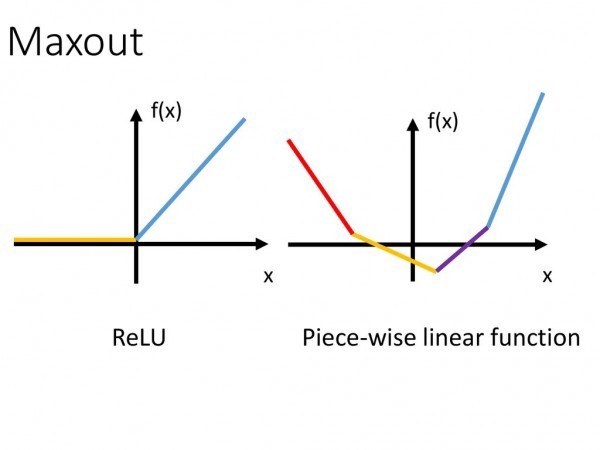
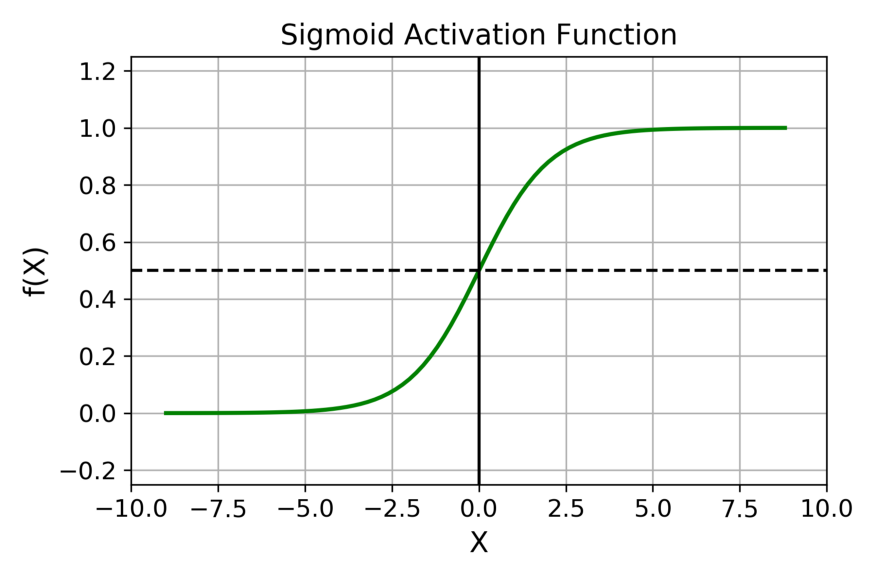
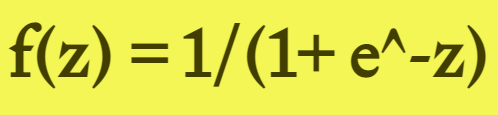
Sigmoid 函數的輸出範圍是 0 到 1。由於輸出值限定在 0 到 1,因此它對每個神經元的輸出進行了歸一化;
用於將預測概率作爲輸出的模型。由於概率的取值範圍是 0 到 1,因此 Sigmoid 函數非常合適;
梯度平滑,避免「跳躍」的輸出值;
函數是可微的。這意味着可以找到任意兩個點的 sigmoid 曲線的斜率;
明確的預測,即非常接近 1 或 0。
傾向於梯度消失;
函數輸出不是以 0 爲中心的,這會降低權重更新的效率;
Sigmoid 函數執行指數運算,計算機運行得較慢。
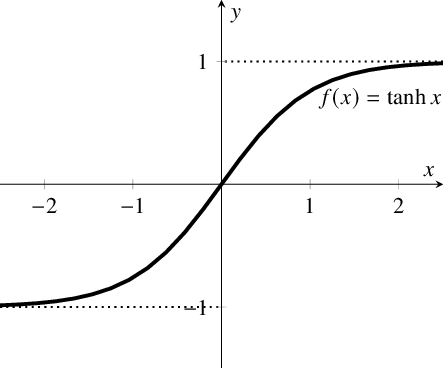

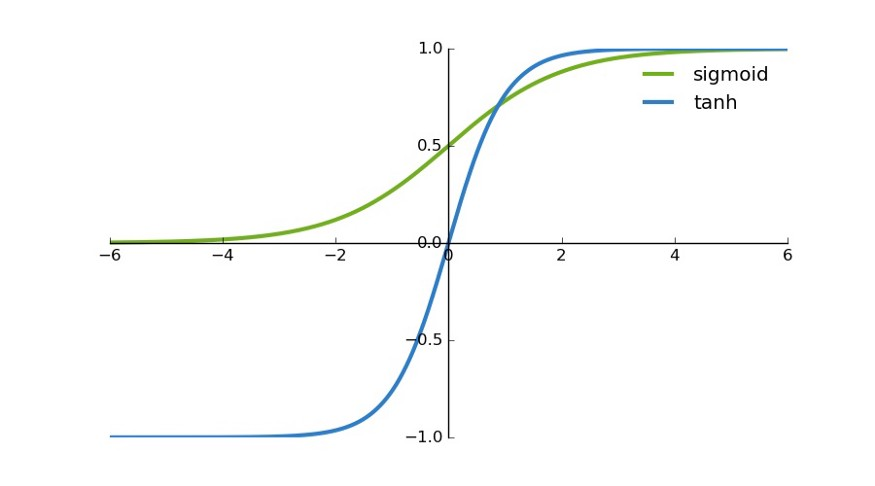
首先,當輸入較大或較小時,輸出幾乎是平滑的並且梯度較小,這不利於權重更新。二者的區別在於輸出間隔,tanh 的輸出間隔爲 1,並且整個函數以 0 爲中心,比 sigmoid 函數更好;
在 tanh 圖中,負輸入將被強映射爲負,而零輸入被映射爲接近零。


當輸入爲正時,不存在梯度飽和問題。
計算速度快得多。ReLU 函數中只存在線性關係,因此它的計算速度比 sigmoid 和 tanh 更快。
Dead ReLU 問題。當輸入爲負時,ReLU 完全失效,在正向傳播過程中,這不是問題。有些區域很敏感,有些則不敏感。但是在反向傳播過程中,如果輸入負數,則梯度將完全爲零,sigmoid 函數和 tanh 函數也具有相同的問題;
我們發現 ReLU 函數的輸出爲 0 或正數,這意味着 ReLU 函數不是以 0 爲中心的函數。
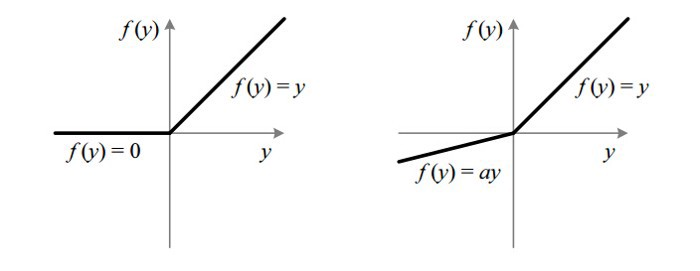

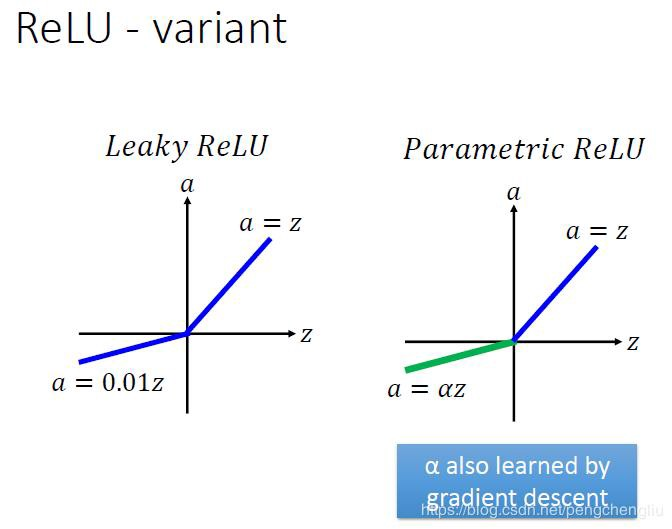
Leaky ReLU 通過把 x 的非常小的線性分量給予負輸入(0.01x)來調整負值的零梯度(zero gradients)問題;
leak 有助於擴大 ReLU 函數的範圍,通常 a 的值爲 0.01 左右;
Leaky ReLU 的函數範圍是(負無窮到正無窮)。


沒有 Dead ReLU 問題,輸出的平均值接近 0,以 0 爲中心;
ELU 通過減少偏置偏移的影響,使正常梯度更接近於單位自然梯度,從而使均值向零加速學習;
ELU 在較小的輸入下會飽和至負值,從而減少前向傳播的變異和信息。

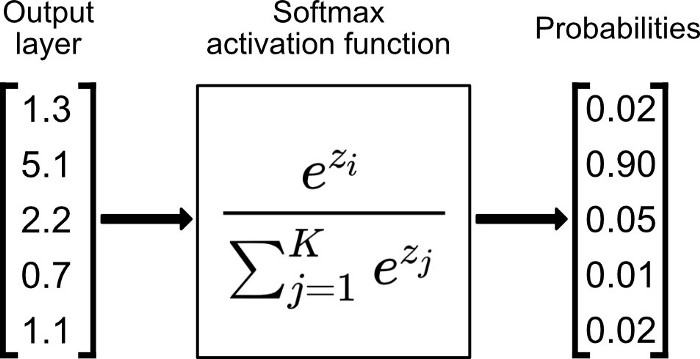
如果 a_i= 0,則 f 變爲 ReLU
如果 a_i> 0,則 f 變爲 leaky ReLU
如果 a_i 是可學習的參數,則 f 變爲 PReLU
在負值域,PReLU 的斜率較小,這也可以避免 Dead ReLU 問題。
與 ELU 相比,PReLU 在負值域是線性運算。儘管斜率很小,但不會趨於 0。

在零點不可微;
負輸入的梯度爲零,這意味着對於該區域的激活,權重不會在反向傳播期間更新,因此會產生永不激活的死亡神經元。
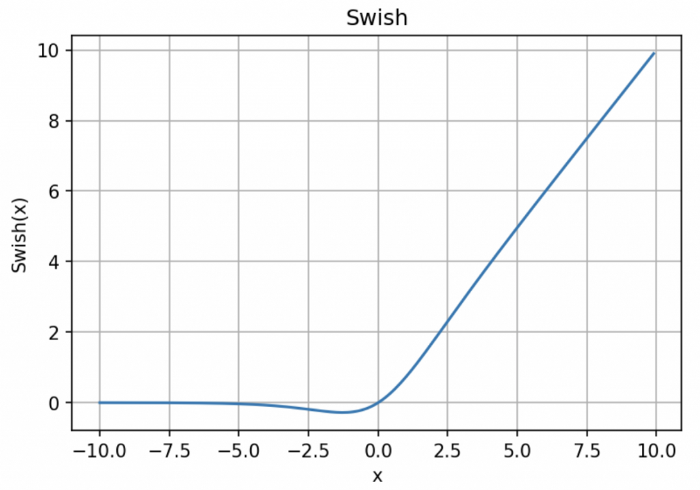
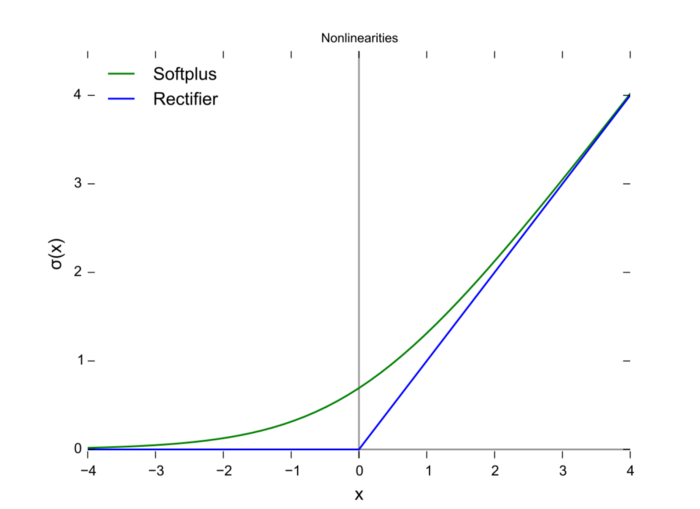
「無界性」有助於防止慢速訓練期間,梯度逐漸接近 0 並導致飽和;(同時,有界性也是有優勢的,因爲有界激活函數可以具有很強的正則化,並且較大的負輸入問題也能解決);
導數恆 > 0;
平滑度在優化和泛化中起了重要作用。