近日,創新奇智有關少樣本學習(Few-shot Learning)的研究論文《Prototype Rectification for Few-Shot Learning》被全球計算機視覺頂會ECCV 2020接收爲Oral論文,入選率僅2%。
ECCV全稱爲European Conference on Computer Vision(歐洲計算機視覺國際會議),與ICCV和CVPR合稱爲全球計算機視覺三大頂級會議,每兩年舉辦一次。據大會官方介紹,本屆會議共收到5025份有效投稿,共接收1361篇,錄取率爲27%,其中1361篇接收論文裏面,有104篇Oral以及161篇 Spotlight,分別佔比2%和5%,堪稱史上最難ECCV。
創新奇智CTO張發恩表示:「當前的深度學習技術對數據具有極大依賴性,如何減小數據依賴,利用較少的數據取得理想的識別效果成爲當下亟待突破的技術難點。少樣本學習旨在從已有類別的數據中學習先驗知識,然後利用極少的標註數據完成對新類別的識別,打破了樣本數據量的制約,在傳統制造業等樣本普遍缺失的領域具有實用價值,有助於推動AI落地。」
創新奇智本次發表的論文指出,少樣本學習的瓶頸在於數據稀缺引起的偏差,主要包括類內偏差和跨類偏差,並提出相應方法有針對性地減小兩項偏差,該思路經過嚴格的理論證明其合理性,並通過大量實驗證明了方法的有效性,在少樣本學習通用的數據集中達到了最優的結果。
以下爲論文解讀:

(論文初版arXiv地址爲:https://arxiv.org/abs/1911.10713 。 後續Camera Ready版本將於近日更新,補充了更多數據集上的表現。
1、概述
少樣本學習(Few-shot learning)旨在從大量有標註數據的類別中學習到普遍的規律,利用學習到的知識,能夠使用少量的有標註數據(如一張或五張)完成對新類別的識別。原型網絡是少樣本學習中一類非常有效的方法,其針對不同的類別提取出對應的類原型,然後根據樣本與類原型之間的距離進行分類。由於新類別的樣本數量極少,原型網絡所計算出的類原型存在一定的偏差。本文指出了制約原型網絡效果的兩個關鍵因素:類內偏差和跨類偏差,並且提出利用僞標籤的方法減小類內偏差,利用特徵偏移的方法減小跨類偏差,進一步通過理論分析指出原型網絡準確率的理論下界,證明僞標籤的方法可以提高理論下界從而提高整體準確率,最後,實驗結果表明,本文的方法在miniImageNet和tieredImageNet上達到了最高水平的結果。
主要貢獻
本文指出了原型網絡在少樣本學習中的兩項制約因素:類內偏差(intra-class bias)及跨類偏差(cross-class bias)。
本文利用僞標籤和特徵偏移,進行原型校正和減小偏差,簡單有效地提高了少樣本分類的表現。
本文分析了理論下界與樣本數量之間的關係,從而驗證了所提方法的合理性,並給出了偏移量的推導過程。
本文所提出的方法在通用的少樣本數據集miniImageNet和tieredImageNet上達到了最優的結果。
2、方法
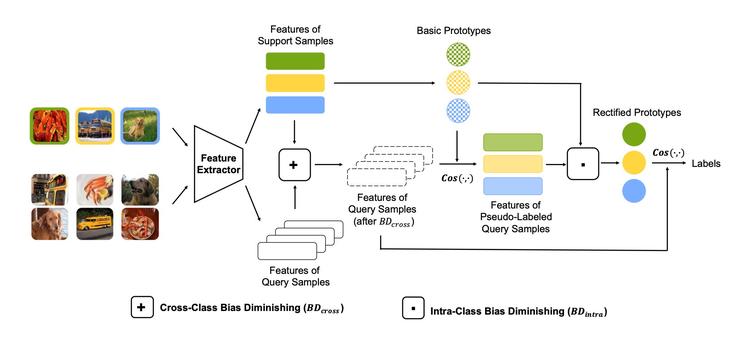
2.1 基於餘弦相似度的原型網絡(CSPN)
本文利用基於餘弦相似度的原型網絡(Cosine Similarity Based Prototypical Network,CSPN)得到少樣本類別(few-shot class)的基礎類原型。
首先在基礎類別(base class)上訓練特徵提取器和餘弦分類器,餘弦分類器定義如下:
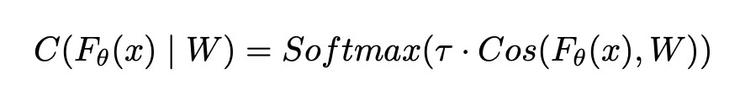
其中Fθ是特徵提取器,W 爲可學習權重,τ爲溫度參數。在模型訓練階段使用如下損失函數:
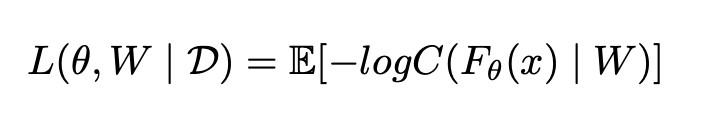
預訓練結束後,使用下式得到few-shot class的基礎類原型:
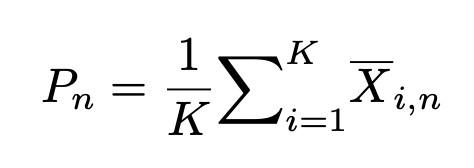
2.2 原型校正中的偏差消除(Bias Diminishing for Prototype Rectification)
在樣本較少的情況下,比如K=1或K=5,計算所得基礎類原型與理想的類原型之間存在一定偏差,減小偏差可以提高類原型的表徵能力,從而提高分類準確率,本文指出如下兩種偏差以及對應的減小偏差的方法。
類內偏差(intra-class bias)
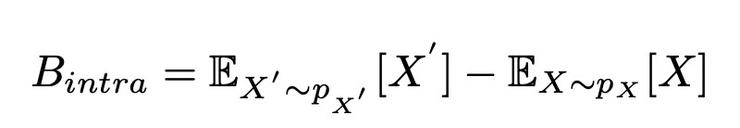
即真實類原型(第一項)和使用少量樣本計算的類原型(第二項)之間的偏差。真實的類原型往往是不可得的,可得的是利用少量有標註的數據集(support set)計算得到的類原型,爲了減小這兩項之間的偏差,本文提出利用無標註的數據集(query set)重新計算類原型。首先通過計算query set中的樣本與基礎類原型之間的餘弦相似度獲得query sample的僞標籤,然後將top-z confident的query sample加入support set中,並根據下式重新計算,得到修正後的類原型P'n:
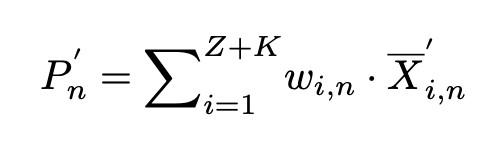
跨類偏差(cross-class bias)
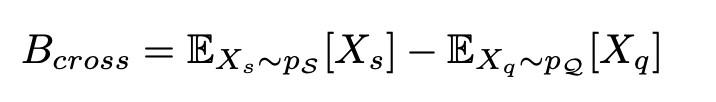
即整個有標註數據集support set和無標註數據集query set之間的偏差。爲了修正跨類偏差,本文在無標註數據中加入偏移量ξ, ξ的具體計算方式如下:
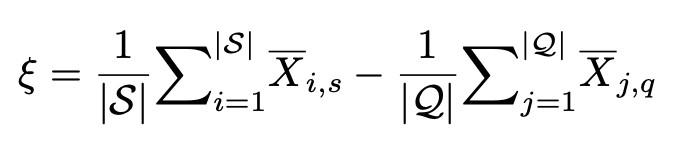
2.3 理論推導Theoretical Analysis
本文通過以下理論推導,解釋了上述方法的合理性以及該方法是如何提高少樣本分類表現的。
理論下界
在原型網絡中,假設最終的準確率與類原型和樣本間餘弦相似度之間呈正相關,即最終優化目標可以表示爲:
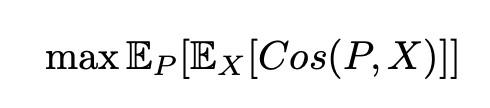
再結合使用一階近似、柯西施瓦茨不等式等方法進行推導驗證,可以得到模型的理論下界:
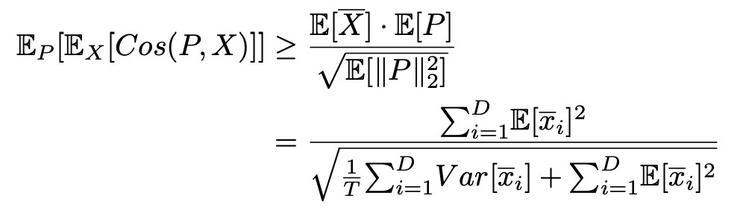
可以看出模型最終效果和樣本數之間呈正相關,因此可以通過引入無標籤樣本來提高模型理論下界,即增大T 可以提高模型表現。
有關偏移量ξ的推導過程詳見論文,在這裏就不敷述了。
3、實驗
3.1實驗結果
本文在少樣本學習的兩個公開數據集 (miniImageNet, tieredImageNet) 上進行了實驗,與其他方法相比,本文提出的BD-CSPN在1-shot及5-shot的設置下均達到了最佳效果。
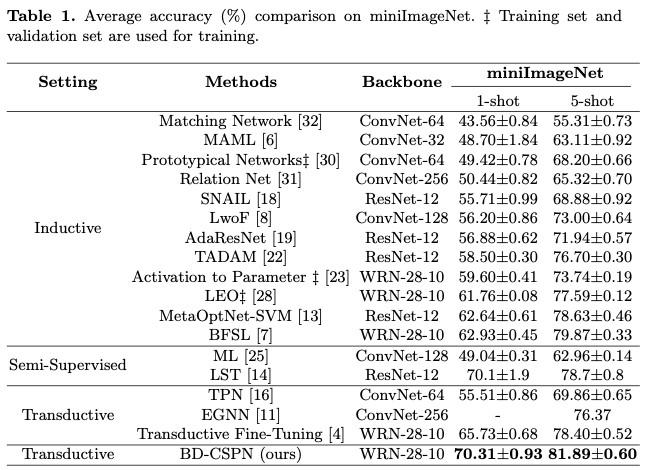
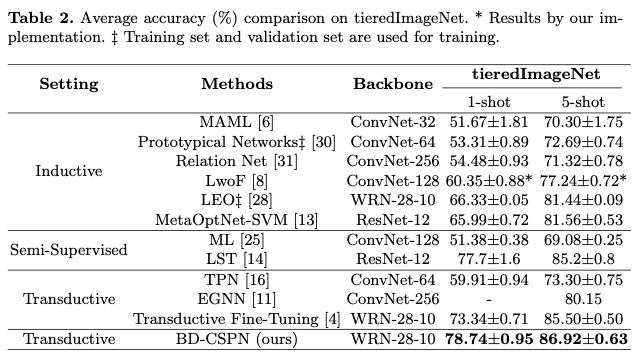
3.2消融實驗
本文通過消融實驗進一步驗證了模型每一部分的有效性。
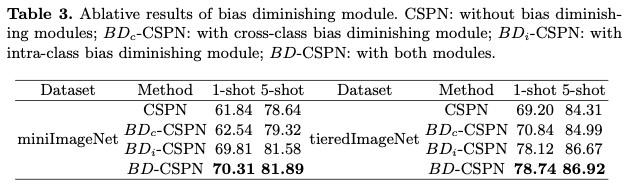
表中從上到下分別爲:不使用原型修正的方法,單獨使用跨類偏差修正,單獨使用類內偏差修正以及同時使用類內偏差和跨類偏差修正的結果,可以看到減小偏差對最終結果有明顯的提升。
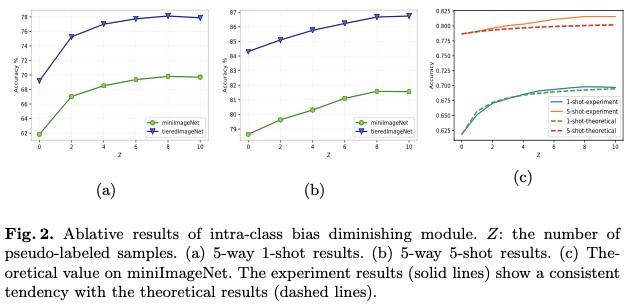
本文進一步分析了原型校正中無標註樣本的樣本數量對於最終結果的影響,如圖2(a-b)所示,隨着無標註樣本的增多最終效果有持續的提升,圖2(c)中虛線爲通過計算所得到的理論下界,可以看到本文的實驗結果和理論相符。
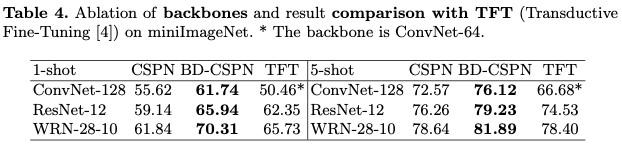
本文采用不同的網絡結構作爲特徵提取器,驗證了原型校正的方法在不同網絡結構下均有明顯提升。
總結
本文提出一種簡單有效的少樣本學習方法,通過減小類內偏差和跨類偏差進行原型校正,從而顯著提高少樣本分類結果,並且給出理論推導證明本文所提方法可以提高理論下界,最終通過實驗表明本方法在通用數據集中達到了最優結果,論文被ECCV 2020 接收爲Oral。本文中提出的算法已經在創新奇智的實際場景中落地應用,可以從海量非結構化數據中根據極少數種子數據(1張至5張)挖掘出所需要的同類數據,可以極大的提升數據收集速度和準確率,降低成本。
雷鋒網雷鋒網(公衆號:雷鋒網)