近年來,圖表示學習(Graph Embedding)和圖神經網絡(Graph Neural Network, GNN)成爲網絡數據分析與應用的熱點研究問題,其特點是將深度神經網絡技術用於網絡結構的建模與計算,誕生了以 DeepWalk、LINE 和 node2vec 爲代表的圖表示學習技術,以 GCN 爲代表的圖神經網絡,能夠利用分佈式表示方案實現對網絡中的節點、邊及其附帶的標籤、屬性和文本等信息的建模,從而更好地利用網絡結構進行精細建模和深度推理,相關技術已經被廣泛用於數據挖掘、社會網絡分析、推薦系統、自然語言處理、知識圖譜等領域。
爲了推進國內在該領域的發展,由中國中文信息學會社會媒體處理專委會和北京智源人工智能研究院聯合主辦的「圖神經網絡在線研討會 2020」於 3 月 29 日下午召開,邀請了宋國傑、沈華偉、唐傑、石川四位國內著名學者介紹圖表示學習和圖神經網絡的最新理論進展和應用探索。
清華大學計算機系教授、系副主任,中國中文信息學會社會媒體處理專委會常務副主任,智源研究院學術副院長唐傑老師進行了主題爲「圖表示學習和圖神經網絡的最新理論進展」的分享,主要介紹了圖神經網絡及其在認知推理方向的一些進展。
唐傑老師主要研究興趣包括人工智能、認知圖譜、數據挖掘、社交網絡和機器學習,主持研發研究者社交網絡挖掘系統 AMiner 等。
以下內容是根據唐傑老師的演講進行的總結。
我們正在經歷第三次人工智能浪潮,世界上很多國家都推出了相應的戰略和發展規劃。但也有人說第三次人工智能浪潮已經接近尾聲,馬上就要到達「冰點」,第四次浪潮已經在醞釀之中。關於下一次浪潮的具體內容,今天暫時不做過多的討論,我們先剖析一下這次浪潮的具體情況。
AI 這幾年發展很快,其中一個重要原因是產業界的很多研究者、資源加入進來,一起推動 AI 的發展,如谷歌的 AlphaGo 和無人駕駛汽車。國內的相關企業也在蓬勃發展,從我的角度來說,我們做的事和硬件的關聯沒那麼緊密,很多的是偏軟件的東西,比如在圖片識別過程中,我們更關注怎麼將其中的語義信息抽取、識別出來,怎麼把文本的語義信息和圖片的語義信息混合起來做計算等。比如下圖,通過將一張狗的圖片減去關鍵詞「dog」,再加上關鍵詞「cat」,從而將貓的圖片識別出來。

這就是一個典型的多媒體的數據,在兩個方面怎麼做處理是我們當下最關心的一些的問題。人工智能在這方面快速發展,總結一下:這個時代是一個感知的時代,AI 到目前爲止基本上解決了所有的感知問題。如果回顧過去的話,會發現計算機主要是做一些存儲和計算的工作;如果展望未來的話,我們想倡導的應該是在認知方面怎麼把計算、推理做到神經網絡中。
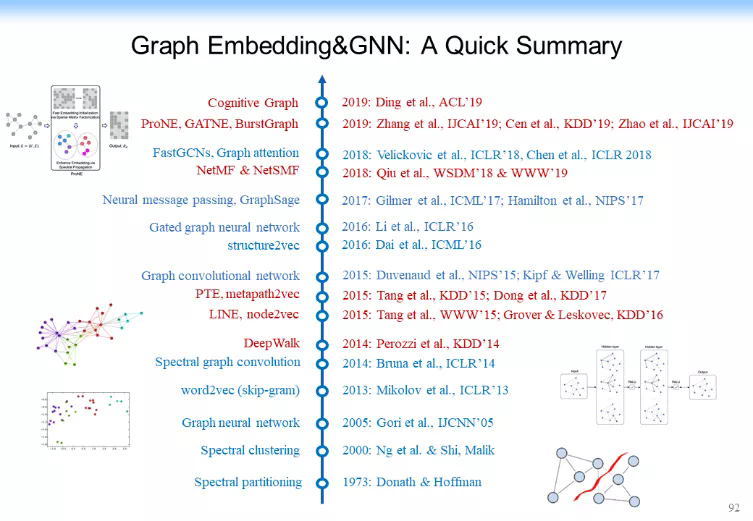
現在這個感知時代最大的特點是算法。下面這張圖彙總了最近幾十年 AI 算法的一些進展。

這張圖最上面的淺紫色的部分大致梳理了卷積神經網絡的發展歷史。1953 年,感知機(Perceptron)被提出來。1986 年,多層感知機(Multi-Layer Perception,MLP)開始出現。1998 年,Yann Le Cun 提出手寫字體識別模型 LeNet 及卷積神經網絡(CNN),但是當時 CNN 並沒有大規模被人關注,因爲當時大火的支持向量機(SVM)壓住了 CNN 的風頭。直到 2012 年,Geoffrey Hinton 的學生在 LeNet 的基礎上加上了 ReLU、Dropout 等內容,實現了 AlexNet,把 CNN 的效率大規模提高,才推動了這個方向的發展。
第二部分淡綠色部分的內容表示自編碼(AutoEncoder),這部分不是今天的重點,不再展開。
第三層淺黃色的部分可以被稱爲循環神經網絡(Recurrent Neural Network, RNN)的發展。放大來看,它的理論和上面的一樣優美,它其實就是一個概率統計模型,即把神經網絡用圖的方式連接起來,雖然最早期的時候大家做的都是序列化的模型,如 RNN,或者是在語言模型(Language Model)上面做一些相關的工作,甚至是Seq2Seq,但是最近更多的工作是在圖上,如唐建他們有一篇文章就是把圖模型(Graphical Model)加上神經網絡,一起連接起來,於是就變成一個基於圖模型的神經網絡(Graphical Model based Neural Network)。
如果結合最上面淺紫色的內容和淺黃色的內容,即把卷積神經網絡加上圖模型,這形成我們今天經常說的圖神經網絡的基本思想。
可以看出來,圖神經網絡有很長的歷史,是一個非常簡單的機器學習算法在圖上的一個自然地延伸。爲什麼現在大家覺得圖神經網絡火得不行?好像所有的人都在研究圖神經網絡?也有些人說這個東西是簡單地把某些東西用在另一個數據集上?其實機器學習所有的發展歷史都有這樣一個過程,它最早期都是從一個簡單的單樣本分析開始,然後逐步複雜化,最後再把樣本與樣本之間的關聯關係考慮進來,如圖神經網絡就是用一個簡單的思路把它結合起來。最早的線性條件隨機場(Conditional Random field,CRF)、最大熵馬爾可夫模型(Maximum Entropy Markov Model,MEMM)等模型的思路都是在原來的思路上擴展的。GNN就是神經網絡在圖上的一個自然地延伸。當然,這一波自然延伸的結果是必然有下一波階躍。如原來在圖模型上有了 CRF、MEMM 以後,概率統計模型基本到了一個極致,後續延伸自然就到了下一個階段。
最下面是一個強化學習(Reinforcement Learning),這裏也不再多講。
回到我們的背景。既然有 CNN、有大量網絡化的數據,就可以做很多相關的研究。
首先,這些數據的規模非常大。如阿里巴巴、Facebook、新浪微博等積累了超大規模的社交網絡數據,如果泛化來看,我們還有經濟方面的網絡(Economic networks)、生物醫學方面的網絡(Biomedical networks)……甚至還有大腦中神經元的網絡(Networks of neurons),這裏面有很多相關的應用,如果從機器學習的角度歸納一下相關的應用,可以發現以下幾個核心的任務。

下面詳細展開介紹一下。
(1)點分類,做一個點的表示,然後做預測它的類型是什麼。
(2)兩個點的鏈接生成,如兩個點之間有沒有可能生成一條邊,或者再放大來看,看有沒有可能找到一個子圖,或者找網絡相似度。這個方面在過去有很多相關的研究,今天我們會大概涉獵這些東西。這方面最早的研究可以追溯到 Geoffrey Hinton 研究的分佈式表示(Distributed representation),但是這個概念在當時被 SVM 壓制,一直沒有火起來,直到 2013 年 Tomas Mikolov 提出了非常快速的算法 Word2vec,才迅速讓深度學習算法在文本分析領域快速落地。到了 2014 年,Bryan Perozzi 很巧妙地將 Word2vec 直接用到了神經網絡中,開啓了在網絡中做表示學習的浪潮,後來唐建、Yann Le Cun、Max Welling 等都做出了大量的工作,最後整個這方面的研究形成了我們今天看到的 GNN,如果放到更高的層面去看,就是網絡表示學習這麼一個領域。
這個問題爲什麼比較難呢?這是因爲:(1)如果我們用 CNN 或者相關的算法在圖片上做學習,由於圖片是典型的二維的、有上下之分,每個點上、下、前、後、左、右是什麼很清楚,但是在網絡中,它是一個複雜的拓撲結構,甚至沒辦法用上、下描述,只能用拓撲結構來說明,或者說兩個節點的距離有多遠,而沒有一個嚴格的空間的概念。(2)節點之間沒有文本那樣的先後關係;(3) 整個網絡是非常動態的,並且可能有一些相關的信息、相關的屬性。比如做一個人的行爲分析的話,某個節點可能有很多的屬性信息,還有很多網絡結構的屬性和信息,我們可以把網絡結構的表示學出來,還可以把網絡屬性的表示學出來,這就有兩種不同的表示。有時候人們可能還發出一些圖片、語音等其他媒體的信息,怎麼把這些表示都學出來非常困難。
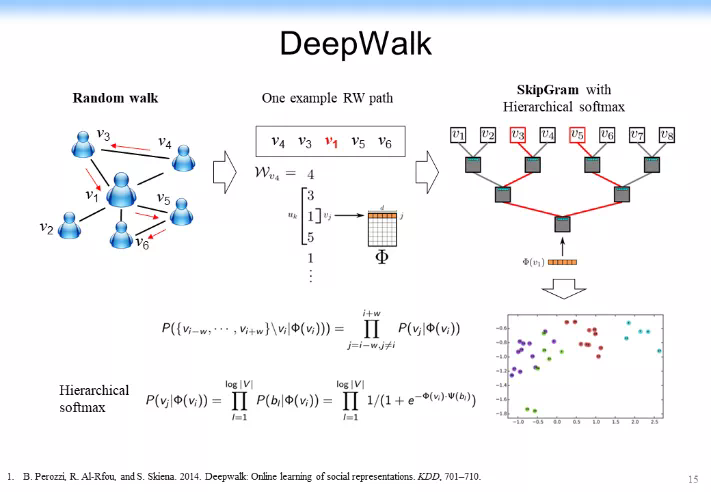
最早在網絡上做表示學習是把整個研究規約到一個很簡單的 Word2vec 問題上,就是我說的 DeepWalk 的思路,即用 word2vec 的思路來做網絡的表示學習。這個思路非常簡單,即 word2vec 就是上下位,如果上下位相同的單詞,他的意思就比較相似,於是學出來的表示也比較相似,如下圖所示。

在網絡表示學習中,DeepWalk 的思路是:既然節點沒有先後關係,就做一個先後關係。從任意一個節點開始,在上面跑一個隨機遊走(Random Walk),跑完了以後可以形成了一個序列,形成一個和 DeepWalk 處理文本一樣的上下位信息,於是 v1 這個節點就由 v3、v4、v5、v6 作爲它的上下位,剩下給一個隨機的低維表示,然後在上面進行 SkipGram with Hierarchical softmax 的一個學習,最後就可以得到一個希望的表示結果,如下圖所示。
這裏做 SkipGram with Hierarchical softmax 是爲了提高計算速度,不再詳細說明。最後的參數學習可以用一個基於梯度的學習很快做到。
這篇文章最初在當時並沒有引起大規模的關注,但是它開啓了一個在網絡中做表示學習的新紀元。最初大家覺得在網絡中做表示學習是一件很麻煩的事,後來發現神經網絡可以用在網絡中,可以學習每個節點的表示,並且學到的表示可能可以用於不同的網絡,如 Blog Catalog,使得它的效果還不錯。後來又試了其他的網絡,如 Youtube 中的網絡,發現效果也不錯。後來就引起了大規模的相關的研究,討論怎麼來提高在網絡上做表學習的效果。於是大家就分析 DeepWalk 的一些缺點。
首先它的上下文是固定的,而它的隨機遊走並沒有考慮到網絡的特性,於是後面一大堆的研究,如 LINE 等。下圖中 5 和 6 這兩個節點根據我們人的行爲來看是很相似的。5 和 6 有四個相近節點(1、2、3、4),但是 6 和 7 是直連的。如果用剛纔的 DeepWalk,即 RandomWalk 在上面隨機遊走,6 和 7 可能距離反而更近,它的相似度反而更高。

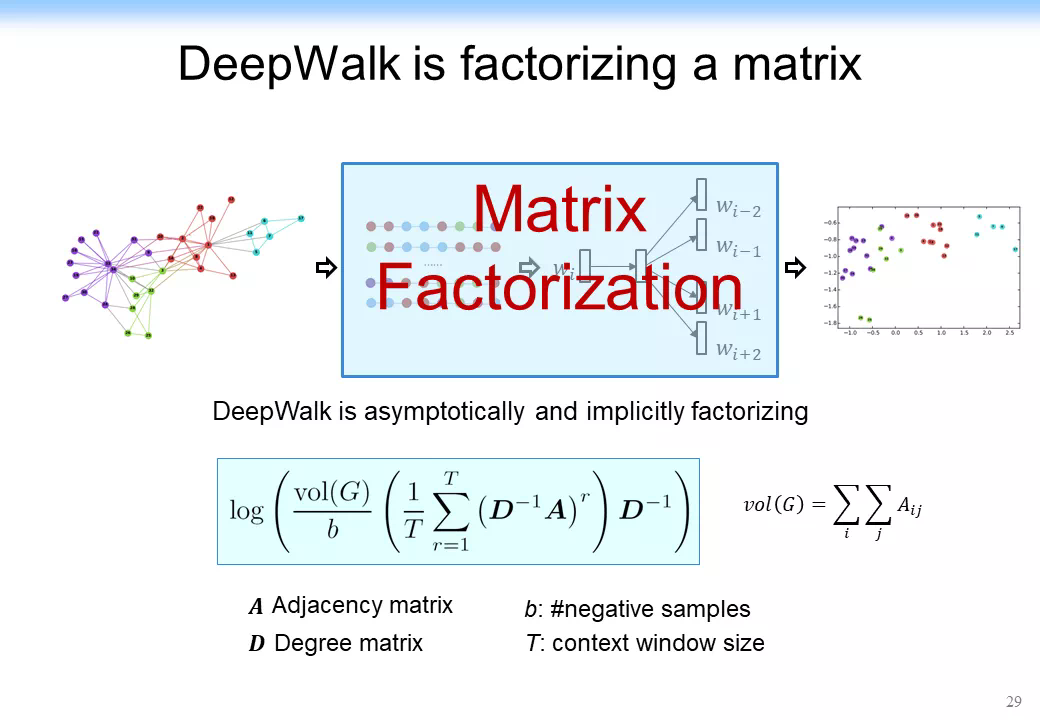
通過數學分析 我們 發現 最簡單的網絡表示學習 在 本質上都是在做一個矩陣分解 , 在做一個 奇異值分解 ( S ingular V alue D ecomposition , SVD ) , 只是分解的形式不一樣 , 如下圖所示 。DeepWalk 分解的是第 1 個式子,LINE 分解的是第 2 個式子,PTE 分解了一個異構的網絡,node2vec 分解了一個更復雜的網絡,因爲它裏面考慮到了三個節點形成的矩陣。



但是這樣又出現了新的問題:我們現在怎麼來做 GNN 或者圖神經網絡呢?畢竟在圖神經網絡中要結合網絡化的信息,如剛纔提到的網絡表示學習結合的是一個上下文信息,用上下文信息做這種網絡表示學習,怎麼真的把這種網絡結構化的信息利用上,而且要讓他速度特別快呢?
我們首先做了一個很巧妙的事情,我們做了一個被稱爲 ProNE 的算法,如下圖所示。
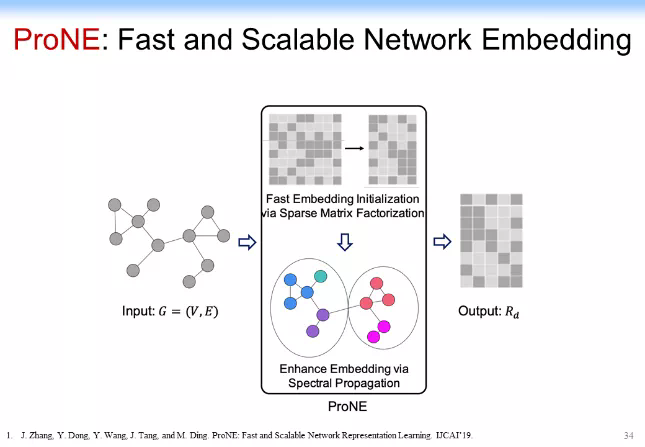
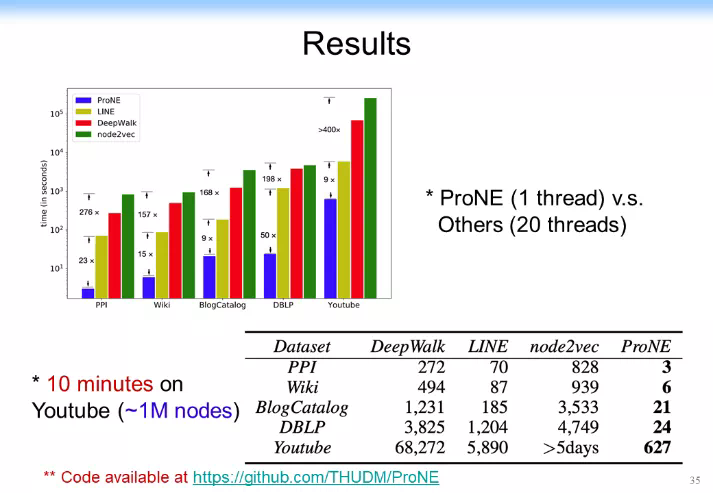
大家可以想象一下,如果我們做一個特別快速的 SVD 分解(如做一個線性的算法,基本做到點和邊成線性關係),同時,把剛纔學到的低維表示在所有的邊上做傳播,事實上跟這個邊又呈線性關係,於是整個算法可以做成一個跟網絡節點和邊呈線性關係的一個算法,這樣的話整個算法的模型會就可以做得非常快。有人提到說這個可能複雜度很高,對此我要再解釋一下,如果我們做一個非常快速的 SVD 分解,我們可以做一個線性算法,比原來傳統的 SVD 算法快兩個數量級,它基本上是個線性關係。舉一個例子。下圖是我們跑出來的一個結果。我們是 ProNE 加上普傳播得到的一個結果,可以看到結果比原來最快的LINE快一個數量級,比 node2vec 快兩個數量級。而且我們最近還發現另外一個算法,它可以比原來 randomize 的 TSVD 分解還要再快一個數量級,甚至加上譜傳播都可以比其他兩個速度還要快。
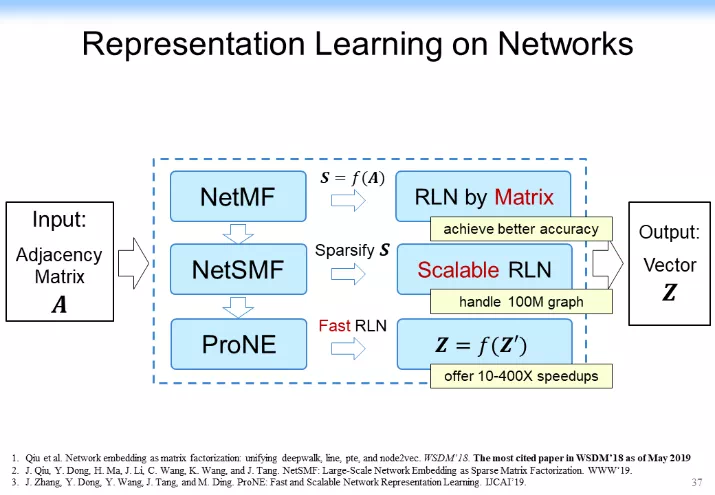
以上就是快速回顧了一下網絡表示學習的一些東西。這裏主要是講的 NetMF(也就是矩陣分解)及傳播的一些東西,如下圖所示。下圖中間這一部分沒有講,大家有興趣也可以去看一下。我們主要是把 NetMF 做了稀疏化,做了一個理論分析,給大家可以在理論上做了一個保證。
現在是 GNN 的時代
這個問題現在其實是個悖論。首先,很多人說我們要把原來的 Shallow 的神經網絡變成深度的神經網絡,這樣可能會提高效果,但是這導致了兩個嚴重的問題。
第一個嚴重的問題是網絡到底要多深纔算深?比如說在網絡中,假如我們真的做了很多深層次的話,如果每一次深層次的都是在做一個鄰居節點的傳播,這時候深層次、很深的網絡會導致這個信息就擴散整個網絡了,這個時候就導致一個過平滑(over-smooth)的問題,而不是過擬合 (Overfitting)。另外一個問題就是整個網絡的深度學習假如都像剛纔都是矩陣分解,如果沒有一個非線性的變化,所有的矩陣分解就讓它深度下去,它其實本質上還是一個矩陣分解。這個到底是怎麼回事呢?我們在這裏做一定的分析。在 GNN 中我們其實分解的就是下圖這樣一個簡單的矩陣。這是一個鄰接矩陣,H 是上一層的隱變量,W 是權重,激活函數是非線性的。其實之前有研究已經證明了,GCN 如果沒有這個激活函數的話,整個 GCN 其實可以退化成一個非常簡單的矩陣,而且效果還有可能更好。所以這也是一個悖論,等一下我們也在後面再探討一下。

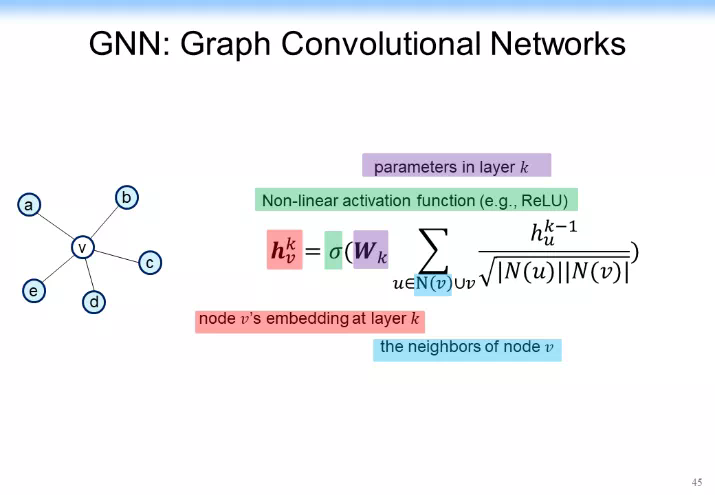
在探討之前,我們先快速說明一下 GCN 的本質。GCN 的本質其實就是在一個網絡中把鄰居節點的表示信息放到自己當前節點上。比如說對於下圖中 v 節點來講,它有鄰居節點 a、b、c、d、e,每一個節點可能都有一個表示(從 ha 到 he)。
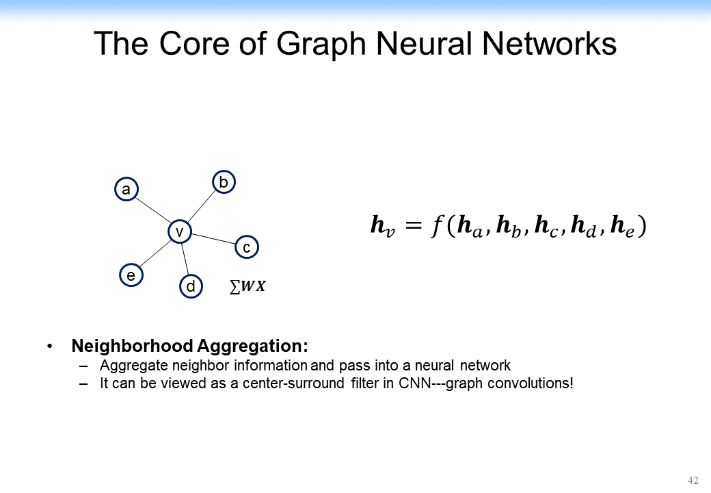
怎麼把鄰居節點的引表示通過某種方法或某種函數(如 f 函數可能是線性變化,也可能是個非線性變化),把它 Aggregate 到當前節點,得到 hv。當然,從下圖所示的內容裏表示我們就可以看出一個結果:左邊給出了一個在鄰居節點身上做的卷積,得到對當前節點進行卷積的結果。
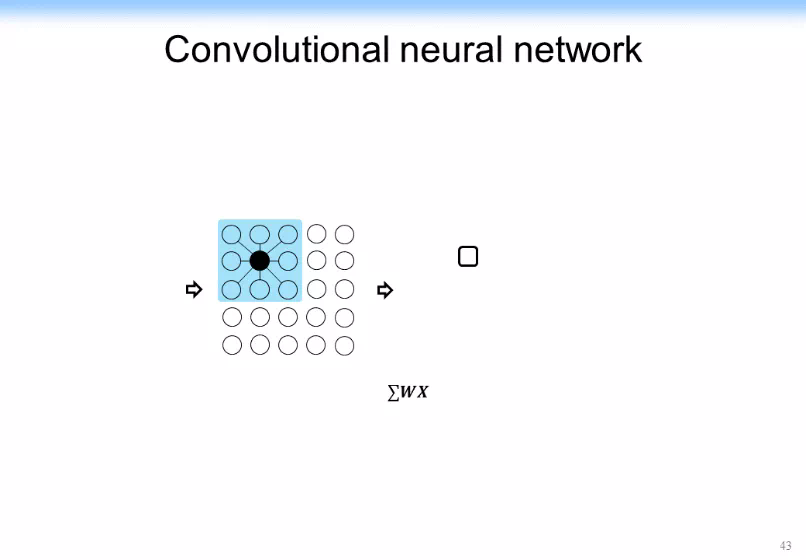
我們可以構造出一個加上了非線性的激活函數的函數,如下圖所示。是權重,是鄰居節點。是當前節點的表示, v 是當前節點,另外還有一個非線性的激活函數。
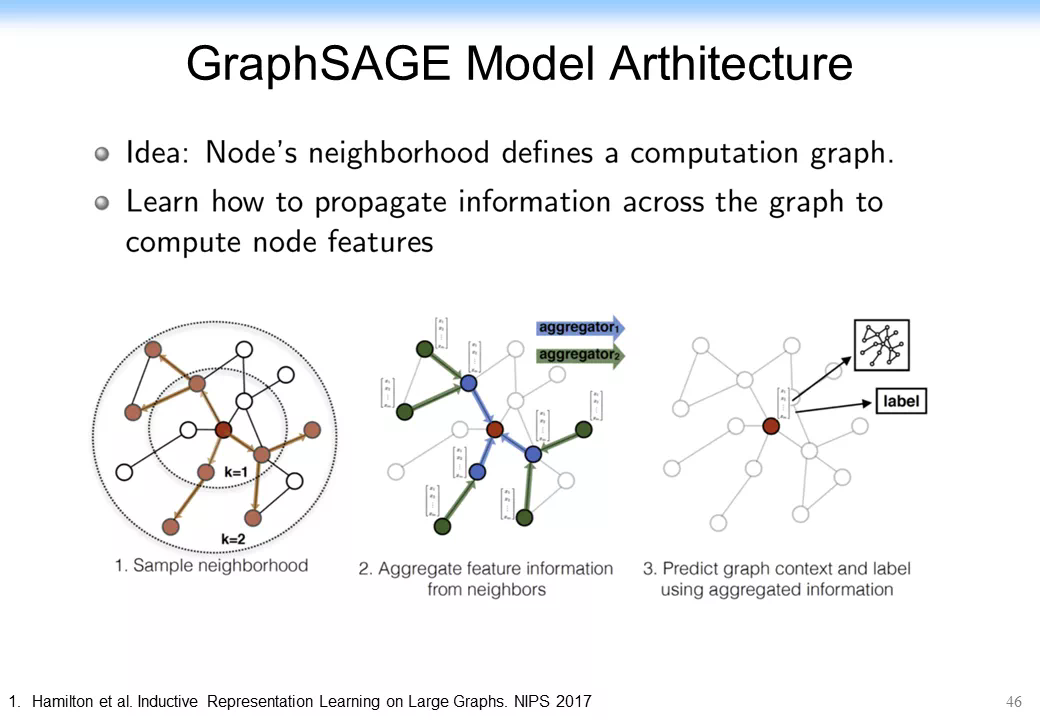
基於這樣的思想,後來在最早的 GCN 相關的論文上也有很多的延續,如 GraphSage。GraphSage 的思想非常簡單,它把原來單純的當前節點和其他所有節點的聚合整合到一起了,變成當前節點的表示和其他所有節點的表示連接在一起,如下圖所示。這樣的話效果反而提高了。
這個思路後來又被 GAT 給打敗了,GAT 是什麼?我們現在 aggregate 的時候,也就是每個節點信息往中間節點傳的時候,它的權重不一樣。從 Social network 的角度來說,它的本質就是影響力不一樣,就相當於某個節點對其他的不同的節點的影響是不一樣的。怎麼把這種影響力在網絡中度量,是社交網絡區別於其他很多網絡一個非常重要的方面。當然,從數學上可以把 GCN 看作是下圖上方的式子,而 GAT 是下圖下方的式子,可以看到唯一的變化就是加上了一個 Attention 參數,這樣的話可以看一些初步的結果,加上 Attention 參數的效果確實比原有算法的效果要好。

我們現在再次問自己一個問題:所有的這些卷積網絡的本質是什麼?剛纔說了,網絡表示學習的本質是一個矩陣分解,那捲積網絡的本質是什麼?而且卷積網絡面臨着很多問題,除了我們經常說的機器學習普遍存在的過擬合問題,這裏還存在更重要的問題——過平滑及不健壯的問題。因爲在網絡中可能存在鏈接,甚至很多噪聲鏈接,這些鏈接可能會大幅影響效果,這個時候該怎麼辦?
我們先來看一看下圖的分析。GCN 每一層的傳播在本質上都是一個矩陣分解,從前面的分析可以看到,對矩陣分解其實可以進一步做一定的分析,把矩陣分解變成一個信通問題。而藉助信通的思路其實還有一個很有意思的擴展,我們可以把網絡中的鄰接矩陣 A 做一定的變換,我們可以在前面做一定的信通的變換,在後面也可以做信通的變換。這樣的話整個網絡其實可以變成一個 Signal Rescaling 的一個思路。
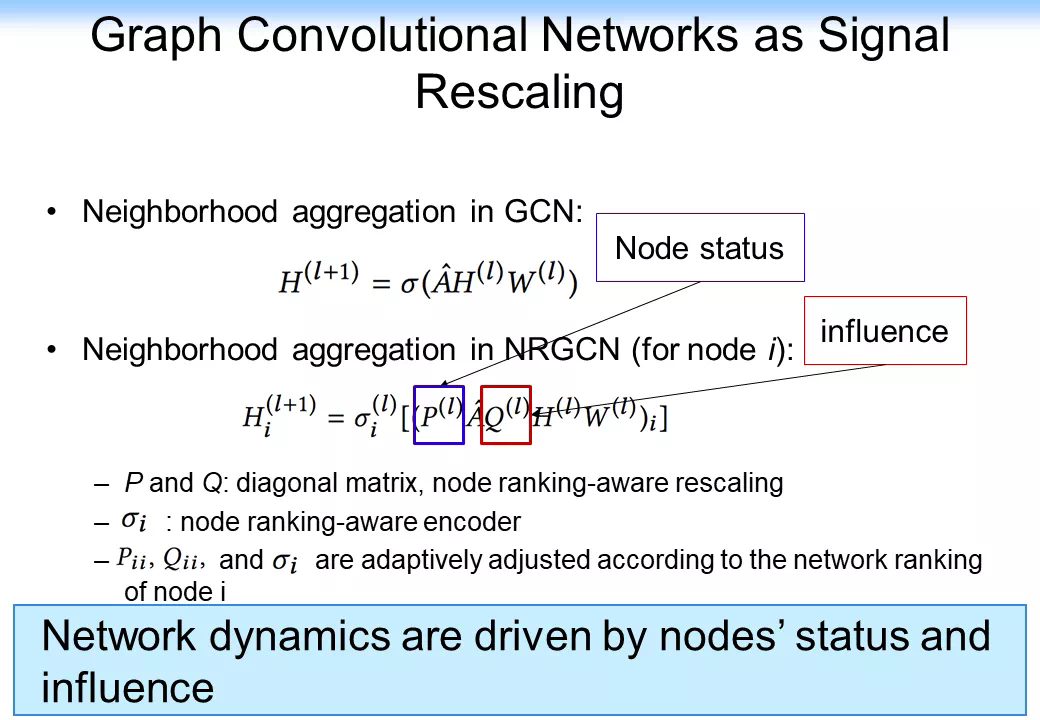
這樣的好處是可以把原來的每一層都做一個矩陣分解直接變換成相關的一些變化,我們可以把網絡中的節點的 status,或者網絡中的影響力全部嵌入卷積神經網絡。這樣的話對每一層的卷積層都可以做一定的變換,它可以是多層的,甚至是可以做 Multi-head Propagation mechanism,還可以做 Multi-hop variants。如果我們去掉每一層的非線性函數,事實上 Multi-hop variants 就和單純的 GCN 等價了。這樣一個分析的思路就把前面所有的注意力機制,如 Node attention、Edge attention、K-hop edge attention 或 Path attention 全部歸一化了起來。更優美的是基於這樣的思想,其實我們在以後就可以不用研究刻意去研究 GCN 的這種結構、架構,而是去研究在 GCN 裏的不同的操作。我們可以基於剛纔的函數對裏面的 P、Q 做變換,或者對 L 值直接做變換。這樣的話我們就可以對整個 GCN 做三種操作:Rescale,Re-normalize、Propagate,如下圖所示。

我們還可以進一步看,GraphSAGE 就相當於構造了一個 L,它沒有做 Rescaling,而是先做了一個 normalization,再做了一個 propagation。而 FastGCN 先做了 normalization,再做了一個 propagation,如下圖所示。

甚至我們可以把所有的這些卷積網絡的方法全部用 signal Rescaling 的方法把它統一起來,而統一的思想就是以上的三個操作,就用三個 operation 把所有的操作都給歸一化起來,如下圖所示。從這個角度上大家可以看到,在網絡表示學習方面,我們把它歸一化到矩陣分解,用矩陣分解把網絡表示學習都給歸一化起來了。而在卷積網絡中或者是叫圖神經網絡(當然更多的是卷積網絡)中,我們就用三個操作+矩陣分解,用矩陣分解把形式化統一,然後用三個操作把不同的方法全部給統一起來。於是這個時候我們有了一個統一的框架,基本上都是矩陣分解加不同的一個操作(這裏更多的是 signal Rescaling)這麼一個思路,再把它統一起來。

我們還做了一些實驗。我們發現結果也比以前確實要好,如下圖所示。
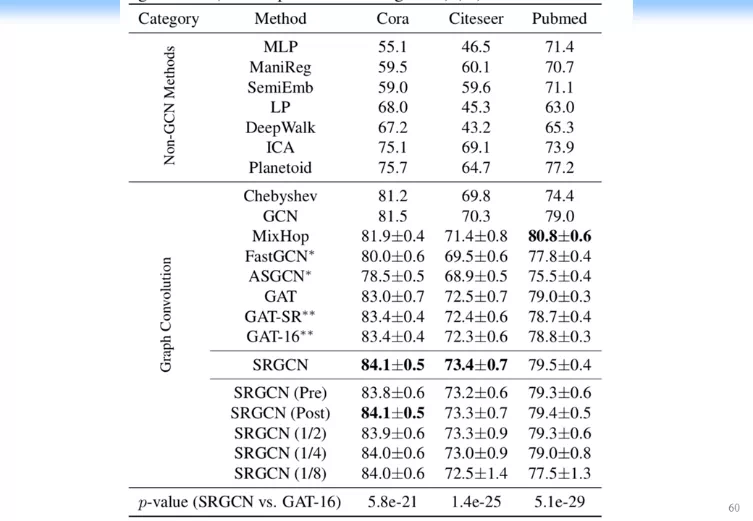
我們加上不同的操作以後,前面有 rescaling,post 叫 propagation,還有 normalization,我們用不同的操作加在上面可以組合成不同的方法。而這些不同的方法可以用一個 AutoML 的方法來做 Tune,這樣就比原來歸一化表示的其他方法的效果都要好。從效果上我們可以得到更好的一個結果。這樣就可能解決「在數學上的分析很漂亮,我們都說是一個 signal Rescaling 的問題,但是我們怎麼讓結果真的比原來好很多,這個時候就有很大的一個麻煩」這個問題。關於這一部分的很多細節沈華偉老師講了很多,所以我在這裏跳過一些,有興趣的可以查看相關的視頻。
接下來我們來看一下最近的一些思路。最近大家都知道自然語言處理及很多其他領域中,預訓練已經變成一個標配了,BERT 從 2018 年底出現到現在已經打敗了很多相關的一些方法,甚至已經出現了關於 BERT 的一系列相關的方法(BERTology),如 XLNet, Roberta, ALBert, TinyBERT 等。在計算機視覺(CV)方向也有很多相關的研究,最近一個很重要的進展就是 Contrastive Learning,即利用無監督學習(Unsupervised Learning)的方法或者是一個非常簡單的 Contrastive Learning 的思路來做的效果更好。MoCo 在 2019 年年底出來,基本上一下子就做到無監督學習的結果基本上就可以跟監督學習(Supervised learning)的結果差不了太多。後來 Geoffrey Hinton 團隊的 SimCLR 又打敗了 MoCo,最近 MoCo2 又把效果進一步提高,打敗了 SimCLR。它們的核心思想都 Contrastive Learning,本質上都是在用 self learning 來做表示學習,類似於做一個預訓練。
我認爲這方面是一個可能的方向,未來在這方面可能會有一些發展。但是怎麼跟網絡化的數據、跟圖掛鉤,就是把圖跟預訓練掛鉤,這方面其實還是一個很大的挑戰。所以總體來講,在 GNN 時代,如果光從算法的來考慮,我覺得值得考慮的其實有兩大核心的挑戰:(1)怎麼把預訓練思路,包括剛纔的 Contrastive Learning 和圖結合起來。其實現在還沒有一個特別里程碑式的進展。(2)我們在這裏面怎麼解決它過平滑、過擬合、不健壯的問題。這幾個問題怎麼解決是很難的問題。
GNN+推理會產生什麼
我們現在再來看一看 GNN 怎麼和推理結合起來。說到推理,可能有些人說這個問題太大了,所以我們先從一個非常簡單的問題(Multi-hop Question Answering,QA)來說。
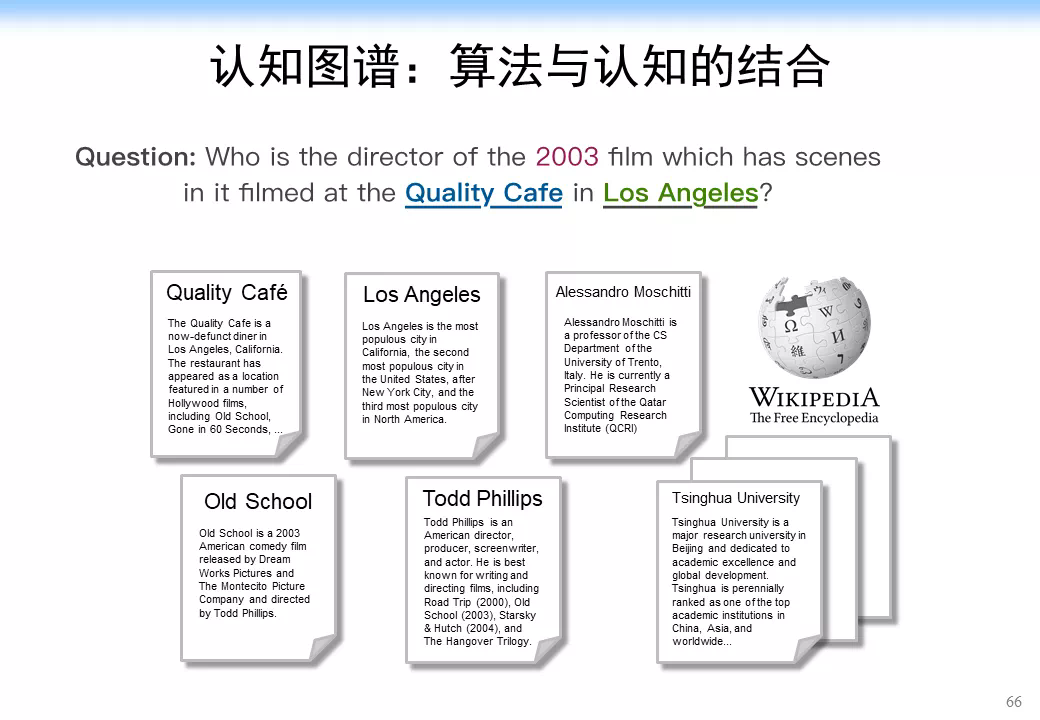
這個問題是個自然語言處理的問題。假如我們要解決一個問題「找到一個 2003 年在洛杉磯的 Quality 咖啡館拍過電影的導演(Who is the director of the 2003 film which has scenes in it filmed at The Quality Cafe in Los Angeles)」。如果是人來解決這個問題的話,可能是先追溯相關的文檔,如 Quality 咖啡館的介紹文檔,洛杉磯的維基百科頁面等,我們可能會從中找到相關的電影,如 Old School,在這個電影的介紹文檔裏面,我們可能會進一步找到該電影的導演 Todd Phillips,經過比對電影的拍攝時間 2003 年,最終確定答案是 Todd Phillips,具體流程如下圖所示。
但是計算機會怎麼做?計算機不像人,計算機沒有這麼聰明。如果我們用一個簡單的方法,也就是說我們用卷積神經網絡的方法來做的話,應該怎麼做?我們可以用 BERT 或 XLNet,BERT 可以做到 512 的 Context 了,我們現在甚至可以做到 1024、2048 的 Context,當然訓練要求就更高了,甚至沒有足夠的機器來完成。但是這裏面核心的一個問題不是說它能不能解的問題(當然第 1 個方面是它能不能解),而是像人那樣解決這個問題,即需要人的推理過程,但 BERT 可能根本就解決不了。
第 2 個更難的是缺乏知識層面上的一個推理能力,尤其是缺乏可解釋性。我們到最後得到的一個可能的結果:BERT 給出了一個和真實結果比較相似的結果,說這就是答案,然後就結束了。要想完美解決這個問題,需要有一個推理路徑或者一個子圖,我們怎麼在這方面來做這樣的事情?這很難。怎麼辦呢?我們來看一看人的推理過程。人的推理過程是:人在拿到這個問題以後,首先可能找到 Quality 咖啡館相關的文檔,這是最好的一個文檔(因爲洛杉磯市的相關文檔不是一個好的初始文檔)。找到 Quality 咖啡館相關的文檔以後,我們可以從裏面找到 old school 的相關文檔,然後從 old school 的文檔中可以找到 Todd Phillips。整個過程有好幾個步驟,如下圖所示。

我們怎麼把步驟形式化成一個計算機或者說機器學習能做的事情就是我們下一步要探討的。
我們把這個問題跟認知科學中的一個很重要的理論——雙通道理論(Dual Process Theory)結合起來。爲什麼和雙通道理論結合起來呢?人在做推理的時候,我們發現有兩個系統:System 1 和 System 2。System 1 被叫作直覺系統,直覺系統是說給定某個關係以後,只要算出相似度,就立馬把相似度給出來。比如當大家聽到 3 月 29 號下午有一個圖神經網絡的研討會時,大家覺得有興趣,決定要聽一下。System 2 會做進一步的推理、邏輯思考、決策。它可能會想下午還要帶小孩出去玩,或者下午還有另外一門課,這個課不能翹,於是你最後說算了,下午不去了,最後你就不參加了。所以 System 2 它是帶有邏輯思考的。
以上就是人思考問題的過程。AI 怎麼跟人來結合?我們在去年探討這個問題的時候,正好 Yoshua Bengio 他們也在聊這個問題,他在去年的 NIPS 上更直接地講了:「深度學習應該直接從 System 1 做到 System 2。現在 System 1 主要是在做直覺式(Intuitive)的思考。而 System 2 應該做一些邏輯加上一些推理,再加上一些 planning 的思考」如下圖所示。

我們當時做了什麼?我們就用 System 1 來做知識擴展,來做直覺的知識擴展;用 System 2 來做決策,我們就把它叫作 認知圖譜 ( Cognitive Graph )。這個思想用剛纔那個例子來說大概是下面這樣。
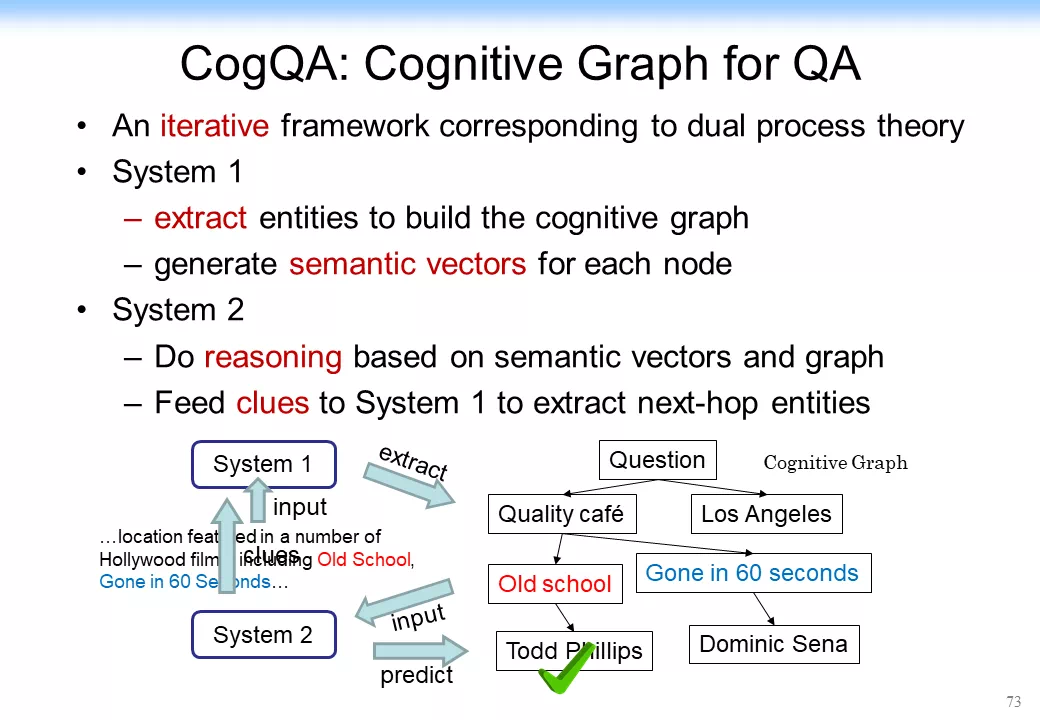
最後怎麼實現呢?對於 System 1,我們剛纔說做擴展,如果我們回到深度學習,這就跟 Yoshua Bengio 的思路基本上結合起來了。System 1 還可以用表示學習的各種方法,如可以用 BERT、ProNE、NetFM 甚至 DeepWalk 等方法。我們可以做一個簡單的相似度的擴展,於是我們就有了 System 1。
System 1 是做知識的擴展,System 2 是做決策和推理的。對 System 2 該怎處理呢?我們把 System 2 做成下圖所示的樣子。System 2 裏面核心的東西有一個推理和決策功能,於是我們就用卷積神經網絡或者圖神經網絡來實現。這裏面相當於匯聚了所有的信息,它把 System 1 中的拿出來的各種信息匯聚過來,判斷這個是不是我需要的答案,最後做決策。於是我們就把兩個神經網絡系統給整合到一起了,我們把它叫做認知圖譜(Cognitive Graph)。

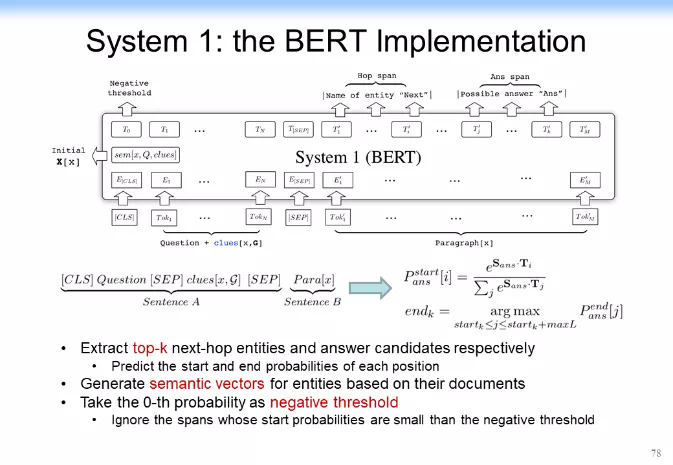
找到以後,我們把它作爲 Cognitive Graph 拿給 System 2 來做決策。System 2 就相當於做直接做一個 prediction,相當於學一個 prediction 的模型。用 GNN 直接來做預測。如果是答案就結束,如果不是答案,但是有用,就把它交給 System 1 來接着做。具體結構如下圖所示。
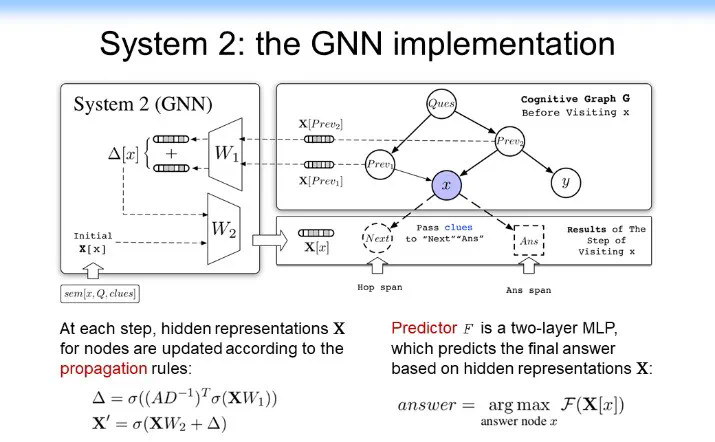
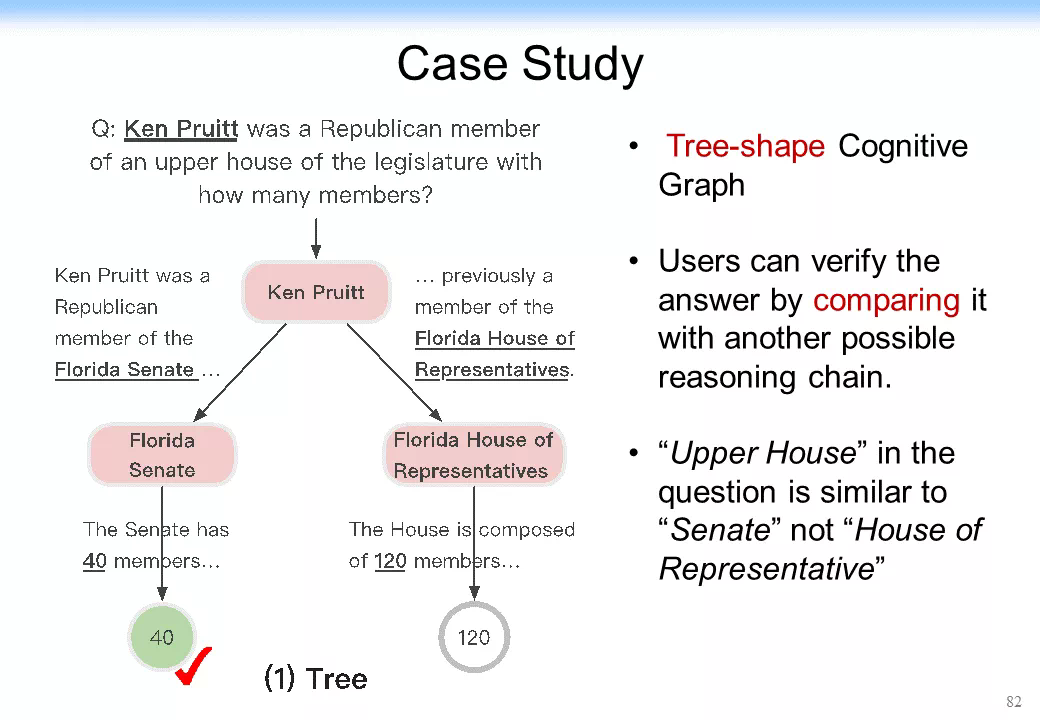
後來我們在去年的時候去參加了 SQuAD 的 HotpotQA 的一個多跳的競賽。就在這個競賽中,當時我們一下子拿到了第 1 名,而且在第 1 名的位置上保持了三個月。大家可以看一下下圖這個結果可以發現更有意思的事:CogQA(CogGraph)的結果比當時的 BERT 好 50%。CogQA 可以做到 49%,而當時的 BERT 在 F1 值上最好的結果是 31%。更優美的是它給出了一個很強的可解釋性,我前面介紹了可解釋性非常重要,尤其是在多跳的情況下。首先,對多跳的效果的提升是很明顯的,如 hop 跳得如果越高的話,即跳出越多的話,CogQA 的結果就明顯的比原來的方法要好得多。其次,它的可解釋性非常強。比如我給你一個答案,這個答案是 40,如下圖左下角所示。這個事實大家可以看到,而我可以告訴你爲什麼能拿到 40。我是先找到這 Ken Pruitt,然後再找到 Florida Senate,最後找到 40。這裏有一個可解釋、可追溯的這麼一個結果,一下就把可解釋性大幅提高。它甚至可以從本質上幫助機器學習。
機器學習原來是依靠某個信息做預測,這個時候可能沒有擴展的信息,而依靠認知圖譜,可以用 system 1 擴展出來新的信息,如果拓展的信息精度不夠高,還可以通過做一層推理給出更多的信息,這個時候機器學習系統可以結合更多的信息再來做預測,這可能又進一步提高了效果。當機器學習系統做了一個錯誤的預測以後,認知圖譜還可以回溯錯誤是怎麼產生的。這個方面有很多相關的應用。
有人可能會說,這個是不是隻能做問答?不是的,它既可以做問答,也可以做知識圖譜的補齊,下圖左邊是一個知識圖譜,右邊是基於剛纔的模型來做知識圖譜的一個補齊,這是一個基本的一個思路。

這就是認知圖譜怎麼和推理結合在一起。
未來我們有很多挑戰,但是也有很多機遇。
張鈸院士在 2015 年提出人工智能基本上在做兩件事。
第一件事:做知識的表示和知識的推理。其實知識表示和知識推理在 20 世紀 50 年代第一個人工智能時代就已經有了。當時的推理就已經很先進了。但是一直沒有發展起來,一個原因就是規模小,另一個原因是固定、死板,不能自學習。這跟當時的計算機計算能力差、缺乏大規模的數據有關係。
第二件事:第二波人工智能浪潮的興起是機器學習驅動的,第三波人工智能浪潮(也就是這一次人工智能浪潮)是依靠深度學習把整個基於學習的人工智能推向了一個頂峯,所以我說這是一個感知時代的頂峯。
現在人工智能最大的問題缺乏可解釋性,而且缺乏健壯性。我剛纔講了,存在一個噪聲可能就會導致整個網絡的表示學習的結果就不行了,甚至缺乏這種可信的結果和可擴展的結果。這些方面都需要我們做進一步的研究,所以當時張院士就提出要做第三代人工智能。DARPA 在 2017 年也做了 XAI 項目,提出一定要做可解釋性的機器學習。
2018 年,清華大學正式提出第三代人工智能的理論框架體系:(1)建立可解釋、健壯性的人工智能理論和方法。(2)發展安全、可靠、可信及可擴展的人工智能技術。(3)推動人工智能創新應用。
結合剛纔講到的內容,我認爲:(1)數據和知識的融合是非常關鍵的,我們要考慮怎麼把知識融合到數據裏面。(2)我們怎麼跟腦科學、腦啓發、腦認知的方法結合起來。所以剛纔我拋磚引玉給了一個思想,即我們用認知圖譜這種思想,可能可以把人的常識知識和一些推理邏輯結合到深度學習中,甚至可以把一些知識的表示也結合到裏面。這樣的話「認知+推理」就是未來。這裏面還有一個核心的基石:要建造萬億級的常識知識圖譜,這是我們必須要做的。這裏面路還非常遠,我也非常歡迎大家一起加入來做這方面的研究和探討。
這裏面再次拋磚引玉,提一下幾個相關的研究。(1)在推理方面有幾個相關的工作,如 DeepMind 的 graph_net 就把關係融合到網絡表示中,在網絡表示學習中發揮一定的作用。(2)最近的一篇文章把知識圖譜融合到了 BERT 中,這樣的話知識圖譜中就有了與 BERT 相關的一些東西,可以用這種知識圖譜來幫助 BERT 的預訓練。當然,我不是說它是最好的,但它們都提出了一個思路,講到了怎麼把表示學習和 GNN 結合起來,這是很重要的一些事情。
下圖列出了一些相關的論文,還有一兩篇是我們沒有發表的文章,包括剛纔說的 Signal Rescaling,其實我們在那篇文章裏面做了很多數學分析。