更快的訓練速度,更少的算力消耗,對於煉丹師們而言,這無疑是飛一般的體驗。
現在,谷歌AI掌門人Jeff Dean轉發推薦了一個訓練ResNet的奇技淫巧大禮包,跟着它一步一步實施,訓練9層ResNet時,不僅不需要增加GPU的數量,甚至只需要1/8的GPU,就能讓訓練速度加快到原來的2.5倍,模型在CIFAR10上還能達到94%的準確率。
甚至只需要26秒,就能訓練好一個模型。
這一」大禮包「由myrtle.ai開源。Jeff Dean稱讚道:
真是減少CIFAR10圖像模型訓練時間的好文章。其中許多技巧都可能適用於其他不同類型的模型。幹得漂亮。
奇技淫巧大禮包
myrtle.ai的奇技淫巧,都可以在Colab上測試,只需配置一個V100。(鏈接見文末)
話不多說,快來看看都是哪些神奇的技巧,造就飛一般的感覺。
基線方法消耗的總時間是75s。
GPU上的預處理(70s)
第一個技巧是,將數據傳輸到GPU,在GPU上進行預處理,然後再傳回CPU進行隨機數據擴增和批處理。
將整個數據集(unit8格式)移至GPU僅需要40ms,幾乎可以忽略不計,而在GPU上完成預處理步驟花費的時間則更少,大概只需要15ms。
這種做法下大部分的時間是消耗在數據集回傳CPU上,這需要將近500ms的時間。
往常的數據預處理方法會花費掉3s以上的時間,相比之下,這樣的處理方式已經把速度加快了不少。
不過,還可以更快。
那就是,不回傳CPU,直接在GPU上把數據擴增這一步也做了。
當然,蠻幹是不行的。爲了避免啓動多個GPU內核導致花銷變大,可以對樣本組應用相同的擴增,並通過預先對數據進行混洗的方式來保持隨機性。
具體的做法是這樣的:
以8×8的cutout爲例,即對CIFAR10圖像做8×8的隨機塊狀遮擋。
在32×32的圖像中有625個可能的8×8剪切區域,因此通過混洗數據集,將其分成625個組,每個組代表一個剪切區域,即可實現隨機擴增。
事實上,選擇大小均勻的組,與爲每個樣本進行隨機選擇並不完全相同,但也很接近。不過爲了進一步優化,如果應用同一種擴增的組的數量太大,可以對其設置一個合理的限制範圍。

如此一來,迭代24個epoch,並對其進行隨機裁減、水平翻轉、cutout數據擴增,以及數據混洗和批處理,只需要不到400ms。
還有一個好處是,CPU預處理隊列和GPU不用再相互賽跑,這樣就不必再擔心數據加載的問題了。
需要注意的是,這樣操作的前提是數據集足夠小,可以在GPU內存中作爲一個整體進行存儲和操作。但Nvidia DALI這樣的工業強度解決方案或許可以實現進一步的突破。
移動最大池化層(64s)
最大池化和ReLU的順序是可以交換的。經典的卷積池化是這樣:

可以把它調整成這樣:

切換順序將使24個epoch的訓練時間進一步減少3秒,而網絡功能完全沒有變化。
甚至還可以進一步把池化提前:

這能進一步使訓練時間縮短5秒,但會導致網絡的改變。不過實驗表明,這樣做對測試精度的負面影響很小,基線是94.1%,池化前移後會準確率會降到94.0%(50次運算的平均值),僅有0.1%的精度損失。
標籤平滑(59s)
標籤平滑是提高分類問題中神經網絡訓練速度和泛化的一個成熟技巧。
應用標籤平滑之後,測試精度能提高到94.2%(50次運算的平均值),這樣一來,就可以通過減少epoch的數量來換取訓練速度的提升。
CELU激活(52s)
平滑的激活函數對於優化過程也很有幫助。
因此可以選擇連續可微分指數線性單元或者CELU激活,來替代ReLU。
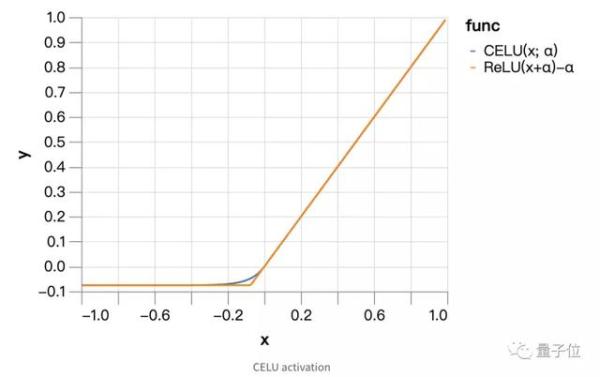
當平滑參數α爲0.075的時候,測試精度能達到94.3%,於是,與標籤平滑相比,又可以進一步減少epoch,速度也就從59s縮短到了52s。
Ghost批量歸一(46s)
批量歸一最合適的批量大小大概在32左右。
但在批量大小比較大的時候,比如512,降低其大小會嚴重影響訓練時間。不過這一問題可以通過對batch的子集分別進行批量歸一來解決,這種方法稱爲「ghost」批量歸一。
固定批量歸一規模(43s)
批量歸一規範了每個通道的均值和方差,但這取決於可學習的規模和偏差。
如果通道規模發生很大的變化,就可能會減少通道的有效數量而造成瓶頸。
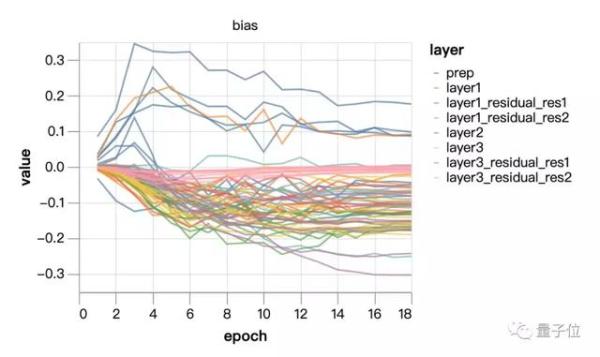
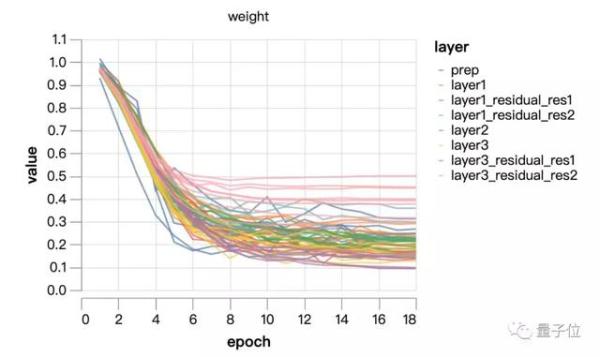
從上面這兩張圖中可以看出,規模並沒有進行太多學習,主要是在權重衰減的控制下進化。嘗試將規模固定在1/4的恆定值(訓練中點的平均值)。最後一層的可學習比例稍大,這可以通過調整網絡輸出的比例來進行補償。
實際上,如果將CELU的α參數重新調整爲補償因子4,批量歸一偏差的學習率和權重衰減分別爲4^2和(1/4)^2,則批量歸一規模就爲1。
需要說明的是,如果不提高批量歸一偏差的學習率,最終的準確率會非常低。
至此,在DAWNBench排行榜上,這一單GPU訓練出來的ResNet9訓練速度已經能超越8個GPU訓練出來的BaiduNet9了。
輸入塊(patch)白化(36s)
批量歸一可以很好地控制各個通道呃分佈,但不能解決通道和像素之間協方差的問題。所以,要引入「白化」版本來控制內部層的協方差。
myrtle.ai提出了一種基於patch的方法,該方法與總圖像的尺寸無關,並且更符合卷積網絡的結構。
將PCA白化應用於3×3的輸入塊,作爲具有固定(不可學習)權重的初始3×3卷積。這可以通過可學習的1×1卷積來實現。該層的27個輸入通道是原始的3×3×3輸入塊的變形,其協方差矩陣近於恆等式(identity),更易於優化。
首先,繪製輸入數據的3×3塊的協方差矩陣的前導特徵向量。括號中的數字是相應特徵值的平方根,以顯示沿這些方向的相對變化尺度,並繪製具有兩個符號的特徵向量以說明變化的方向。
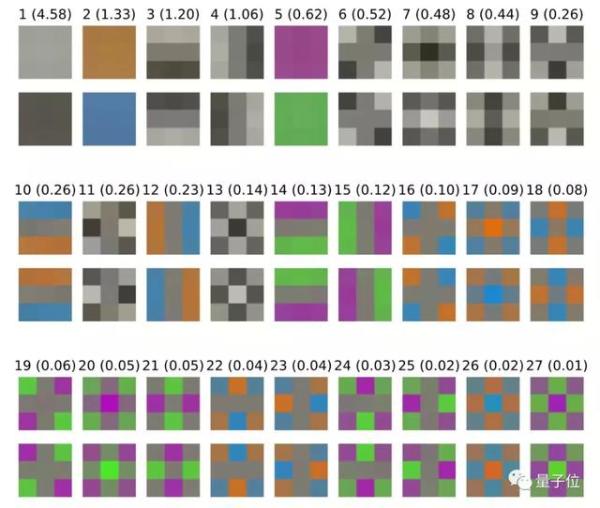
可以看出,局部亮度的變化佔據主導地位。
接下來,用固定的3×3白化卷積替換網絡的第一個3×3卷積,以均衡本徵塊的比例,而後用可學習的1×1卷積,並查看其對訓練的影響。
如果將最大學習率提高50%,並把剪切擴增的總量從8×8降至5×5,以補償更高的學習率帶來的額外正則化,就可以在36s內讓模型達到94.1的測試精度。
指數移動平均(34s)
高學習率,是快速訓練的必要條件,因爲它允許隨機梯度下降在有限的時間內在參數空間中通過必要的距離。
另一方面,學習速率需要在訓練結束時進行退火,以便在參數空間中沿着更陡峭和更嘈雜的方向進行優化。
參數平均方法允許以更快的速度繼續訓練,同時通過多次迭代進行平均,可以沿着有噪聲或振盪的方向接近最小值。
myrtle.ai發現,更頻繁的更新並不能改善情況,出於效率的原因,就每5個batch更新一次移動平均。
他們說,這需要選擇一個新的學習率計劃,在訓練接近尾聲時提高學習率,併爲移動平均提供動力。
對於學習速率,一個簡單的選擇就是堅持他們一直使用的分段線性時間表,在最後兩個epoch以一個較低的固定值表示,他們選擇的是一個0.99的動量,這樣平均就可以在大約上一個時期的時間尺度上進行。
測試精度提高到94.3%,也意味着可以進一步削減epoch。
最後的結果是:13個epoch訓練達到94.1%的測試精度,訓練時間低於34秒,比這一系列開始的時候單GPU表現提高了10倍!
測試狀態增強(26秒)
如果你想讓你的網絡在輸入的水平翻轉下,也能以相同的方式對圖像進行分類。
一種方法是向網絡提供大量的數據,通過保存左右翻轉的標籤來增強數據,然後希望網絡最終通過廣泛的訓練來學習不變性。
第二種方法,是同時呈現輸入圖像和水平翻轉後的圖像,並通過對兩個版本的網絡輸出進行平均來達成一致,從而保證不變性。
這種非常明智的方法被稱爲測試狀態增強(Test-time augmentation,TTA)。

在訓練時,myrtle.ai仍然向網絡呈現每個圖像的單一版本——可能會進行隨機翻轉來增強數據,以便在不同的訓練階段呈現不同的版本。
他們採取的另一個做法是,在訓練時使用與測試時相同的程序,並將每個圖像及其鏡像顯示出來。
在這種情況下,myrtle.ai可以通過將網絡分成兩個相同的分支來改變網絡,其中一個分支可以看到翻轉後的圖像,然後在最後合併。
通過這一視角,原始訓練可以被看作是一個權重綁定的隨機訓練過程,即兩個分支網絡,其中每個訓練示例都有一個分支被」dropped-out「。
這種dropout-訓練的觀點清楚地表明,任何試圖引入禁止測試狀態增強從基準中刪除的規則都將充滿困難。
從這個角度看,myrtle.ai剛剛介紹了一個更大的網絡,他們有一個有效的隨機訓練方法。
另一方面,如果myrtle.ai不限制準備在測試時做的工作量,那麼就會出現一些明顯的退化解決方案,其中訓練所需的時間與存儲數據集所需的時間一樣少!
這些參數不僅與人工基準測試相關,而且與最終的用例有關。在一些應用程序中,對分類精度有所要求,在這種情況下,絕對應該使用測試狀態增強。
在其他情況下,推斷時間也是一種約束,明智的做法是在這種約束下,將精度最大化。這可能也是一個訓練基準測試的好方法。
在目前的案例中,Kakao Brain團隊應用了這裏描述的測試狀態增強的簡單形式——在推斷時呈現圖像及其左右鏡像,從而使計算量加倍。
當然,對於其他對稱(如平移對稱、亮度/顏色的變化等)來說,測試狀態增強的應用也會更廣泛,但這將付出更高的計算成本。
現在,由於目前是基於一個計算量較少的9層ResNet,因此包括測試狀態增強在內的總推斷時間,可能比100多個層網絡中要短得多。
根據上面的討論,任何限制這種方法的合理規則,都應該基於推斷時間約束,而不是實現的功能,因此從這個角度來看,myrtle.ai團隊說,應該接受這種方法。
爲了與當前DAWNBench提交數值的一致,他們將限制自己使用水平翻轉測試狀態增強,因爲這似乎是準確性和推斷成本之間的最優平衡點。
最後的結果是:在現有的網絡和13個epoch訓練設置下,測試狀態增強的精度提高到94.6%。
如果移除了對剩餘數據的增強操作,可以將訓練減少到 10 個 epoch,而且能在26 秒實現測試狀態增強精度——94.1%。
訓練效果
單塊GPU就能有這麼快的速度,效果又如何呢?myrtle.ai團隊還用了ImageNet來驗證。
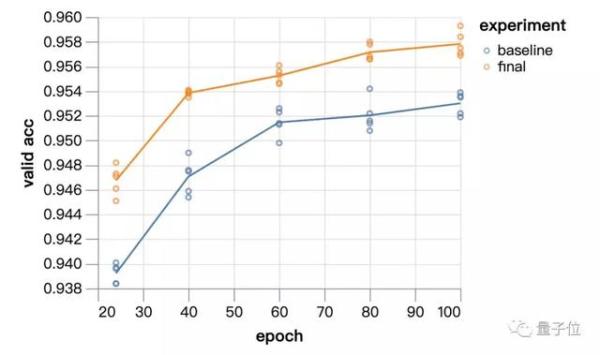
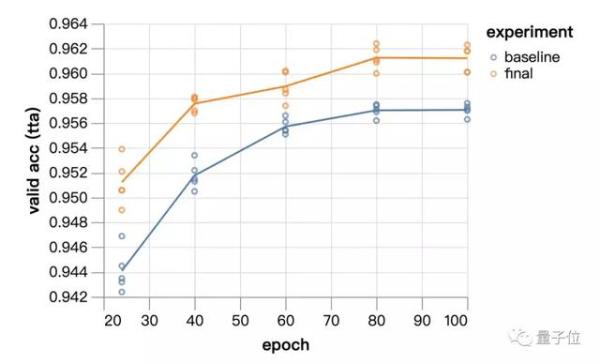
從24個epoch到100個epoch,實驗模型的表現始終優於基線方法。
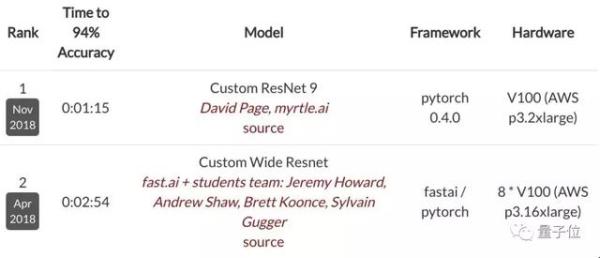
用上了奇技淫巧大禮包的9層ResNet其實去年11月就登上了DAWNBench CIFAR10排行榜的榜首,速度提高近2.5倍,而GPU從8個降到了1個。
DAWNBench是斯坦福大學提出的基準,在這一排行榜中,準確度只要達到94%即可。
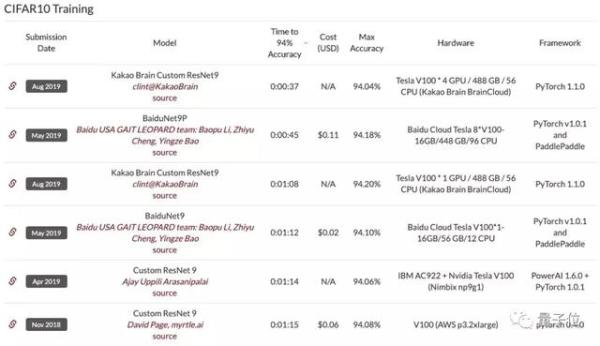
現在,雖然這一登頂成績已經滑落到了第六位,但myrtle.ai表示在使用了與榜首Kakao Brain相同的TTA方法之後,實驗模型的訓練速度能降至26秒,超過Kakao Brain近10秒。
傳送門
博客地址:
https://myrtle.ai/how-to-train-your-resnet-8-bag-of-tricks/
Colab地址:
GitHub地址:
https://github.com/davidcpage/cifar10-fast/blob/master/bag_of_tricks.ipynb
— 完 —