今天刷看到了YOLOv4之時,有點激動和興奮,等了很久的YOLOv4,你終究還是出現了
論文地址:https://arxiv.org/pdf/2004.10934.pdf
GitHub地址:https://github.com/AlexeyAB/darknet
首先附上對論文總結的思維導圖,幫助大家更好的理解!
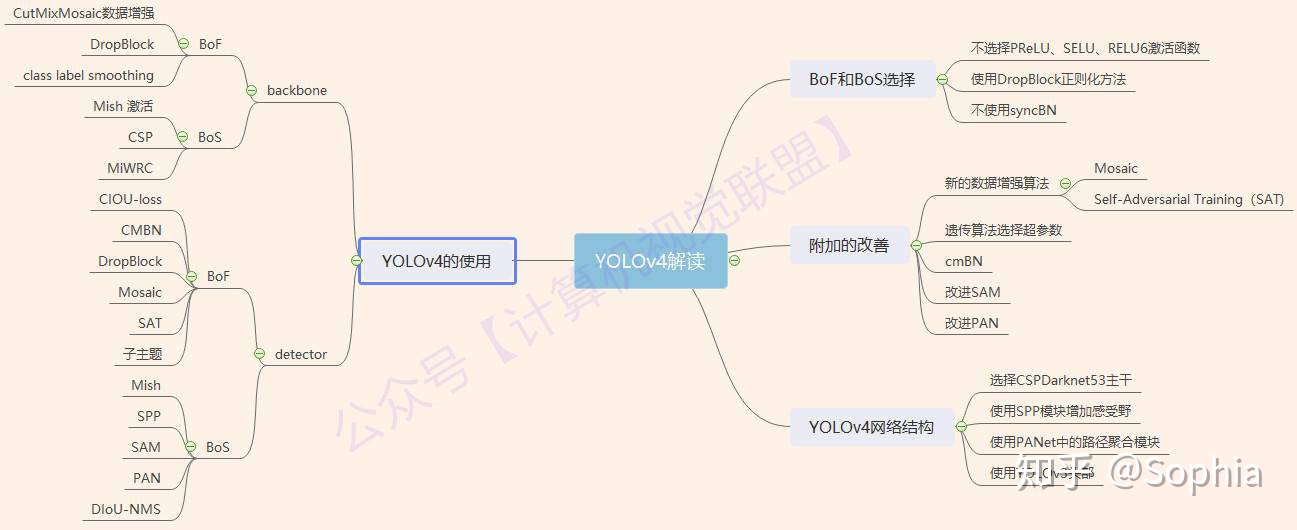
下邊是對論文的翻譯,有些地方可能翻譯的不是很準確,歡迎指正補充


摘要
有很多特徵可以提高卷積神經網絡(CNN)的準確性。需要在大型數據集上對這些特徵的組合進行實際測試,並需要對結果進行理論證明。某些特徵僅在某些模型上運行,並且僅在某些問題上運行,或者僅在小型數據集上運行;而某些特徵(例如批歸一化和殘差連接)適用於大多數模型,任務和數據集。我們假設此類通用特徵包括加權殘差連接(WRC),跨階段部分連接(CSP),交叉小批量標準化(CmBN),自對抗訓練(SAT)和Mish激活。我們使用以下新功能:WRC,CSP,CmBN,SAT,Mish激活,馬賽克數據增強,CmBN,DropBlock正則化和CIoU丟失,並結合其中的一些特徵來實現最新的結果:在MS COCO數據集上利用Tesla V10以65 FPS的實時速度獲得了43.5%的AP(65.7%AP50)。開源代碼鏈接:https://github.com/AlexeyAB/darknet。
1、介紹
大多數基於CNN的物體檢測器僅適用於推薦系統。例如,通過慢速精確模型執行的城市攝像機搜索免費停車位,而汽車碰撞警告與快速不精確模型有關。提高實時物體檢測器的精度不僅可以將它們用於提示生成推薦系統,還可以用於獨立的過程管理和減少人工輸入。常規圖形處理單元(GPU)上的實時對象檢測器操作允許以可承受的價格對其進行運行。最精確的現代神經網絡無法實時運行,需要使用大量的GPU進行大量的mini-batch-size訓練。我們通過創建在常規GPU上實時運行的CNN來解決此類問題,並且該培訓僅需要一個傳統的GPU。
這項工作的主要目標是在產生式系統中設計一個運行速度快的目標探測器,並對並行計算進行優化,而不是設計一個低計算量的理論指標(BFLOP)。我們希望所設計的對象易於訓練和使用。如圖1中的YOLOv4結果所示,任何人使用傳統的GPU進行訓練和測試,都可以獲得實時、高質量和令人信服的目標檢測結果。我們的貢獻概括如下:
- 我們開發了一個高效且功能強大的目標檢測模型。它使每個人都可以使用1080Ti或2080TiGPU來訓練超快、精確的物體探測器。
- 我們驗證了當前最新的「免費袋」和「特殊袋」檢測方法在探測器訓練過程中的影響。
- 我們修改了最新的方法,使其更有效,更適合於單個GPU的培訓,包括CBN[89]、PAN[49]、SAM[85]等。

2、相關工作(Related work)
2.1 目標檢測算法(Object detection models)
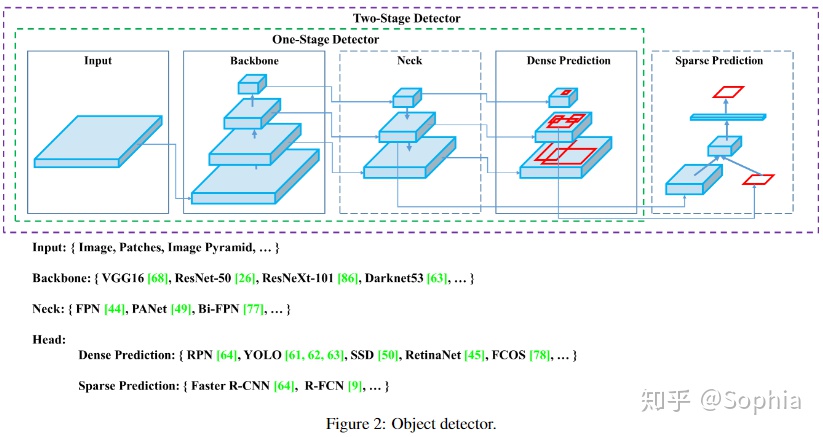
目標檢測算法一般有兩部分組成:一個是在ImageNet預訓練的骨架(backbone),,另一個是用來預測對象類別和邊界框的頭部。對於在GPU平臺上運行的檢測器,其骨幹可以是VGG [68],ResNet [26],ResNeXt [86]或DenseNet [30]。對於在CPU平臺上運行的那些檢測器,其主幹可以是SqueezeNet [31],MobileNet [28、66、27、74]或ShuffleNet [97、53]。對於頭部,通常分爲兩類,即一級對象檢測器和二級對象檢測器。最具有代表性的兩級對象檢測器是R-CNN [19]系列,包括fast R-CNN [18],faster R-CNN [64],R-FCN [9]和Libra R-CNN [ 58]。還可以使兩級對象檢測器成爲無錨對象檢測器,例如RepPoints [87]。對於一級目標檢測器,最具代表性的模型是YOLO [61、62、63],SSD [50]和RetinaNet [45]。近年來,開發了無錨的(anchor free)一級物體檢測器。這類檢測器是CenterNet [13],CornerNet [37、38],FCOS [78]等。近年來,無錨點單級目標探測器得到了發展,這類探測器有CenterNet[13]、CornerNet[37,38]、FCOS[78]等。近年來發展起來的目標探測器經常在主幹和頭部之間插入一些層,這些層通常用來收集不同階段的特徵圖。我們可以稱它爲物體探測器的頸部。通常,頸部由幾個自下而上的路徑和幾個自上而下的路徑組成。具有這種機制的網絡包括特徵金字塔網絡(FPN)[44]、路徑聚集網絡(PAN)[49]、BiFPN[77]和NAS-FPN[17]。除上述模型外,一些研究人員將重點放在直接構建用於檢測對象的新主幹(DetNet [43],DetNAS [7])或新的整個模型(SpineNet [12],HitDe-tector [20])上。
總而言之,普通的檢測器由以下幾個部分組成:
- 輸入:圖像,斑塊,圖像金字塔
- 骨架:VGG16 [68],ResNet-50 [26],SpineNet [12],EfficientNet-B0 / B7 [75],CSPResNeXt50 [81],CSPDarknet53 [81]
- 頸部:
- 其他塊:SPP [25],ASPP [5],RFB [47],SAM [85]
- 路徑聚合塊:FPN [44],PAN [49],NAS-FPN [17] ],Fully-connected FPN,BiFPN [77],ASFF [48],SFAM [98]
- Heads :
- 密集預測(一階段):
- RPN[64],SSD [50],YOLO [61], RetinaNet [45](基於錨)
- CornerNet[37],CenterNet [13],MatrixNet [60],FCOS [78](無錨)
- 稀疏預測(兩階段):
- Faster R-CNN [64],R-FCN [9],Mask R-CNN [23](基於錨)
- RepPoints[87](無錨)
2.2 Bag of freebies
通常,傳統的物體檢測器是離線訓練的。因此,研究人員一直喜歡採用這種優勢並開發出更好的訓練方法,從而可以使目標檢測器獲得更好的精度而又不會增加推理成本。我們稱這些僅改變培訓策略或僅增加培訓成本的方法爲「免費贈品」。數據檢測是對象檢測方法經常採用的並符合免費贈品的定義。數據增強的目的是增加輸入圖像的可變性,從而使設計的物體檢測模型對從不同環境獲得的圖像具有更高的魯棒性。例如,光度失真和幾何失真是兩種常用的數據增強方法,它們無疑有利於物體檢測任務。在處理光度失真時,我們調整圖像的亮度,對比度,色相,飽和度和噪點。對於幾何失真,我們添加了隨機縮放,裁剪,翻轉和旋轉。
上面提到的數據增強方法是全像素調整,並且保留了調整區域中的所有原始像素信息。此外,一些從事數據增強的研究人員將重點放在模擬對象遮擋問題上。他們在圖像分類和目標檢測方面取得了良好的成果。例如,random erase[100]和CutOut [11]可以隨機選擇圖像中的矩形區域,並填充零的隨機或互補值。至於hide-and-seek[69]和grid mask[6],他們隨機或均勻地選擇圖像中的多個矩形區域,並將其替換爲所有零。如果類似的概念應用於要素地圖,則有DropOut [71],DropConnect [80]和DropBlock [16]方法。另外,一些研究人員提出了使用多個圖像一起執行數據增強的方法。例如,MixUp [92]使用兩個圖像對具有不同係數的圖像進行乘法和疊加,然後使用這些疊加的係數來調整標籤。對於CutMix [91],它是將裁切後的圖像覆蓋到其他圖像的矩形區域,並根據混合區域的大小調整標籤。除了上述方法之外,樣式轉移GAN [15]還用於數據擴充,這種用法可以有效地減少CNN所學習的紋理偏差。
與上面提出的各種方法不同,其他一些免費贈品方法專用於解決數據集中語義分佈可能存在偏差的問題。在處理語義分佈偏向問題時,一個非常重要的問題是不同類之間存在數據不平衡的問題,這一問題通常是通過兩階段對象設計器中的難例挖掘[72]或在線難例挖掘[67]來解決的。但是實例挖掘方法不適用於一級目標檢測器,因爲這種檢測器屬於密集預測架構。因此Linet等 [45]提出了焦點損失,以解決各個類別之間存在的數據不平衡問題。另一個非常重要的問題是,很難用one-hot representation來表達不同類別之間的關聯度。這種表示方法經常在執行標籤時使用。[73]中提出的標籤平滑是將硬標籤轉換爲軟標籤以進行訓練,這可以使模型更加健壯。爲了獲得更好的軟標籤,Islamet等人[33]引入知識蒸餾的概念來設計標籤優化網絡。
最後一袋贈品是邊界框迴歸的目標函數。傳統的目標檢測器通常使用均方誤差(MSE)直接對BBox的中心點座標和高度、寬度進行迴歸,即{xcenter,ycenter,w,h},或者對左上角和右下點,即{xtopleft,ytopleft,xbottomright,ybottomright}進行迴歸。對於基於錨點的方法,是估計相應的偏移量,例如{xcenterOffset,ycenterOffset,wOffset,hoffset}和{xtopleftoffset,ytopleftoffset,xbottomright toffset,ybottomright toffset},例如{xtopleftoffset,ytopleftoffset}和{xtopleftoffset,ytopleftoffset}。然而,直接估計BBox中每個點的座標值是將這些點作爲獨立變量來處理,而實際上並沒有考慮對象本身的完整性。爲了更好地處理這一問題,最近一些研究人員提出了IoU loss[90],將預測BBOX區域的覆蓋率和地面真實BBOX區域的覆蓋率考慮在內。IOU loss計算過程將觸發BBOX的四個座標點的計算,方法是執行具有地面實況的借條,然後將生成的結果連接到一個完整的代碼中。由於IOU是一種標度不變的表示,它可以解決傳統方法計算{x,y,w,h}的l1或l2個損失時,損失會隨着尺度的增大而增大的問題。最近,搜索者不斷改善欠條損失。例如,GIOU損失[65]除了包括覆蓋區域外,還包括對象的形狀和方向。他們提出找出能同時覆蓋預測BBOX和實際BBOX的最小面積BBOX,並用這個BBOX作爲分母來代替原來在欠條損失中使用的分母。對於DIoU loss[99],它另外考慮了物體中心的距離,而CIoU損失[99]則同時考慮了重疊面積、中心點之間的距離和縱橫比。在求解BBox迴歸問題時,Ciou可以達到較好的收斂速度和精度。
2.3 Bag of spedials
對於那些僅增加少量推理成本但可以顯着提高對象檢測準確性的插件模塊和後處理方法,我們將其稱爲「特價商品」。一般而言,這些插件模塊用於增強模型中的某些屬性,例如擴大接受域,引入注意力機制或增強特徵集成能力等,而後處理是用於篩選模型預測結果的方法。
可以用來增強接收域的通用模塊是SPP [25],ASPP [5]和RFB [47]。 SPP模塊起源於空間金字塔匹配(SPM)[39],SPM的原始方法是將功能圖分割成若干x不等的塊,其中{1,2,3,...}可以是空間金字塔,然後提取詞袋特徵。 SPP將SPM集成到CNN中,並使用最大池操作而不是詞袋運算。由於Heet等人提出了SPP模塊。 [25]將輸出一維特徵向量,在全卷積網絡(FCN)中應用是不可行的。因此,在YOLOv3的設計中[63],Redmon和Farhadi將SPP模塊改進爲內核大小爲k×k的最大池輸出的串聯,其中k = {1,5,9,13},步長等於1。在這種設計下,相對大k×kmax池有效地增加了骨幹特徵的接受範圍。在添加了改進版本的SPP模塊之後,YOLOv3-608在MS COCOobject檢測任務上將AP50升級了2.7%,而額外的計算費用爲0.5%。ASPP[5]模塊和改進的SPP模塊之間的操作差異主要來自於原始k× kkernel大小,最大卷積步長等於1到3×3內核大小,膨脹比等於tok,步長等於1。 RFB模塊將使用k×kkernel的幾個擴張卷積,擴張比率equalstok和步幅等於1來獲得比ASPP更全面的空間覆蓋範圍。 RFB [47]僅花費7%的額外推斷時間即可將MS COCO上SSD的AP50提高5.7%。
物體檢測中常用的注意模塊主要分爲通道式注意和點式注意,這兩種注意模型的代表分別是擠壓激發(SE)[29]和空間注意模塊(SAM)[85]。雖然SE模塊在Im-ageNet圖像分類任務中可以提高1%的TOP-1準確率,但是在GPU上通常會增加10%左右的推理時間,因此更適合在移動設備上使用,雖然SE模塊在Im-ageNet圖像分類任務中可以提高1%的TOP-1準確率,但是在GPU上通常會增加10%左右的推理時間。而對於SAM,它只需要額外支付0.1%的計算量,在ImageNet圖像分類任務上可以提高ResNet50-SE 0.5%的TOP-1準確率。最棒的是,它完全不影響GPU上的推理速度。
在特徵集成方面,早期的實踐是使用KIP連接[51]或超列[22]將低級物理特徵集成到高級語義特徵。隨着模糊神經網絡等多尺度預測方法的普及,人們提出了許多集成不同特徵金字塔的輕量級模塊。這種類型的模塊包括SfAM[98]、ASFF[48]和BiFPN[77]。SfAM的主要思想是使用SE模塊對多比例尺拼接的特徵地圖進行通道級的加權。ASFF採用Softmax作爲逐點層次加權,然後添加不同尺度的特徵地圖;BiFPN採用多輸入加權殘差連接進行尺度層次重新加權,再添加不同尺度的特徵地圖。
在深度學習的研究中,有些人專注於尋找良好的激活功能。良好的激活函數可以使梯度更有效地傳播,同時不會引起過多的計算成本。在2010年,Nair和Hin-ton [56]提出了ReLU,以基本上解決傳統tanh和sigmoid激活函數中經常遇到的梯度消失問題。隨後,LReLU [54],PReLU [24],ReLU6 [28],比例指數線性單位(SELU)[35],Swish [59],hard-Swish [27]和Mish [55]等,它們也是已經提出了用於解決梯度消失問題的方法。 LReLU和PReLU的主要目的是解決當輸出小於零時ReLU的梯度爲零的問題。至於ReLU6和hard-Swish,它們是專門爲量化網絡設計的。爲了對神經網絡進行自歸一化,提出了SELU激活函數來滿足這一目標。要注意的一件事是,Swish和Mishare都具有連續可區分的激活功能。
在基於深度學習的對象檢測中通常使用的後處理方法是NMS,它可以用於過濾那些無法預測相同對象的BBox,並僅保留具有較高響應速度的候選BBox。 NMS嘗試改進的方法與優化目標函數的方法一致。 NMS提出的原始方法沒有考慮上下文信息,因此Girshicket等人。 [19]在R-CNN中添加了分類置信度得分作爲參考,並且根據置信度得分的順序,從高分到低分的順序執行貪婪的NMS。對於軟網絡管理系統[1],考慮了一個問題,即物體的遮擋可能會導致帶有IoU評分的貪婪的網絡管理系統的置信度得分下降。 DIoU NMS [99]開發人員的思維方式是在softNMS的基礎上將中心距離的信息添加到BBox篩選過程中。值得一提的是,由於上述後處理方法均未直接涉及捕獲的圖像功能,因此在隨後的無錨方法開發中不再需要後處理。
3、方法(Methodology)
其基本目標是在生產系統中對神經網絡進行快速操作,並針對並行計算進行優化,而不是低計算量理論指示器(BFLOP)。我們提供了實時神經網絡的兩種選擇:
- 對於GPU,我們使用少量的組(1-8)卷積層:CSPResNeXt50 / CSPDarknet53
- 對於VPU-我們使用分組卷積,但是我們不再使用擠壓和激發(SE)塊-特別是這包括以下模型:EfficientNet-lite / MixNet [76] / GhostNet [21] / Mo-bileNetV3
3.1 Selection of architecture
我們的目標是在輸入網絡分辨率,卷積層數,參數數(filtersize2 *過濾器*通道/組)和層輸出(過濾器)數目之間找到最佳平衡。例如,大量研究表明,在ILSVRC2012(ImageNet)數據集的對象分類方面,CSPResNext50比CSPDarknet53更好。然而,相反,就檢測MS COCO數據集上的對象而言,CSPDarknet53比CSPResNext50更好。
下一個目標是爲不同的檢測器級別從不同的主幹級別中選擇其他塊以增加接收場和參數聚集的最佳方法: FPN,PAN,ASFF,BiFPN。
對於分類最佳的參考模型對於檢測器並非總是最佳的。與分類器相比,檢測器需要滿足以下條件:
- 更大的網絡輸入,用於檢測小目標
- 更多的層-以獲得更大的感受野來覆蓋增大的輸入圖像
- 更多的參數-爲了增強從單張圖像中檢測出不同大小的多個對象的能力
假設可以選擇接受場較大(卷積層數爲3×3)和參數數較多的模型作爲主幹。表1顯示了CSPResNeXt50、CSPDarknet53和Effi-cientNet B3的信息。CSPResNext50只包含16個卷積層3×3,425×425感受野和20.6M參數,而CSPDarknet53包含29個卷積層3×3,725×725感受野和27.6M參數。這一理論證明,再加上我們的大量實驗,表明CSPDarknet53神經網絡是兩者作爲探測器骨幹的最佳模型。

不同大小的感受野對檢測效果的影響如下所示:
- 最大對象大小-允許查看整個對象
- 最大網絡大小-允許查看對象周圍的上下文
- 超過網絡大小-增加圖像點和最終激活之間的連接
我們在CSPDarknet53上添加SPP塊,因爲它顯著增加了接受場,分離出最重要的上下文特徵,並且幾乎不會降低網絡操作速度。我們使用PANET代替YOLOv3中使用的FPN作爲不同骨級的參數聚合方法,用於不同的檢測器級別。
最後,我們選擇了CSPDarknet53主幹、SPP附加模塊、PANET路徑聚合Neck和YOLOv3(基於錨點的)頭部作爲YOLOv4的體系結構。
將來,我們計劃顯着擴展檢測器的贈品袋(BoF)的內容,從理論上講,它可以解決一些問題並提高檢測器的準確性,並以實驗方式依次檢查每個功能的影響。
我們不使用跨GPU批量標準化(CGBNor SyncBN)或昂貴的專用設備。這使任何人都可以在傳統的圖形處理器上重現我們的最新成果,例如GTX 1080Ti或RTX2080Ti。
3.2 Selection of BoF and BoS
爲了改進目標檢測訓練,CNN通常使用以下方法:
- 激活:ReLU,leaky-ReLU,parameter-ReLU,ReLU6,SELU,Swish或Mish
- 邊界框迴歸損失:MSE,IoU,GIoU,CIoU,DIoU
- 數據增強:CutOut,MixUp,CutMix
- 正則化方法:DropOut, DropPath [36],Spatial DropOut [79]或DropBlock
- 通過均值和方差對網絡激活進行歸一化:Batch Normalization (BN) [32],Cross-GPU Batch Normalization (CGBN or SyncBN)[93], Filter Response Normalization (FRN) [70], orCross-Iteration Batch Normalization (CBN) [89]
- 跨連接:Residual connections, Weightedresidual connections, Multi-input weighted residualconnections, or Cross stage partial connections (CSP)
至於訓練激活功能,由於PReLU和SELU更難訓練,並且ReLU6是專門爲量化網絡設計的,因此我們從候選列表中刪除了上述激活功能。在重新量化方法中,發佈Drop-Block的人們將自己的方法與其他方法進行了詳細的比較,而其正則化方法贏得了很多。因此,我們毫不猶豫地選擇了DropBlock作爲我們的正則化方法。至於標準化方法的選擇,由於我們專注於僅使用一個GPU的訓練策略,因此不考慮syncBN。
3.3 Additional improvements
爲了使設計的檢測器更適合在單個GPU上進行訓練,我們進行了以下附加設計和改進:
- 我們引入了一種新的數據增強方法:Mosaic, and Self-Adversarial Training (SAT)
- 在應用遺傳算法時,我們選擇最優的超參數
- 我們修改了一些現有方法,使我們的設計適合進行有效的訓練和檢測-改進的SAM,改進的PAN ,以及跨小批量標準化(CmBN)
Mosaic是一種新的混合4幅訓練圖像的數據增強方法。所以四個不同的上下文信息被混合,而CutMix只混合了2種。
這允許檢測其正常上下文之外的對象。此外,批量歸一化從每層上的4個不同的圖像計算激活統計。這極大地減少了對large mini-batch-size的需求。
自對抗訓練(SAT)也代表了一種新的數據增強技術,它在兩個前向後向階段運行。在第一階段,神經網絡改變原始圖像而不是網絡權值。通過這種方式,神經網絡對其自身執行對抗性攻擊,改變原始圖像,以製造圖像上沒有所需對象的欺騙。在第二階段,訓練神經網絡,以正常的方式在修改後的圖像上檢測目標。
CmBN表示CBN的修改版本,如圖4所示,定義爲交叉小批量規範化(Cross mini-Batch Normalization,CMBN)。這僅在單個批次內的小批次之間收集統計信息。

我們將SAM從空間注意修改爲點注意,並將PAN的快捷連接分別替換爲串聯,如圖5和圖6所示。

3.4 YOLOv4
在本節中,我們將詳細介紹YOLOv4的細節。
YOLOv4的組成:

YOLOv4的使用:

4、Experiments
我們在ImageNet(ILSVRC 2012 Val)數據集上測試了不同訓練改進技術對分類器精度的影響,然後在MS Coco(test-dev 2017)數據集上測試了不同訓練改進技術對檢測器精度的影響。
4.1 Experimental setup
在ImageNet圖像分類實驗中,缺省超參數如下:訓練步數爲800萬步;batch size和mini-batch size分別爲128和32;採用多項式衰減學習率調度策略,初始學習率爲0.1;預熱步數爲1000步;動量和權值分別設置爲0.9和0.005。我們所有的BoS實驗都使用與默認設置相同的超參數,並且在BoF實驗中,我們增加了50%的訓練步驟。在BoF實驗中,我們驗證了MixUp、CutMix、Mosaic、Bluring數據增強和標記平滑正則化方法。在BoS實驗中,我們比較了LReLU、SWISH和MISHISH激活函數的效果。所有實驗均使用1080Ti或2080Ti GPU進行訓練。
在MS COCO目標檢測實驗中,缺省超參數如下:訓練步數爲500,500;採用階躍衰減學習率調度策略,初始學習率爲0.01,在400,000步和450,000步分別乘以因子0.1;動量衰減和權重衰減分別設置爲0.9和0.0005。所有的體系結構都使用單個GPU來執行批處理大小爲64的多尺度訓練,而小批處理大小爲8或4,具體取決於體系結構和GPU內存的限制。除採用遺傳算法進行超參數搜索實驗外,其餘實驗均採用默認設置。遺傳算法使用YOLOv3-SPP算法在有GIoU損失的情況下進行訓練,在300個曆元中搜索Min-Val5k集。我們採用搜索學習率0.00261,動量0.949,IOU閾值分配地面真值0.213,損失歸一化0.07%進行遺傳算法實驗。我們驗證了大量的BoF算法,包括網格敏感度消除、moSAIC數據增強、IOU閾值、遺傳算法、類標籤平滑、交叉小批量歸一化、自對抗訓練、餘弦退火調度器、動態小批量大小、DropBlock、優化錨點、不同類型的IOU損失。我們還在不同的BoS上進行了實驗,包括MISH、SPP、SAM、RFB、BiFPN和Gaus-Sian YOLO[8]。對於所有的實驗,我們只使用一個GPU進行訓練,因此不使用諸如優化多個GPU的syncBN之類的技術。
4.2 Influence of different features on Classifier training
首先,我們研究了不同特徵對分類器訓練的影響;具體地說,類標籤平滑的影響,不同數據擴充技術的影響,雙邊模糊,混合,CutMix和馬賽克,如圖7所示,以及不同活動的影響,如Leaky-relu(默認情況下),SWISH和MISH。

在我們的實驗中,如表2所示,通過引入諸如:CutMix和Mosaic數據增強、類標籤平滑和Mish激活等特徵,提高了分類器的精度。因此,我們用於分類器訓練的BoF-Backbone(Bag Of Freebies)包括以下內容:CutMix和Mosaic數據增強以及類標籤平滑。此外,我們還使用MISH激活作爲補充選項,如表2和表3所示。


4.3 Influence of different features on Detector training
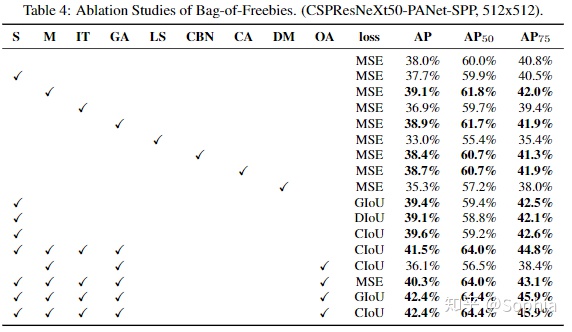
進一步的研究涉及不同的免費袋(BOF探測器)對探測器訓練精度的影響,如表4所示。我們通過研究在不影響FPS的情況下提高探測器精度的不同特性,顯著擴展了BOF列表:


進一步研究了不同的專業袋(BOS檢測器)對檢測器訓練精度的影響,包括PAN、RFB、SAM、高斯YOLO(G)和ASFF,如表5所示。在我們的實驗中,當使用SPP、PAN和SAM時,檢測器的性能最佳。
4.4 Influence of different backbones and pretrained weightings on Detector training
進一步,我們研究了不同主幹模型對檢測器精度的影響,如表6所示。請注意,具有最佳分類精度的模型在檢測器精度方面並不總是最佳。
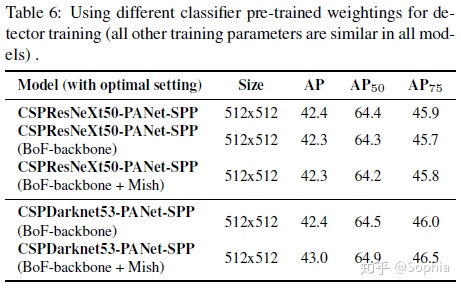
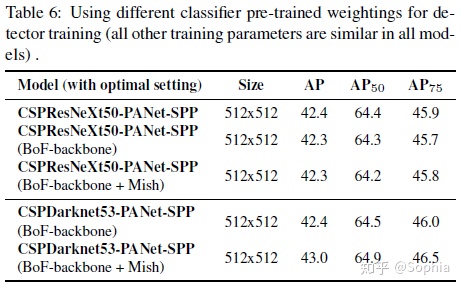
首先,儘管與CSPDarknet53模型相比,經過不同功能訓練的CSPResNeXt-50模型的分類準確性更高,但CSPDarknet53模型在對象檢測方面顯示出更高的準確性。
其次,使用BoF和Mish進行CSPResNeXt50分類器訓練會提高其分類準確性,但是將這些預先訓練的權重進一步應用於檢測器訓練會降低檢測器準確性。但是,將BoF和Mish用於CSPDarknet53分類器訓練可以提高分類器和使用該分類器預訓練加權的檢測器的準確性。結果是,與CSPResNeXt50相比,主幹CSPDarknet53更適合於檢測器。
我們觀察到,由於各種改進,CSPDarknet53模型具有更大的能力來提高檢測器精度。
4.4 Influence of different mini-batch size on Detector training
最後,我們分析了在不同最小批量大小下訓練的模型所獲得的結果,結果如表7所示。從表7所示的結果中,我們發現在添加BoF和BoS訓練策略之後,最小批量大小几乎沒有影響在檢測器的性能上。該結果表明,在引入BoF和BoS之後,不再需要使用昂貴的GPU進行訓練。換句話說,任何人都只能使用傳統的GPU來訓練出色的探測器。

5、Results
與其他最先進的物體探測器獲得的結果比較如圖8所示。YOLOv4在速度和準確性方面均優於最快,爲最準確的探測器。
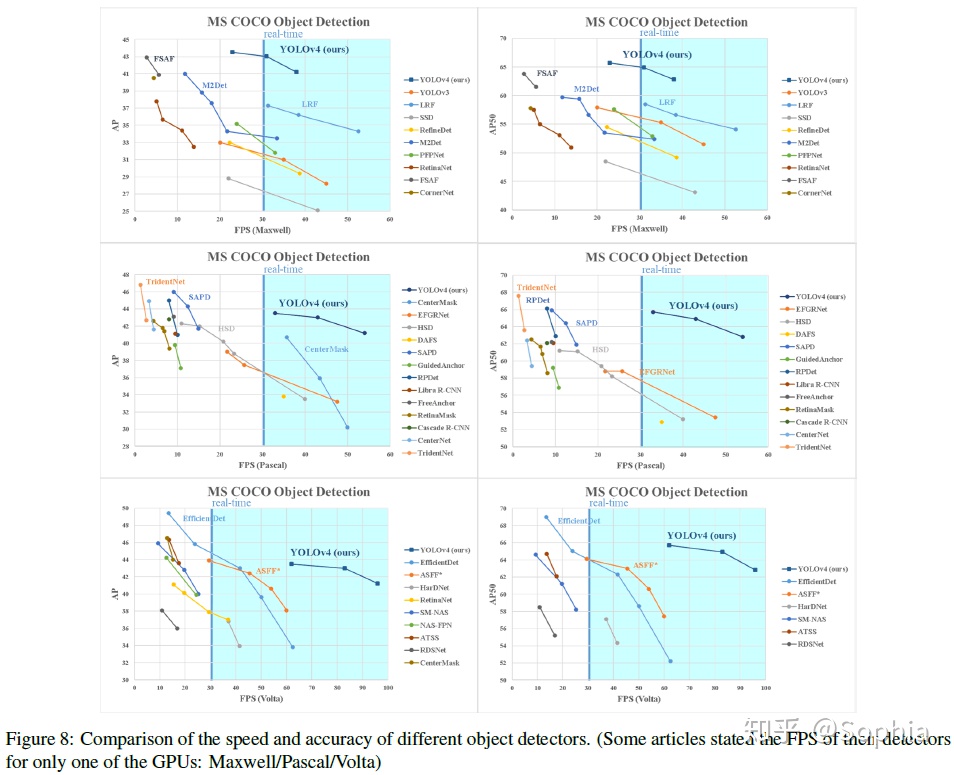
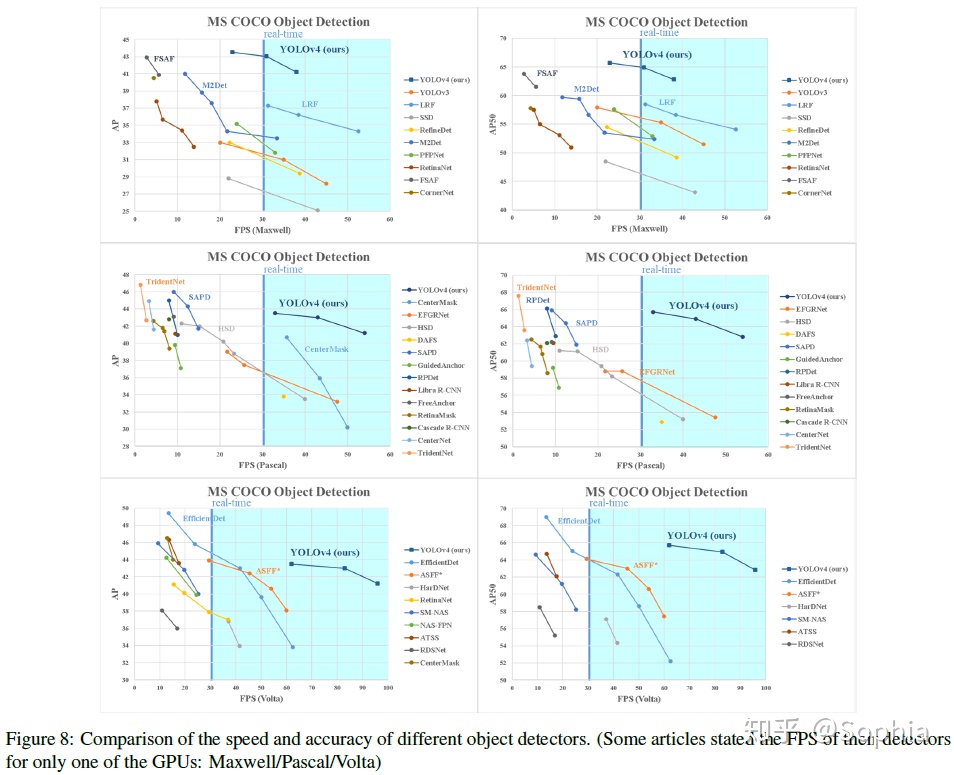
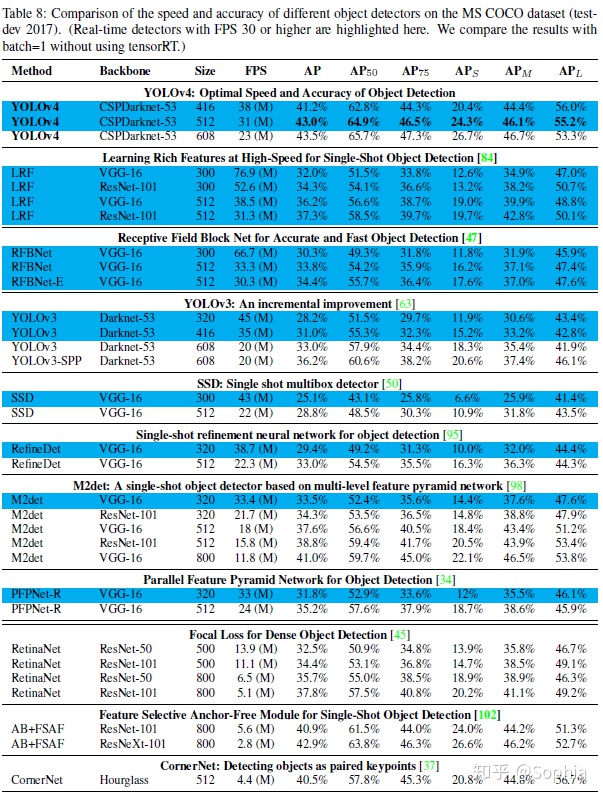
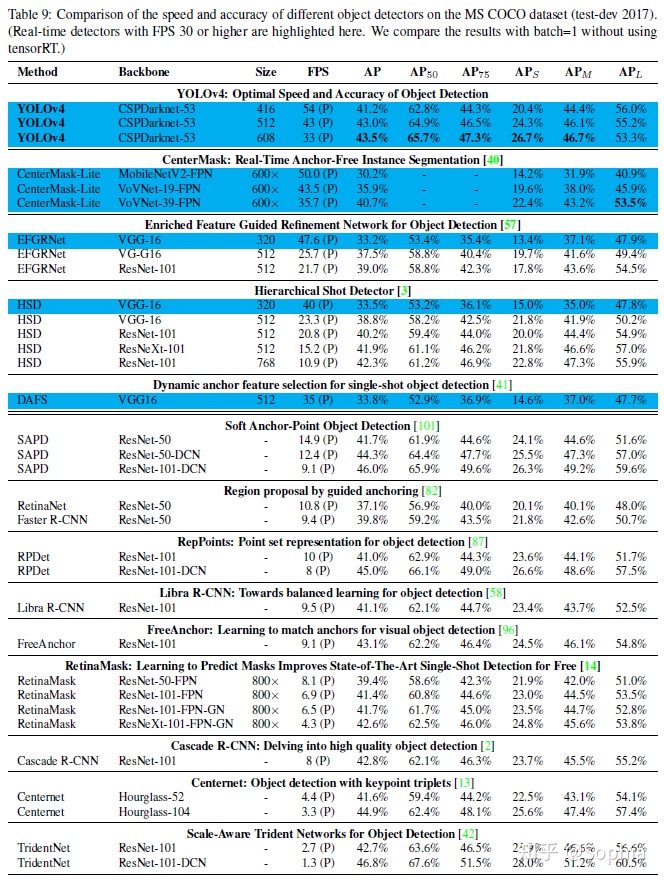
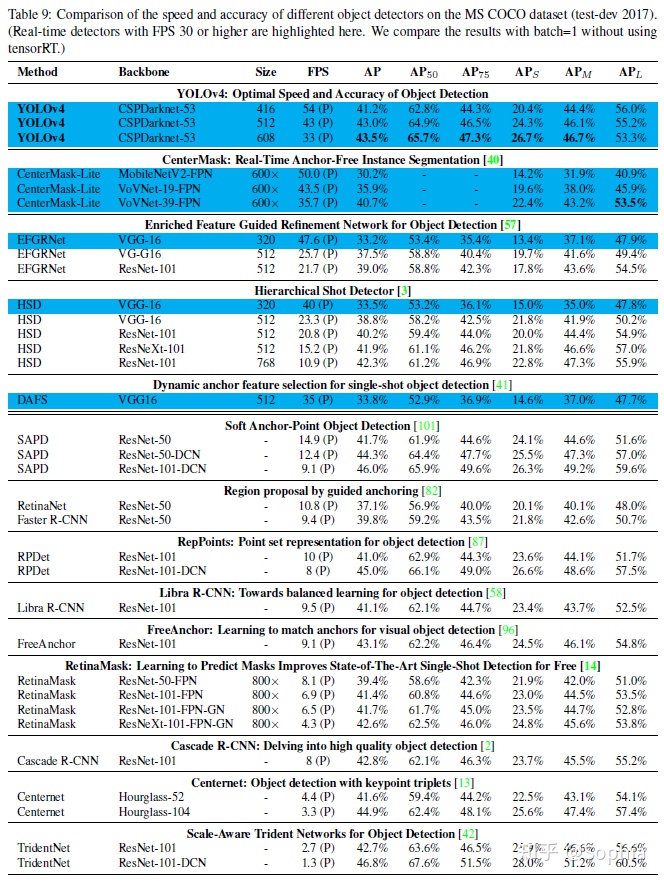
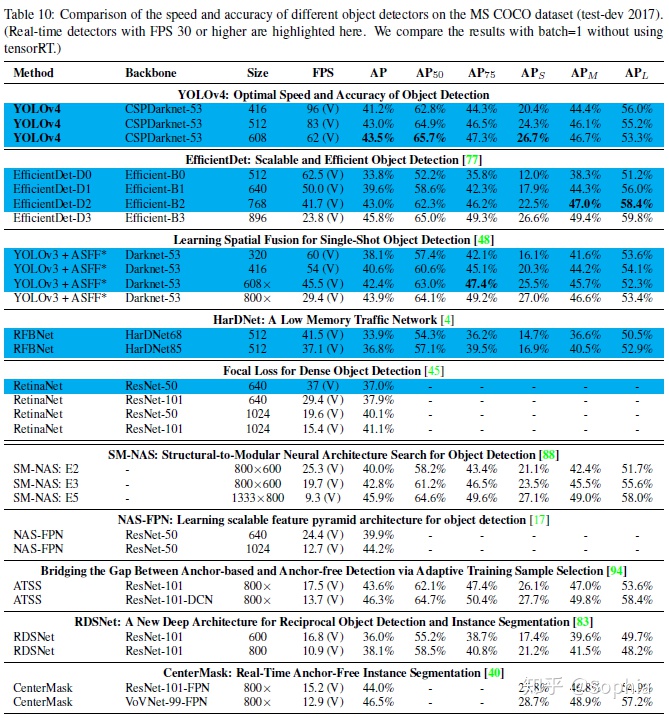
由於不同的方法使用不同體系結構的GPU進行推理時間驗證,我們在常用的Maxwell、Pascal和VoltaArchitecture體系結構的GPU上運行YOLOv4,並將它們與其他先進的方法進行了比較。表8列出了使用Maxwell GPU的幀率比較結果,可以是GTX Titan X(Maxwell)或Tesla M40 GPU。表9列出了使用Pascal GPU的幀率比較結果,它可以是Titan X(Pascal)、Titan XP、GTX 1080 Ti或Tesla P100 GPU。表10列出了使用VoltaGPU的幀率對比結果,可以是Titan Volta,也可以是Tesla V100 GPU。
6、Conclusions
我們提供最先進的檢測器,其速度(FPS)和準確度(MS COCO AP50 ... 95和AP50)比所有可用的替代檢測器都高。所描述的檢測器可以在具有8-16GB-VRAM的常規GPU上進行訓練和使用,這使得它的廣泛使用成爲可能。一階段基於錨的探測器的原始概念已證明其可行性。我們已經驗證了大量特徵,並選擇使用其中的一些特徵以提高分類器和檢測器的準確性。這些功能可以用作將來研究和開發的最佳實踐。
7、Acknowledgements
作者要感謝Glenn Jocher進行Mosaic數據增強的想法,通過使用遺傳算法選擇超參數並解決網格敏感性問題的方法https://github.com/ultralytics/yolov3.10。