語境信息對 BERT 非常重要,它利用遮蔽語言模型(masked language model,MLM)允許表徵融合左右兩側的語境,從而預訓練深度雙向 Transformer。
Hinton 舉了一個例子:「She scromed him with the frying pan」。在這個句子中,即使你不知道 scromed 的意思,也可以根據上下文語境進行推斷。
視覺領域也是如此。然而,
BERT 這類方法無法很好地應用到視覺領域,因爲網絡最深層需要編碼圖像的細節。
經過訓練,Hinton 指出唯一的空間一致性特徵是「不一致性」(The Only Spatially Coherent Property is Disparity),所以這也是必須要提取出來的。
他表示這種最大化互信息的方法存在一個棘手的問題,並做出以下假設,即如果只學習線性映射,並且對線性函數進行優化,則變量將成爲分佈式的。不過,這種假設並不會導致太多問題。
以往研究方法回顧
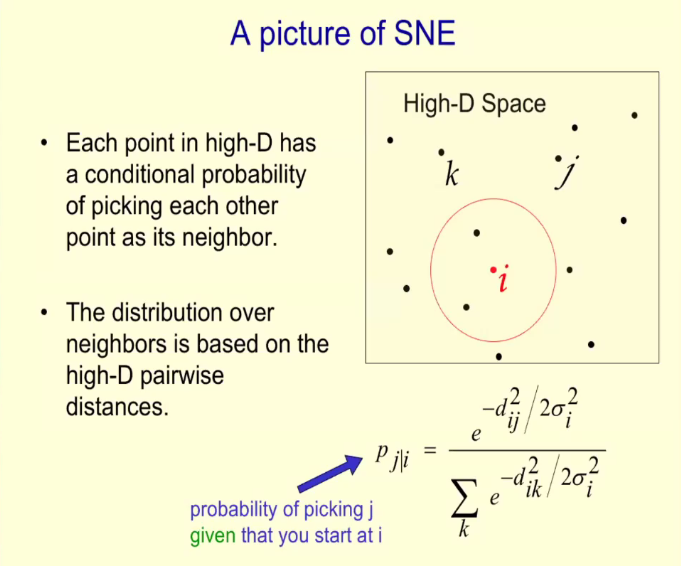
在這部分中,Hinton 先後介紹了 LLE、LRE、SNE、t-SNE 等方法。
局部線性嵌入方法(Locally Linear Embedding, LLE)
Hinton 介紹了 Sam T. Roweis 和 Lawrence K. Saul 在 2000 年 Science 論文《Nonlinear Dimensionality Reduction by Locally Linear Embedding》中提到的局部線性嵌入方法,該方法可以在二維圖中顯示高維數據點,並且使得非常相似的數據點彼此捱得很近。
但需要注意的是,LLE 方法會導致數據點重疊交融(curdling)和維度崩潰(dimension collapse)問題。
下圖爲 MNIST 數據集中數字的局部線性嵌入圖,其中每種顏色代表不同的數字: