Transformer 用在圖像識別上會存在計算效率過低的挑戰,最近一篇向 ICLR 2021 大會提交的論文似乎很好地解決了這一問題,其研究的 PyTorch 代碼也已在 GitHub 上開源。
在自然語言處理領域(NLP)成爲重要力量的 Transformer 技術最近已經開始在計算機視覺領域展現自己的實力。不過到目前爲止,由於 Transformer 注意力機制對內存的需求是輸入圖像的二次方,所以這一方向還存在一些挑戰。
近日,LambdaNetworks 的出現提供了一種解決此問題的方法,人們可以無需建立昂貴的注意力圖即可捕捉長距離交互。這一方法在 ImageNet 上達到了新的業界最佳水平(state-of-the-art)。
GitHub鏈接: https://github.com/lucidrains/lambda-networks
對長程交互進行建模在機器學習中至關重要。注意力已成爲捕獲長程交互的一種常用範式。但是,自注意力二次方式的內存佔用已經阻礙了其對長序列或多維輸入(例如包含數萬個像素的圖像)的適用性。例如,將單個多頭注意力層應用於一批 256 個64x64 (8 頭)輸入圖像需要32GB的內存,這在實踐中是不允許的。
該研究提出了一種名爲「lambda」的層,這些層提供了一種捕獲輸入和一組結構化上下文元素之間長程交互的通用框架。
lambda 層將可用上下文轉換爲單個線性函數(lambdas)。這些函數直接單獨應用於每個輸入。研究者認爲,lambda 層可以作爲注意力機制的自然替代。注意力定義了輸入元素和上下文元素之間的相似性核,而 lambda 層將上下文信息彙總爲固定大小的線性函數,從而避免了對內存消耗大的注意力圖的需求。這種對比如圖1所示。
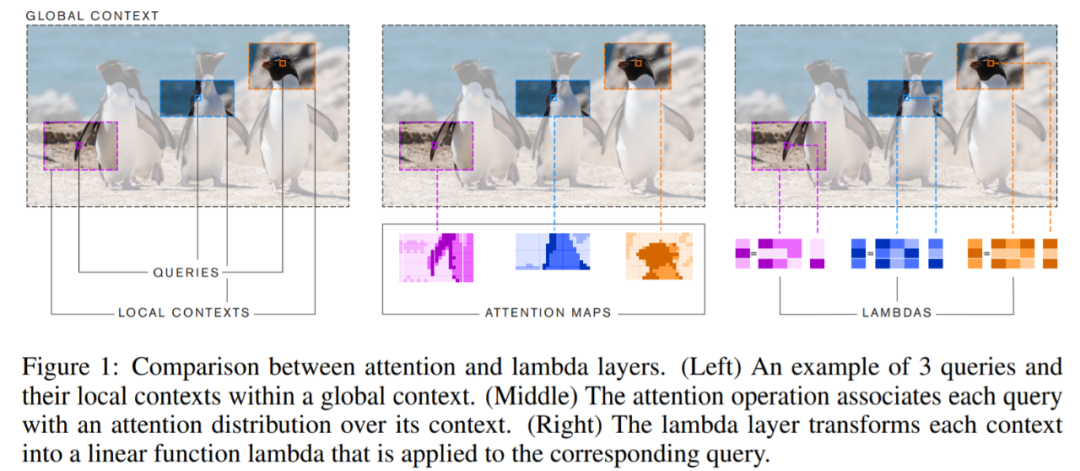 研究者證明了 lambda 層的通用性,展示了它們的實現可以被用來捕獲全局、局部或掩模上下文中基於內容和位置的交互。利用lambda生成的神經網絡 LambdaNetwork 計算效率很高,能夠以很小的內存成本建模長程依賴,因而可用於高分辨率圖像等大型結構化輸入。
研究者證明了 lambda 層的通用性,展示了它們的實現可以被用來捕獲全局、局部或掩模上下文中基於內容和位置的交互。利用lambda生成的神經網絡 LambdaNetwork 計算效率很高,能夠以很小的內存成本建模長程依賴,因而可用於高分辨率圖像等大型結構化輸入。
研究者在計算機視覺任務上評估了 LambdaNetwork,在這些任務上,自注意力顯示出了希望,但遇到了內存成本高昂和無法實際實現的問題。在 ImageNet 分類、COCO 目標檢測和實例分割三方面的對照實驗表明,LambdaNetwork 顯著優於基於卷積和注意力的同類方法,並且計算效率更高、運行速度更快。
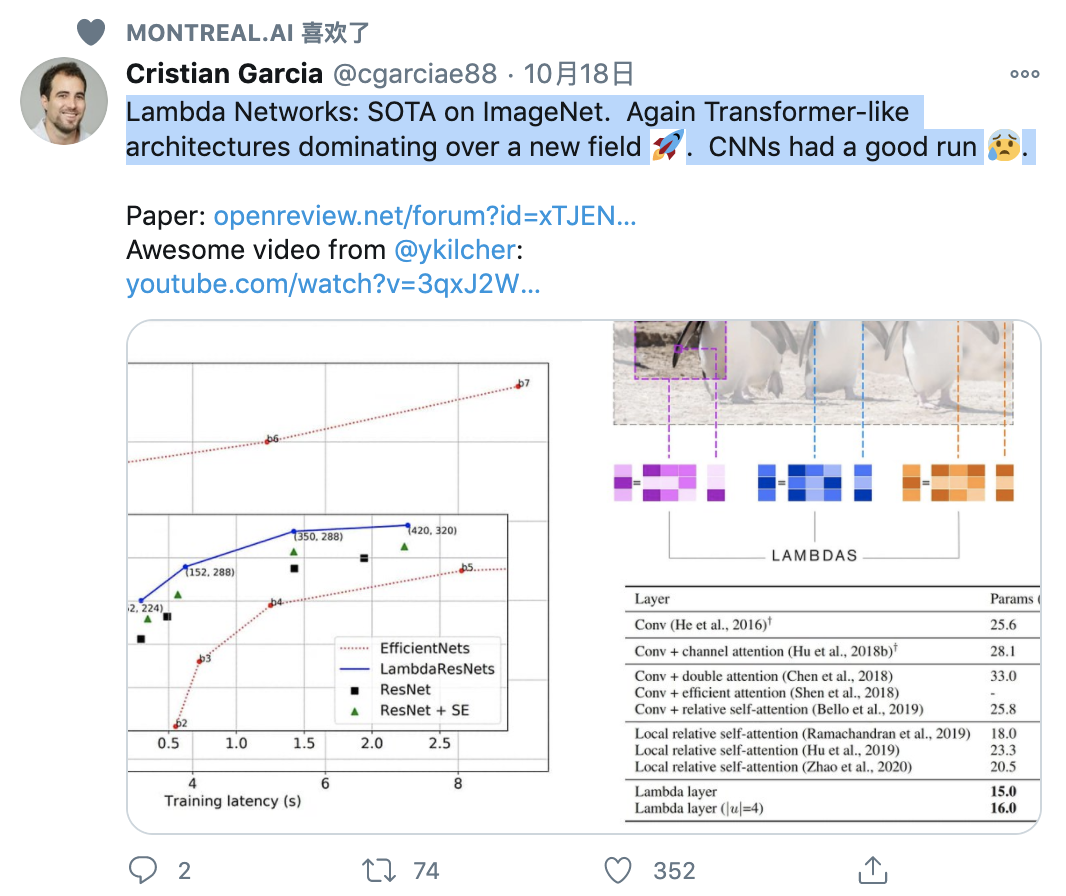
最後,研究者提出了 LambdaResNets,它顯著改善了圖像分類模型的速度-準確性權衡。具體而言,LambdaResNets 在實現 SOTA ImageNet 準確性的同時,運行速度是 EfficientNets 的4.5 倍左右。
建模長程交互
注意力交互。首先縮小查詢深度,創建查詢和上下文元素之間的相似性核(注意力圖),也就是所謂的注意力操作。該機制可以被看作激發查詢、鍵和數值術語的可微內存的尋址。由於上下文位置 |m| 的數量越來越大,並且輸入和輸出維數 |k| 和 |v| 保持不變,所以在層輸出是較小維數 |v| << |m| 的一個向量時,我們可以假設計算注意力圖是不划算的。
相反, 由於 y_n = F((q_n, n), C) = λ(C, n)(q_n) 擬合一些線性函數 λ(C, n),所以通過線性函數將每個查詢映射到輸出可能更有效率。在這種場景下,上下文聚合到一個固定大小的線性函數 λ_n = λ(C, n)。每個 λ_n作爲獨立於上下文(計算後)存在的小的線性函數,並在應用於關聯查詢q_n之後被丟棄。該機制令人聯想到與lambda這個術語相關的函數式編程和 λ 演算。
lambda層將輸入
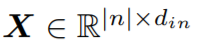 和上下文
和上下文
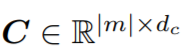 作爲輸入,生成線性函數lambdas,然後將其應用於查詢,從而得到輸出
作爲輸入,生成線性函數lambdas,然後將其應用於查詢,從而得到輸出
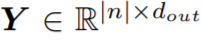 。
。
注意,在自注意力情況下可能有C=X。在不失一般性的前提下,研究者假設d_in=d_c=d_out=d。在論文的其他部分中,研究者將重點放在lambda層的特定實例上,並說明它可以在沒有注意力圖的情況下,處理密集的長程內容和基於位置的交互。
lambda層:將上下文轉換成線性函數
研究者首先在(q_n,n)的上下文中描述lambda層。由於研究者希望生成一個線性函數
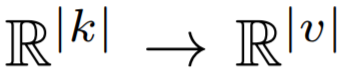 或將
或將
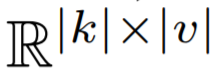 矩陣當作函數。
矩陣當作函數。
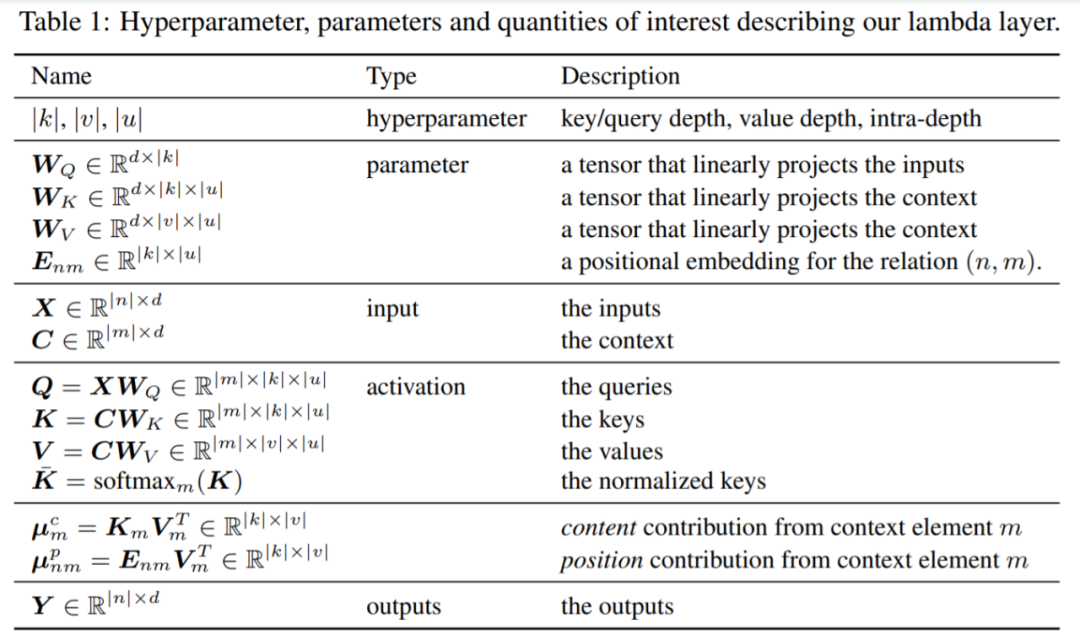
表1給出了lambda層的超參數、參數等量化數值。
 1. 生成上下文lambda函數
1. 生成上下文lambda函數
lambda層首先通過線性投影上下文來計算鍵和值,通過softmax運算對鍵進行歸一化,從而得到歸一化鍵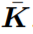 。
。
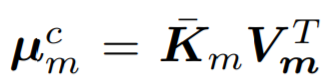 和一個位置函數
和一個位置函數
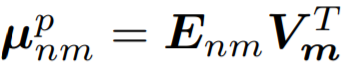 。λ_n 是通過將上下文貢獻求和得到的,如下所示:
。λ_n 是通過將上下文貢獻求和得到的,如下所示:
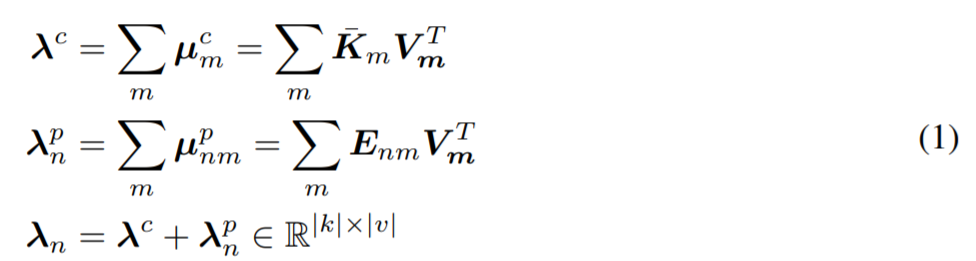
其中還定義了內容lambda λ^c和位置lambda λ^p_n。內容lambda λ^c對於上下文元素的排列組合是固定不變的,在所有的查詢位置n上共享,並且對如何轉換僅基於上下文內容的查詢內容q_n進行編碼。相比之下,位置lambda λ^p_n對如何根據內容c_m和位置(n, m)轉換查詢內容q_n,從而可以對諸如圖像之類的結構化輸入進行建模。
2. 將lambda應用於查詢
將輸入x_n轉換爲查詢 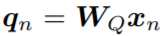 ,然後獲得lambda層的輸出爲
,然後獲得lambda層的輸出爲
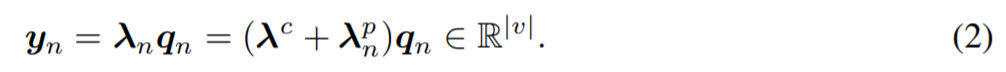
3. lambda解釋
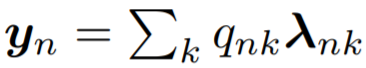 。
。
此過程可以捕獲密集內容和基於位置的長程交互,同時不產生注意力圖。
4. 歸一化
可修改方程式1和2以涵蓋非線性或歸一化運算。該研究的實驗表明,在計算查詢和值之後應用批歸一化是很有用的。
帶有結構化上下文的 lambda 層
1. 平移等變性
在很多學習情景中,平移等變性是一種很強的歸納偏置。基於內容的交互是置換等變的,因此它已經具備平移等變性。對於任意的平移 t,研究者通過確保位置嵌入滿足
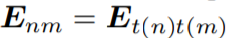 。在位置交互中得到平移不變性。在實踐中,研究者定義了相對位置嵌入
。在位置交互中得到平移不變性。在實踐中,研究者定義了相對位置嵌入
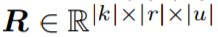 的一個張量。其中,r 表示所有 (n, m) 對的可能相對位置,並將其重新索引到
的一個張量。其中,r 表示所有 (n, m) 對的可能相對位置,並將其重新索引到
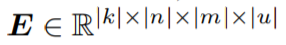 ,從而使得
,從而使得
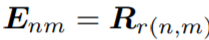 。
。
儘管長程交互有一定的優點,但在很多任務中,局部性依然是一種強大的歸納偏置。從計算的角度來看,使用全局上下文可能會增加噪聲,增加算力消耗。因此,將位置交互的範圍限制到查詢位置 n 周圍的一個局部鄰域,就像局部自注意和卷積中那樣,可能是一種有用的做法。這可以通過對所需範圍之外的上下文位置 m 的位置嵌入進行歸零來實現。但是,對於較大的 |m| 值,這種策略依然代價高昂,因爲計算仍在進行。
在這種上下文被安排在多維網格上的情況下,可以使用一個將 V 中的第 v 維視爲一個額外空間維度的常規卷積來從局部上下文中生成位置 lambda。例如,假設我們想在一維序列上生成局部範圍大小爲 |r| 的位置 lambdas。相對位置嵌入張量
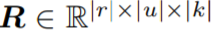 可以變爲
可以變爲
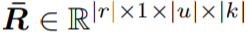 ,然後被用作一個二維卷積的卷積核,計算所需的位置 lambda
,然後被用作一個二維卷積的卷積核,計算所需的位置 lambda
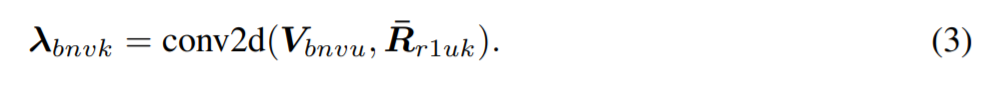
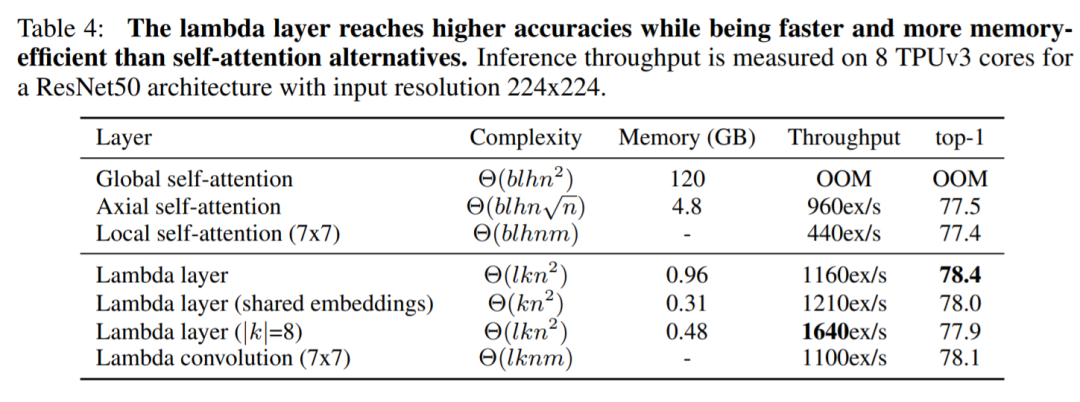
研究者將這個運算稱爲 lambda 卷積。由於現在的計算被限制在局部範圍內,lambda 卷積可以得到與輸入長度相關的線性時間和內存複雜度。lambda 卷積很容易用於 dilation 和 striding 等其他功能,並且在專用硬件加速器上享有高度優化的實現。這與局部自注意力的實現形成鮮明對比,後者需要物化重疊查詢和內存塊的特徵塊,從而增加了內存消耗和延遲(見下表4)。
 利用多查詢 lambda 降低複雜度
利用多查詢 lambda 降低複雜度
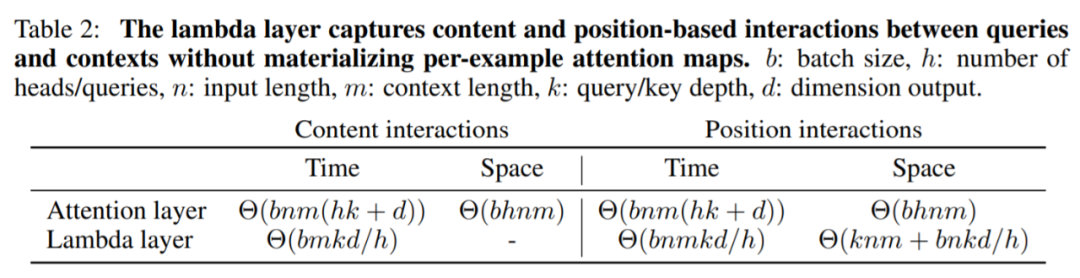
對於多個 |b| 元素,每個都包含 |n| 輸入。應用 lambda 層所需算數運算和內存佔用的數量分別爲 Θ(bnmkv) 和 Θ(bnkv + knm)。由於E_nm 參數捕獲了基於位置的交互 ,因此相對於輸入長度,研究者擁有的內存佔用仍是二次的。但是,這個二次項並不隨批大小擴展,這與生成每個示例(per-example)注意力圖譜的注意力操作一樣。在實踐中,超參數 |k| 設爲很小的值,如 |k| =16,並且在注意力失效的情況下可以處理大批量的大型輸入。
多查詢 lambdas 可以降低複雜度。lambdas 將注意力圖 q_n ∈ R^k映射到輸出 y_n ∈ R^d。如公式2所示,這意味着 |v|=d。所以,|v| 的較小值成爲了特徵向量 y_n上的瓶頸,但考慮到 Θ(bnmkv) 和 Θ(bnkv + knm) 的時間和空間複雜度,更大的輸入維數 |v| 將導致非常高昂的計算成本。
所以,研究者提出將 lambda 層的時間和空間複雜度從輸出維數 d 中解耦。他們並沒有強制地令 |v|=d,而是創建了 |h| 查詢 {q^h _n},將相同的 lambda 函數 λ_n 應用到每個查詢 q^h_n,並將輸出串連接成 y_n=concat(λ_nq^1_n , · · · ,λ_nq^|h|_n )。
由於每個 lambda 都應用於 |h| 查詢,所以研究者將這一操作當做多查詢 lambda 層。這也可以理解爲將 lambda 約束到具有 |h| 等重複塊的更小塊矩陣。現在d=|hv|,並且時間和空間複雜度變成了 Θ(bnmkd/h) 和 Θ(bnkd/h + knm)。此外,研究者注意到,這類似於多頭或多查詢注意力機制,但motivation不同。在注意力操作中使用多個查詢增強了表示能力和複雜度。而在本研究中,使用多查詢 lambdas 降低了複雜度和表示能力。
下表2比較了多查詢 lambda 層和多頭注意力操作的時間和空間複雜度:
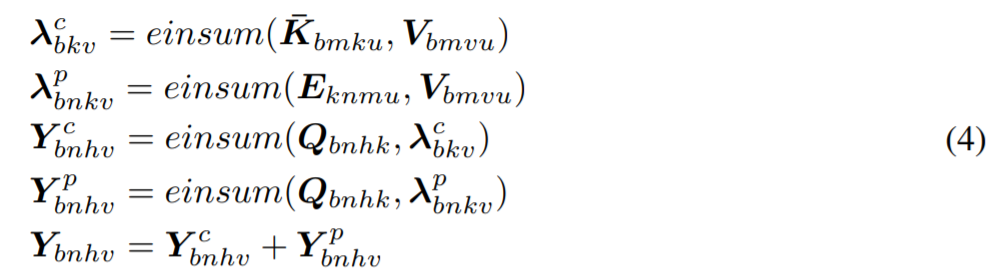
實驗
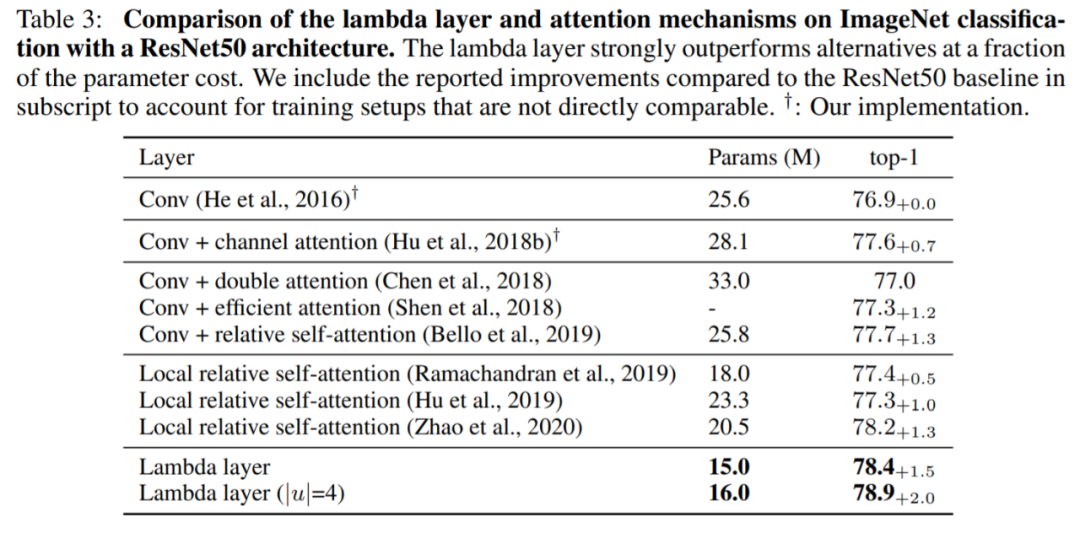
LambdaNetworks 優於基於卷積和注意力的同類方法
在下表 3 中,研究者進行了控制實驗,以比較 LambdaNetworks 與 a)基線 ResNet50、b)通道注意力和 c)以往使用自注意力來補充或替換 ResNet50 中的 3x3 卷積的研究方法。結果顯示,在參數成本僅爲其他方法一小部分的情況下,lambda 層顯著優於這些方法,並且相較於 Squeeze-and-Excitation(通道注意力)實現了 +0.8% 的提升。
 在上表 4 中,研究者對比了 lambda 層和自注意力機制,並給出了它們的吞吐量、內存複雜度和 ImageNet 圖像識別準確性比較,這一結果展示了注意力機制的不足。相比之下,lambda 層可以捕獲高分辨率圖像上的全局交互,並可以比局部自注意力機制獲得多 1.0% 的提升,同時運行速度幾乎是後者的 3 倍。
在上表 4 中,研究者對比了 lambda 層和自注意力機制,並給出了它們的吞吐量、內存複雜度和 ImageNet 圖像識別準確性比較,這一結果展示了注意力機制的不足。相比之下,lambda 層可以捕獲高分辨率圖像上的全局交互,並可以比局部自注意力機制獲得多 1.0% 的提升,同時運行速度幾乎是後者的 3 倍。
此外,位置嵌入也可以在 lambda 層之間共享,以最小的降級花費進一步降低了內存使用的需求。最後,lambda 卷積具有線性內存複雜度,這在圖像檢測和分割任務中遇到非常大的圖片時非常有用。
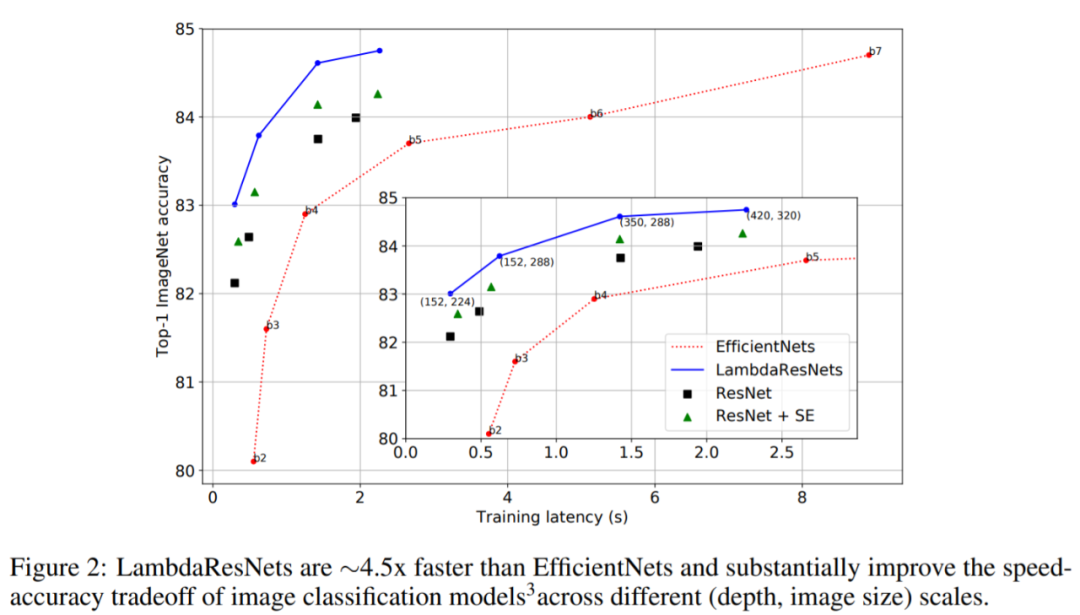
LambdaResNets 明顯改善了 ImageNet 分類任務的速度-準確性權衡
下圖 2 展示了 LambdaResNets與使用或不使用 channel attention 機制的ResNet 及最流行的 EfficientNets 相比的效果。LambdaResNets 在所有深度和圖像尺度上均優於基準水平,最大的 LambdaResNet 實現了 SOTA 水平準確度 84.8。更值得注意的是,LambdaResNets 在準確性一定的情況下比 EfficientNets 要快大概 3.5 倍,速度-準確性曲線提升明顯。
在下表5和表6中,研究者發現構造 LambdaResNets 來提升大型 EfficientNets 的參數和 flops 效率也是有可能的。


目標檢測與實例分割
最後,研究人員評估了 LambdaResNets 使用 Mask-RCNN 架構在 COCO 數據集上進行目標檢測和實力分割任務的效果。使用 lambda 層會在所有 IoU 閾值和所有對象比例(尤其是難以定位的小對象)上產生一致的增益,這表明 lambda 層容易在需要定位信息的更復雜的視覺任務中實現不錯的效果。