這兩年, 頻頻有專家警示深度學習即將進入寒冬。 而同時, 一個名叫「類腦智能」的詞彙火起來, 這個概念說的是一種比目前深度學習更加接近人腦的智能。 這背後的故事是, 深度學習的大佬,目前已經注意到深度學習的原創性進展面臨瓶頸,甚至呼籲全部重來。爲了拯救這種趨勢, 模擬人腦再次成爲一種希望。 然而這一思路是否經得住深度推敲? 我本人做過多年計算神經科學和AI , 做一個拋磚引玉的小結。
AI發展的危機
人工智能, 目前多被理解成一個領域領應用的工程學科,從自動安防系統到無人駕駛是它的疆土,而模式識別和計算機專家, 是這片陸地的原住民。 目前的人工智能事實上以工程思維爲主, 從當下人工智能的主流深度學習來看, 打開任何一篇論文, 映入眼簾的是幾個知名數據集的性能比較,無論是視覺分類的ImageNet,Pascal Vol, 還是強化學習的Atari game。各種各樣的bench mark和曲線, 讓我們感覺像是一個CPU或者數碼相機的導購指南。
那麼, 是否這些在這些流行數據庫跑分最高的「智能工具"就更智能? 這可能取決於對」智能「 本身的定義。 如果你問一個認知專家「智能」是不是ImageNet的錯誤率, 那麼他一定會覺得相當好笑。 一個人可能在識別圖片的時候由於各種勞累和馬虎, 在這個數據集的錯誤率高於機器。但是隻要你去和它談任何一個圖片它所理解的東西, 比如一個蘋果, 你都會震驚於其信息之豐富, 不僅包含了真實蘋果的各種感官, 還包含了關於蘋果的各種文學影視, 從夏娃的蘋果, 到白雪公主的蘋果。 應該說, 人類理解的蘋果更加接近概念網絡裏的一個節點,和整個世界的所有其它概念相關聯, 而非機器學習分類器眼裏的n個互相分離的「高斯分佈」。
如果我們認爲, 」智能「 是解決某一類複雜問題的能力,是否我們就可以完全不care上述那種」理解「呢 ? 這樣的智能工具, 頂多是一些感官的外延, 而」感官「 是否可以解決複雜問題呢? 一個能夠準確的識別1000種蘋果的機器, 未必能有效的利用這樣的信息去思考如何把它在聖誕節分作爲禮品分發給公司的員工, 或者取悅你的女友。沒有」理解「 的智能, 將很快到達解決問題複雜度的上限。 缺少真正的理解, 甚至連做感官有時也會捉襟見肘, 你在圖像里加入各種噪聲, 會明顯的干擾分類的準確性, 這點在人類裏並不存在。比如下圖的小狗和曲奇, 你可以分出來,AI很難。

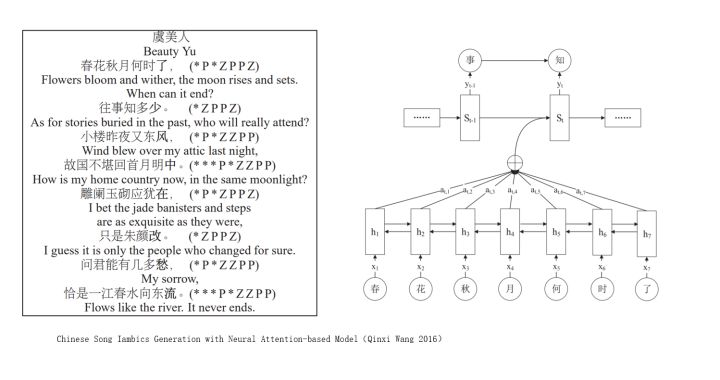
」語言「 在人類的智能裏享有獨一無二的特殊性,而剛剛的」理解「問題, 背後的本質是目前深度學習對語言的捉襟見肘。 雖然我們可以用強大的LSTM生成詩歌(下圖), 再配上注意力機制和外顯記憶與人類對話, 也不代表它能理解人類的這個語言系統。 目前機器對自然語言處理的能力遠不及視覺(當下的圖卷積網絡或可以這個領域做出貢獻)。
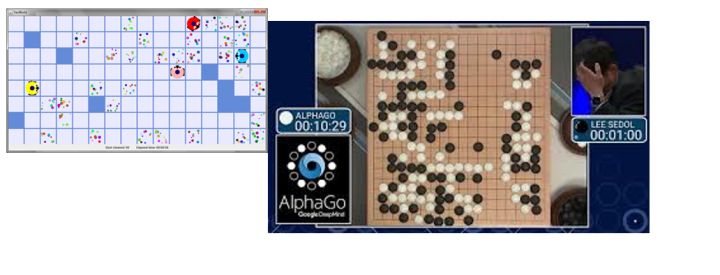
更加糟糕的還有強化學習, 深度強化學習已經戰勝了最強大的人類棋手。 但是強化學習卻遠非一種可靠的實用方法。 這裏面最難的在於目前的強化學習還做不到可擴展, 也就是從一個遊戲的問題擴展到真實的問題時候會十分糟糕。 一個已經學的很好的強化學習網絡,可以在自己已經學到的領域所向披靡, 然而在遊戲裏稍微增加一點變化, 神經網絡就不知所措。 我們可以想象成這是泛化能力的嚴重缺失, 在真實世界裏,這恰恰一擊致命。
事實上在很長時間裏,人工智能的過分依賴工科思維恰恰給它的危機埋下了伏筆,在人工數據上破記錄, 並不代表我們就會在剛說的「理解」上做進步。 這更像是兩個不同的進化方向。 其實, 關於智能的更深刻的理解, 早就是認知科學家,心理學家和神經科學家的核心任務。 如果我們需要讓人工智能進步, 向他們取經就看起來很合理。
腦科學與人工智能合作與分離的歷史
雖然看起來模擬生物大腦是達到更高層次人工智能的必由之路,但是從當下的人工智能學者的角度,這遠非顯然。 這裏的淵源來自人工智能的早期發展史,應該說深度學習來自於對腦科學的直接取經, 然而它的壯大卻是由於對這條道路的背離。 我們可以把這個歷史概括爲兩次合作一次分離。
第一次合作: 深度學習的前身-感知機。模擬人類大腦的人工智能流派又稱爲連接主義,最早的連接主義嘗試就是模擬大腦的單個神經元。 Warren McCulloch 和 WalterPitts在1943 提出而來神經元的模型, 這個模型類似於某種二極管或邏輯門電路。事實上, 人們很快發現感知機的學習有巨大的侷限性,Minksky等一批AI早期大師發現感知機無法執行「異或」這個非常基本的邏輯運算,從而讓人們徹底放棄了用它得到人類智能的希望。 對感知機的失望導致連接主義機器學習的研究陷入低谷達15年, 直到一股新的力量的注入。
第二次合作: 這次風波, 來自一羣好奇心極強的物理學家,在20世紀80年代,hopefiled提出了它的 Hopefield 網絡模型,這個模型受到了物理裏的Ising模型和自旋玻璃模型的啓發, Hopefield發現,自旋玻璃和神經網絡具有極大的相似性。每個神經元可以看作一個個微小的磁極, 它可以一種極爲簡單的方法影響周圍的神經元,一個是興奮(使得其他神經元和自己狀態相同), 一個是抑制(相反)。 如果我們用這個模型來表示神經網絡, 那麼我們會立刻得到一個心理學特有的現象: 關聯記憶。 比如說你看到你奶奶的照片, 立刻想到是奶奶,再聯想到和奶奶有關的很多事。 這裏的觀點是, 某種神經信息(比如奶奶)對應神經元的集體發放狀態(好比操場上正步走的士兵), 當奶奶的照片被輸入進去, 它會召喚這個神經元的集體狀態, 然後你就想到了奶奶。
由於這個模型可以模擬心理學的現象, 人們開始重新對模擬人腦的人工智能報以希望。 人們從不同領域開始涌入這個研究。 在這批人裏,發生了一個有趣的分化。 有的人沿着這個路數去研究真實大腦是怎麼思考的, 有的人則想直接用這個模型製造機器大腦, 前者派生出了計算神經科學, 後者則導致了聯結主義機器學習的復興, 你可以理解爲前者對貓感興趣,後者只對機器貓感興趣,雖然兩者都在那裏寫模型。 CNN和RNN分別在80年中後期被發現, 應該說, CNN的結構是直接借鑑了Husel和Wiesel 發現的視覺皮層處理信息的原理, 而RNN則是剛剛說到的Hopefield 網絡的一個直接進化。


一批人用模型研究真實大腦, 另一批研究機器大腦
AI與腦科學的分離: 90年代後人工智能的主流是以支持向量機爲代表的統計機器學習, 而非神經網絡。 在漫長的聯結主義低谷期, Hinton堅信神經網絡既然作爲生物智能的載體, 它一定會稱爲人工智能的救星, 在它的努力下, Hopefield網絡很快演化稱爲新的更強大的模型玻爾茲曼機, 玻爾茲曼機演化爲受限玻爾茲曼機, 自編碼器, 堆疊自編碼器,這已經很接近當下的深度網絡。 而深度卷積網絡CNN則連續打破視覺處理任務的記錄,宣佈深度學習時代開始。
然而, 如果你認爲這一股AI興起的風波的原因是我們對大腦的借鑑, 則一定會被機器學習專家diss,恰恰相反,這波深度學習的崛起來自於深度學習專家對腦科學的背離。 CNN雖然直接模擬了大腦視皮層結構的模擬, 利用了層級編碼, 局部網絡連接, 池化這樣和生物直接相關的原理。但是, 網絡的訓練方法,卻來自一種完全非生物的方法。 由於信息存儲在無數神經元構成的網絡連接裏, 如何讓它學進去, 也是最難的問題。很久以前,人們使用的學習方法是Hebian learning 的生物學習方法, 這種方法實用起來極爲困難。 Hinton等人放棄這條道路而使用沒有生物支撐但更加高效的反向傳播算法, 使得最終訓練成功。 從此數據猶如一顆顆子彈打造出神經網絡的雛形 ,雖然每次只改一點點, 最終當數據的量特別巨大, 卻發生一場質變。
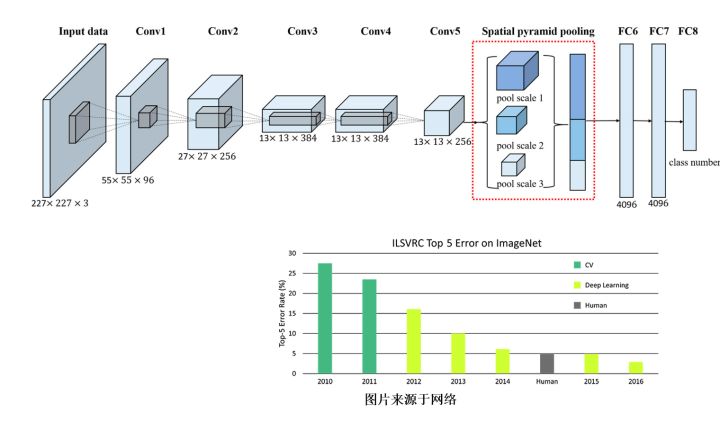
CNN能夠在2012 年而不是2011或者2010年開始爆發是因爲那一年人們提出了Alexnet。 而Alexnet比起之前的Lenet一個關鍵性的微小調整在於使用Relu,所謂線性整流單元替換了之前的Sigmoid作爲激活函數。Simoid 函數纔是更加具有生物基礎的學習函數, 然而能夠拋棄模擬大腦的想法使用Relu, 使得整個網絡的信息流通通暢了很多。
深度學習另一條主線, 沿着讓機器聽懂人類的語言, 一種叫LSTM的神經網絡, 模擬了人類最奇妙的記憶能力, 並卻開始處理和自然語言有關的任務, LSTM框架的提出依然是沒有遵循大腦的結構,而是直接在網絡裏引入類似邏輯門的結構控制信息。
由此我們看到, 神經網絡雖然在誕生之初多次吸收了生物學的原理本質, 而其最終的成功卻在於它大膽的脫離生物細節, 使用更加講究效率的數理工科思維。 生物的細節千千萬, 有一些是進化的副產品, 或者由於生物經常捱餓做出的妥協, 卻遠非智能的必須, 因此對它們的拋棄極大的解放了人工智能的發展。
腦科學究竟能否開啓深度學習時代的下個階段
那麼生物神經網絡究竟可不可以啓發人工智能呢? 剛剛的分析我們看到生物的細節並不一定對人工智能有幫助, 而生物大腦計算的根本原理卻始終在推動深度學習 。 正如CNN的發展直接使用了層級編碼的原理, 然後根據自己計算的需求重新設定了細節, 無論如何變化, 生物視覺處理和CNN背後的數學核心卻始終保持一致。
那麼目前的深度學習工具用到了多少生物大腦計算的基本原理呢, 答案是, 冰山一角。 如果說人工智能要繼續革命, 那麼無疑還要繼續深挖這些原理,然後根據這些原則重新設定細節。 答案很簡單, 宇宙的基本定律不會有很多, 比如相對論量子論這樣的根本原理幾乎統治物理世界。 如果生物大腦使用一套原理實現了智能, 那麼很可能人工智能也不會差很遠。即使細節差距很大, 那個根本的東西極有可能是一致的。
這樣的數學原理應該不會有很多條, 因爲人腦的結構一個驚人的特點就是雖然腦區非常不同, 但不同腦區的構造卻極爲相似, 這種相似性顯示了大腦不同腦區使用類似的基本原理。 我們目前的深度學習算法, 無論是CNN還是RNN,都只是發現了這個基本原理的某個局部。 發現這個基本原理, 恰恰是計算神經科學的使命。 對於智能這個上帝最傑出的作品, 我們能做的只有盲人摸象, 目前摸到的東西有一些已經被用到了人工智能裏, 有些則沒有,我們隨便舉幾個看看。
確定已經被應用的原理:
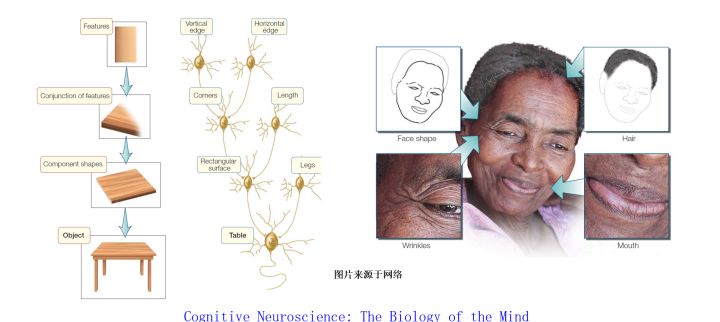
1. 層級編碼原理(Hierarchical coding): 生物神經網絡最基本的結構特點是多層, 無論是視覺, 聽覺, 我們說基本的神經迴路都有層級結構, 而且經常是六層。這種縱深的層級, 對應的編碼原理正是從具體特徵到抽象特徵的層級編碼結構。 最有名的莫過於祖母細胞, 這一思路直接催生了以CNN爲代表的深度學習。
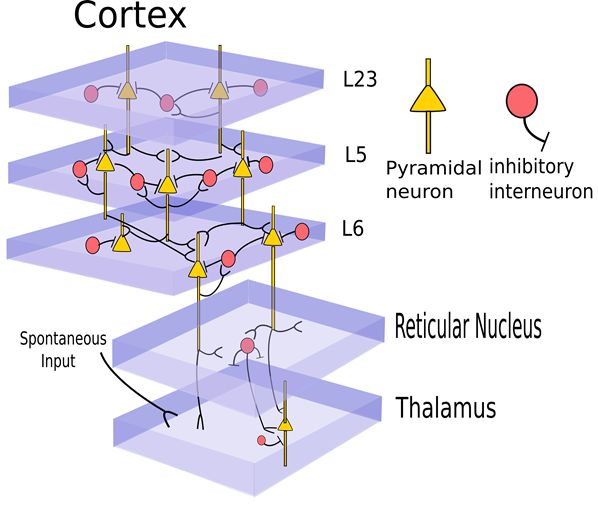
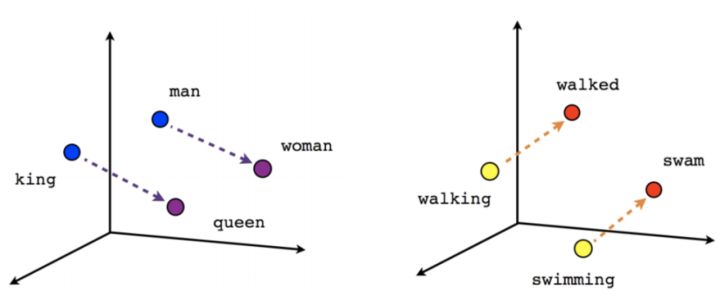
2. 集羣編碼原理 (Distributed coding): 一個與層級編碼相對應的生物神經編碼假設是集羣編碼, 這裏說的是一個抽象的概念, 並非對應某個具體的神經元, 而是被一羣神經元所表述。 這種編碼方法, 相比層級編碼, 會更具備魯棒性, 或更加反脆弱,因爲刪除一些細胞不會造成整體神經迴路的癱瘓。 集羣編碼在深度學習裏的一個直接體現就是詞向量編碼, word2vect, 詞向量編碼並沒有採取我們最常想到的每個向量獨立的獨熱編碼, 而是每個向量裏有大量非零的元素, 如此好比用一個神經集羣表述一個單詞, 帶來的好處不僅是更加具有魯棒性, 而且我們無形中引入了詞語之間本來的互相關聯,從而使得神經網絡更好的吸收語義信息, 從而增加了泛化能力。 在此處, 每個詞語概念都有多個神經元表達, 而同一個神經元,可以參與多個概念的描述。 這與之前說的每個概念比如祖母對應一個特定的神經元有比較大的區別。
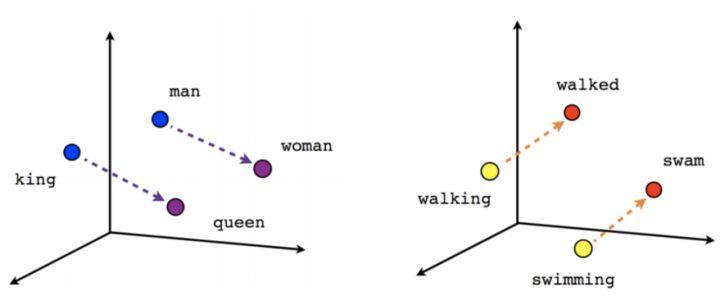
然而目前的深度學習依然缺乏對集羣編碼更深刻的應用, 這點上來看,計算神經科學走的更遠,我們使用RNN內在的動力學特性, 可以編碼很多屬性。
局部被應用或沒有被應用的原理:
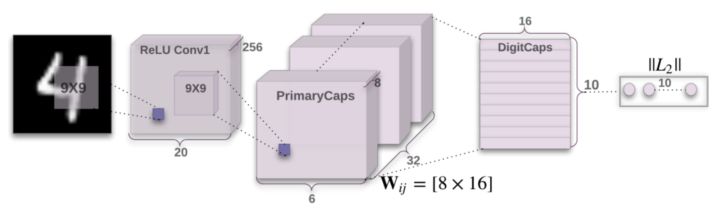
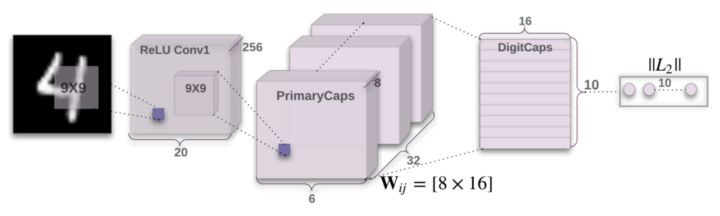
1.cortical minicolumn:皮層內的神經元都採取簇狀結構, 細胞之間不是獨立的存在, 而是聚集成團簇, 猶如一個微型的柱狀體。 這些柱狀體成爲信息傳輸的基本單元。 這種驚人一致的皮層內結構, 背後的認知原理是什麼呢? 目前還沒有定論。 但是Hinton已經把類似的結構用到了Capsule Network , 在那裏, 每個Capsule對應一個簇狀體, 而它們有着非常明確的使命, 就是記錄一個物體的不同屬性, 由於一個Capsule有很多神經元構成,它也可以看作一個神經元向量, 如果它用來記錄一組特徵, 則可以對付向旋轉不變性這種非常抽象的性質。

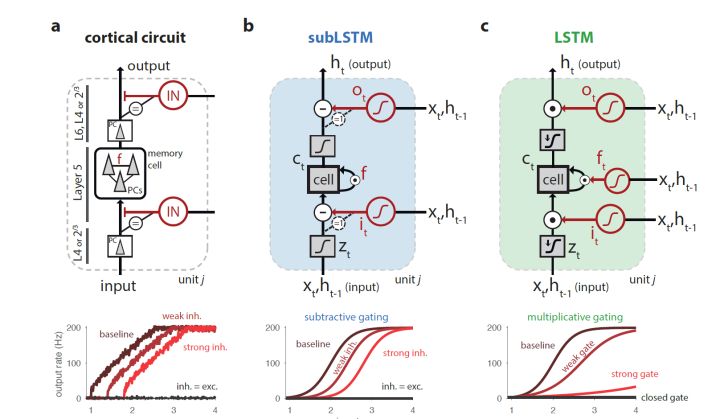
2.興奮抑制平衡: 生物神經系統的各個組成部分, 尤其是靠近深層的腦區, 都具有的一個性質是興奮性和抑制性神經元的信號互相抵消,猶如兩個隊伍拔河, 兩邊勢均力敵(最終和爲零)。這使得每個神經元接受的信息輸入都在零附近, 這帶來的一個巨大的好處是神經元對新進入信號更加敏感, 具有更大的動態範圍。 這個原理已經被深度學習悄悄的介入了, 它的直接體現就是極爲實用的batch normalization, 輸入信號被加上或減去一個值從而成爲一個零附近的標準高斯分佈(這和興奮抑制平衡效果類似), 從而大大提升了網絡梯度傳輸的效率。
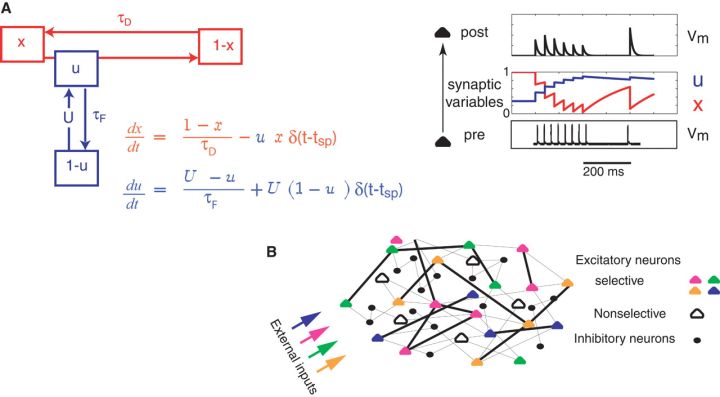
3.動態網絡連接: 生物神經系統的神經元和神經元之間的連接-突觸本身是隨放電活動變化的。 當一個神經元經過放電, 它的活動將會引起細胞突觸鈣離子的濃度變化,從而引起兩個神經元間的連接強度變化。這將導致神經網絡的連接權重跟着它的工作狀態變化, 計算神經科學認爲動態連接的神經網絡可以承載工作記憶, 而這點並沒有被目前的深度學習系統很好利用 。
4.Top down processing: 目前深度學習使用的網絡以前向網絡爲主(bottom up), 而事實上, 在生物大腦裏, 不同腦區間反饋的連接數量超過前向的連接, 這些連接的作用是什麼? 一個主流的觀點認爲它們是從高級腦區向感官的反向調節(top down), 如同我們所說的相由心生, 而不是相由眼生。 同一個圖片有美女拿着蛋糕, 可能一個你在飢腸轆轆的時候只看到蛋糕而吃飽了就只看到美女。 我們所看到的,很大程度上取決於我們想要看到什麼,以及我們的心情 。這點對我們的生存無疑十分重要, 你顯然不是在被動的認知和識別物體, 你的感知和認知顯然是統一的。 你在主動的搜索對你的生存有利的物體, 而非被動的感覺外界存在。這一點目前深度學習還完全沒有涉及。 一個引入相應的機制的方法是加入從深層神經網絡返回輸入層的連接,這樣深層的神經活動就可以調控輸出層的信息處理, 這可能對真正的「 理解」 有着極爲重大的意義。
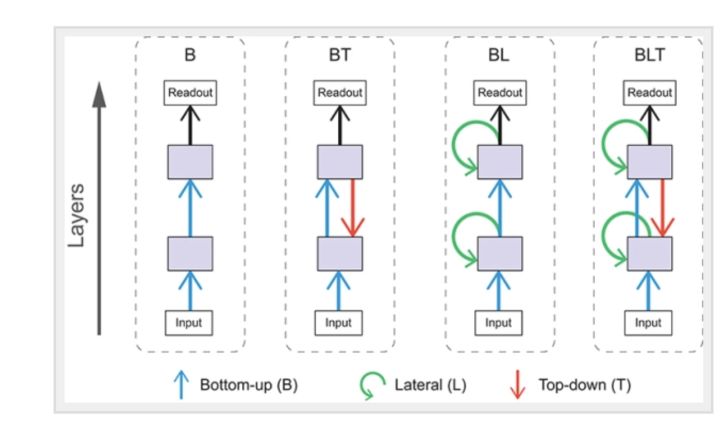
給卷積神經網絡加入從輸出端返回輸入端的連接, 是一個深度學習未來的重要方向Deep Convolutional Neural Networks as Models of the Visual System
5.Grid Cells: 海馬柵格細胞是一組能夠集羣表徵空間位置的細胞, 它們的原理類似於對物體所在的位置做了一個傅里葉變換, 形成一組表徵物體空間位置的座標基。爲什麼要對空間裏物體的位置做一次傅里葉變換, 這裏包含的原理是對任何環境中的物體形成通用的空間表示, 在新的環境裏也可以靈活的學習物體的位置,而不是一下子成爲路癡。
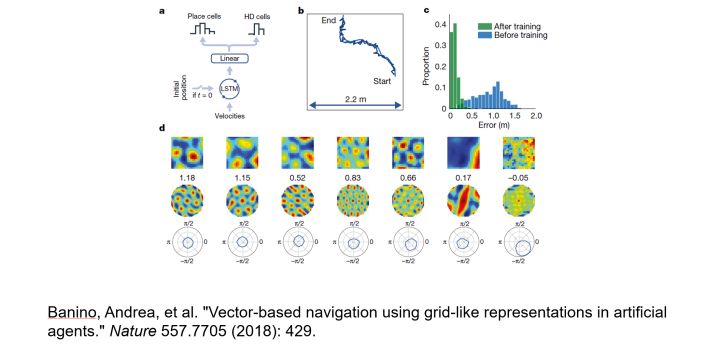
我們對柵格細胞的認知可能只是更大的神經編碼原則的一個局部,正如同傅里葉變換和量子力學之間存在着隱祕的聯繫。 雖然柵格網絡,目前已經被Deepmind用於空間導航任務, 但是目前AI所應用的應該只是這一原理的冰山一角。
6.Dale Principle: Dale Principle 說的是興奮型和抑制型神經元 是完全分開的,猶如動物分雌雄。 興奮性神經元只對周圍神經元發放正向反饋(只分泌興奮性遞質, 如Glutamine),讓其它神經元一起興奮, 而抑制型神經元只發放負向反饋(只分泌抑制型遞質, 如GABA),取消其它神經元的興奮。 目前的深度學習網絡不會對某個神經元的連接權重做如此限制 ,每個神經元均可向周圍神經元發放正或負的信號。 這一原理到底對AI有沒有作用目前未知。

7.Routing by Inhibitory cells : 生物神經系統包含種類豐富的抑制型神經元, 它們往往在生物神經網絡起到調控功能,如同控制信息流動的路由器,在合適的時候開啓或關閉某個信號。 當下的AI直接用attention的機制, 或者LSTM裏的輸入門來調控是否讓某個輸入進入網絡, 其它一點類似路由器的作用, 但是種類和形式的多樣性遠不及生物系統。
8.臨界: 大腦的神經元組成一個巨大的喧鬧的動力系統, 根據很多實驗數據發現, 這個動力系統處於平衡和混沌的邊緣, 被稱爲臨界。 在臨界狀態, 神經元的活動是一種混亂和秩序的統一體, 看似混亂, 但是隱含着生機勃勃的秩序。 臨界是不是也可以用於優化目前的深度學習系統, 是一個很大的課題。
9.自由能假說: 這個假定認爲大腦是一臺貝葉斯推斷機器。 貝葉斯推斷和決策的核心即由最新採納的證據更新先驗概率得到後驗概率。 認知科學的核心(Perception)就是這樣一個過程。
10.一些未被量化的心理學和認知科學領地,比如意識。 意識可以理解爲自我對自我本身的感知。 關於意識的起源,已經成爲一個重要的神經科學探索方向而非玄學, 最近的一些文章指出(The controversial correlates of consiousness - Science 2018), 意識與多個腦區協同的集體放電相關。 但是, 關於意識的一個重大疑團是它對認知和智能到底有什麼作用, 還是一個進化的副產物。 如果它對智能有不可替代的作用, 那麼毫無疑問, 我們需要讓AI最終擁有意識。 一個假說指出意識與我們的社會屬性相關, 因爲我們需要預測它人的意圖和行動, 就需要對它人的大腦建模, 從而派生了對自己本身大腦的感知和認知,從而有了意識。 那麼我們究竟需要不需要讓AI之間能夠互相交流溝通形成組織呢? 這就是一個更有趣的問題了。
深度學習對腦科學的啓發:
反過來, 深度學習的某些發現也在反向啓發腦科學, 這點正好對應費曼所說的, 如果你要真正理解一個東西, 請你把它做出來。 由於深度學習的BP算法太強大了, 它可以讓我們在不care任何生物細節的情況下任意的改變網絡權重, 這就好比給我們了一個巨大的檢測各種理論假設的東西。 由於當下對大腦連接改變的方式我們也只理解了冰山一角, 我們可以先丟下細節, 直接去檢驗所有可能的選項。 這點上看, 用深度學習理解大腦甚至更加有趣。
就那剛剛講的興奮抑制平衡來看, 最初人們對興奮抑制平衡作用的理解更多停留在它通過對信號做一個信息增益, 而在深度學習興起後 , 我們越來越多的把它的功能和batch normalization 聯繫起來, 而batch normalization更大的作用在於對梯度消失問題的改進, 而且提高了泛化性能, 這無疑可以提示它的更多功能。 而最近的一篇文章甚至直接將它和LSTM的門調控機制聯繫起來。 抑制神經元可以通過有條件的發放對信息進行導流, 正如LSTM種的輸入門, 輸出門的作用, 而互相連接的興奮神經元則作爲信息的載體(對應LSTM中央的循環神經網絡)
我們距離通用人工智能可能還有多遠?
其實人工智能的目標就是找尋那個通用人工智能,而類腦計算是實現它的一個重要途徑 。 通用智能和當下的智能到底有什麼實質性的區別, 作爲本文結尾, 我們來看一下:
對數據的使用效率: 比如大腦對數據的應用效率和AI算法並非一個等級, 你看到一個數據, 就可以充分的提取裏面的信息,比如看到一個陌生人的臉, 你就記住他了, 但是對於目前的AI算法, 這是不可能的, 因爲我們需要大量的照片輸入讓他掌握這件事。 我們可以輕鬆的在學完蛙泳的時候學習自由泳, 這對於AI,就是一個困難的問題, 也就是說,同樣的效率, 人腦能夠從中很快提取到信息, 形成新的技能, AI算法卻差的遠。
這是爲什呢? 可能這裏的掛件體現在一種被稱爲遷移學習的能力。雖然當下的深度學習算法也具備這一類舉一反三的遷移學習能力, 但是往往集中在一些真正非常相近的任務裏, 人的表現卻靈活的多。這是爲什麼呢? 也許, 目前的AI算法缺少一種元學習的能力。 和爲元學習, 就是提取一大類問題裏類似的本質, 我們人類非常容易乾的一個事情。 到底什麼造成了人工神經網絡和人的神經網路的差距, 還是未知的, 而這個問題也構成一個非常主流的研究方向。
能耗比:如果和人類相比, 人工智能系統完成同等任務的功耗是人的極多倍數(比如阿法狗是人腦消耗的三百倍, 3000MJ vs 10MJ 5小時比賽)。 如果耗能如此劇烈, 我們無法想象在能源緊張的地球可以很容易大量普及這樣的智能。 那麼這個問題有沒有解呢? 當然有, 一種, 是我們本身對能量提取的能力大大增強, 比如小型可控核聚變實用化。 另一種, 依然要依靠算法的進步, 既然人腦可以做到的, 我們相信通過不斷仿生機器也可以接近。 這一點上我們更多看到的信息是, 人工智能的能耗比和人相比, 還是有很大差距的。
不同數據整合: 我們離終極算法相差甚遠的另一個重要原因可能是現實人類在解決的AI問題猶如一個個分離的孤島, 比如說視覺是視覺, 自然語言是自然語言, 這些孤島並沒有被打通。 相反,人類的智慧裏, 從來就沒有分離的視覺, 運動或自然語言, 這點上看, 我們還處在AI的初級階段。 我們可以預想, 人類的智慧是不可能建立在一個個分離的認知孤島上的, 我們的世界模型一定建立在把這些孤立的信息領域打通的基礎上, 纔可以做到真正對某個事物的認知, 無論是一個蘋果, 還是一隻狗。
溝通與社會性: 另外, 人類的智慧是建立在溝通之上的, 人與人相互溝通結成社會, 社會基礎上纔有文明, 目前的人工智能體還沒有溝通, 但不代表以後是不能的, 這點, 也是一個目前的AI水平與強AI(超級算法)的距離所在。
有的人認爲, 我們可以直接通過模擬大腦的神經元,組成一個和大腦類似複雜度的複雜系統, 讓它自我學習和進化, 從而實現強AI。 從我這個複雜系統專業的角度看, 這還是一個不太現實的事情。因爲複雜系統裏面最重要的是涌現,也就是說當組成一個集合的元素越來越多,相互作用越來越複雜, 這個集合在某個特殊條件下會出現一些特殊的總體屬性,比如強AI,自我意識。 但是我們幾乎不可能指望只要我們堆積了那麼多元素, 這個現象(相變)就一定會發生。
至於回到那個未來人工智能曲線發展展望的話題, 我們可以看到, 這些不確定的因素都會使得這條發展曲線變得不可確定。 然而有一點是肯定的, 就是正在有越來越多非常聰明的人, 開始迅速的進入到這個領域, 越來越多的投資也在進來。 這說明, AI已經是勢不可擋的稱爲人類歷史的增長極, 即使有一些不確定性, 它卻不可能再進入到一個停滯不前的低谷了, 我們也許不會一天兩天就接近終極算法, 但卻一定會在細分領域取得一個又一個突破。無論是視覺, 自然語言, 還是運動控制。
能否走向通用人工智能的確是人工智能未來發展最大的變數, 或許, 我們真正的沉下心來去和大腦取經還是可以或多或少的幫助我們。 因爲本質上, 我們在人工智能的研究上所作的, 依然是在模擬人類大腦的奧祕。 我們越接近人類智慧的終極算法, 就越能得到更好的人工智能算法。