YOLO v4 論文:https://arxiv.org/abs/2004.10934
YOLO v4 開源代碼:https://github.com/AlexeyAB/darknet
加權殘差連接(WRC)
Cross-Stage-Partial-connection,CSP
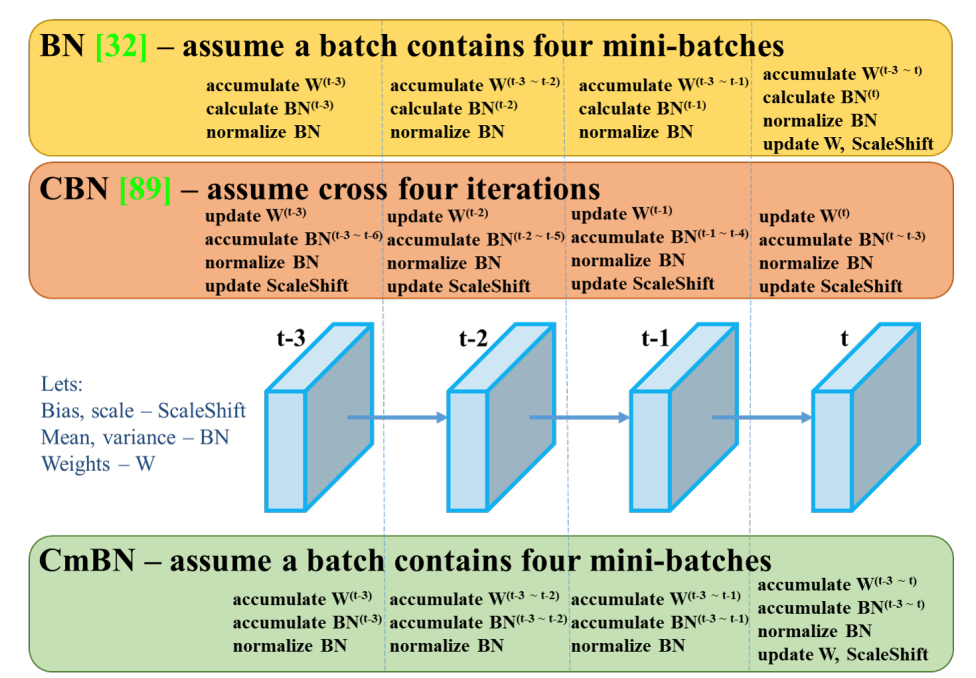
Cross mini-Batch Normalization,CmBN
自對抗訓練(Self-adversarial-training,SAT)
Mish 激活(Mish-activation)
Mosaic 數據增強
DropBlock 正則化
CIoU 損失
-
建立了一個高效強大的目標檢測模型。它使得每個人都可以使用 1080Ti 或 2080Ti 的 GPU 來訓練一個快速準確的目標檢測器。 -
驗證了當前最優 Bag-of-Freebies 和 Bag-of-Specials 目標檢測方法在檢測器訓練過程中的影響。 -
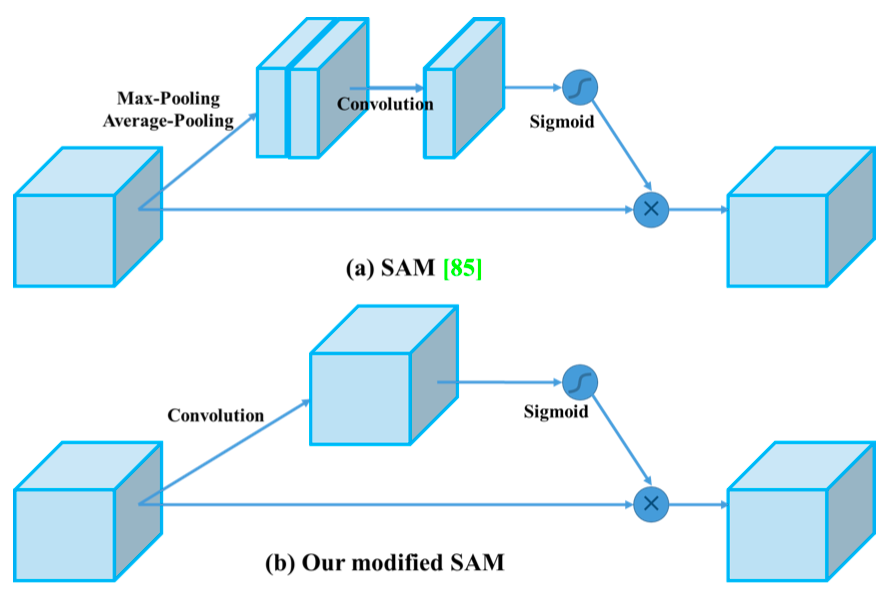
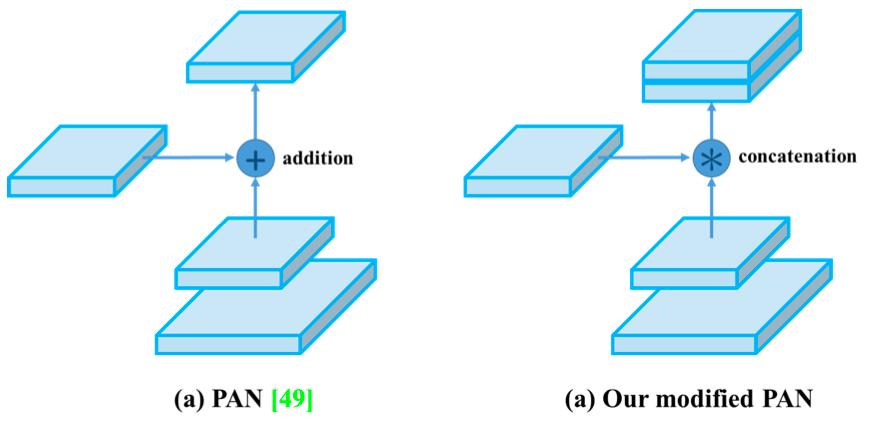
修改了 SOTA 方法,使之更加高效,更適合單 GPU 訓練。這些方法包括 CBN、PAN、SAM 等。
對於 GPU,研究者在卷積層中使用少量組(1-8 組):CSPResNeXt50 / CSPDarknet53;
對於 VPU,研究者使用了分組卷積(grouped-convolution),但避免使用 Squeeze-and-excitement(SE)塊。具體而言,它包括以下模型:EfficientNet-lite / MixNet / GhostNet / MobileNetV3。
-
骨幹網絡:CSPDarknet53 -
Neck:SPP、PAN -
Head:YOLOv3
用於骨幹網絡的 Bag of Freebies(BoF):CutMix 和 Mosaic 數據增強、DropBlock 正則化和類標籤平滑;
用於骨幹網絡的 Bag of Specials(BoS):Mish 激活、CSP 和多輸入加權殘差連接(MiWRC);
用於檢測器的 Bag of Freebies(BoF):CIoU-loss、CmBN、DropBlock 正則化、Mosaic 數據增強、自對抗訓練、消除網格敏感性(Eliminate grid sensitivity)、針對一個真值使用多個錨、餘弦退火調度器、優化超參數和隨機訓練形狀;
用於檢測器的 Bag of Specials(BoS):Mish 激活、SPP 塊、SAM 塊、PAN 路徑聚合塊和 DIoU-NMS。
激活函數:ReLU、 leaky-ReLU、parametric-ReLU、ReLU6、SELU、Swish、Mish;
邊界框迴歸損失(Bounding box regression loss):MSE、IoU、GIoU、CIoU、DIoU;
數據增強:CutOut、MixUp、CutMix;
正則化方法:DropOut,、DropPath、Spatial DropOut、DropBlock;
通過均值和方差的歸一化網絡激活函數:批歸一化(BN)、跨 GPU 批歸一化 (CGBN 或 SyncBN)、濾波器響應歸一化(FRN)、交叉迭代批歸一化(CBN);
跳躍連接方式:殘差連接、加權殘差連接、多輸入加權殘差連接、Cross stage 局部連接(CSP)。
提出新型數據增強方法 Mosaic 和自對抗訓練(SAT);
在應用遺傳算法時選擇最優超參數;
修改現有方法,使新方法實現高效訓練和檢測——modified SAM、modified PAN 和 Cross mini-Batch Normalization (CmBN)。