的方式,按照它對句子含義的影響的比例爲單詞提供足夠的權重。得分是兩個獨立評分,詞頻(tf)和逆文件頻率(idf)的乘積。

詞頻(TF):詞頻表示詞語出現在一篇文章中的頻率。
獨熱編碼
獨熱編碼是另一種以數字形式表示詞語的方法。詞語向量的長度等於詞彙表的長度,每一個句子用一個矩陣來表示,行數等於詞彙表的長度,列數等於句子中詞語的數量。詞彙表中的詞語出現在句子中時,詞語向量對應位置的值爲1,否則爲0。
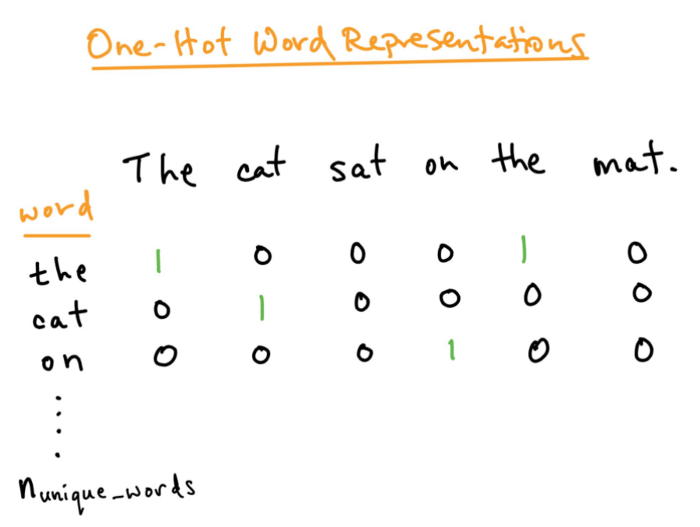
圖片來源 - 谷歌
詞嵌入
爲了便於理解,我們可以將嵌入看作是將每個單詞投射到一個特徵空間,如下圖所示。

每個詞被映射到一個特徵空間裏(性別,王室成員,年齡,食物等)
然而,事實上這些維度並不那麼清楚或便於理解。但由於算法是在維度的數學關係上訓練的,因此這不會產生問題。從訓練和預測的角度來看,維度所代表的內容對於神經網絡來說是沒有意義的。
表示方法
詞袋
詞袋是一種以表格表示數據的方法,其中列表示語料庫的總詞彙表,每一行表示一個觀察。單元格(行和列的交集)表示該特定觀察中的列所代表的單詞數。 它有助於機器用易於理解的矩陣範式理解句子,從而使各種線性代數運算和其他算法能夠應用到數據上,構建預測模型。
下面是醫學期刊文章樣本的詞袋模型示例
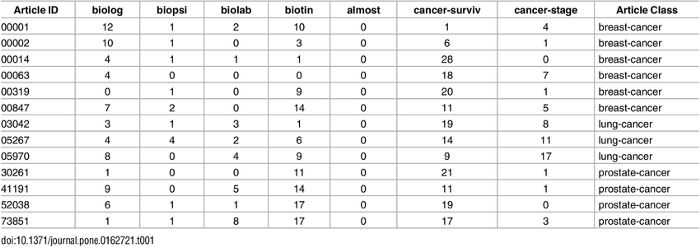
這種表示非常有效,並且負責爲一些最常用的機器學習任務(如垃圾郵件檢測,情感分類器等)生成模型。
-
它忽視了文本的順序/語法,從而失去了單詞的上下文。 -
這種表示方法生成的矩陣非常稀疏,並且更偏向於最常見的單詞。試想,算法主要依賴於單詞的數量,而在語言中,單詞的重要性實際上與出現頻率成反比。頻率較高的詞是更通用的詞,如the,is,an,它們不會顯着改變句子的含義。因此,重要的是適當地衡量這些詞,以反映它們對句子含義的影響。
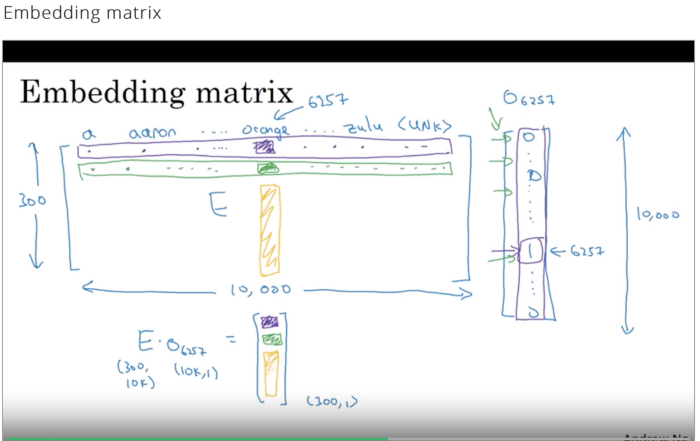
嵌入矩陣
爲了將樣本轉換爲其嵌入形式,將獨熱編碼形式中的每個單詞乘以嵌入矩陣,從而得到樣本的詞嵌入形式。
循環神經網絡(RNN)
循環神經網絡的的標準輸入是一個詞而不是一個完整的樣本,這是概念上與標準神經網絡的不同之處。這給神經網絡提供了能夠處理不同長度句子的靈活性,而這是標準神經網絡無法做到的(由於它固定的結構)。它也提供了一個額外的在不同文本位置共享特徵學習的優勢,而這也是標準神經網絡無法做到的。
循環神經網絡把一個句子的不同單詞在t時刻輸入並且利用t-1時刻的激活值,下面的圖詳細展示了循環神經網絡結構:
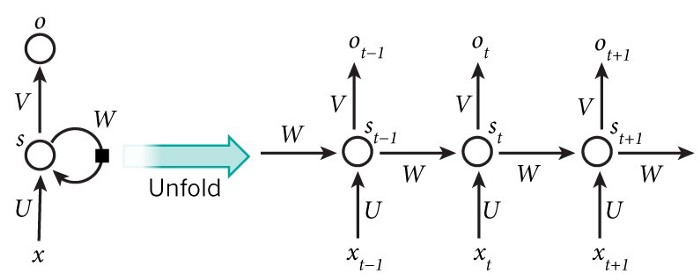
上述結構也被叫做多對多架構,也就是輸入的數量等於輸出的數量。這種結構在序列模型中是非常有用的。
除了上面提到的架構外,還有三種常用的RNN架構。
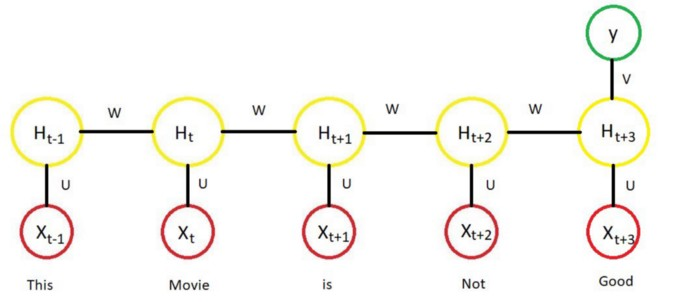
上圖中,H表示激活函數的輸出。
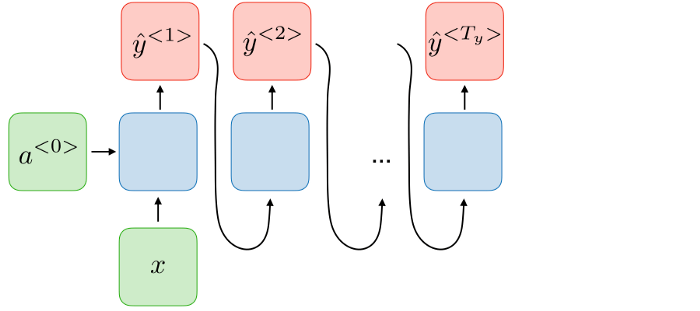
2.一對多的RNN:一對多架構指的是RNN基於單個輸入值生成一系列輸出值的情況。使用這種架構的一個主要示例是音樂生成任務,其中輸入是jounre或第一個音符。
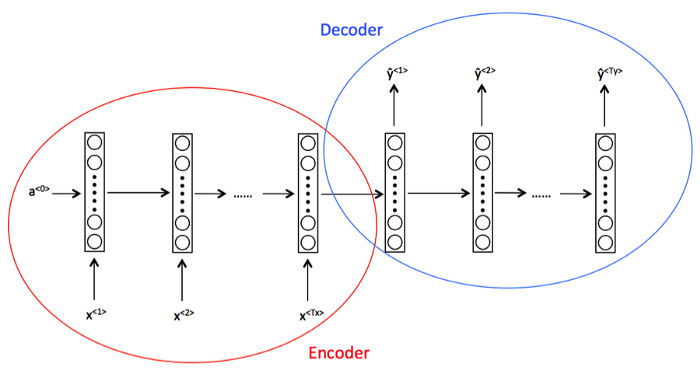
3.多對多(Tx不等於Ty)架構:該架構指的是讀取許多輸入以產生許多輸出的地方,其中,輸入的長度不等於輸出的長度。使用這種架構的一個主要例子是機器翻譯任務。
RNN的侷限性
-
上述RNN架構的示例僅能捕獲語言的一個方向上的依賴關係。基本上,在自然語言處理的情況下,它假定後面的單詞對之前單詞的含義沒有影響。根據我們的語言經驗,我們知道這肯定是不對的。 -
RNN也不能很好地捕捉長期的依賴關係,梯度消失的問題在RNN中再次出現。
門控循環單元(GRU)
它是對基本循環單元的一種修改,有助於捕獲長期的依賴關係,也有助於解決消失梯度問題。
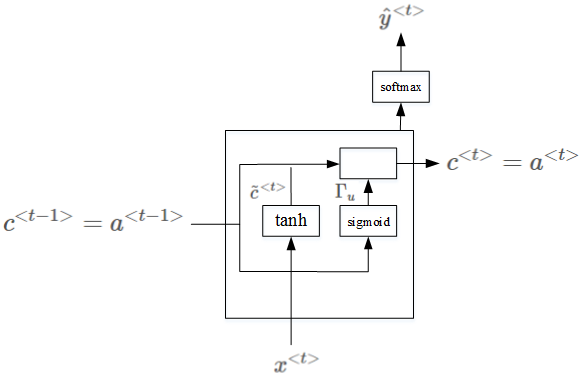
GRU增加了一個額外的存儲單元,通常稱爲更新門或重置門。除了通常的具有sigmoid函數和softmax輸出的神經單元外,它還包含一個額外的單元,tanh作爲激活函數。使用tanh是因爲它的輸出可以是正的也可以是負的,因此可以用於向上和向下伸縮。然後,該單元的輸出與激活輸入相結合,以更新內存單元的值。
因此,在每個步驟中,隱藏單元和存儲單元的值都會被更新。存儲單元中的值在決定傳遞給下一個單元的激活值時起作用。
LSTM
在LSTM架構中,有一個更新門和一個忘記門,而不是像在GRU中那樣只有一個更新門。
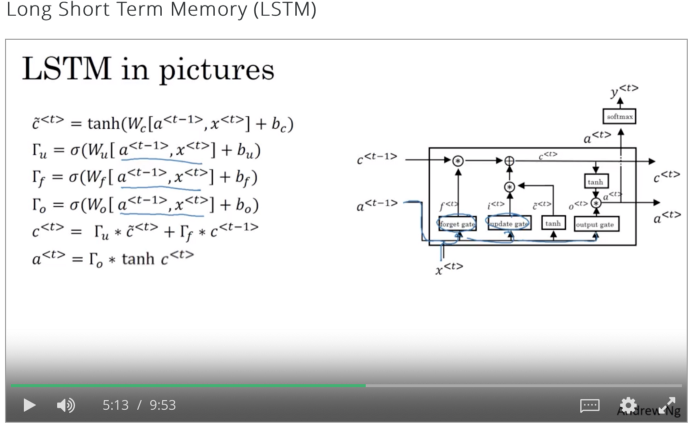
這種架構爲存儲單元提供了一個選項,可以保留t-1時刻的舊值,並將t時刻向其添加值。
關於LSTM的更詳細的解釋,請訪問:http://colah.github.io/posts/2015-08-explanation – lstms/
雙向RNN
在上述RNN架構中,僅考慮以前時間戳出現的影響。在NLP中,這意味着它只考慮了當前單詞出現之前的單詞的影響。但在語言結構中,情況並非如此,因此靠雙向RNN來拯救。
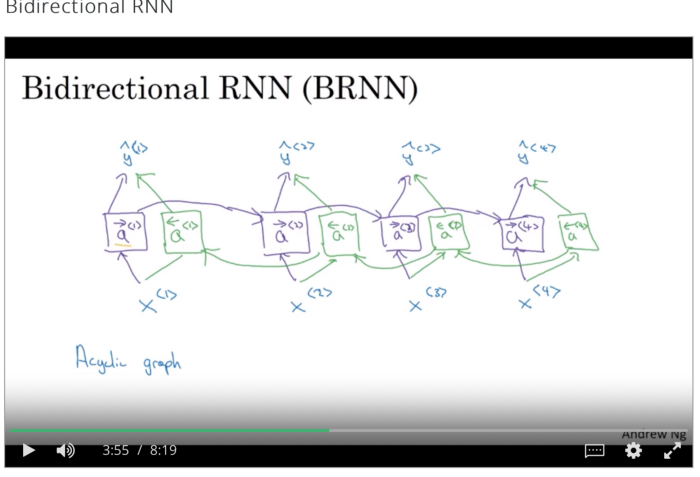
雙向RNN由前向和後向循環神經網絡組成,並結合兩個網絡在任意給定時間t的結果進行最終預測,如圖所示。
在這篇文章中,我試圖涵蓋自然語言處理領域中所有流行的相關實踐和神經網絡架構。對於那些對深入瞭解神經網絡感興趣的人,我強烈建議你們去 Coursera 上 Andrew Ng 的課程。
想要查看相關文獻和參考內容?
點擊【從基礎到 RNN 和 LSTM,NLP 取得的進展都有哪些?】即可訪問~
你可能錯過了這些企業的秋招信息,新增B站、美團、攜程、網易等(持續更新中...)
自今天開始,AI研習社會定期蒐集並推送各大名企校招崗位和內推信息,同時也會邀請求職成功者和企業人力專家分享求職經驗。另外,我們會在社區職薦版塊更新 AI 企業校招和社招信息,歡迎有志於在 AI 行業發展的應屆畢業生們來 AI 研習社投遞簡歷噢~
點擊鏈接可訪問查看過去一段時間企業校招信息:https://ai.yanxishe.com/page/blogDetail/14121