總結概括下:老黃喪心病狂,GPU的競爭已經進入到了下一個紀元。

首先我們要明確一下,老黃的全新核心是爲計算而生的,而不是爲了遊戲而生,不要用遊戲的眼光看待這回的全新核心。由於纔剛剛發佈,所以簡單說幾個厲害的地方。
【核心】


這回GA100採用臺積電的N7工藝製造,有着高達826mm2的核心面積和542億的晶體管,400W TDP,真真真是一個恐怖的核彈,不用看規格也知道這是如何喪心病狂了,如此奢華的晶體管下必然有着令人窒息的性能。800多的面積,這不是小打小鬧啊,這算是摸着臺積電的極限走了。
由於面積真的非常高,作爲GA100的首發產品A100,並不是完整的規格,不過也已經很喪心病狂了。
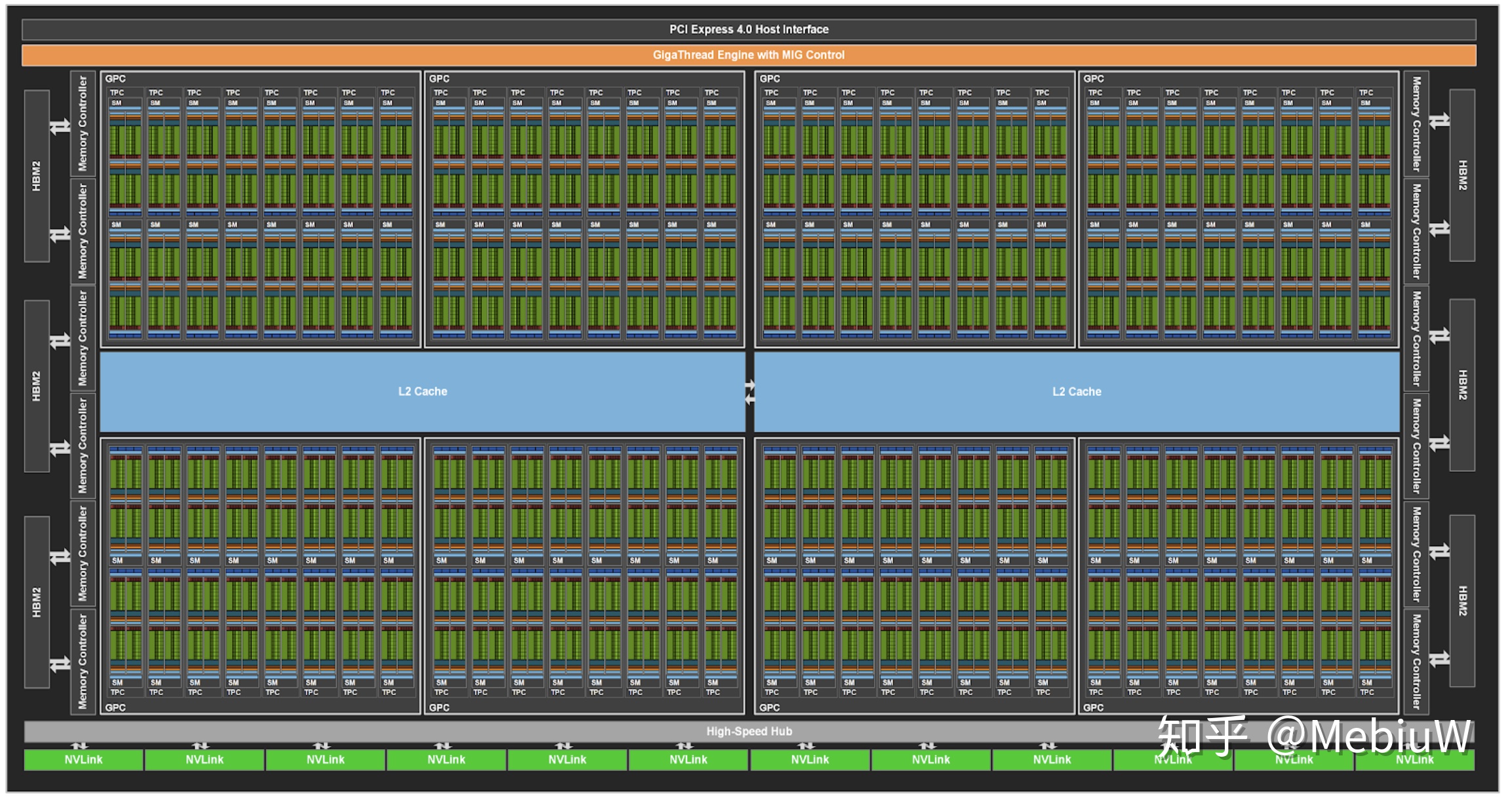


大概來說目前上市的A100閹割了1/8的計算資源,以及1/6的顯存資源,後期等着良品率上去了後,我們應該可以看到更加完整的GA100核心。不過別看這回晶體管那麼多,其實GA100但從核心數上來說提升不是很大,GA100對比GV100也就是多了30%+的SM而已,不過請記住剛剛說的這回GA100的重點並不是遊戲性能,只看核心數,只看傳統FP32 64性能就太Naive了。
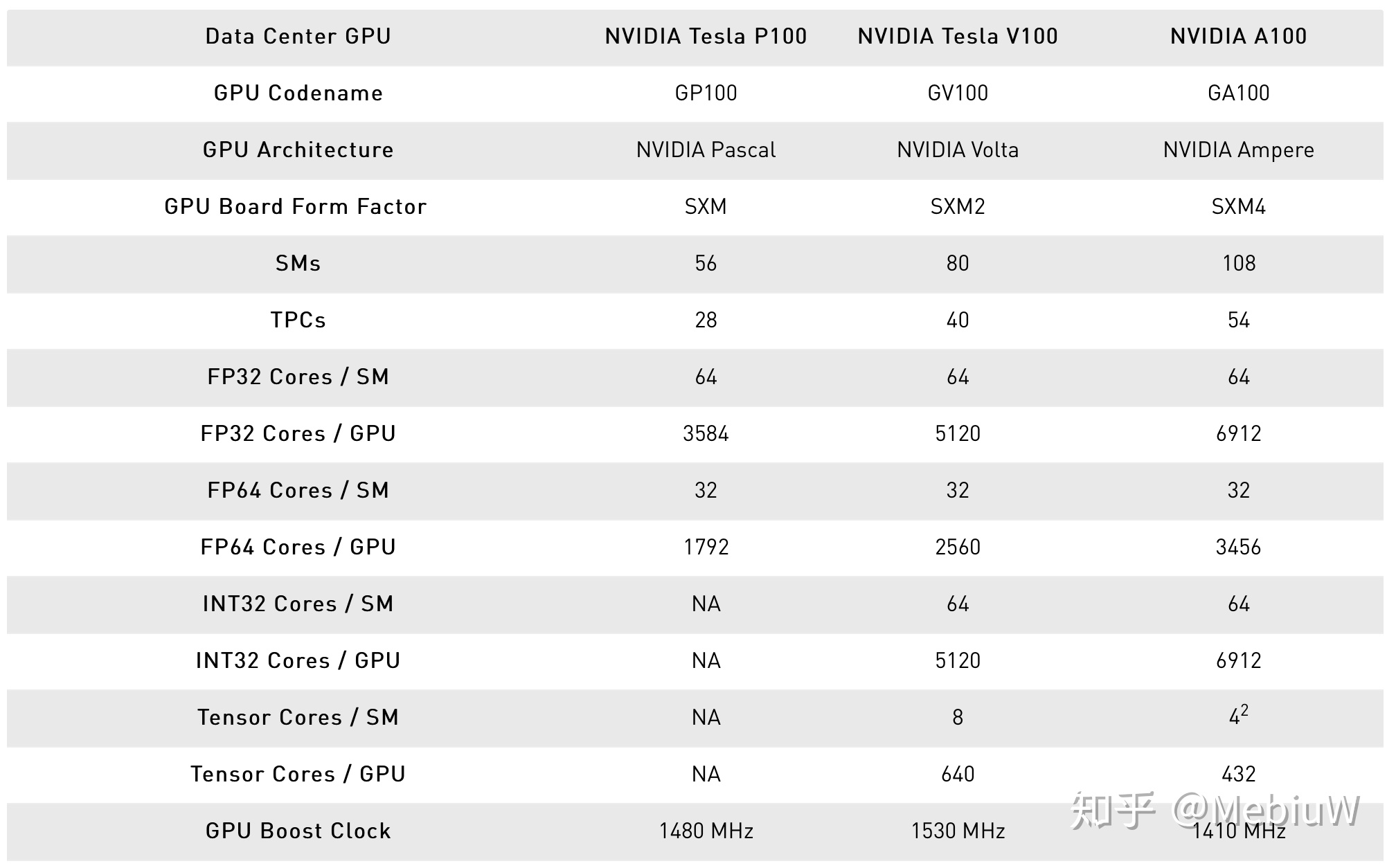
【性能】
Nvidia Ampere的重點是AI性能,其改進的重點是Tensor Core。因此如果只是看遊戲玩家最愛的FP32和傳統的FP64性能,其實FP32和FP64只是提升了25%而已(SM更多但是頻率更低),FP16性能多一些到了2.5X。
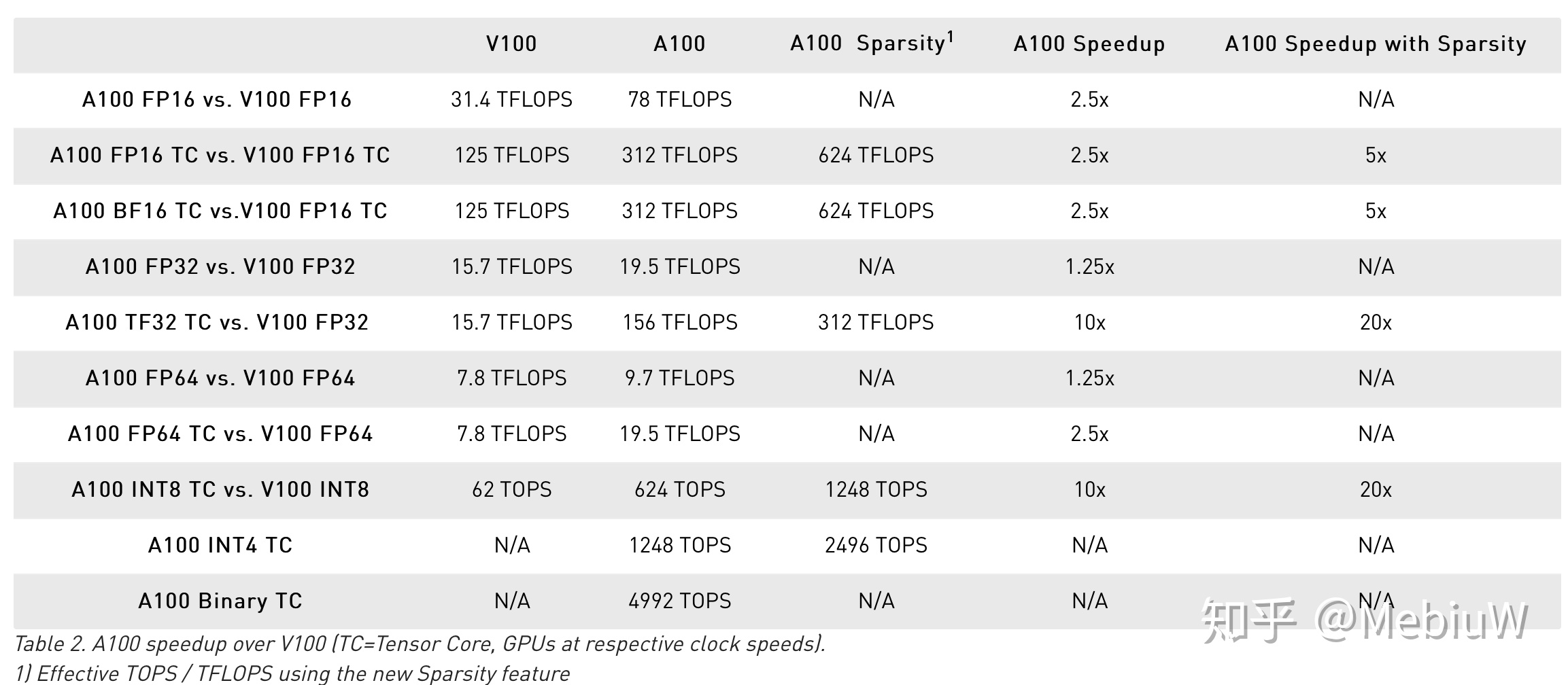
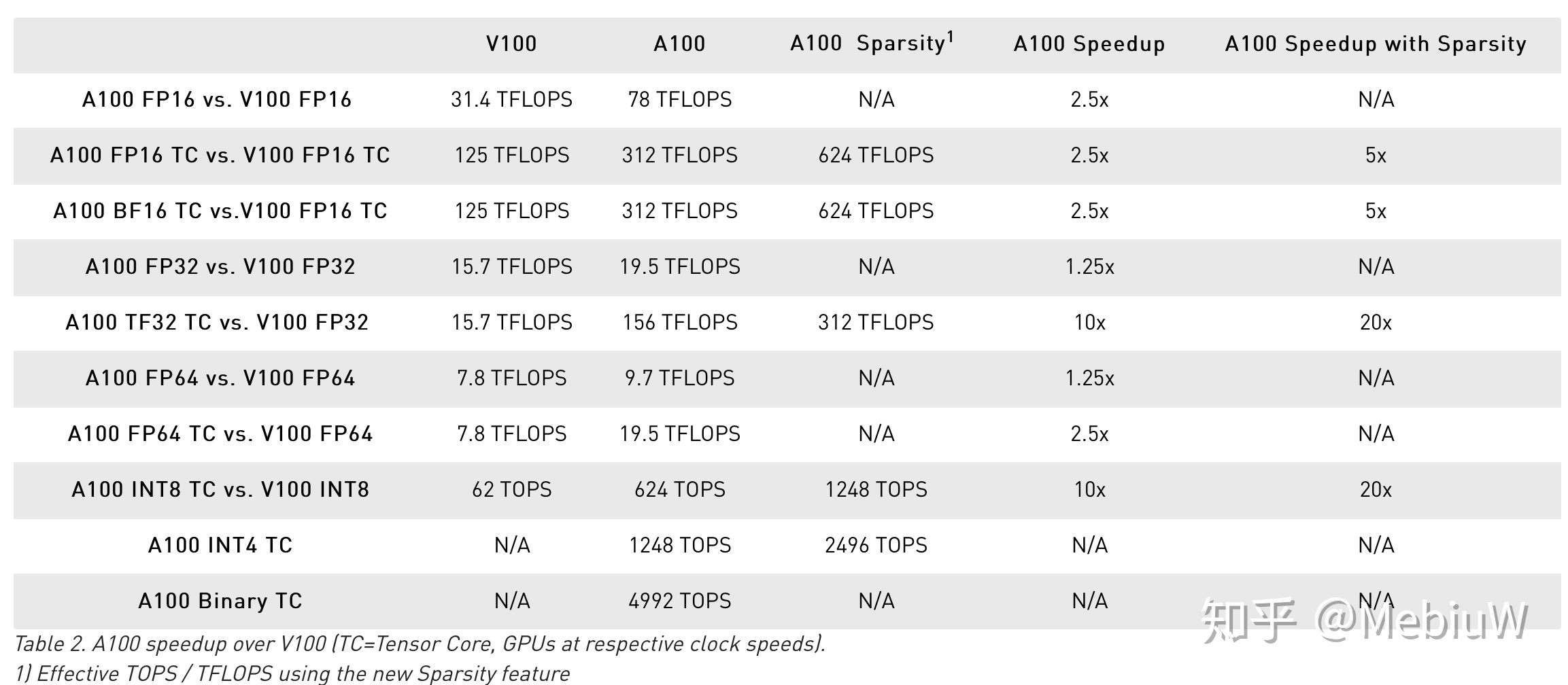
但如果你看AI性能就會發現一切不一樣了,Nvidia首先大幅改進了TensorCore,使其支持了TF32 TF64 還改進了INT 8 FP6的支持,作爲結果,16/32/64的Tensor性能分別提升了2.5X,10X,和2.5X。 FP32是目前深度學習訓練和推理中用的最多的一個格式了,10倍是啊!此外在低精度場景中,INT8也非常常見,GA100提升了10倍(由於支持完善)。而在更極端的場合,INT4和二值化的 INT1,則是分別對INT8提升到了2X和8X,顫抖吧4992T的性能(5P!)。
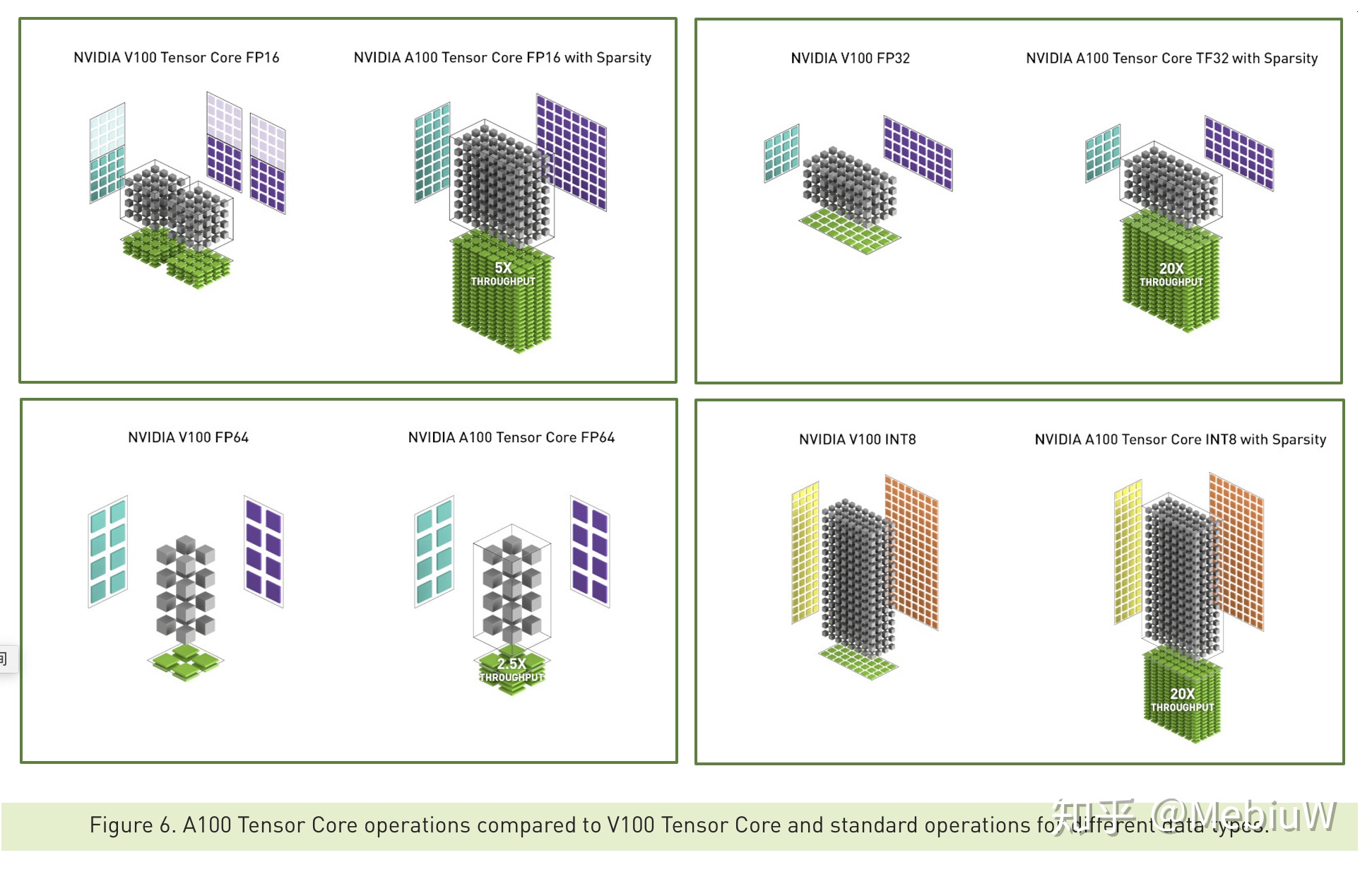
精彩還沒結束,這回Nvidia對於稀疏數據增加了優化,如果遇上稀疏數據操作,性能可以再度翻倍,比如FP32翻倍到了20倍。
【實際性能】
也不要光說不練,來看看實際性能。 做AI、NLP的同學對BERT一定不陌生,那個改變了NLP的預練語言模型,並由此掀起了腥風血雨。BERT性能非常牛,但問題是其訓練和推理開銷都不是一般研究機構、公司可以承擔的,模型太複雜、參數太多。
用上了GA100後,訓練性能直接翻了6倍(FP32)或者3倍(FP16),推理性能提升了7倍。這意味着只要買了GA100後,很多機構也能自己訓練了,原來XX周變成了XX天,可怕至極。可想而知,GA100上市後,類似BERT的各種超級龐大模型又可以繼續堆參數堆結構了,對AI領域有核彈級的影響。
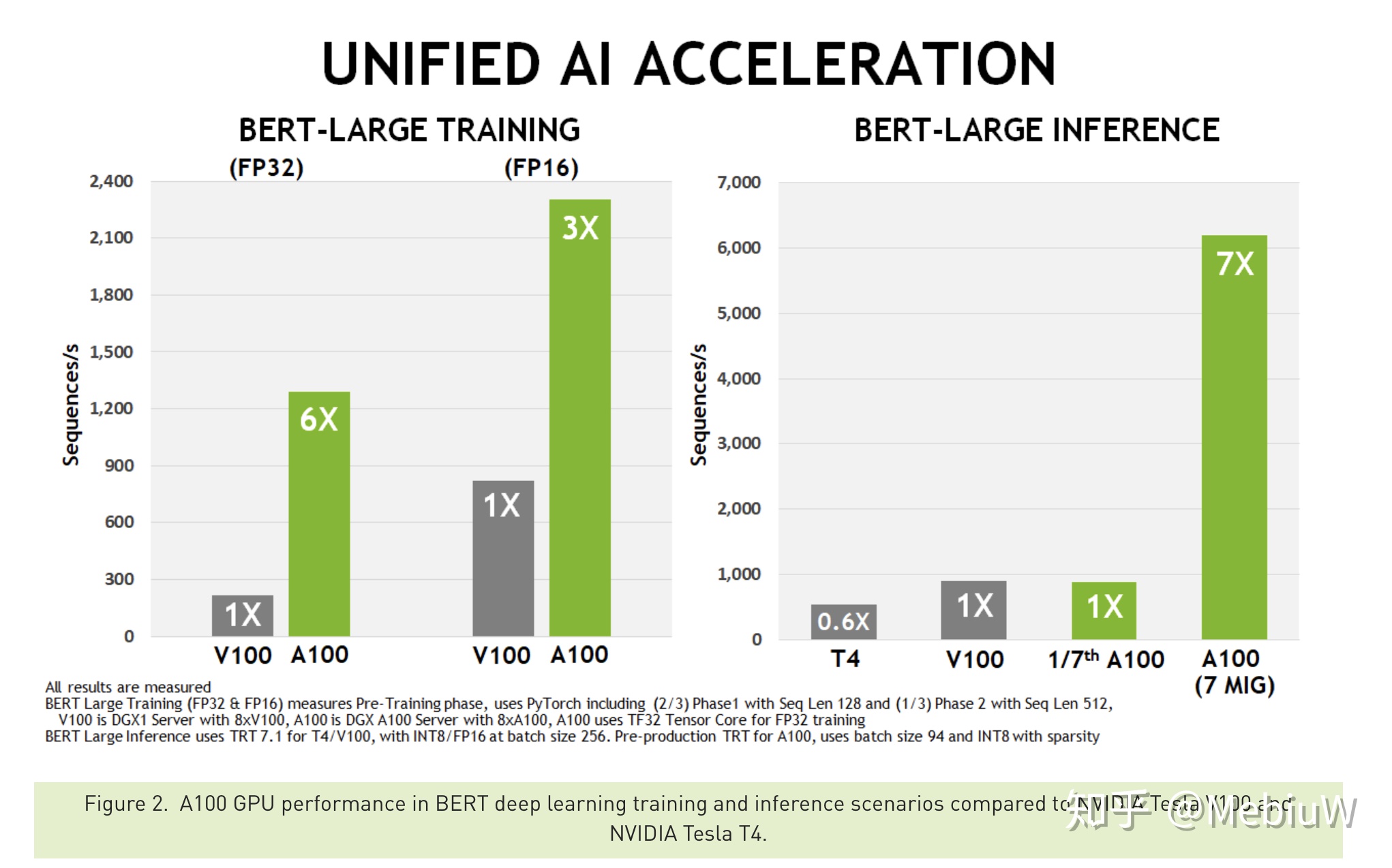
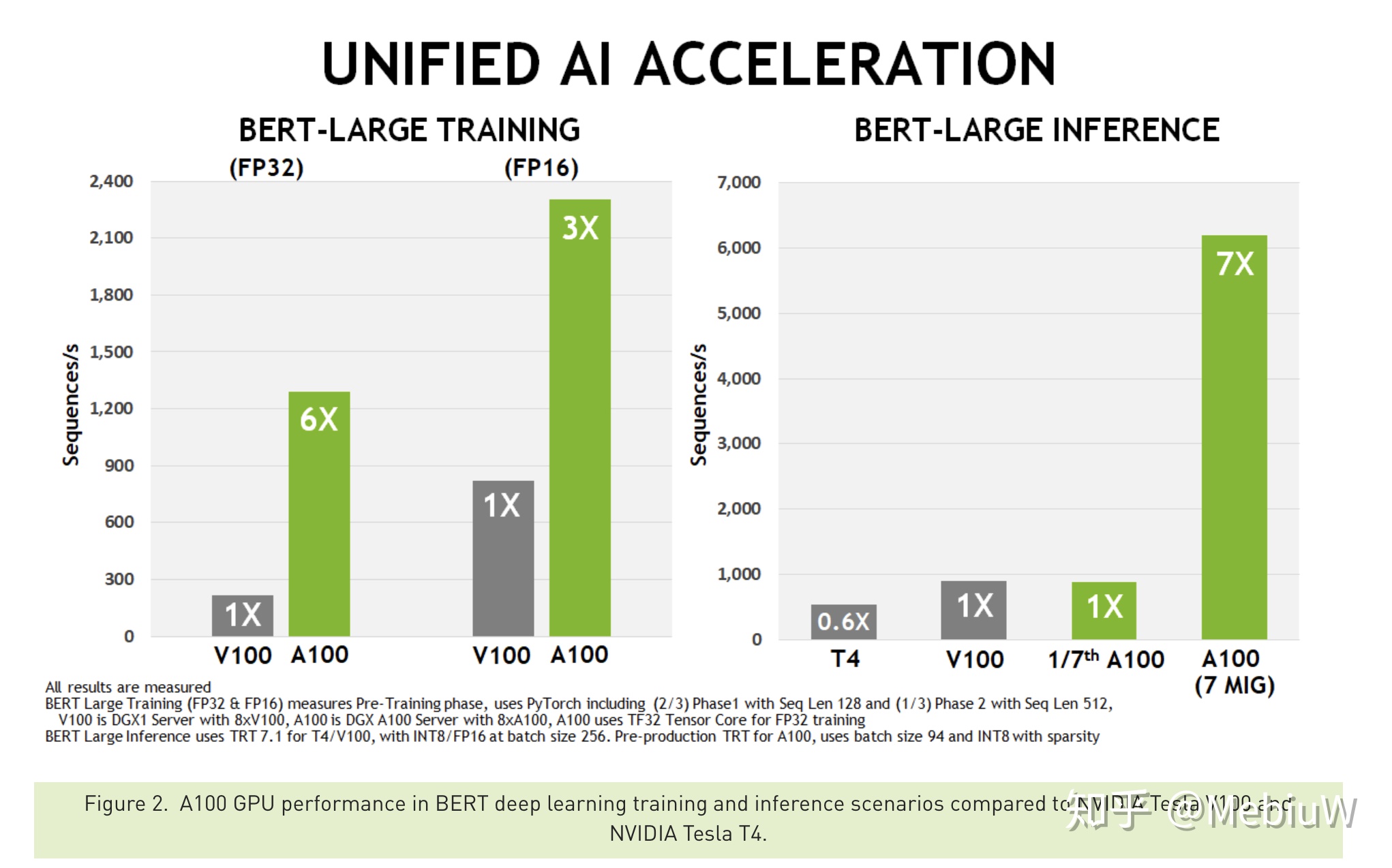
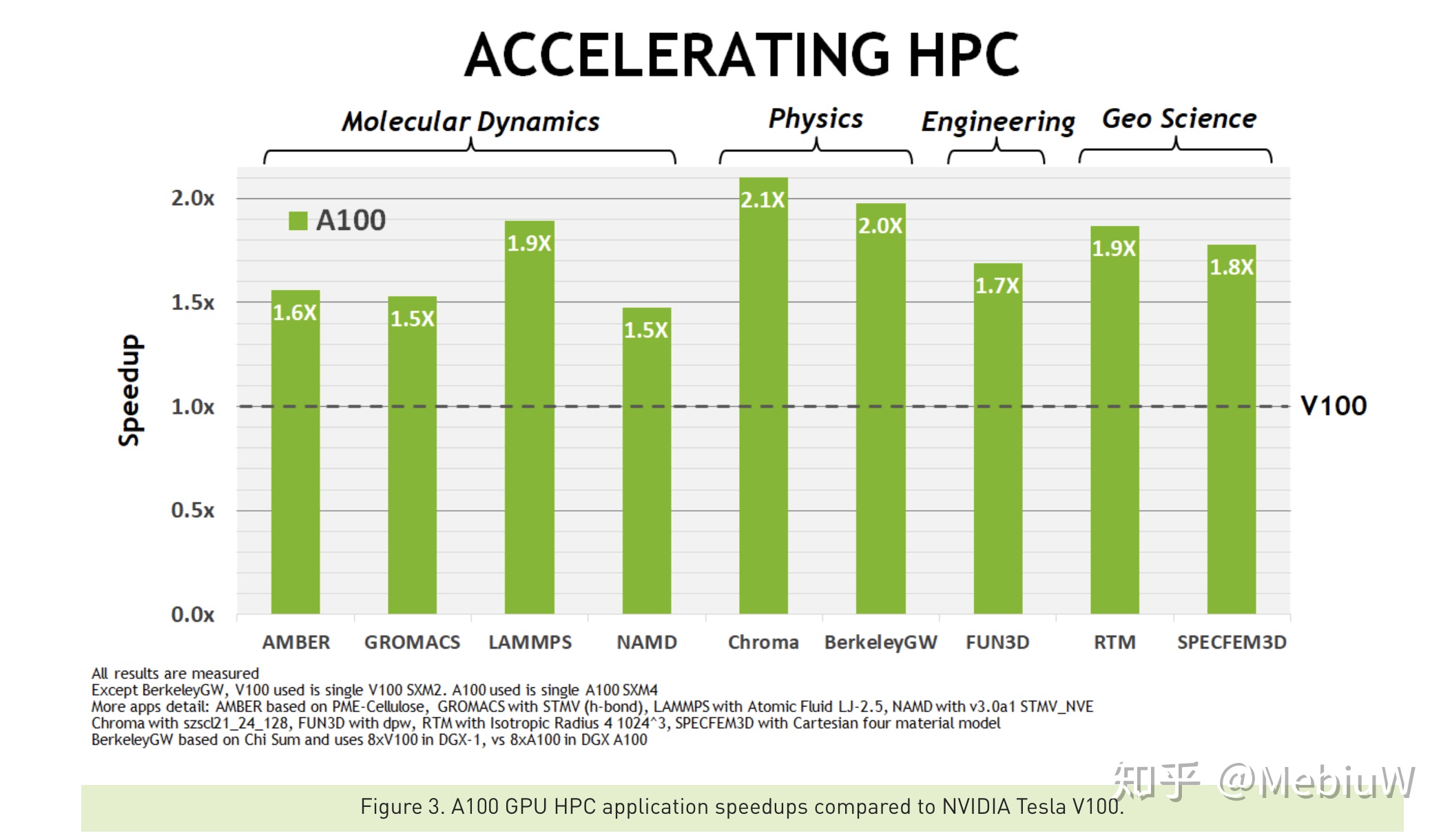
在傳統的高性能計算領域,主要依靠原始的FP32 64性能,這時候雖然沒有AI那麼兇猛,但是提升1.5X~1.9X後,依舊還是HPC的最強計算GPU。
【小結】
如果你去看FP32和FP64的原始性能,真沒什麼出彩的地方,那麼大面積那麼高功耗才20T的FP32。 但是這真的大錯特錯,GA100是面向AI的,對於AI煉丹師會有質的幫助。
Nvidia的GA100根本不準備和AMD爭奪遊戲市場,玩FP32數字遊戲,其面向更大的一個市場。對於傳統遊戲用戶、HPC用戶來說,這些Tensor可能是電爐絲,不過也不用擔心,Nvidia肯定會有後手的,比如GA101 GA102,這些會砍了一些Tensor拿去堆FP32/64性能或縮小面積。
看到Nvidia在AI市場上那麼用心,不禁擔心其AMD能不能追上來,AMD在這塊真的很欠缺,這不僅是硬件上的差距,還有軟件生態上的差距。如果說GA100最大的對手會是誰,我想下一個有機會成爲對手的是Intel 2021年末的Xe HPC PVC卡,Intel今年在計算、AI上的積累也是非常深厚,還有傳說中的OneAPI~~ 雖然遊戲卡不行,但這個真不能小視,希望Intel 7nm別延遲了。