作者:Kamil KaczmarekICLR 2020會議的16篇最佳深度學習論文
編譯:ronghuaiyang
原文鏈接:

給大家介紹一下今年的ICLR上的最佳16篇深度學習論文。

上週,我很榮幸地參加了學習表現國際會議(ICLR),這是一個致力於深度學習各方面研究的活動。最初,會議本應在埃塞俄比亞首Addis Ababa召開,但由於新型冠狀病毒大流行,會議變成了虛擬會議。把活動搬到網上對組織者來說是一個挑戰,但是我認爲效果非常令人滿意!
1300多名演講者和5600名與會者證明,虛擬形式更容易爲公衆所接受,但與此同時,會議保持了互動和參與。從許多有趣的演講中,我決定選擇16個,這些演講既有影響力又發人深省。以下是來自ICLR的最佳深度學習論文。
1. On Robustness of Neural Ordinary Differential Equations
2. Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity
3. Target-Embedding Autoencoders for Supervised Representation Learning
4. Understanding and Robustifying Differentiable Architecture Search
5. Comparing Rewinding and Fine-tuning in Neural Network Pruning
6. Neural Arithmetic Units
7.The Break-Even Point on Optimization Trajectories of Deep Neural Networks
8. Hoppity: Learning Graph Transformations To Detect And Fix Bugs In Programs
9. Selection via Proxy: Efficient Data Selection for Deep Learning
10. And the Bit Goes Down: Revisiting the Quantization of Neural Networks
11. A Signal Propagation Perspective for Pruning Neural Networks at Initialization
12. Deep Semi-Supervised Anomaly Detection
13. Multi-Scale Representation Learning for Spatial Feature Distributions using Grid Cells
14. Federated Learning with Matched Averaging
15. Chameleon: Adaptive Code Optimization for Expedited Deep Neural Network Compilation
16. Network Deconvolution
最佳深度學習論文
1. On Robustness of Neural Ordinary Differential Equations
深入研究了神經常微分方程或神經網絡的魯棒性。使用它作爲構建更健壯的網絡的基礎。
論文:https://openreview.net/forum?id=B1e9Y2NYvS

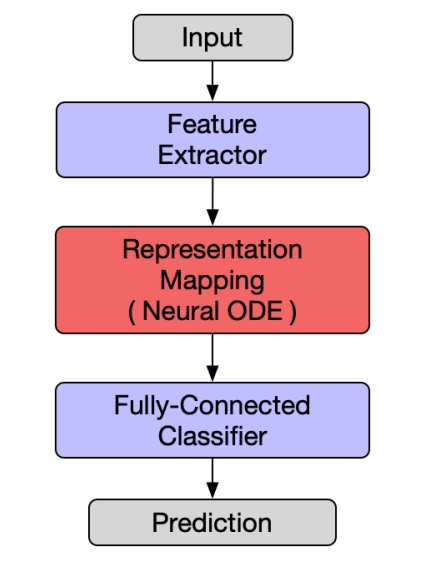
ODENet的結構,神經ODE塊作爲一個保維非線性映射。

2. Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity
證明梯度裁剪可加速非光滑非凸函數的梯度下降。
論文:https://openreview.net/forum?id=BJgnXpVYwS
代碼:https://github.com/JingzhaoZhang/why-clipping-accelerates

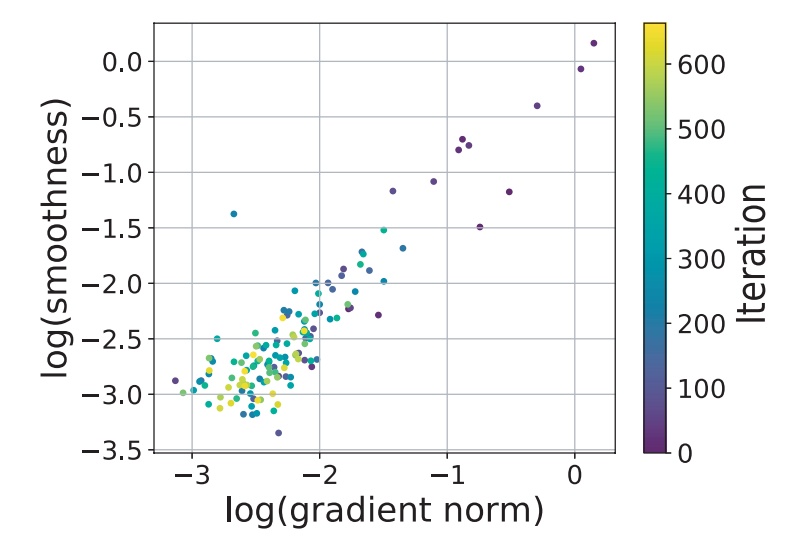
PTB數據集上AWD-LSTM (Merity et al., 2018)訓練軌跡上的對數尺度上的梯度範數vs局部梯度Lipschitz常數。顏色條表示在訓練過程中迭代的次數。
第一作者:Jingzhao Zhang
3. Target-Embedding Autoencoders for Supervised Representation Learning
新的,通用目標嵌入自動編碼器或者說TEA監督預測框架。作者給出了理論和經驗的考慮。
論文:https://openreview.net/forum?id=BygXFkSYDH
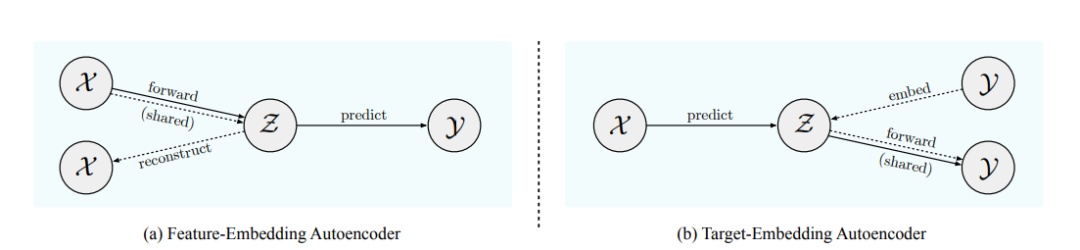
(a)特徵嵌入和(b)目標嵌入自動編碼器。實線對應於(主要)預測任務,虛線爲(輔助)重建任務。兩者都涉及到共享組件。

4. Understanding and Robustifying Differentiable Architecture Search
通過分析驗證損失的海塞矩陣的特徵值,研究了DARTS(可微結構搜索)的失效模式,並在此基礎上提出了相應的對策。
論文:https://openreview.net/forum?id=H1gDNyrKDS
代碼:https://github.com/automl/RobustDARTS
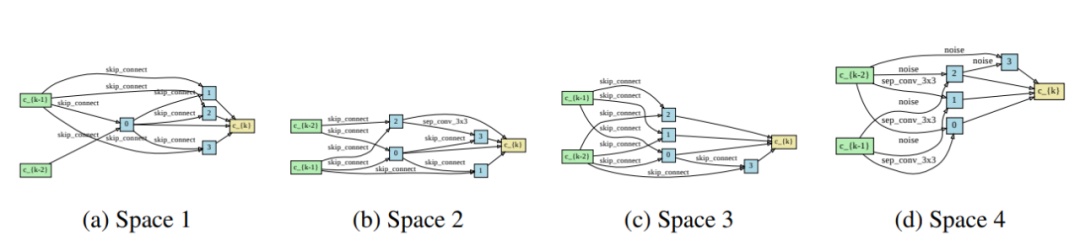
在Space1到Space4上,DARTS發現的差的網格標準。對於所有的空間,DARTS選擇的大多是無參數的操作(跳過連接),甚至是有害的噪聲操作。

5. Comparing Rewinding and Fine-tuning in Neural Network Pruning
在修剪神經網絡時,不需要在修剪後進行微調,而是將權值或學習率策略倒回到它們在訓練時的值,然後再從那裏進行再訓練,以達到更高的準確性。
論文:https://openreview.net/forum?id=S1gSj0NKvB
代碼:https://github.com/lottery-ticket/rewinding-iclr20-public
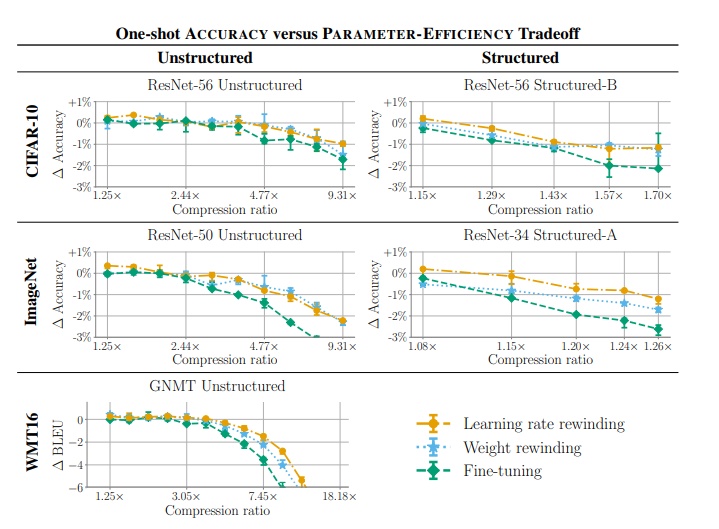
通過一次修剪獲得再訓練時間的最佳可達到的精度。

第一作者:Alex Renda
6. Neural Arithmetic Units
神經網絡雖然能夠逼近複雜的函數,但在精確的算術運算方面卻很差。這項任務對深度學習研究者來說是一個長期的挑戰。在這裏,我們介紹了新的神經加法單元(NAU)和神經乘法單元(NMU),它們能夠執行精確的加法/減法(NAU)和向量子集乘法(MNU)。
論文:https://openreview.net/forum?id=H1gNOeHKPS
代碼:https://github.com/AndreasMadsen/stable-nalu

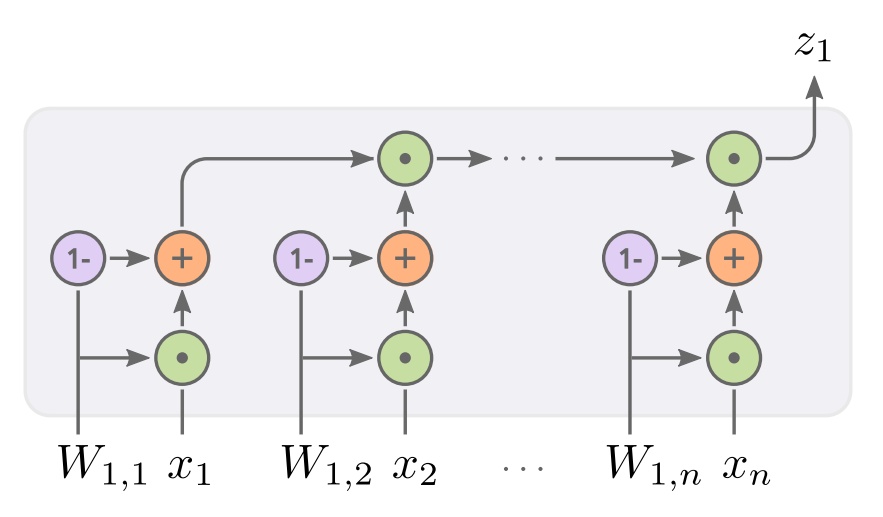
NMU的可視化,其中權值(Wi,j)控制門控的值1(identity)或xi,然後顯式地乘上每個中間結果以形成zj。

7. The Break-Even Point on Optimization Trajectories of Deep Neural Networks
在深度神經網絡訓練的早期階段,存在一個決定整個優化軌跡性質的「均衡點」。
論文:https://openreview.net/forum?id=r1g87C4KwB

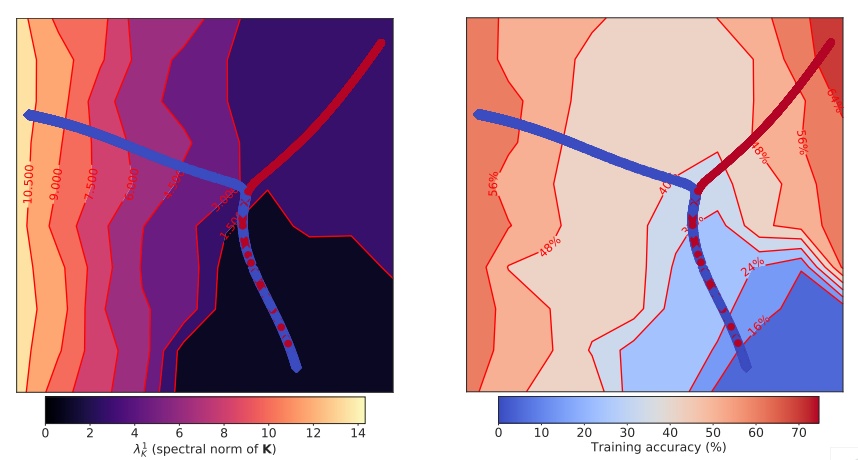
早期訓練軌跡的可視化,CIFAR-10(之前訓練精度達到65%)的一個簡單的CNN模型優化使用SGD學習率η= 0.01(紅色)和η= 0.001(藍色)。訓練軌跡上的每個模型(顯示爲一個點)通過使用UMAP將其測試預測嵌入到一個二維空間中來表示。背景顏色表示梯度K (λ1K, 左)的協方差歸一化頻譜和訓練精度(右)。對於小的η,達到我們所說的收支平衡點後,對於同樣的訓練精度(右),軌跡是引向一個地區,這個區域具有更大λ1K(左)的特點。

8. Hoppity: Learning Graph Transformations To Detect And Fix Bugs In Programs
一種基於學習的方法,用於檢測和修復Javascript中的bug。
論文:https://openreview.net/forum?id=SJeqs6EFvB


演示現有方法的侷限性的示例程序包括基於規則的靜態分析器和基於神經的錯誤預測器。

9. Selection via Proxy: Efficient Data Selection for Deep Learning
通過使用一個更小的代理模型來執行數據選擇,我們可以顯著提高深度學習中數據選擇的計算效率。
論文:https://openreview.net/forum?id=HJg2b0VYDr
代碼:https://github.com/stanford-futuredata/selection-via-proxy

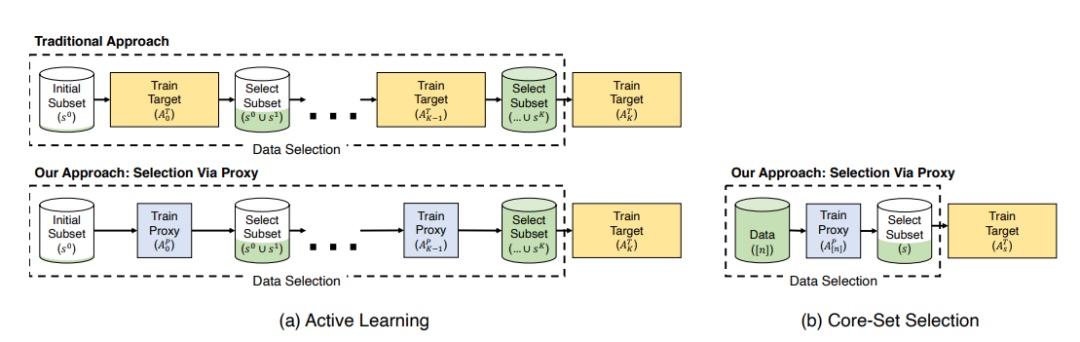
SVP應用於主動學習(左)和核心集選擇(右)。在主動學習中,我們遵循了相同的迭代過程,即訓練和選擇標記爲傳統方法的點,但是用計算成本更低的代理模型代替了目標模型。對於核心集的選擇,我們學習了使用代理模型對數據進行特徵表示,並使用它選擇點來訓練更大、更精確的模型。在這兩種情況下,我們發現代理和目標模型具有較高的rank-order相關性,導致相似的選擇和下游結果。

10. And the Bit Goes Down: Revisiting the Quantization of Neural Networks
採用結構化量化技術對卷積神經網絡進行壓縮,實現更好的域內重構。
論文:https://openreview.net/forum?id=rJehVyrKwH
代碼:https://drive.google.com/file/d/12QK7onizf2ArpEBK706ly8bNfiM9cPzp/view?usp=sharing

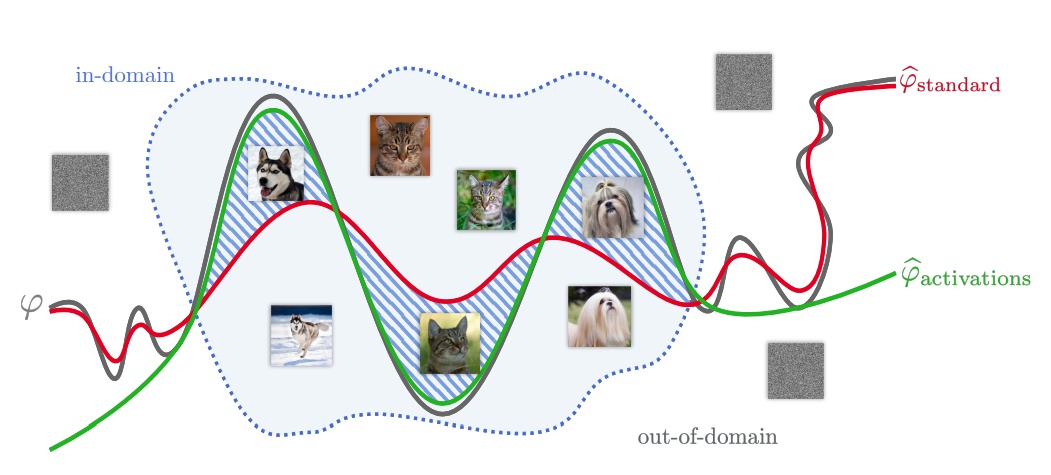
圖解我們的方法。我們近似一個二元分類器ϕ,通過量化權重把圖像標記爲狗或貓。標準方法:使用標準目標函數來量化 ϕstandard,(1)提升分類器ϕ,試圖在整個輸入空間上近似ϕ,因此對於域內的輸入可能表現很差。我們的方法:用我們的目標函數量化ϕ(2)提升分類器ϕbactivations,使之對於域內輸入表現良好。在輸入空間的圖像由ϕactivations正確分類,但ϕstandard不正確。

11. A Signal Propagation Perspective for Pruning Neural Networks at Initialization
我們正式描述了初始化時有效剪枝的初始化條件,並分析了得到的剪枝網絡的信號傳播特性,提出了一種增強剪枝網絡可訓練性和剪枝效果的方法。
論文:https://openreview.net/forum?id=HJeTo2VFwH

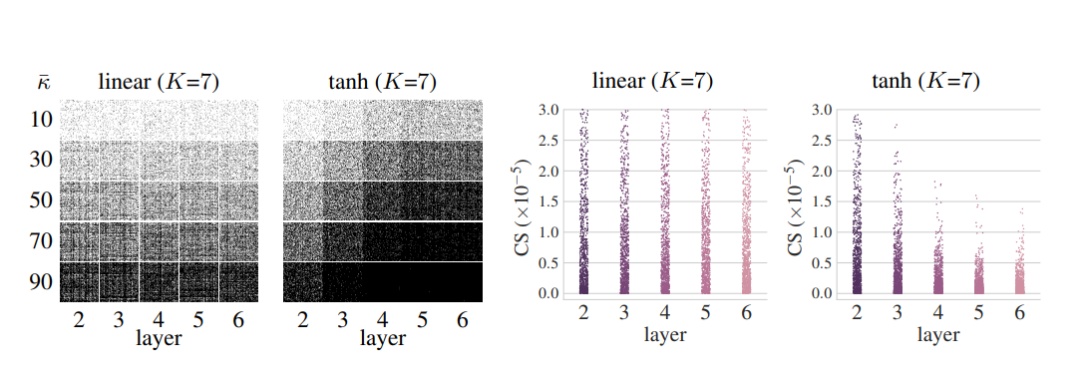
(左)layerwise稀疏模式c∈{0,1} 100×100獲得剪枝水平爲κ¯= {10 . .90}%的效果。這裏,黑色(0)/白色(1)像素爲修剪/保留參數,(右)各層參數的連接靈敏度(CS)所有網絡初始化γ=1.0。與線性情況不同,tanh網絡的稀疏模式在不同層上是不均勻的。當進行高等級剪枝的時候(例如,κ¯= 90%),這成爲關鍵,導致學習能力差,只有幾個參數留在後面的層。這是由連接靈敏度圖所解釋的,圖中顯示,對於非線性網絡參數,後一層的連接靈敏度低於前一層。

12. Deep Semi-Supervised Anomaly Detection
我們介紹了Deep SAD,一種用於一般性的半監督異常檢測的深度方法,特別利用了異常的標記。
論文:https://openreview.net/forum?id=HkgH0TEYwH
代碼:https://github.com/lukasruff/Deep-SAD-PyTorch

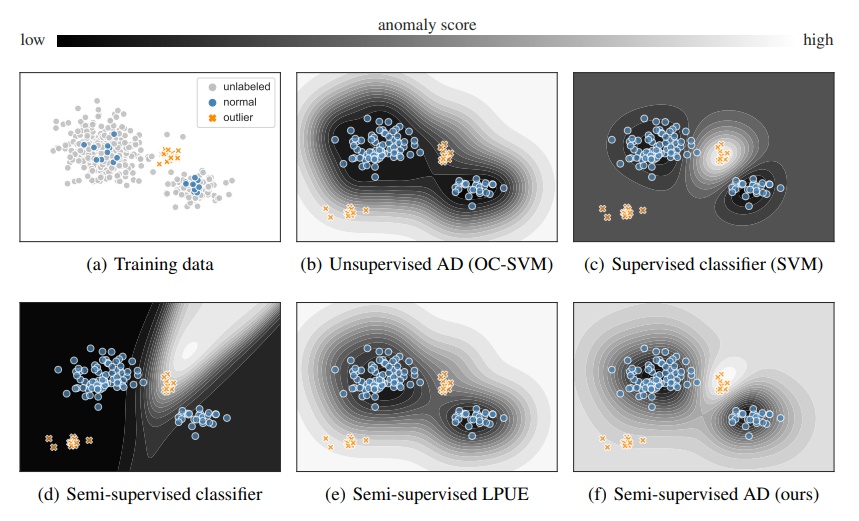
半監督異常檢測的需要:訓練數據(如(a)所示)由(大部分正常)未標記數據(灰色)和少數標記正常樣本(藍色)和標註的異常樣本(橙色)組成。圖(b) - (f)顯示了測試時各種學習模式的決策邊界,以及出現的新異常(每個圖的左下角)。我們的半監督AD方法利用了所有的訓練數據:未標記的樣本,標記的正常樣本,以及標記的異常樣本。這在單類別學習和分類之間取得了平衡。

13. Multi-Scale Representation Learning for Spatial Feature Distributions using Grid Cells
我們提出了一個名爲Space2vec的表示學習模型來編碼位置的絕對位置和空間關係。
論文:https://openreview.net/forum?id=rJljdh4KDH
代碼:https://github.com/gengchenmai/space2vec

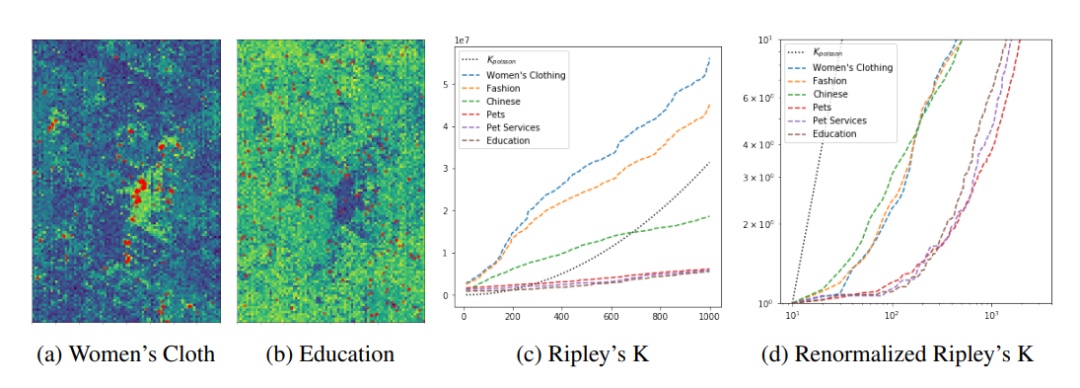
具有非常不同特徵的聯合建模分佈的挑戰。(a)(b)拉斯維加斯的POI位置(紅點)以及Space2Vec預測了女裝(使用聚類分佈)和教育(使用均勻分佈)的條件似然。(b)中的黑色區域表明市中心區域的其他類型的POIs比教育多。(c)相對於wrap, Space2Vec具有最大和最小改進的POI類型的Ripley的K曲線(Mac Aodha et al., 2019)。每條曲線表示以某一類型的點爲中心的某一半徑內某一類型點的點的個數(d)用POI密度重新規格化的Ripley’s K曲線,並以對數刻度表示。爲了高效地實現多尺度表示,Space2Vec將64個尺度(波長從50米到40k米不等)的網格單元編碼作爲深度模型的第一層,並以無監督的方式與POI數據進行訓練。

14. Federated Learning with Matched Averaging
使用分層匹配來實現聯邦學習的高效交流。
論文:https://openreview.net/forum?id=BkluqlSFDS
代碼:https://github.com/IBM/FedMA

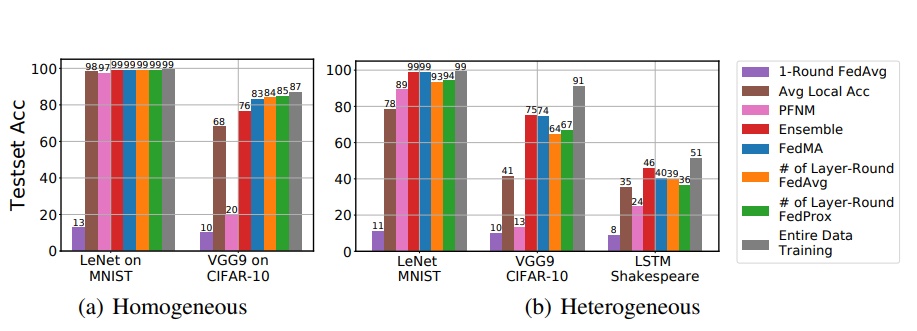
在MNIST上進行有限次數的LeNet聯邦學習方法的比較,在CIFAR-10數據集上訓練VGG-9,LSTM在莎士比亞數據集上訓練:(a)同構數據(b)異構數據

第一作者:Hongyi Wang
15. Chameleon: Adaptive Code Optimization for Expedited Deep Neural Network Compilation
深度神經網絡優化編譯的增強學習和自適應採樣。
論文:https://openreview.net/forum?id=rygG4AVFvH


我們的模型編譯工作流的概要,突出顯示的是這項工作的範圍。

第一作者:Byung Hoon Ahn
16. Network Deconvolution
爲了更好地訓練卷積網絡,我們提出了一種類似於動物視覺系統的網絡反捲積方法。
論文:https://openreview.net/forum?id=rkeu30EtvS
代碼:https://github.com/yechengxi/deconvolution


使用相關濾波器(例如高斯核)對這個真實世界的圖像進行卷積,將相關性添加到生成的圖像中,這使得目標識別更加困難。去除這種模糊的過程稱爲反捲積。但是,如果我們看到的真實世界的圖像本身是某種未知的相關濾波器的結果,這使得識別更加困難呢?我們提出的網絡反捲積操作可以去除底層圖像特徵之間的關聯,使得神經網絡能夠更好地執行。

第一作者:Chengxi Ye
總結
ICLR的深度和廣度相當鼓舞人心。在這裏,我只介紹了「深度學習」主題的冰山一角。然而,這一分析表明,有一些是很受歡迎的領域,特別是:
- 深度學習(本文涵蓋)
- 強化學習
- 生成模型
- 自然語言處理/理解
爲了更全面地概述ICLR的頂級論文,我們正在撰寫一系列文章,每一篇都集中在上面提到的一個主題上。
英文原文:https://neptune.ai/blog/iclr-2020-deep-learning