兩年一度AI頂會ICCV已經召開,今年在韓國首爾舉辦。
隨着論文收錄名單揭曉,大會也進入放榜收穫時刻。
騰訊旗下頂級視覺研發平臺騰訊優圖,官宣有13篇論文入選,居業界實驗室前列,其中3篇被選做口頭報告(Oral),該類論文佔總投稿數的4.3%(200/4323)。
ICCV——國際計算機視覺大會,英文全稱International Conference on Computer Vision。
被譽爲計算機視覺領域三大頂級會議之一,與CVPR和ECCV並列,錄用率非常低,其論文集代表了計算機視覺領域最新的發展方向和水平。
本屆ICCV共收到4323篇論文投稿,其中1075篇被錄用,錄取率25%。
而優圖入圍的13篇論文中,涉及2D圖像多視圖生成、人臉照片的圖像轉換等喜聞樂見研究。
我們選取其中代表性的2篇初步解析,2篇均有賈佳亞教授參與,詳細論文見傳送門。

2篇論文
基於視角無關特徵的多視圖對抗生成框架
View Independent Generative Adversarial Network for Novel View Synthesis
本論文與香港中文大學合作完成,論文入選Oral。
2D圖像的多視圖生成任務,指的是基於單張2D圖像,生成其不同視角下的圖像信息。
此類方法可以在不涉及複雜的三維重建的基礎上,實現多個視角下的信息的合成觀察。
例如下圖中給定特定視角的2D圖像,可以生成其他各個視角的圖像信息:

該論文提出了一種適用於此類任務的對抗生成框架,旨在通過結合圖像對應的相機參數信息,實現對於多類物體均適用的多視角轉換框架。
長遠來看,這項技術的應用有望讓普通的2D視頻也能實現3D觀感,就像在電影院觀看的3D電影一樣。
現有的多視圖生成任務中,當前基於生成模型的方法將預先提取輸入圖像中與視角信息無關的特徵,而後將視角信息相關的參數作用於此特徵,進而得到生成的結果。
該論文中,作者使用此種思路,配合以多種損失函數的設置,利用相機參數加上圖像信息來得到與視角無關的特徵。
相比於現有的方法,該方法適用於連續相機參數下的多視圖生成,並不限制於數個固定的視角。
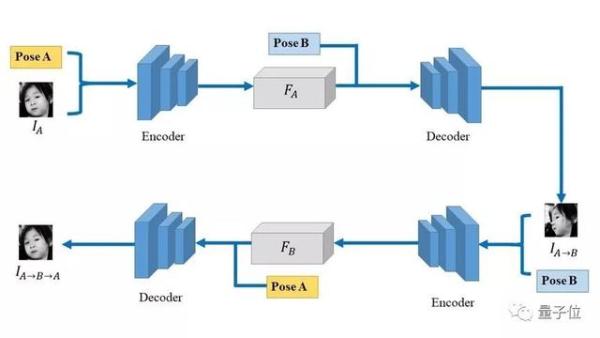
除了合成視圖與監督信息之間的損失函數之外,本文提出使用一種基於循環生成的重建損失函數,來提升合成視圖的準確性;同時借鑑目前的對抗生成技術,從圖像本身的生成分佈,與圖像的姿態準確性保證兩方面出發,提出兩個不同作用的對抗學習損失,以提升生成圖像的質量和合成視圖的姿態準確度。
該框架可以適用於不同類別的物體。
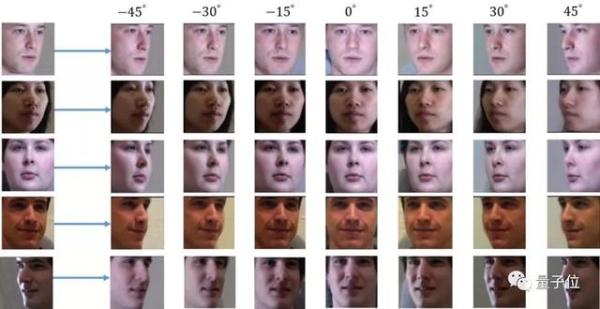
首先是人臉在預先設定的有限數目的視角之間的轉換結果。最左邊是輸入的2D圖像,箭頭右側均爲生成的,不同視角下的結果。
應對其他一般的物體。通過在Shape-Net這個數據集上的多個類別物體作爲數據,得到以下結果:

通過在多個類別的物體上進行多視圖生成任務,利用多個定量定性指標來進行評價,證明該方法具有通用性,且在多個類別任務上表現良好。
基於屬性自光流域的非監督圖像轉換算法
Attribute-Driven Spontaneous Motion in Unpaired Image Translation

△微笑表情轉換結果圖。從左到右依次爲:輸入、StarGAN結果、該論文結果
本論文與香港中文大學、哈工大深圳研究院合作完成。
人臉照片隨着社交軟件的普及被大幅度地應用於各種社交應用中,而人臉照片的自動化編輯一方面作爲社交軟件的娛樂應用促進了社交用戶的交流,另一方面也幫助用戶對人臉照片進行快速的自動化編輯。
由於深度學習的興起,基於深度神經網絡的圖像轉換(Image translation)技術常常被應用於圖像編輯任務上。
現有的圖像變換算法主要基於生成對抗神經網絡,這些算法儘管能生成較高分辨率的圖像,但由於它們較少考慮圖像之間的幾何變形關係,轉換後的圖像往往包含許多瑕疵和失真,尤其是在原圖像域和目標圖像域幾何結構不一致的情況下。
本論文提出了SPM(自光流模塊),希望通過學習不同圖像域間的光流解決圖像的幾何變換問題。
其框架以傳統的生成器-判別器作爲基礎,其中,生成器用於生成更好的圖像,而判別器用於判別生成器生成圖像的質量好壞。
此外,他們在生成器的基礎網絡結構上做出擴展以適應圖像轉換之中的幾何變換。
擴展後的生成器包含兩個主要模塊,自光流模塊SPM和微調模塊R。
最後,該論文還引入了從低分辨率圖像到高分辨率的生成方案。

△整體框架圖
本文提出的自光流模塊,通過輸入原圖像和目標屬性,自光流域模塊旨在預測光流,並利用光流對原圖像採用變形操作得到中間結果圖像。
該論文利用一個編碼-解碼網絡作爲該模塊的主要結構,其中他們主要考慮了網絡結構、域分類器、微調模塊、殘差結構、注意力掩碼幾方面的設計。
同時,爲了產生更高分辨率的圖像,該論文采用了一種新穎的粗到細的神經網絡訓練策略。
在訓練好低分辨的神經網絡後會有許多中間結果的低分辨率表示。
具體地,低分辨率的自光流域w殘差r以及注意力掩碼m是已知的。爲了得到它們的高分辨率表示,首先對它們進行雙線性插值上採樣到分辨率更高的w, r以及m。
但是通過雙線性插值的上採樣所得到的結果往往是模糊的,因此對於這三個變量他們引入了三個小的增強神經網絡對上採樣的結果進行微調。
利用微調後的高分辨率中間結果,我們即可對高分辨率的輸入圖像進行處理和轉換,並最後得到相應的高分辨轉換結果。

如圖所示,RaFD數據集上的圖像轉換結果,從左到右依次爲:輸入、憤怒、驚恐、開心(後三個爲算法生成結果)。
本論文通過提出自光流模塊,將圖像域間的幾何變換顯式地引入到了圖像轉換框架中。算法主要在CelebA-HQ和RaFD數據集上進行驗證,其結果相比於現有算法都有一定的提升。
其各部分的實驗充分證明了該框架的有效性,並且取得了很好的圖像轉換效果。
這一框架也給解決圖像轉換中的幾何變換問題提供了新的解決思路。
傳送門:
基於視角無關特徵的多視圖對抗生成框架