RCNN系列、Fast-RCNN、Faster-RCNN、R-FCN檢測模型對比
一.RCNN
問題一:速度
經典的目標檢測算法使用滑動窗法依次判斷所有可能的區域。本文則預先提取一系列較可能是物體的候選區域,之後僅在這些候選區域上提取特徵,進行判斷。
問題二:訓練集
經典的目標檢測算法在區域中提取人工設定的特徵(Haar,HOG)。本文則需要訓練深度網絡進行特徵提取。可供使用的有兩個數據庫:
一個較大的識別庫(ImageNet ILSVC 2012):標定每張圖片中物體的類別。一千萬圖像,1000類。
一個較小的檢測庫(PASCAL VOC 2007):標定每張圖片中,物體的類別和位置。一萬圖像,20類。
保證合併後形狀規則。

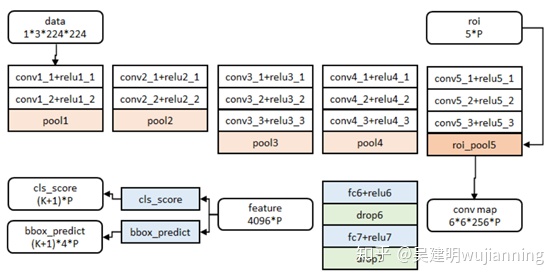
網絡分爲四個部分:區域劃分、特徵提取、區域分類、邊框迴歸
區域劃分:使用selective search算法畫出2k個左右候選框,送入CNN
特徵提取:使用imagenet上訓練好的模型,進行finetune
區域分類:從頭訓練一個SVM分類器,對CNN出來的特徵向量進行分類
邊框迴歸:使用線性迴歸,對邊框座標進行精修
優點:
ss算法比滑窗得到候選框高效一些;使用了神經網絡的結構,準確率比傳統檢測提高了。
缺點:
1、ss算法太耗時,每張圖片都分成2k,並全部送入CNN,計算量很大,訓練和inference時間長。
2、四個模塊基本是單獨訓練的,CNN使用預訓練模型finetune、SVM重頭訓練、邊框迴歸重頭訓練。微調困難,可能有些有利於邊框迴歸的特徵並沒有被CNN保留。

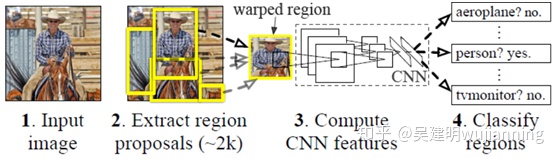
二.Fast-RCNN
Fast RCNN方法解決了RCNN方法三個問題:
問題一:測試時速度慢
RCNN一張圖像內候選框之間大量重疊,提取特徵操作冗餘。
本文將整張圖像歸一化後直接送入深度網絡。在鄰接時,才加入候選框信息,在末尾的少數幾層處理每個候選框。
問題二:訓練時速度慢
原因同上。
在訓練時,本文先將一張圖像送入網絡,緊接着送入從這幅圖像上提取出的候選區域。這些候選區域的前幾層特徵不需要再重複計算。
問題三:訓練所需空間大
RCNN中獨立的分類器和迴歸器需要大量特徵作爲訓練樣本。
本文把類別判斷和位置精調統一用深度網絡實現,不再需要額外存儲。
相對RCNN,準確率和速度都提高了,具體做了以下改進:
1、依舊使用了selective search算法對原始圖片進行候選區域劃分,但送入CNN的是整張原始圖片,相當於對一張圖片只做一次特徵提取,計算量明顯降低
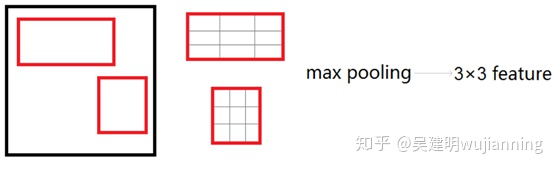
2、在原圖上selective search算法畫出的候選區域對應到CNN後面輸出的feature map上,得到2k個左右的大小長寬比不一的候選區域,然後使用RoI pooling將這些候選區域resize到統一尺寸,繼續後續的運算
3、將邊框迴歸融入到卷積網絡中,相當於CNN網絡出來後,接上兩個並行的全連接網絡,一個用於分類,一個用於邊框迴歸,變成多任務卷積網絡訓練。這一改進,相當於除了selective search外,剩餘的屬於端到端,網絡一起訓練可以更好的使對於分類和迴歸有利的特徵被保留下來
4、分類器從SVM改爲softmax,迴歸使用平滑L1損失。
缺點:因爲有selective search,所以還是太慢了,一張圖片inference需要3s左右,其中2s多耗費在ss上,且整個網絡不是端到端。


三.Faster-RCNN
從RCNN到fast RCNN,再到本文的faster RCNN,目標檢測的四個基本步驟(候選區域生成,特徵提取,分類,位置精修)終於被統一到一個深度網絡框架之內。所有計算沒有重複,完全在GPU中完成,大大提高了運行速度。

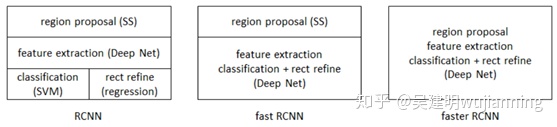
引入RPN,Faster-RCNN相當於Fast-RCNN+RPN,準確率和速度進一步提高,主要做了以下改進:
1、移除selective search算法,還是整張原始圖片輸入CNN進行特徵提取,在CNN後面的卷積不再使用ss算法映射過來的候選區域,而是採用新的網絡RPN,使用神經網絡自動進行候選區域劃分。
2、RPN通過生成錨點,以每個錨點爲中心,畫出9個不同長寬比的框,作爲候選區域,然後對這些候選區域進行初步判斷和篩選,看裏面是否包含物體(與groundtruth對比IoU,大於0.7的爲前景,小於0.3的爲背景,中間的丟棄),若沒有就刪除,減少了不必要的計算。
3、有效的候選區域(置信度排序後選取大概前300個左右)進行RoI pooling後送入分類和邊框迴歸網絡。
優點:端到端網絡,整體進行優化訓練;使用神經網絡自動生成的候選區域對結果更有利,比ss算法好;過濾了一些無效候選區,較少了冗餘計算,提升了速度。
RPN訓練:
1、加載預訓練模型,訓練RPN。
2、訓練fast-rcnn,使用的候選區域是RPN的輸出結果,然後進行後續的bb的迴歸和分類。
3、再訓練RPN,但固定網絡公共的參數,只更新RPN自己的參數。
4、根據RPN,對fast-rcnn進行微調訓練。

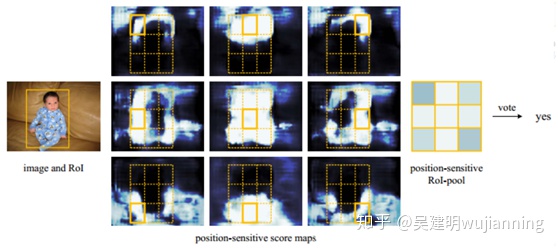
四.R-FCN
一個base的conv網絡如ResNet101, 一個RPN(Faster RCNN來的),一個position sensitive的prediction層,最後的ROI pooling+投票的決策層。
分類需要特徵具有平移不變性,檢測則要求對目標的平移做出準確響應。現在的大部分CNN在分類上可以做的很好,但用在檢測上效果不佳。SPP,Faster R-CNN類的方法在ROI pooling前都是卷積,是具備平移不變性的,但一旦插入ROI pooling之後,後面的網絡結構就不再具備平移不變性了。因此,本文想提出來的position sensitive score map這個概念是能把目標的位置信息融合進ROI pooling。
對於region-based的檢測方法,以Faster R-CNN爲例,實際上是分成了幾個subnetwork,第一個用來在整張圖上做比較耗時的conv,這些操作與region無關,是計算共享的。第二個subnetwork是用來產生候選的boundingbox(如RPN),第三個subnetwork用來分類或進一步對box進行regression(如Fast RCNN),這個subnetwork和region是有關係的,必須每個region單獨跑網絡,銜接在這個subnetwork和前兩個subnetwork中間的就是ROI pooling。我們希望的是,耗時的卷積都儘量移到前面共享的subnetwork上。因此,和Faster RCNN中用的ResNet(前91層共享,插入ROI pooling,後10層不共享)策略不同,本文把所有的101層都放在了前面共享的subnetwork。最後用來prediction的卷積只有1層,大大減少了計算量。
在Faster-RCNN基礎上,進一步提高了準確率,主要以下改進:
1、使用全卷積層代替CNN basenet裏面的全連接層。
2、CNN得到的feature map在RoI pooling之後變成3x3大小,把groundtruth也變成3x3大小,對9宮格每個區域分別比較和投票。