簡單回顧的話,2006年Geoffrey Hinton的論文點燃了「這把火」,現在已經有不少人開始潑「冷水」了,主要是AI泡沫太大,而且深度學習不是包治百病的藥方。
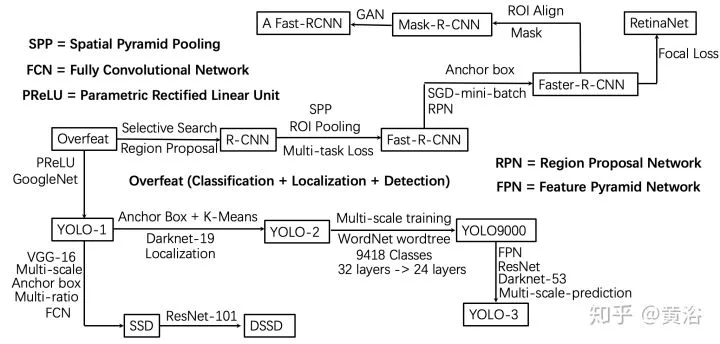
計算機視覺不是深度學習最早看到突破的領域,真正讓大家大吃一驚的顛覆傳統方法的應用領域是語音識別,做出來的公司是微軟,而不是當時如日中天的谷歌。計算機視覺應用深度學習堪稱突破的成功點是2012年ImageNet比賽,採用的模型是CNN,而不是Hinton搞的RBM和DBN之類,就是Hinton學生做出來以他命名的AlexNet。
(注:順便提一下,2010年的ImageNet冠軍是餘凱/林元慶領導的NEC和UIUC Tom Huang組的合作團隊,當時採用的方法是基於sparse coding+SVM。)
-
AlexNet應該算第一個深度CNN; -
ZFNet採用DeconvNet和visualization技術可以監控學習過程; -
VGGNet採用小濾波器3X3去取代大濾波器5X5和7X7而降低計算複雜度; -
GoogleNet推廣NIN的思路定義Inception基本模塊(採用多尺度變換和不同大小濾波器組合,即1X1,3X3,5X5)構建模型; -
Highway Networks借鑑了RNN裏面LSTM的gaiting單元; -
ResNet是革命性的工作,借鑑了Highway Networks的skip connection想法,可以訓練大深度的模型提升性能,計算複雜度變小; -
Inception-V3/4用1X7和1X5取代大濾波器5X5和7X7,1X1濾波器做之前的特徵瓶頸,這樣卷積操作變成像跨通道(cross channel)的相關操作; -
DenseNet主要通過跨層鏈接解決vanishing gradient問題; -
SE-Net是針對特徵選擇的設計,gating機制還是被採用; -
前段時間流行的Attention機制也是借鑑於LSTM,實現object-aware的context模型。 -
......
在具體應用領域也出現了不少成功的模型,比如:
-
detection問題的R-CNN,fast RCNN,faster RCNN,SSD,YOLO,RetinaNet,CornerNet等, -
解決segmentation問題的FCN,DeepLab,Parsenet,Segnet,Mask R-CNN,RefineNet,PSPNet,U-Net等, -
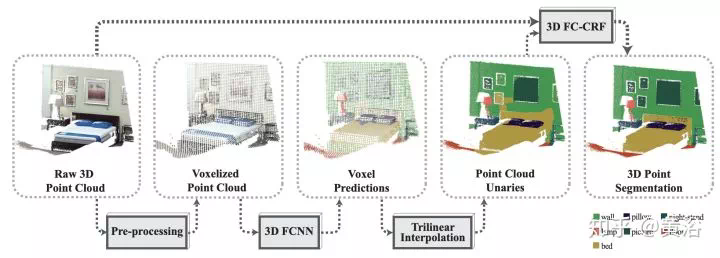
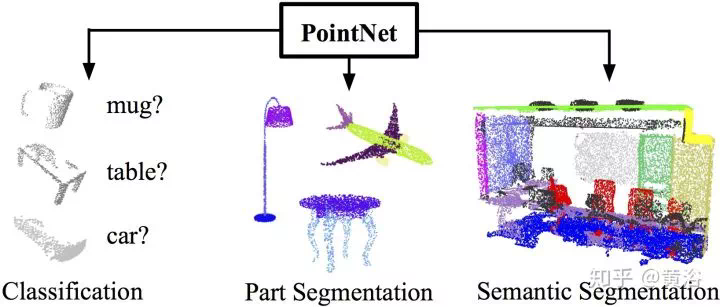
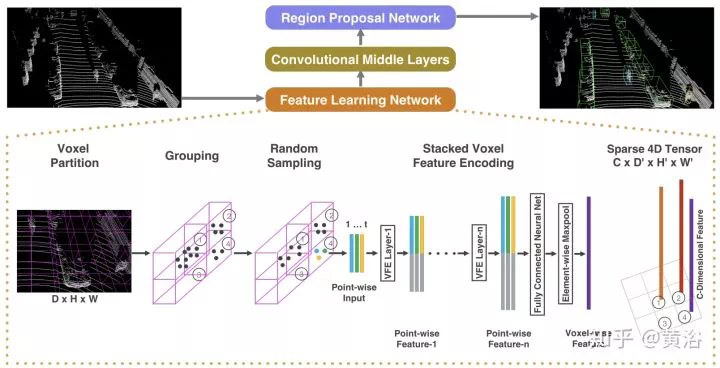
處理激光雷達點雲數據的VoxelNet,PointNet,BirdNet,LMNet,RT3D,PIXOR,YOLO3D等, -
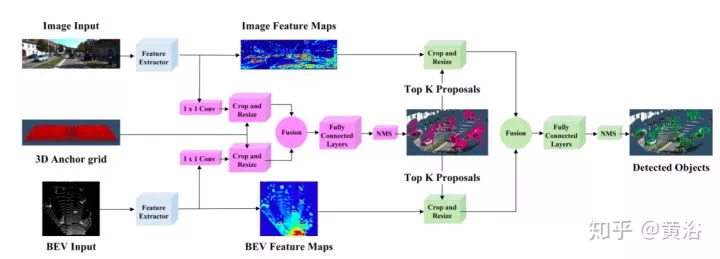
實現激光雷達和圖像融合的PointFusion,RoarNet,PointRCNN,AVOD等, -
做圖像處理的DeHazeNet,SRCNN (super-resolution),DeepContour,DeepEdge等, -
2.5 D視覺的MatchNet,DeepFlow,FlowNet等, -
3-D重建的PoseNet,VINet,Perspective Transformer Net,SfMNet,CNN-SLAM,SurfaceNet,3D-R2N2,MVSNet等, -
以及解決模型壓縮精簡的MobileNet,ShuffleNet,EffNet,SqueezeNet, ......
下面我們針對具體應用再仔細聊。
圖像/視頻處理
先說圖像/視頻處理(計算機視覺的底層,不低級)。
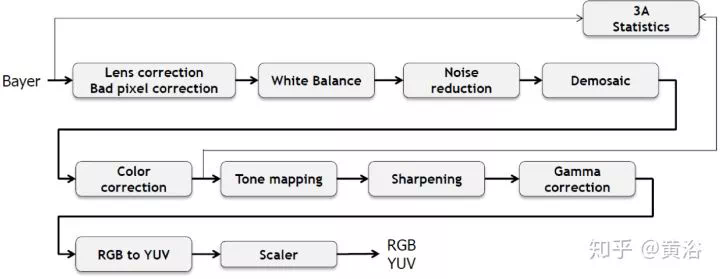
這是一個典型成像處理的流程圖:

先給出一個encoder-decoder network的AR-CNN模型(AR=Artifact Reduction):

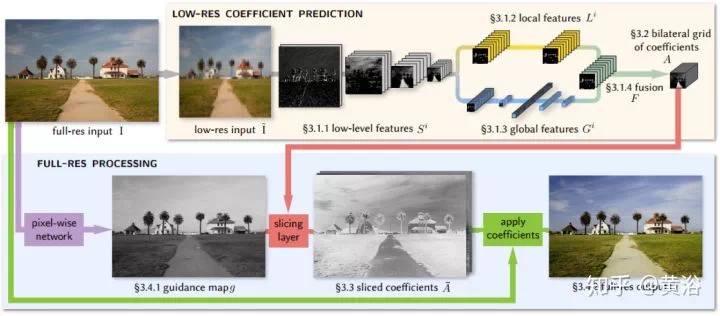
Bilateral filter是很有名的圖像濾波器,這裏先給出一個受此啓發的CNN模型做圖像增強的例子:
用於修補的基於GAN思想的Encoder-Decoder Network模型:


還有計算機視覺的預處理(2-D)。
1、特徵提取
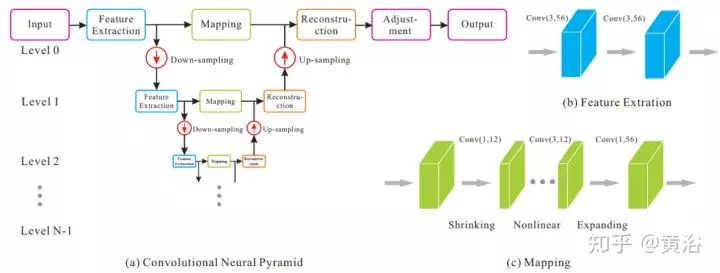
一個輪廓檢測的encoder-decoder network模型:

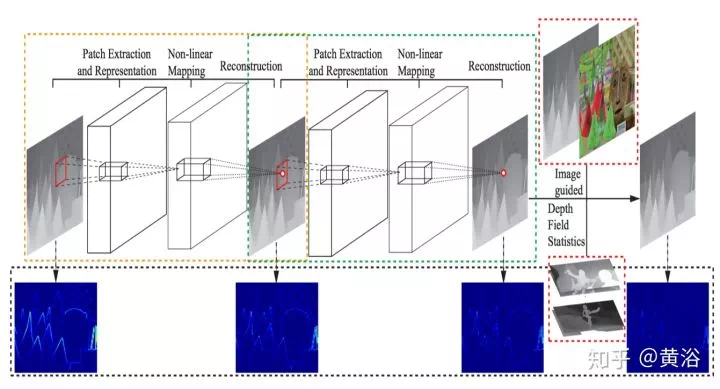
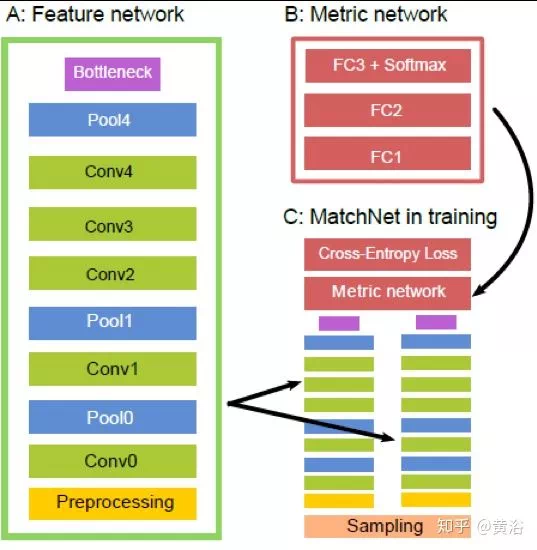
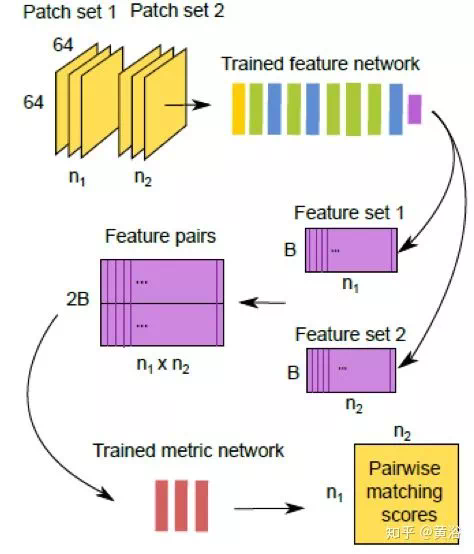
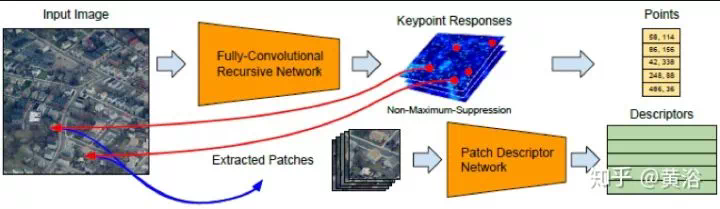
這裏給出一個做匹配的模型MatchNet:
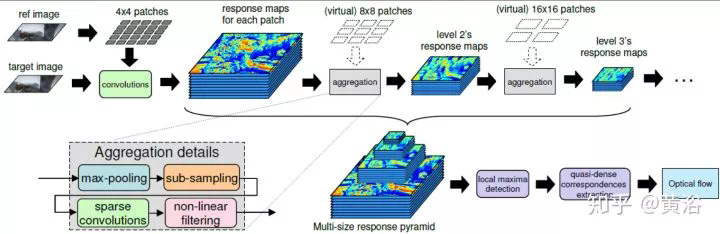
2.5-D計算機視覺
再說2.5-D計算機視覺部分(不是全3-D)。
可以說深度學習是相當「暴力」的,以前分析的什麼約束呀,先驗知識呀在這裏統統扔一邊,只要有圖像數據就可以和傳統機器學習方法拼一把。
傳統的方法包括局部法和全局法,這裏CNN取代的就是全局法。
2、視差/深度圖估計
深度圖估計和運動估計是類似問題,唯一不同的是單目可以估計深度圖,而運動不行。
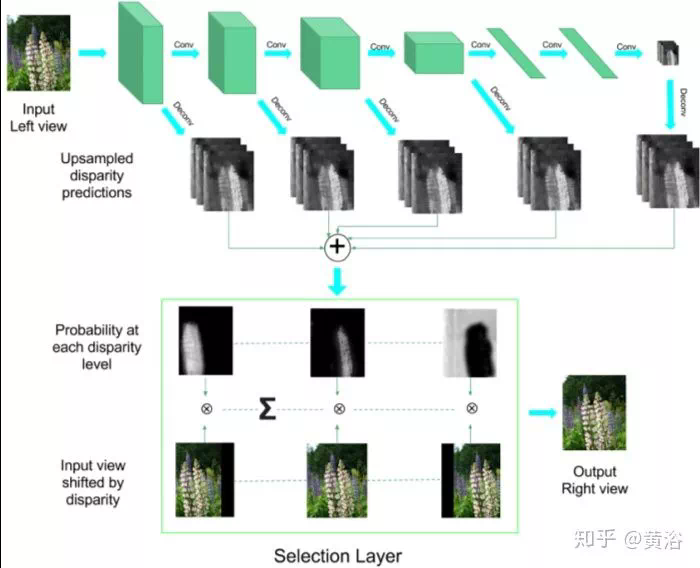
這裏是一個雙目估計深度圖的模型:
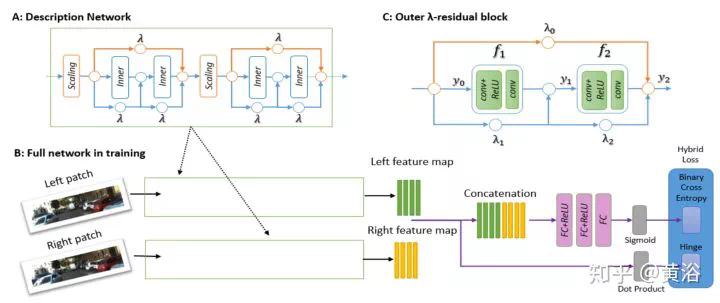

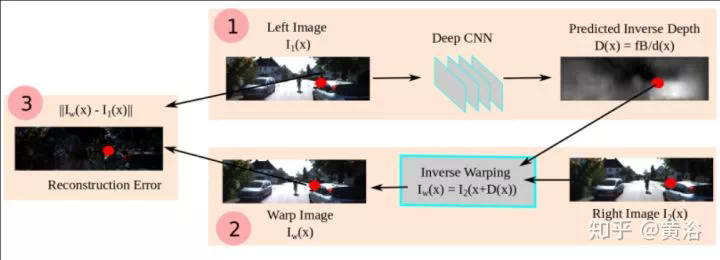



剛纔介紹單目估計深度圖的時候,其實已經看到採用inverse warping方法做新視角生成的例子,在IBR領域這裏有一個分支叫Depth Image-based Rendering (DIBR)。
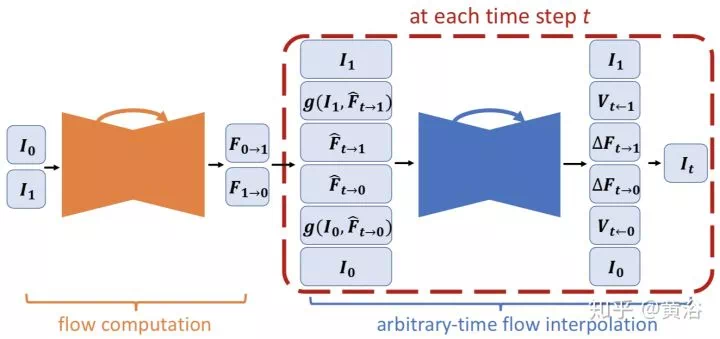
這是一個產生新視角的模型:

3-D計算機視覺
下面談談3-D,基於多視角(MVS)/運動(SFM)的重建,後者也叫SLAM。
基本上可以分成兩種路徑:一是多視角重建,二是運動重建。前一個有一個經典的方法MVS(multiple view stereo),就是多幀匹配,是雙目匹配的推廣,這樣採用CNN來解決也合理。當年CMU在Superbowl展示的三維重建和視角轉化,轟動一時,就是基於此路徑,但最終沒有被產品化(技術已經轉讓了)。
想想像特徵點匹配,幀間運動估計,Loop Closure檢測這些模塊都可以採用CNN模型解決,那麼SLAM/SFM/VO就進入CNN的探索區域。
1、標定
Calibration是計算機視覺的經典問題,攝像頭作爲傳感器的視覺系統首要任務就是要確定自己觀測數據和3-D世界座標系的關係,即標定。攝像頭標定要確定兩部分參數,一是內參數,二是外參數。對於有多個傳感器的視覺系統,比如深度測距儀,以前有Kinect RGB-D,現在有Velodyne激光雷達,它們相互之間的座標系關係是標定的任務。
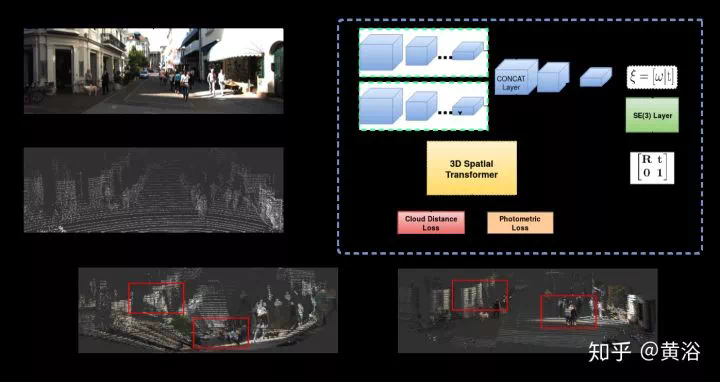
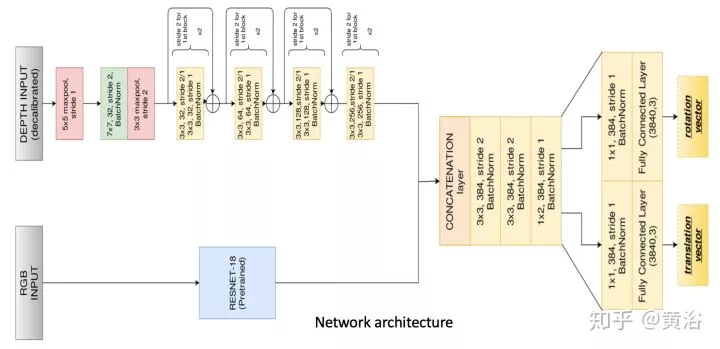
2、Visual Odometry(VO)
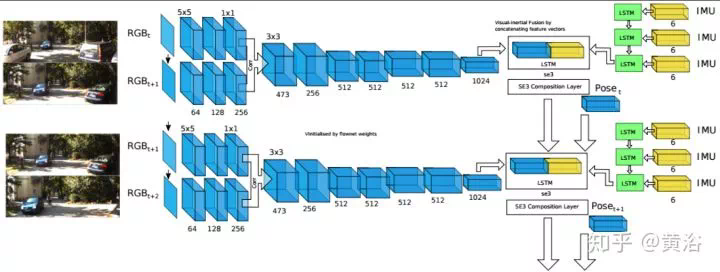



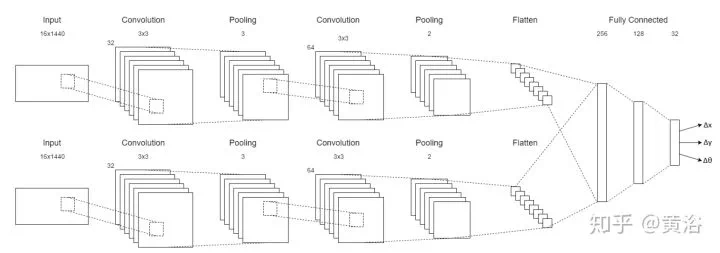
運動恢復結構是基於背景不動的前提,計算機視覺的同行喜歡SFM這個術語,而機器人的peers稱之爲SLAM。SLAM比較看重工程化的解決方案,SFM理論上貢獻大。
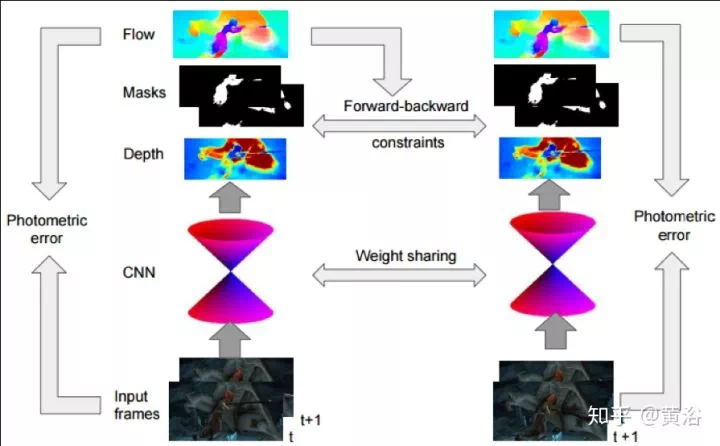
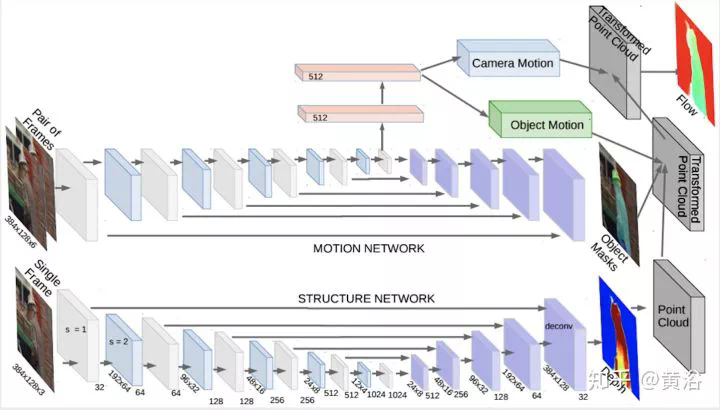
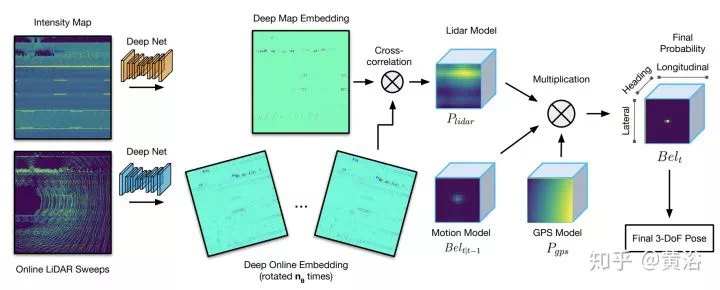
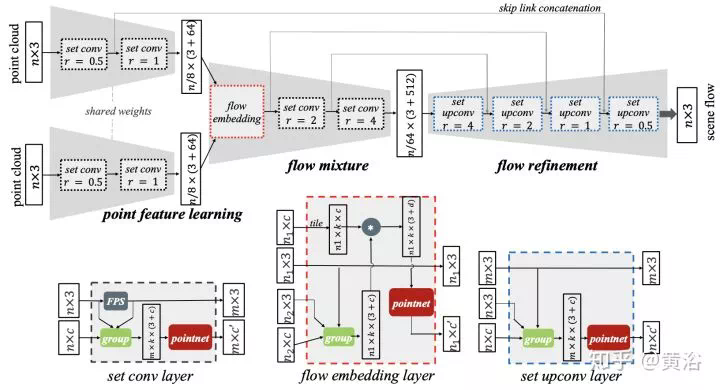
MVS的傳統方法可以分成兩種:region growing和depth-fusion,前者有著名的PMVS,後者有KinectFusion,CNN模型求解MVS的方法就是基於此。


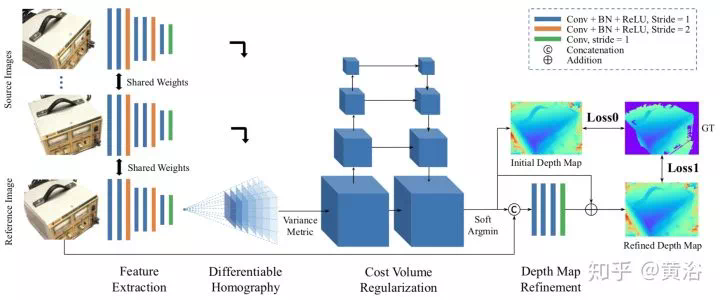
環境理解
核心部分是計算機視覺的高層。
這部分是深度學習在計算機視覺最先觸及,並展示強大實力的部分。出色的工作太多,是大家關注和追捧的,而且有不少分析和總結文章,所以這裏不會重複過多,只簡單回顧一下。
1、語義分割/實例分割(Semantic/Instance Segmentation)
語義分割最早成功應用CNN的模型應該是FCN(Fully Convolution Network),由Berkeley分校的研究人員提出。它是一種pixel2pixel的學習方法,之後各種演變模型,現在都可以把它們歸類於Encoder-Decoder Network。
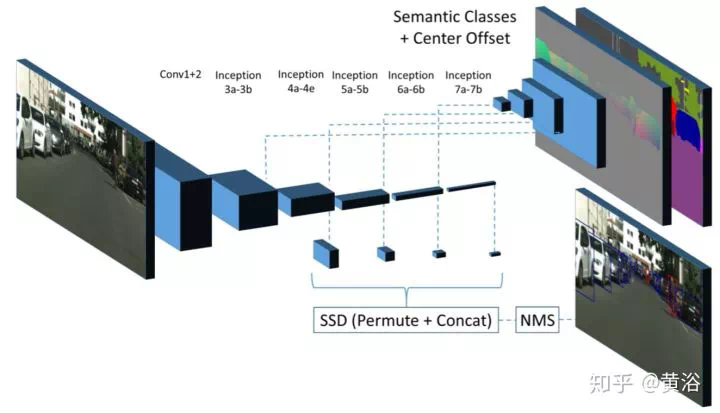
這是一個借鑑目標檢測算法SSD的實例分割模型。
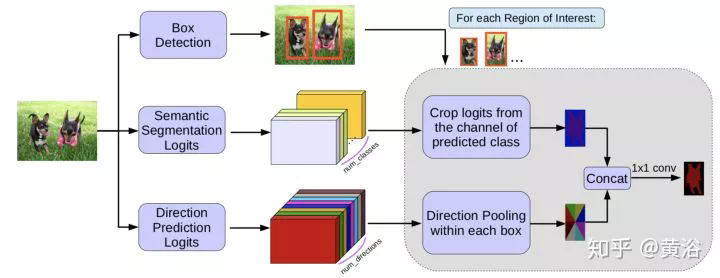
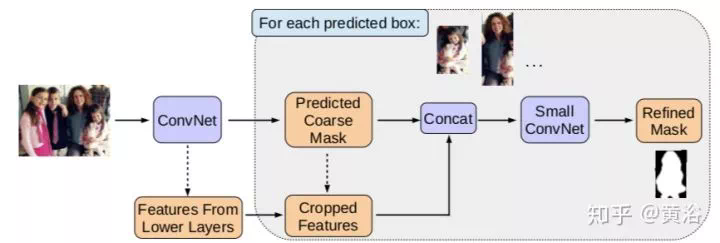
目標檢測的開拓性工作應該是Berkeley分校Malik組出來的,即兩步法的R-CNN(Region-based CNN),借用了傳統方法中的Region Proposal。之後不斷改進的有fast RCNN和faster RCNN,每次都有新點子,真是「羣星閃耀」的感覺。
一步法的工作,有名的就是SSD(Single Shot Detection)和YOLO(You Only Look Once),期間何凱明針對one-stage和two-stage方法的各自優缺點引進一個Focal Loss,構建的新方法叫RetinaNet,而後來YOLO3基本也解決了精度低的弱點。
激光雷達點雲數據的處理,無論識別還是分割,有PointNet以及改進的CNN模型。
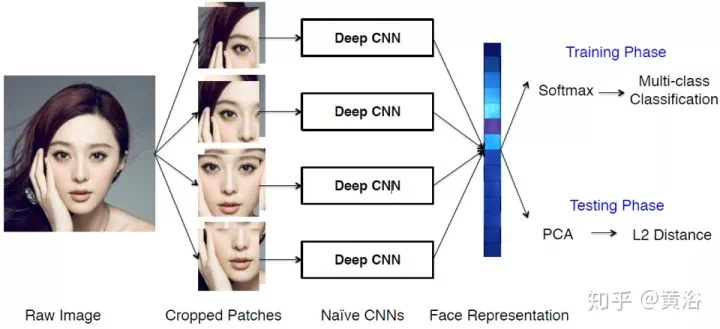
請注意,人臉識別分人臉驗證(face verification)和人臉確認(face identification);前者是指兩個人是不是同一個人,1-to-1 mapping,而後者是確定一個人是一羣人中的某個,1-to-many ampping。以前經常有報道機器的人臉識別比人強了,都是指前者,假如後者的話,那誰能像機器一樣識別上萬人的人臉數據庫呢?何況中國公安部的數據高達億的數量級。
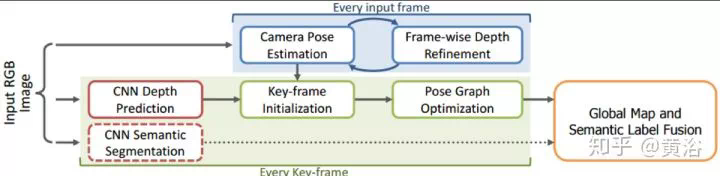
一個完整的人臉識別系統,需要完成人臉檢測和人臉校準(face alignment),而後者是需要人臉關鍵點(facial landmarks)的檢測,也是可以基於CNN模型來做。這裏以FB的DeepFace模型爲例吧,給出一個人臉識別的系統框圖:

這是不久前剛剛提出的人臉檢測模型:Selective Refinement Network

而這裏給出一個基於facial landmarks做校準的模型:
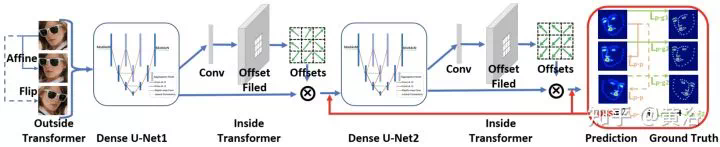
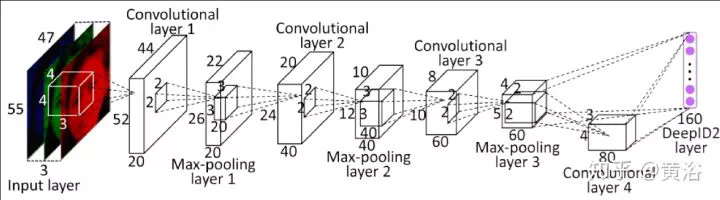
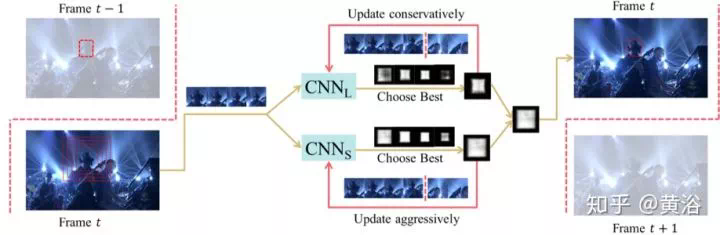
3、跟蹤(特別例子:人體姿態/骨架)
目標跟蹤是一個遞推估計問題,根據以前的圖像幀目標的信息推算當前目標的位置甚至大小/姿態。有一陣子,跟蹤和檢測變得渾爲一體,即所謂tracking by detection,跟蹤也可以看出一個目標分割(前後景而言)/識別問題。
跟蹤是短時(short term)鄰域的檢測,而一般的檢測是長時(long term)大範圍的檢測。跟蹤的困難在於目標的遮擋(分部分還是全部),背景複雜(相似目標存在),快速(fast)以及突變(agile)運動等等。比如,跟蹤人臉,當轉90度成側臉時就會有以上這些問題。
跟蹤方法有一個需要區分的點,多目標(MOT)還是單目標(SOT)跟蹤器。單目標不會考慮目標之間的干擾和耦合,而多目標跟蹤會考慮目標的出現,消失以及相互交互和制約,保證跟蹤各個目標的唯一性是算法設計的前提。
跟蹤目標是多樣的,一般是考慮剛體還是柔體,是考慮單剛體還是鉸接式(articulated),比如人體或者手指運動,需要確定skeleton模型。跟蹤可以是基於圖像的,或者激光雷達點雲的,前者還要考慮目標在圖像中大小的變化,姿態的變化,難度更大。
基於以上特點,跟蹤可以用CNN或者RNN模型求解,跟蹤目標的描述本身就是NN模型的優勢,檢測也罷,分割或者識別也罷,都不是問題。運動特性的描述也可以借鑑RNN模型,不過目前看到的結果這部分不比傳統方法好多少。




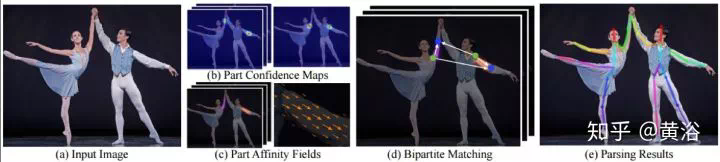
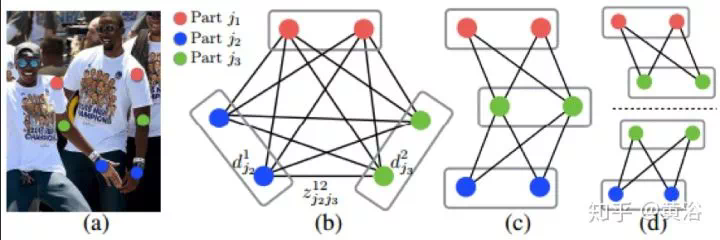
最近CMU提出一個方法,基於Part Affinity Fields(PAF)來估計人體姿態和骨架,速度非常快。PAF是一個非參數描述模型,用來將圖像像素和人體各肢體相關起來,看它的架構如圖,採用的是two branch CNN結構,聯合學習各肢體的相關性和位置。
四大領域應用
最後一下計算機視覺的推動領域。
後來有了SIFT,用了Information Retrieval的概念Bag of Words,加上inverted Indexing,TF-IDF(term frequency–inverse document frequency),hashing之類的技術變得好多了,每年ACM MM會議上一堆的paper。深度學習進來,主要就是扮演特徵描述的角色。


AR一開始就不好做,不說VR那部分的問題,主要是實時性要求高,無論識別還是運動/姿態估計,精度都不好。現在計算機硬件發展了,計算速度提高了,加上深度學習讓識別變得落地容易了,最近越來越熱,無論是姿態估計還是特徵匹配(定位),都變得容易些了。希望這次能真正對社會帶來衝擊,把那些AR的夢想都實現。
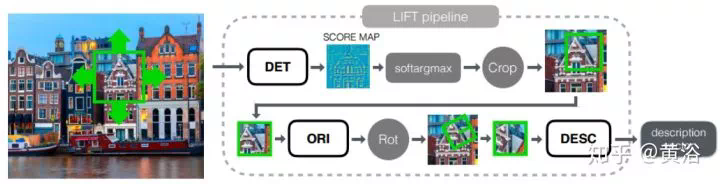
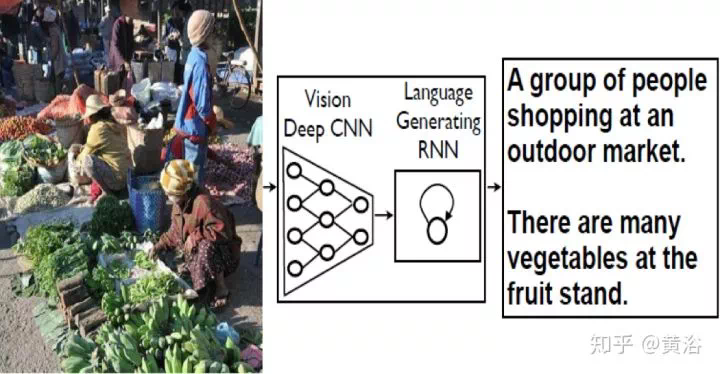
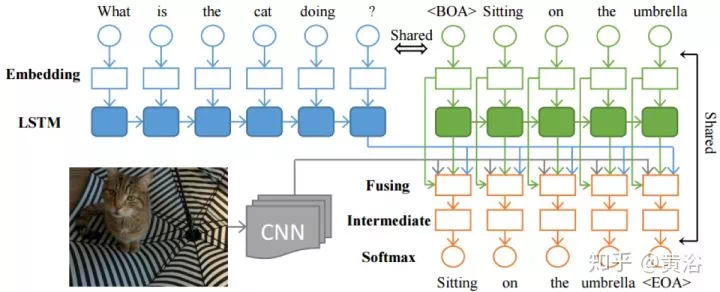
Captioning是計算機視覺和NLP的結合。你可以把它當成一個「檢索」任務,也可以說是一個「翻譯」工作。深度學習,就是來幫助建立一個語言模型並取樣產生描述。


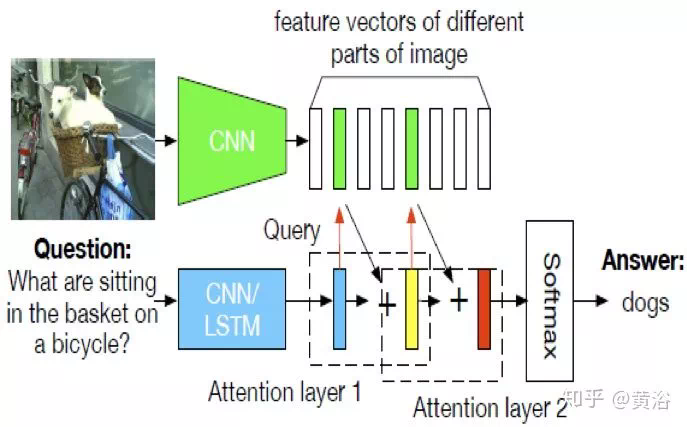
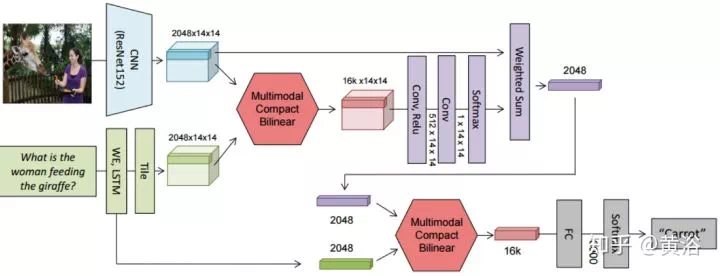
4、內容問答(Q&A)
原文鏈接:
https://zhuanlan.zhihu.com/p/55747295