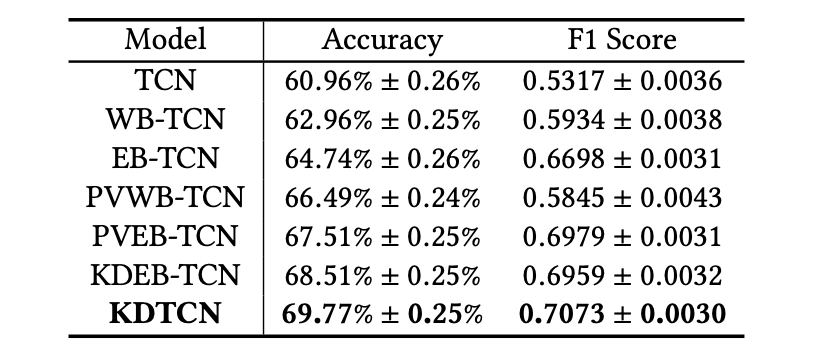
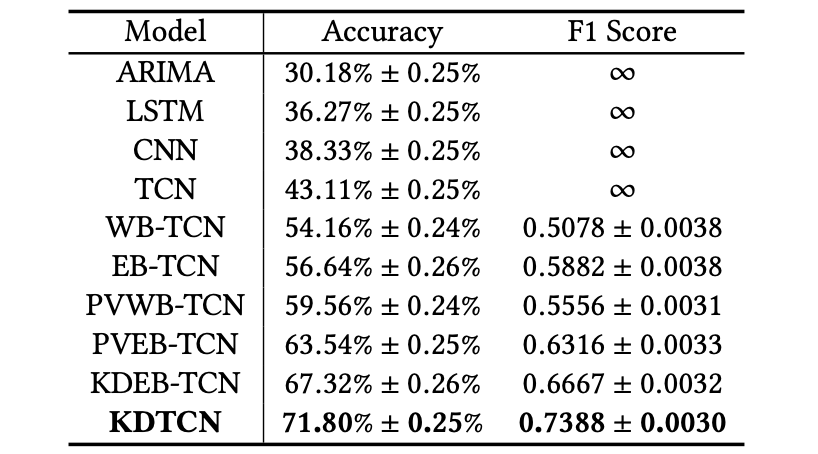
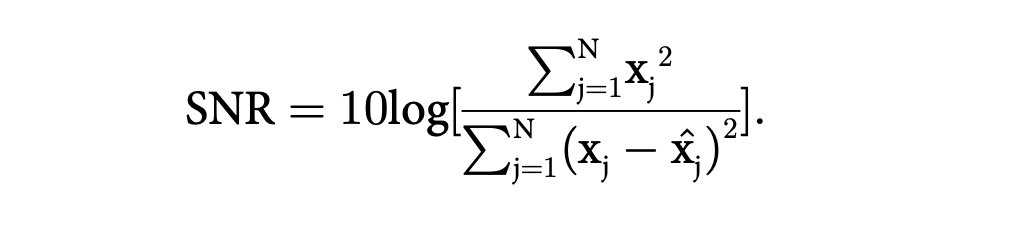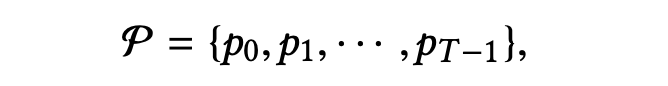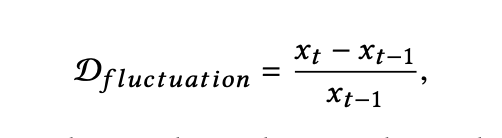如果 | Ci | 超過特定閾值,則可以認爲在第 i 天,股票價格突變。
4.4 解釋預測結果
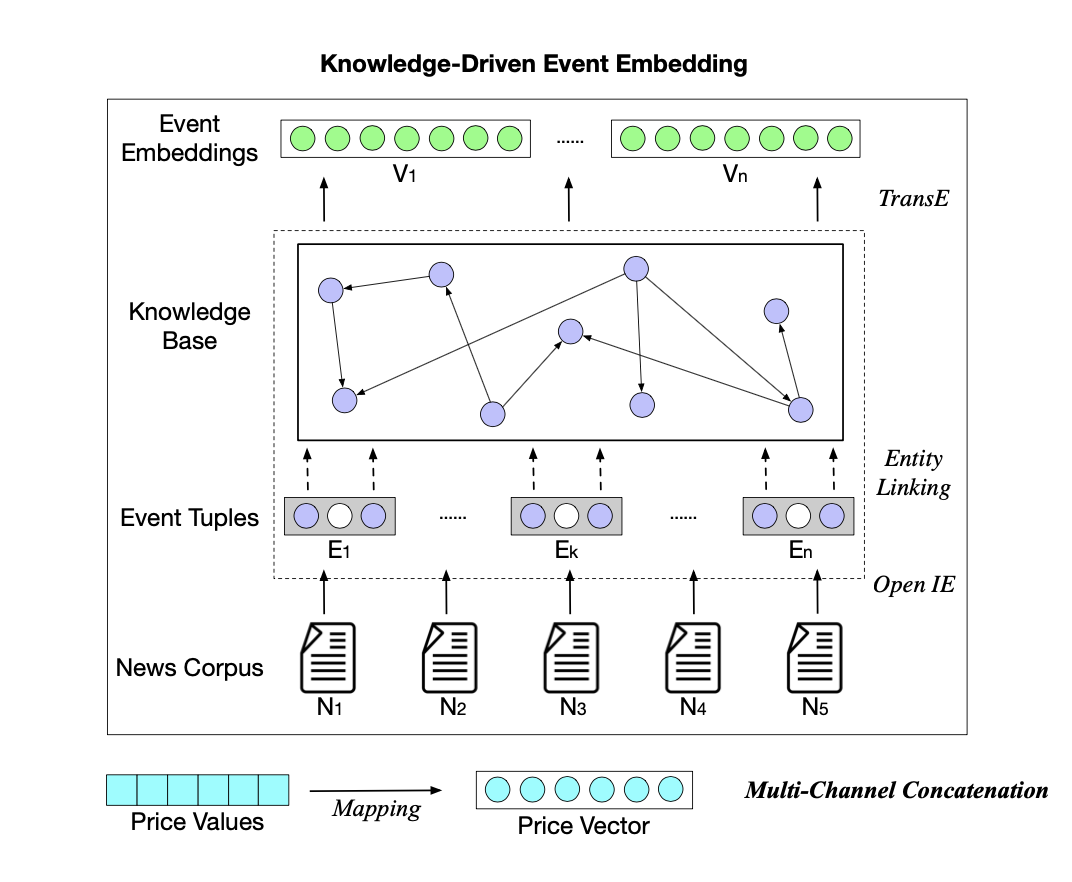
爲什麼知識驅動事件是不具備 ML 專業知識的人識別股市突變的常規來源?這可以從兩個方面進行解釋:1)將知識驅動事件對突變預測結果的影響可視化;2)將知識驅動事件鏈接至外部 KG,進而檢索事件的背景事實。
將知識驅動事件的影響可視化:
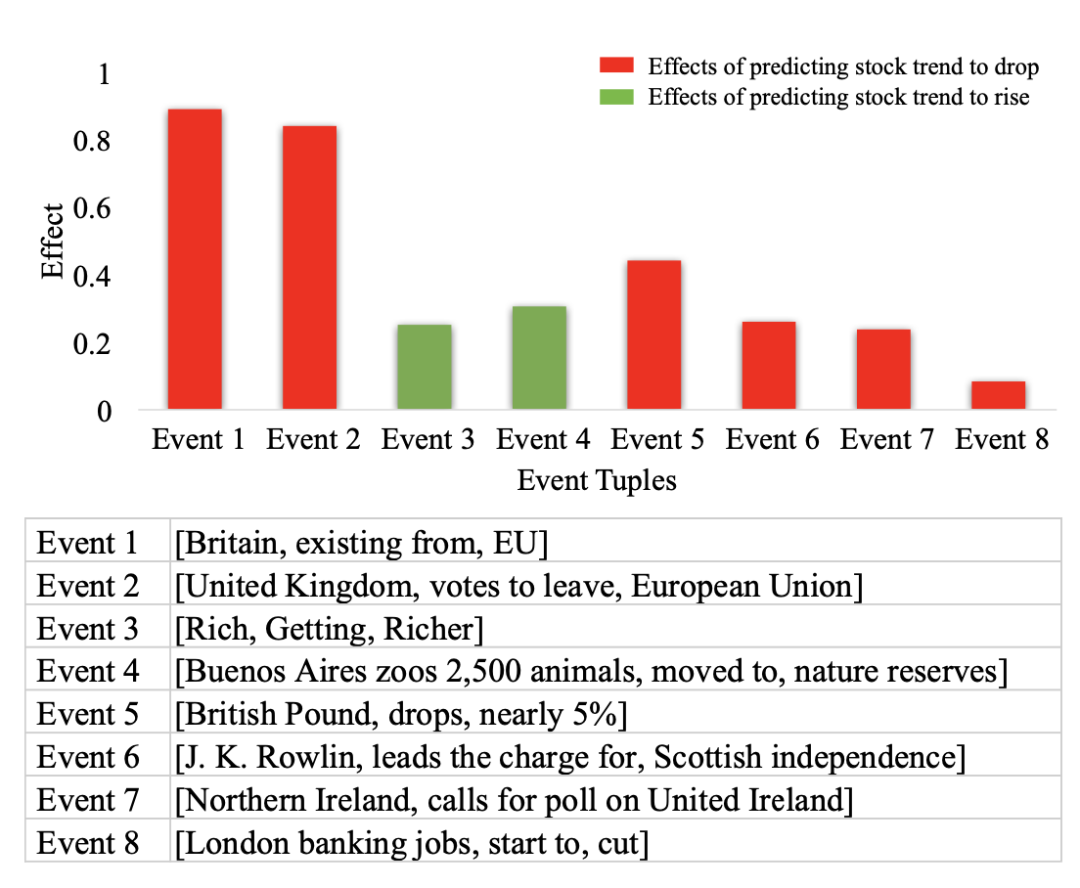
下圖中的預測結果顯示道瓊斯工業平均指數趨勢將下降。注意圖中同色長條表示相同的事件影響,長條的高度反映了影響的程度,事件的流行性自左向右下降。直觀來看,具備更高流行性的事件對股市趨勢突變預測應有更大的影響,但事實並不總是如此。
事件對股市趨勢預測的影響示例。
幾乎所有負影響事件都與這兩個事件有關,如 (British Pound, drops, nearly 5%) 和 (Northern Ireland, calls for poll on United Ireland)。
儘管一些事件對預測股市趨勢上漲有着積極影響也具備高流行性,但整體影響仍是負面的。因此,股票指數波動出現突變可被視爲事件影響和事件流行性的共同結果。
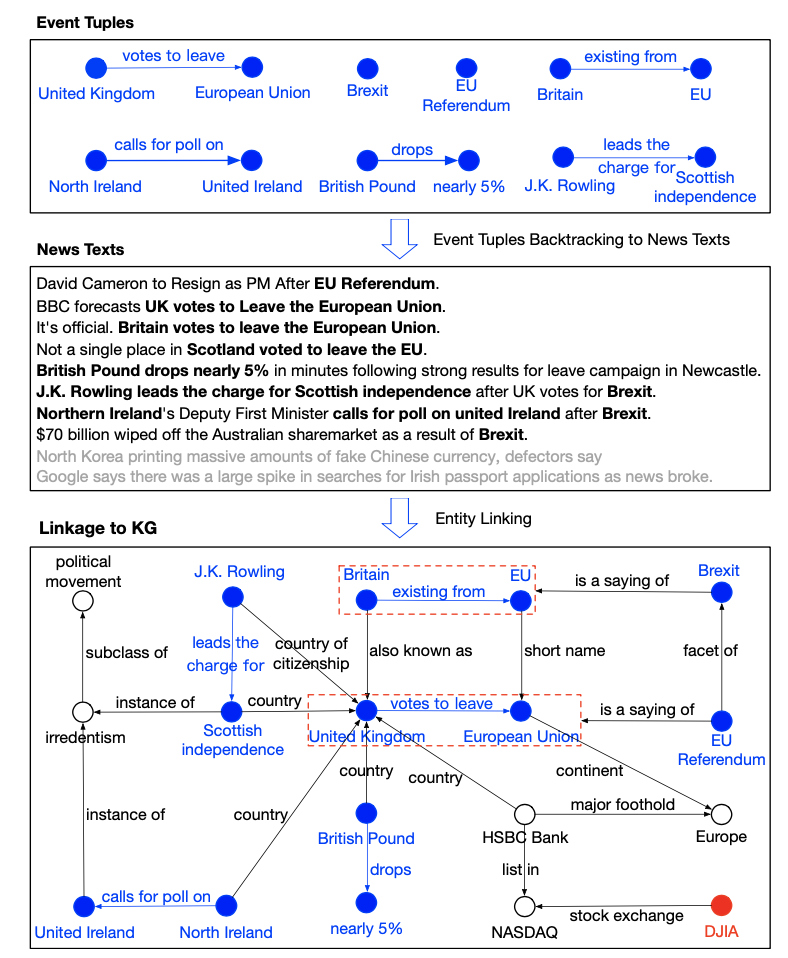
事件元組鏈接至 KG 後的可視化結果:
首先,搜索具備高影響或高流行性的事件元組;然後,回溯包含這些事件的新聞文本;最後,通過
實體鏈接檢索與事件元組相關的 KG 三元組。上圖中,藍色爲事件元組,其中的實體與 KG 鏈接。
列出的這些事件元組字面上並沒有強相關。但是,鏈接 KG 後,它們可以彼此建立關聯,並與英國脫歐和歐盟公投事件產生強相關。通過集成事件影響的解釋,我們可以證明知識驅動事件是突變的常規來源。
結論
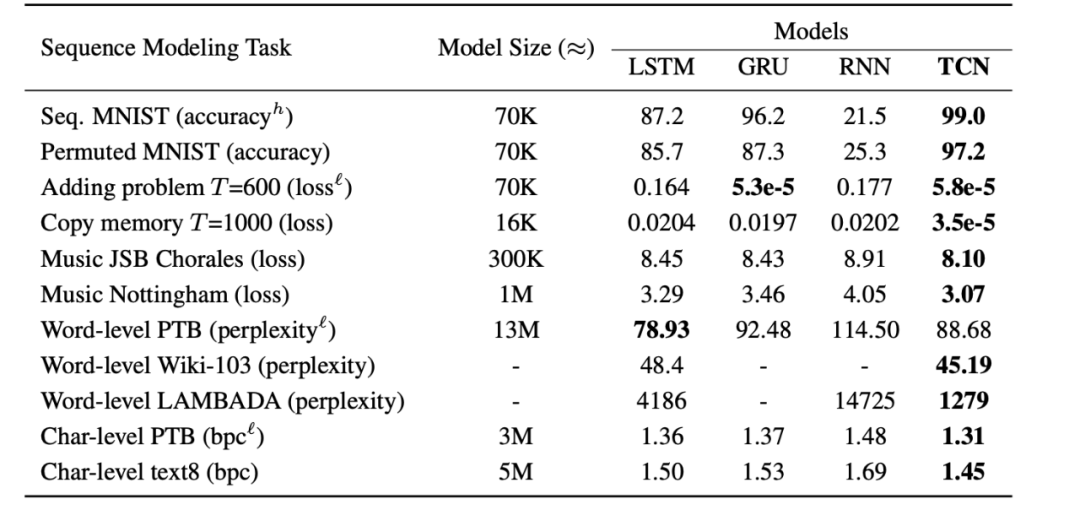
循環網絡在序列建模中的優秀效果可能大多是歷史的痕跡。最近,擴張卷積和殘差連接等架構元素的引入使得卷積架構不那麼弱了。近期的學術研究表明,使用這些元素後,簡單的卷積架構在不同序列建模任務上的效果優於循環架構,如 LSTM。由於 TCN 的清晰性和簡潔性,Shaojie Bai 等人提出卷積網絡應被看作序列建模的起點和強大工具。
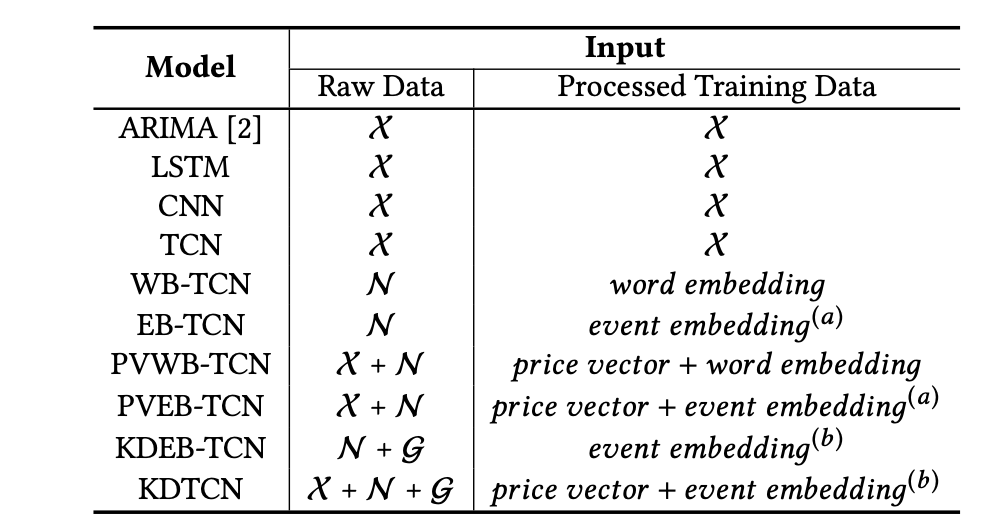
此外,本文介紹的 TCN 在股市趨勢預測任務中的應用表明,集成新聞事件和
知識圖譜後,TCN 的性能大幅超過 RNN。
參考文獻
[1] Hollis, T., Viscardi, A. and Yi, S. (2020). 「A Comparison Of Lstms And Attention Mechanisms For Forecasting Financial Time Series」. (https://arxiv.org/abs/1812.07699)
[2] Qiu J, Wang B, Zhou C. (2020). 「Forecasting stock prices with long-short term memory neural network based on attention mechanism」. (https://doi.org/10.1371/journal.pone.0227222)
[3] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. (2020). 「Neural Machine Translation By Jointly Learning To Align And Translate」. (https://arxiv.org/abs/1409.0473)
[4] Bai, S., Kolter, J. and Koltun, V., 2020. 「An Empirical Evaluation Of Generic Convolutional And Recurrent Networks For Sequence Modeling」. (https://arxiv.org/abs/1803.01271)
[6] Deng, S., Zhang, N., Zhang, W., Chen, J., Pan, J. and Chen, H., 2019. 「Knowledge-Driven Stock Trend Prediction and Explanation via Temporal Convolutional Network」. (https://dl.acm.org/doi/10.1145/3308560.3317701)
[5] Hao, H., Wang, Y., Xia, Y., Zhao, J. and Shen, F., 2020. 「Temporal Convolutional Attention-Based Network For Sequence Modeling」. (https://arxiv.org/abs/2002.12530)