本文解析來源:
https://blog.csdn.net/longxinchen_ml/article/details/86533005
原英文鏈接:
https://jalammar.github.io/illustrated-transformer/
正文:
Transformer由論文《Attention is All You Need》提出,現在是谷歌雲TPU推薦的參考模型。論文相關的Tensorflow的代碼可以從GitHub獲取,其作爲Tensor2Tensor包的一部分。哈佛的NLP團隊也實現了一個基於PyTorch的版本,並註釋該論文。
在本文中,我們將試圖把模型簡化一點,並逐一介紹裏面的核心概念,希望讓普通讀者也能輕易理解。
Attention is All You Need:
https://arxiv.org/abs/1706.03762
從宏觀的視角開始:
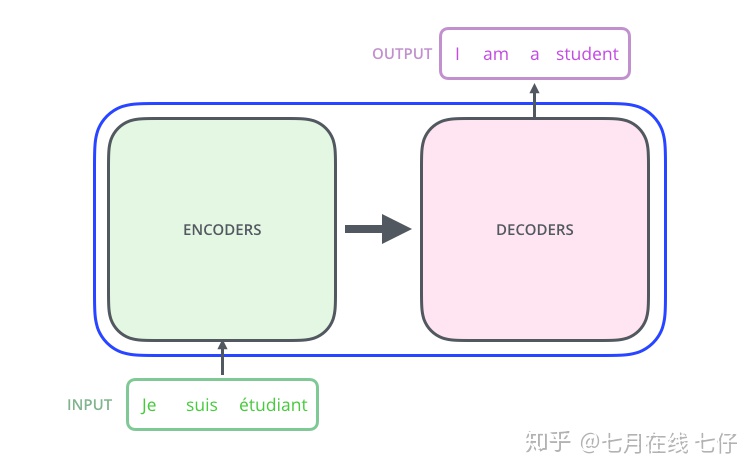
首先將這個模型看成是一個黑箱操作。在機器翻譯中,就是輸入一種語言,輸出另一種語言。

那麼拆開這個黑箱,我們可以看到它是由編碼組件、解碼組件和它們之間的連接組成。

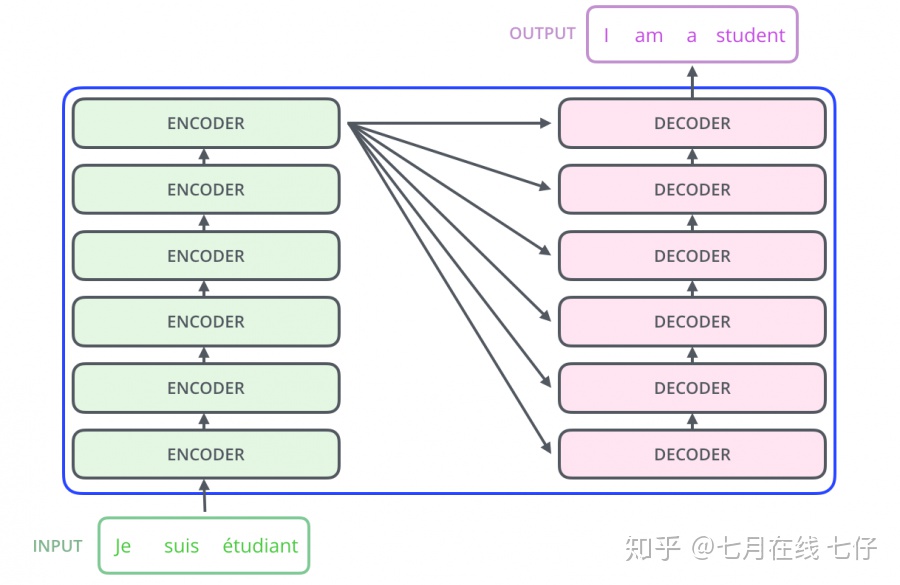
編碼組件部分由一堆編碼器(encoder)構成(論文中是將6個編碼器疊在一起——數字6沒有什麼神奇之處,你也可以嘗試其他數字)。
解碼組件部分也是由相同數量(與編碼器對應)的解碼器(decoder)組成的。
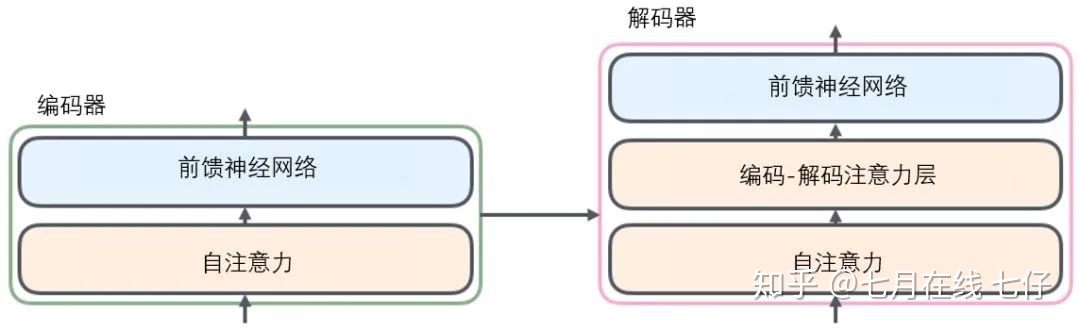
所有的編碼器在結構上都是相同的,但它們沒有共享參數。每個解碼器都可以分解成兩個子層。
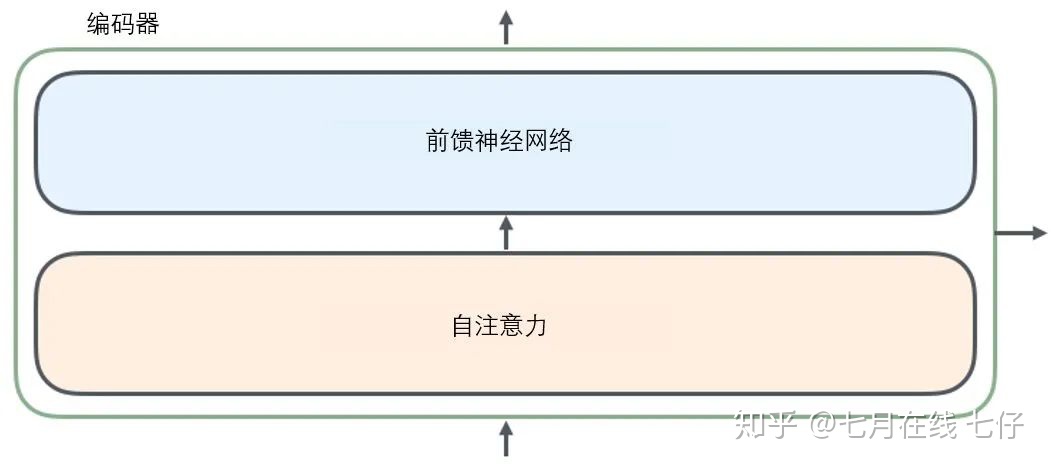
從編碼器輸入的句子首先會經過一個自注意力(self-attention)層,這層幫助編碼器在對每個單詞編碼時關注輸入句子的其他單詞。我們將在稍後的文章中更深入地研究自注意力。
自注意力層的輸出會傳遞到前饋(feed-forward)神經網絡中。每個位置的單詞對應的前饋神經網絡都完全一樣(譯註:另一種解讀就是一層窗口爲一個單詞的一維卷積神經網絡)。
解碼器中也有編碼器的自注意力(self-attention)層和前饋(feed-forward)層。除此之外,這兩個層之間還有一個注意力層,用來關注輸入句子的相關部分(和seq2seq模型的注意力作用相似)。
將張量引入圖景:
我們已經瞭解了模型的主要部分,接下來我們看一下各種向量或張量(譯註:張量概念是矢量概念的推廣,可以簡單理解矢量是一階張量、矩陣是二階張量。)是怎樣在模型的不同部分中,將輸入轉化爲輸出的。
像大部分NLP應用一樣,我們首先將每個輸入單詞通過詞嵌入算法轉換爲詞向量。


每個單詞都被嵌入爲512維的向量,我們用這些簡單的方框來表示這些向量。
詞嵌入過程只發生在最底層的編碼器中。所有的編碼器都有一個相同的特點,即它們接收一個向量列表,列表中的每個向量大小爲512維。在底層(最開始)編碼器中它就是詞向量,但是在其他編碼器中,它就是下一層編碼器的輸出(也是一個向量列表)。向量列表大小是我們可以設置的超參數——一般是我們訓練集中最長句子的長度。
將輸入序列進行詞嵌入之後,每個單詞都會流經編碼器中的兩個子層。

接下來我們看看Transformer的一個核心特性,在這裏輸入序列中每個位置的單詞都有自己獨特的路徑流入編碼器。在自注意力層中,這些路徑之間存在依賴關係。而前饋(feed-forward)層沒有這些依賴關係。因此在前饋(feed-forward)層時可以並行執行各種路徑。
然後我們將以一個更短的句子爲例,看看編碼器的每個子層中發生了什麼。
現在我們開始「編碼」:
如上述已經提到的,一個編碼器接收向量列表作爲輸入,接着將向量列表中的向量傳遞到自注意力層進行處理,然後傳遞到前饋神經網絡層中,將輸出結果傳遞到下一個編碼器中。

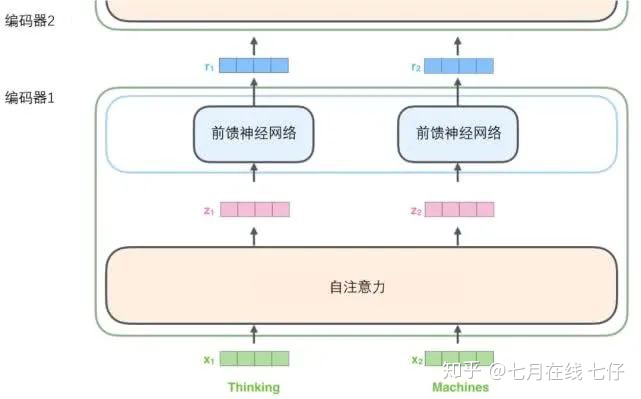
輸入序列的每個單詞都經過自編碼過程。然後,他們各自通過前向傳播神經網絡——完全相同的網絡,而每個向量都分別通過它。
從宏觀視角看自注意力機制:
不要被我用自注意力這個詞弄迷糊了,好像每個人都應該熟悉這個概念。其實我之也沒有見過這個概念,直到讀到Attention is All You Need 這篇論文時才恍然大悟。讓我們精煉一下它的工作原理。
例如,下列句子是我們想要翻譯的輸入句子:
The animal didn’t cross the street because it was too tired
這個「it」在這個句子是指什麼呢?它指的是street還是這個animal呢?這對於人類來說是一個簡單的問題,但是對於算法則不是。
當模型處理這個單詞「it」的時候,自注意力機制會允許「it」與「animal」建立聯繫。
隨着模型處理輸入序列的每個單詞,自注意力會關注整個輸入序列的所有單詞,幫助模型對本單詞更好地進行編碼。
如果你熟悉RNN(循環神經網絡),回憶一下它是如何維持隱藏層的。RNN會將它已經處理過的前面的所有單詞/向量的表示與它正在處理的當前單詞/向量結合起來。而自注意力機制會將所有相關單詞的理解融入到我們正在處理的單詞中。

當我們在編碼器#5(棧中最上層編碼器)中編碼「it」這個單詞的時,注意力機制的部分會去關注「The Animal」,將它的表示的一部分編入「it」的編碼中。
請務必檢查Tensor2Tensor notebook ,在裏面你可以下載一個Transformer模型,並用交互式可視化的方式來檢驗。
從微觀視角看自注意力機制:
首先我們瞭解一下如何使用向量來計算自注意力,然後來看它實怎樣用矩陣來實現。
計算自注意力的第一步就是從每個編碼器的輸入向量(每個單詞的詞向量)中生成三個向量。也就是說對於每個單詞,我們創造一個查詢向量、一個鍵向量和一個值向量。這三個向量是通過詞嵌入與三個權重矩陣後相乘創建的。
可以發現這些新向量在維度上比詞嵌入向量更低。他們的維度是64,而詞嵌入和編碼器的輸入/輸出向量的維度是512. 但實際上不強求維度更小,這只是一種基於架構上的選擇,它可以使多頭注意力(multiheaded attention)的大部分計算保持不變。


X1與WQ權重矩陣相乘得到q1, 就是與這個單詞相關的查詢向量。最終使得輸入序列的每個單詞的創建一個查詢向量、一個鍵向量和一個值向量。
什麼是查詢向量、鍵向量和值向量向量?
它們都是有助於計算和理解注意力機制的抽象概念。請繼續閱讀下文的內容,你就會知道每個向量在計算注意力機制中到底扮演什麼樣的角色。
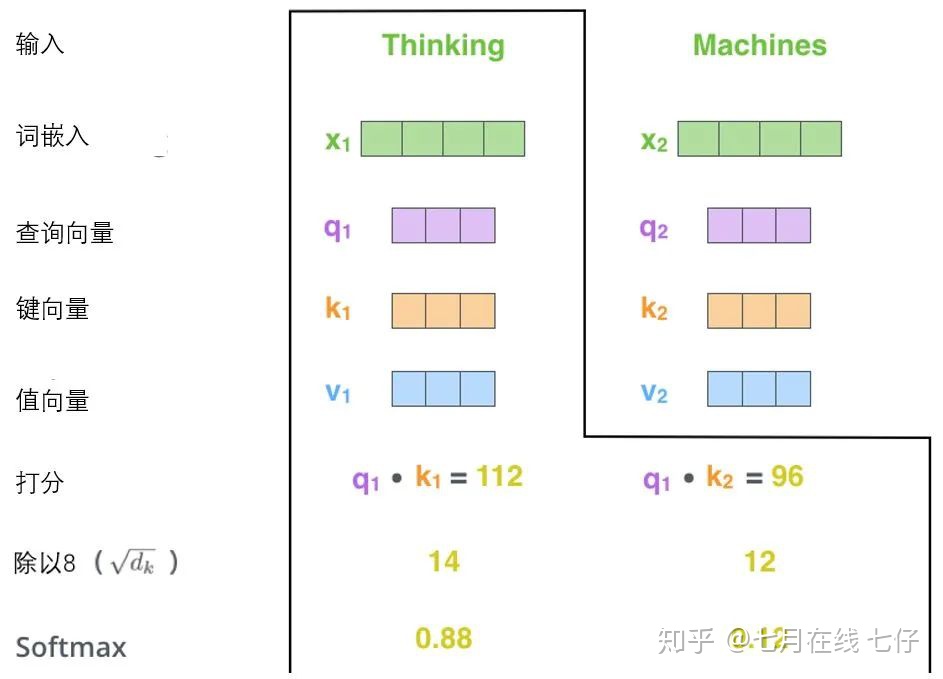
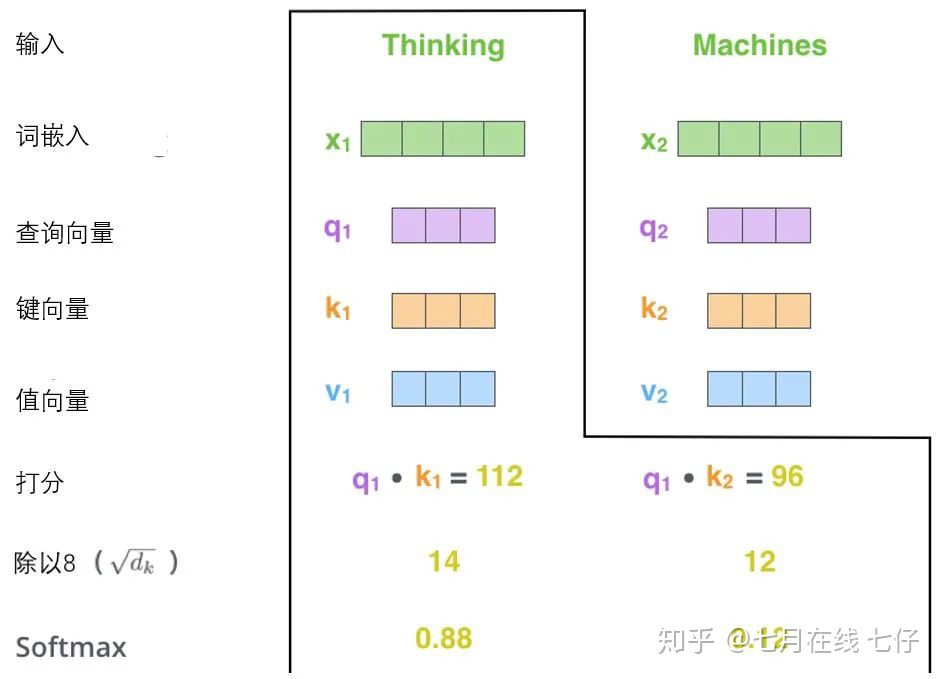
計算自注意力的第二步是計算得分。假設我們在爲這個例子中的第一個詞「Thinking」計算自注意力向量,我們需要拿輸入句子中的每個單詞對「Thinking」打分。這些分數決定了在編碼單詞「Thinking」的過程中有多重視句子的其它部分。
這些分數是通過打分單詞(所有輸入句子的單詞)的鍵向量與「Thinking」的查詢向量相點積來計算的。所以如果我們是處理位置最靠前的詞的自注意力的話,第一個分數是q1和k1的點積,第二個分數是q1和k2的點積。

第三步和第四步是將分數除以8(8是論文中使用的鍵向量的維數64的平方根,這會讓梯度更穩定。這裏也可以使用其它值,8只是默認值),然後通過softmax傳遞結果。
softmax的作用是使所有單詞的分數歸一化,得到的分數都是正值且和爲1。
這個softmax分數決定了每個單詞對編碼當下位置(「Thinking」)的貢獻。顯然,已經在這個位置上的單詞將獲得最高的softmax分數,但有時關注另一個與當前單詞相關的單詞也會有幫助。
第五步是將每個值向量乘以softmax分數(這是爲了準備之後將它們求和)。這裏的直覺是希望關注語義上相關的單詞,並弱化不相關的單詞(例如,讓它們乘以0.001這樣的小數)。
第六步是對加權值向量求和(譯註:自注意力的另一種解釋就是在編碼某個單詞時,就是將所有單詞的表示(值向量)進行加權求和,而權重是通過該詞的表示(鍵向量)與被編碼詞表示(查詢向量)的點積並通過softmax得到。),然後即得到自注意力層在該位置的輸出(在我們的例子中是對於第一個單詞)。
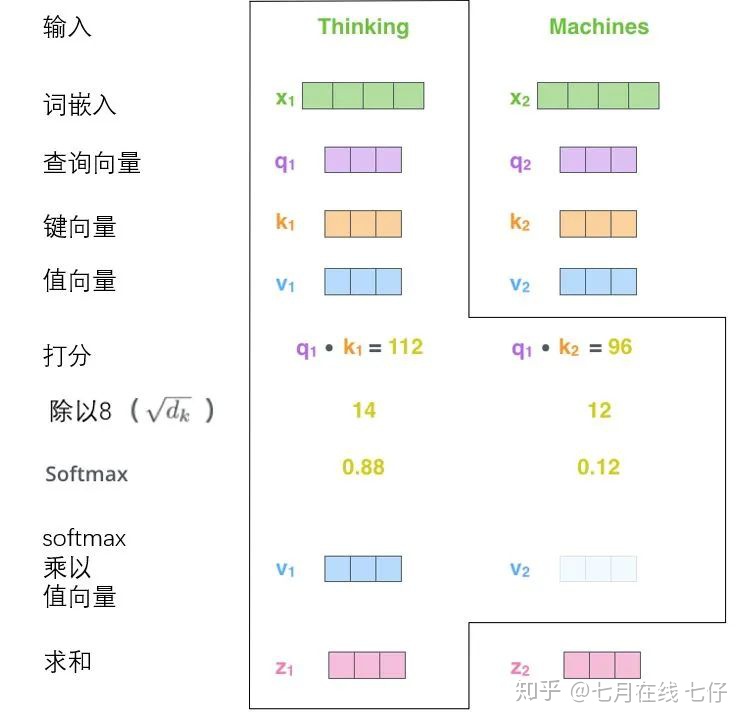
這樣自注意力的計算就完成了。得到的向量就可以傳給前饋神經網絡。然而實際中,這些計算是以矩陣形式完成的,以便算得更快。那我們接下來就看看如何用矩陣實現的。
通過矩陣運算實現自注意力機制:
第一步是計算查詢矩陣、鍵矩陣和值矩陣。爲此,我們將將輸入句子的詞嵌入裝進矩陣X中,將其乘以我們訓練的權重矩陣(WQ,WK,WV)。

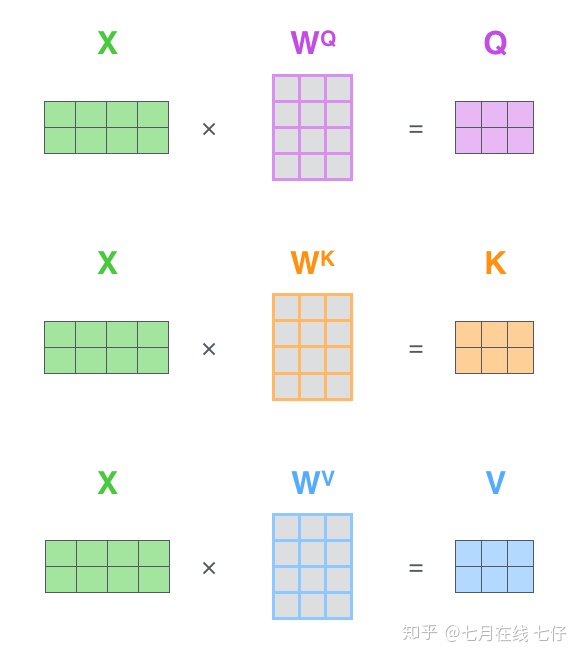
x矩陣中的每一行對應於輸入句子中的一個單詞。我們再次看到詞嵌入向量 (512,或圖中的4個格子)和q/k/v向量(64,或圖中的3個格子)的大小差異。
最後,由於我們處理的是矩陣,我們可以將步驟2到步驟6合併爲一個公式來計算自注意力層的輸出。

自注意力的矩陣運算形式:
「大戰多頭怪」
通過增加一種叫做「多頭」注意力(「multi-headed」 attention)的機制,論文進一步完善了自注意力層,並在兩方面提高了注意力層的性能:
1.它擴展了模型專注於不同位置的能力。在上面的例子中,雖然每個編碼都在z1中有或多或少的體現,但是它可能被實際的單詞本身所支配。
如果我們翻譯一個句子,比如「The animal didn’t cross the street because it was too tired」,我們會想知道「it」指的是哪個詞,這時模型的「多頭」注意機制會起到作用。
2.它給出了注意力層的多個「表示子空間」(representation subspaces)。接下來我們將看到,對於「多頭」注意機制,我們有多個查詢/鍵/值權重矩陣集(Transformer使用八個注意力頭,因此我們對於每個編碼器/解碼器有八個矩陣集合)。
這些集合中的每一個都是隨機初始化的,在訓練之後,每個集合都被用來將輸入詞嵌入(或來自較低編碼器/解碼器的向量)投影到不同的表示子空間中。
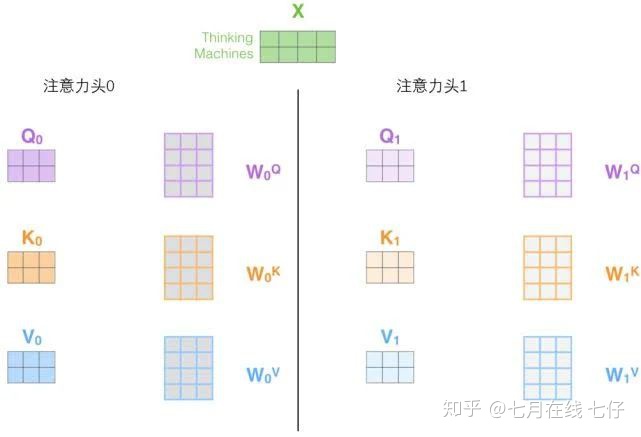
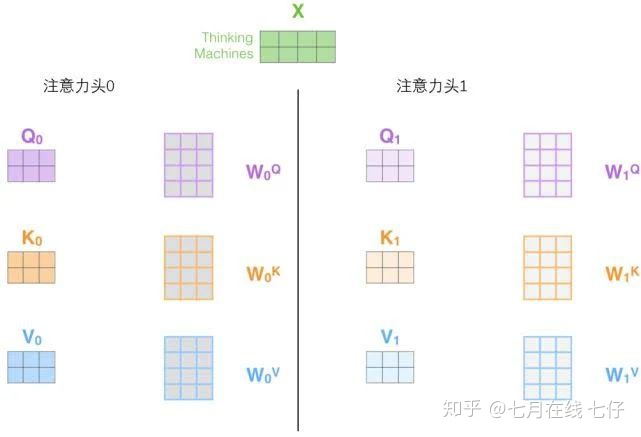
在「多頭」注意機制下,我們爲每個頭保持獨立的查詢/鍵/值權重矩陣,從而產生不同的查詢/鍵/值矩陣。和之前一樣,我們拿X乘以WQ/WK/WV矩陣來產生查詢/鍵/值矩陣。
如果我們做與上述相同的自注意力計算,只需八次不同的權重矩陣運算,我們就會得到八個不同的Z矩陣。

這給我們帶來了一點挑戰。前饋層不需要8個矩陣,它只需要一個矩陣(由每一個單詞的表示向量組成)。所以我們需要一種方法把這八個矩陣壓縮成一個矩陣。
那該怎麼做?其實可以直接把這些矩陣拼接在一起,然後用一個附加的權重矩陣WO與它們相乘。

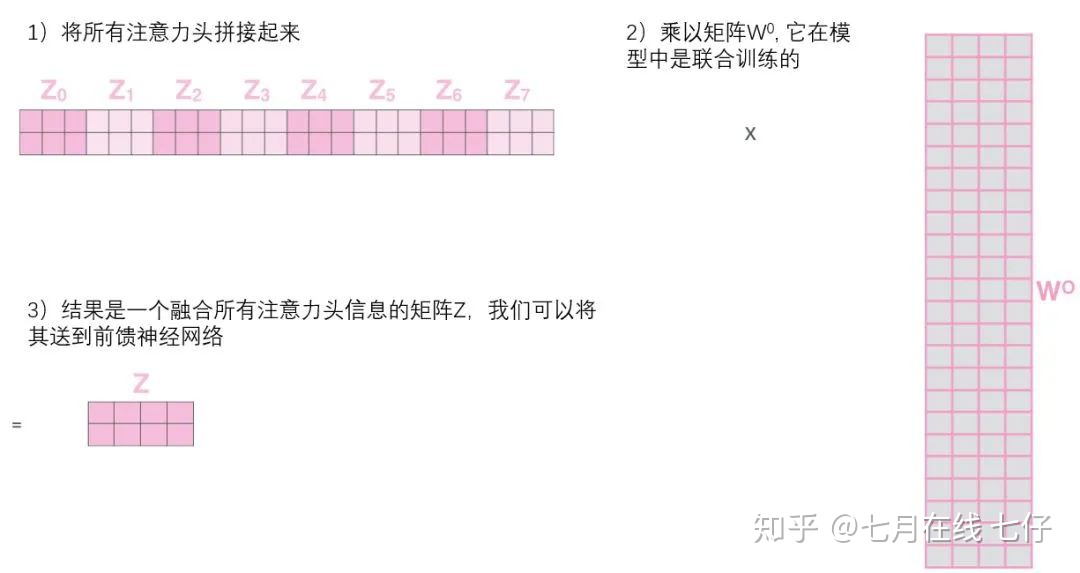
這幾乎就是多頭自注意力的全部。這確實有好多矩陣,我們試着把它們集中在一個圖片中,這樣可以一眼看清。

既然我們已經摸到了注意力機制的這麼多「頭」,那麼讓我們重溫之前的例子,看看我們在例句中編碼「it」一詞時,不同的注意力「頭」集中在哪裏:

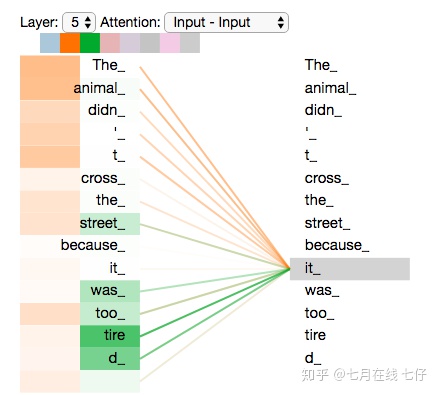
當我們編碼「it」一詞時,一個注意力頭集中在「animal」上,而另一個則集中在「tired」上,從某種意義上說,模型對「it」一詞的表達在某種程度上是「animal」和「tired」的代表。
然而,如果我們把所有的attention都加到圖示裏,事情就更難解釋了:

使用位置編碼表示序列的順序:
到目前爲止,我們對模型的描述缺少了一種理解輸入單詞順序的方法。
爲了解決這個問題,Transformer爲每個輸入的詞嵌入添加了一個向量。這些向量遵循模型學習到的特定模式,這有助於確定每個單詞的位置,或序列中不同單詞之間的距離。
這裏的直覺是,將位置向量添加到詞嵌入中使得它們在接下來的運算中,能夠更好地表達的詞與詞之間的距離。

爲了讓模型理解單詞的順序,我們添加了位置編碼向量,這些向量的值遵循特定的模式。
如果我們假設詞嵌入的維數爲4,則實際的位置編碼如下:
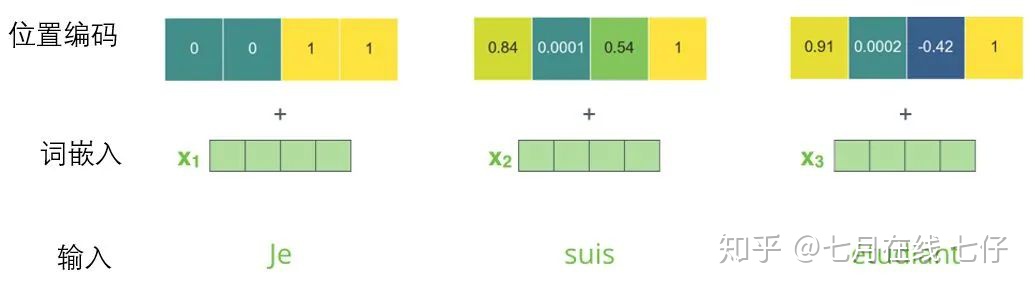
尺寸爲4的迷你詞嵌入位置編碼實例:
這個模式會是什麼樣子?
在下圖中,每一行對應一個詞向量的位置編碼,所以第一行對應着輸入序列的第一個詞。每行包含512個值,每個值介於1和-1之間。我們已經對它們進行了顏色編碼,所以圖案是可見的。
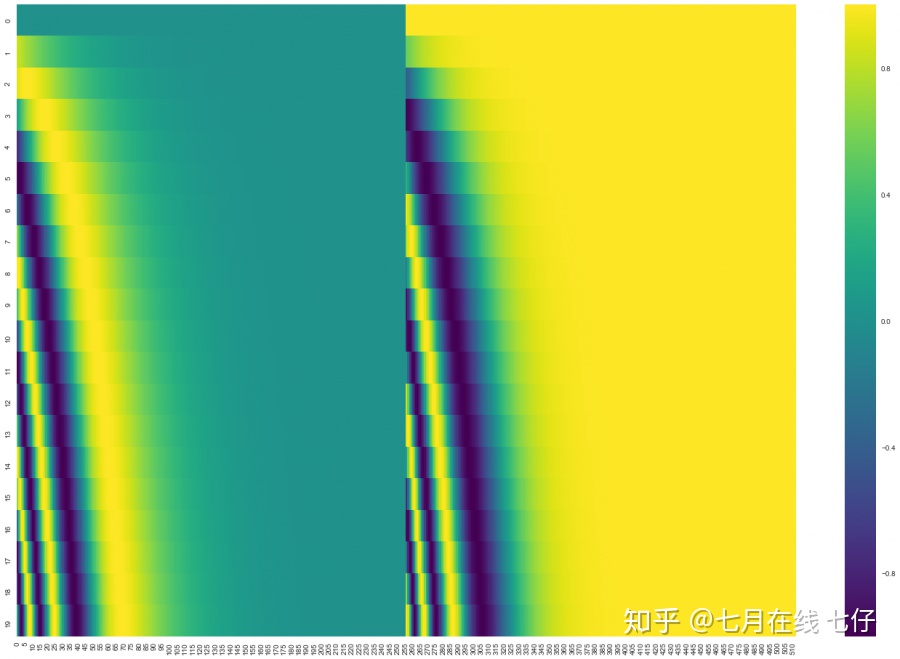

20字(行)的位置編碼實例,詞嵌入大小爲512(列)。你可以看到它從中間分裂成兩半。這是因爲左半部分的值由一個函數(使用正弦)生成,而右半部分由另一個函數(使用餘弦)生成。然後將它們拼在一起而得到每一個位置編碼向量。
原始論文裏描述了位置編碼的公式(第3.5節)。你可以在 get_timing_signal_1d()中看到生成位置編碼的代碼。這不是唯一可能的位置編碼方法。
然而,它的優點是能夠擴展到未知的序列長度(例如,當我們訓練出的模型需要翻譯遠比訓練集裏的句子更長的句子時)。
殘差模塊:
在繼續進行下去之前,我們需要提到一個編碼器架構中的細節:在每個編碼器中的每個子層(自注意力、前饋網絡)的周圍都有一個殘差連接,並且都跟隨着一個「層-歸一化」步驟。
層-歸一化步驟:
https://arxiv.org/abs/1607.06450
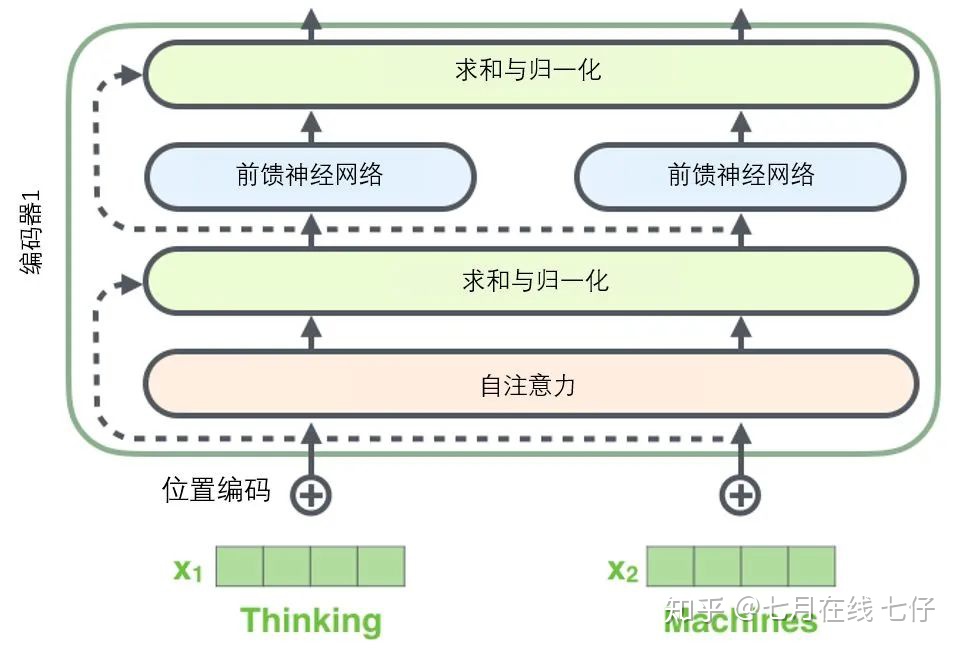
如果我們去可視化這些向量以及這個和自注意力相關聯的層-歸一化操作,那麼看起來就像下面這張圖描述一樣:


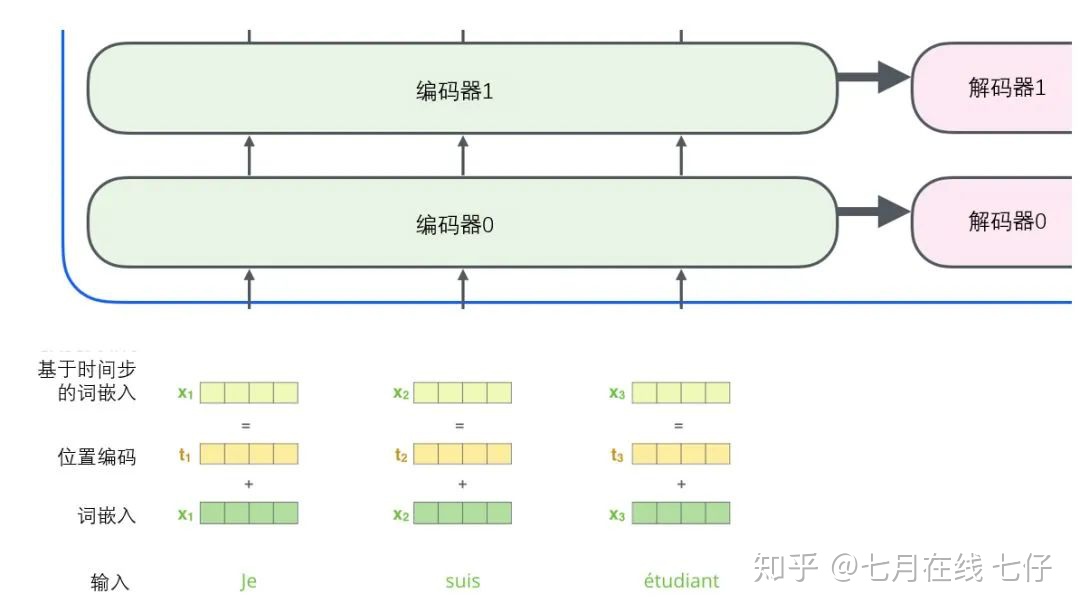
解碼器的子層也是這樣樣的。如果我們想象一個2 層編碼-解碼結構的transformer,它看起來會像下面這張圖一樣:
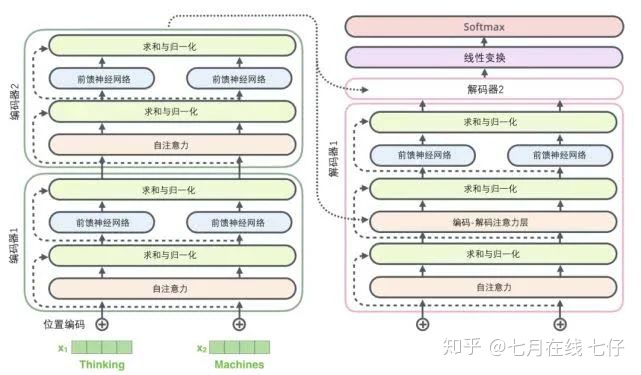
解碼組件:
既然我們已經談到了大部分編碼器的概念,那麼我們基本上也就知道解碼器是如何工作的了。但最好還是看看解碼器的細節。
編碼器通過處理輸入序列開啓工作。頂端編碼器的輸出之後會變轉化爲一個包含向量K(鍵向量)和V(值向量)的注意力向量集 。
這些向量將被每個解碼器用於自身的「編碼-解碼注意力層」,而這些層可以幫助解碼器關注輸入序列哪些位置合適:
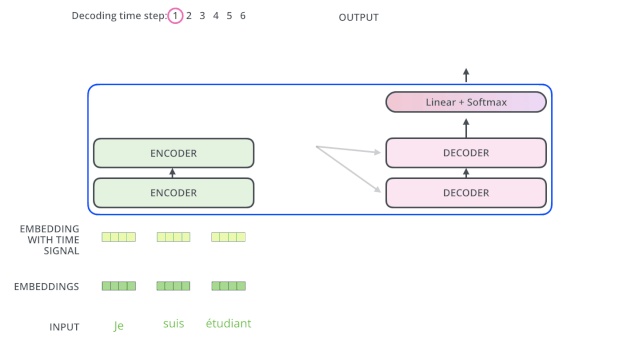

在完成編碼階段後,則開始解碼階段。解碼階段的每個步驟都會輸出一個輸出序列(在這個例子裏,是英語翻譯的句子)的元素。
接下來的步驟重複了這個過程,直到到達一個特殊的終止符號,它表示transformer的解碼器已經完成了它的輸出。每個步驟的輸出在下一個時間步被提供給底端解碼器,並且就像編碼器之前做的那樣,這些解碼器會輸出它們的解碼結果 。
另外,就像我們對編碼器的輸入所做的那樣,我們會嵌入並添加位置編碼給那些解碼器,來表示每個單詞的位置。

而那些解碼器中的自注意力層表現的模式與編碼器不同:在解碼器中,自注意力層只被允許處理輸出序列中更靠前的那些位置。在softmax步驟前,它會把後面的位置給隱去(把它們設爲-inf)。
這個「編碼-解碼注意力層」工作方式基本就像多頭自注意力層一樣,只不過它是通過在它下面的層來創造查詢矩陣,並且從編碼器的輸出中取得鍵/值矩陣。
最終的線性變換和Softmax層:
解碼組件最後會輸出一個實數向量。我們如何把浮點數變成一個單詞?這便是線性變換層要做的工作,它之後就是Softmax層。
線性變換層是一個簡單的全連接神經網絡,它可以把解碼組件產生的向量投射到一個比它大得多的、被稱作對數機率(logits)的向量裏。
不妨假設我們的模型從訓練集中學習一萬個不同的英語單詞(我們模型的「輸出詞表」)。因此對數機率向量爲一萬個單元格長度的向量——每個單元格對應某一個單詞的分數。
接下來的Softmax 層便會把那些分數變成概率(都爲正數、上限1.0)。概率最高的單元格被選中,並且它對應的單詞被作爲這個時間步的輸出。

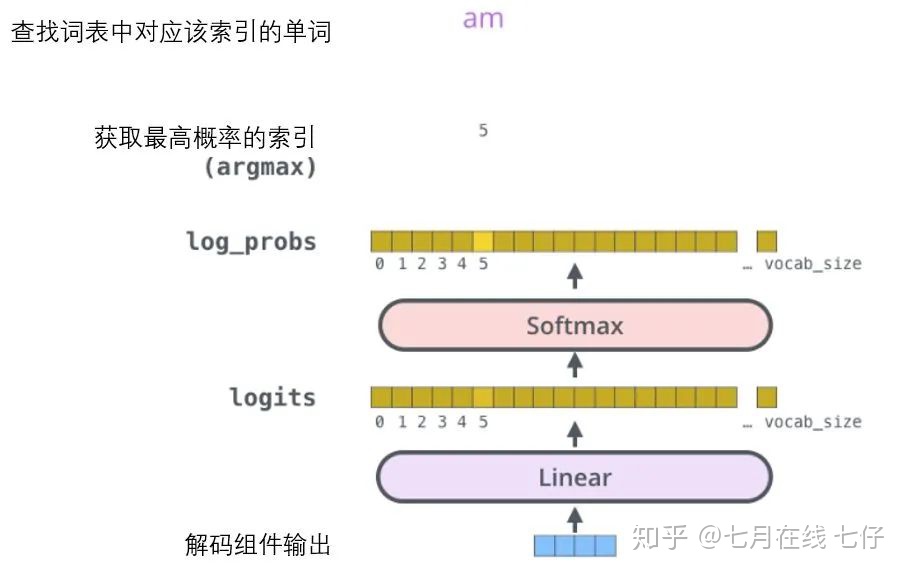
這張圖片從底部以解碼器組件產生的輸出向量開始。之後它會轉化出一個輸出單詞。
訓練部分總結:
既然我們已經過了一遍完整的transformer的前向傳播過程,那我們就可以直觀感受一下它的訓練過程。
在訓練過程中,一個未經訓練的模型會通過一個完全一樣的前向傳播。但因爲我們用有標記的訓練集來訓練它,所以我們可以用它的輸出去與真實的輸出做比較。
爲了把這個流程可視化,不妨假設我們的輸出詞彙僅僅包含六個單詞:「a」, 「am」, 「i」, 「thanks」, 「student」以及 「」(end of sentence的縮寫形式)。

我們模型的輸出詞表在我們訓練之前的預處理流程中就被設定好。
一旦我們定義了我們的輸出詞表,我們可以使用一個相同寬度的向量來表示我們詞彙表中的每一個單詞。這也被認爲是一個one-hot 編碼。所以,我們可以用下面這個向量來表示單詞「am」:

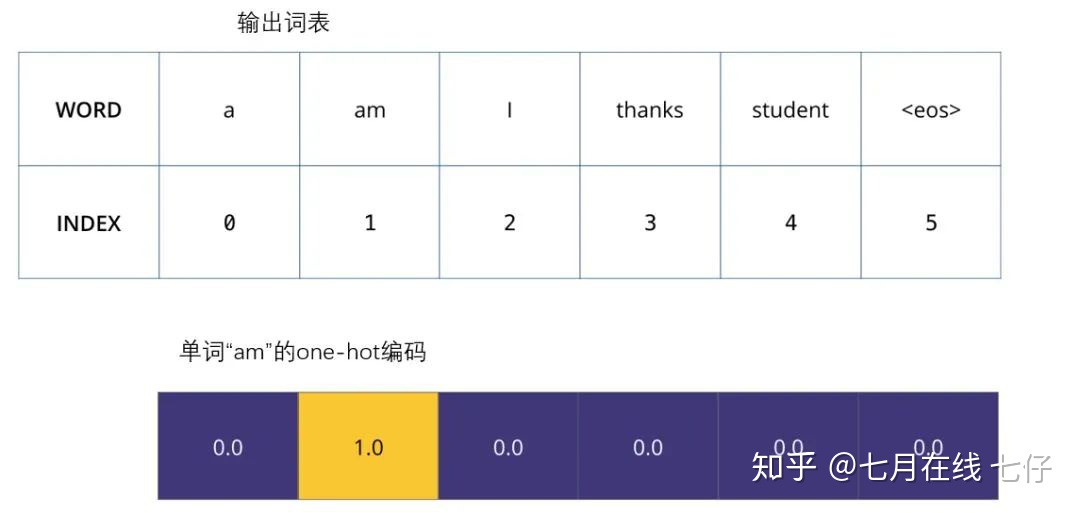
例子:對我們輸出詞表的one-hot 編碼
接下來我們討論模型的損失函數——這是我們用來在訓練過程中優化的標準。通過它可以訓練得到一個結果儘量準確的模型。
損失函數:
比如說我們正在訓練模型,現在是第一步,一個簡單的例子——把「merci」翻譯爲「thanks」。
這意味着我們想要一個表示單詞「thanks」概率分佈的輸出。但是因爲這個模型還沒被訓練好,所以不太可能現在就出現這個結果。
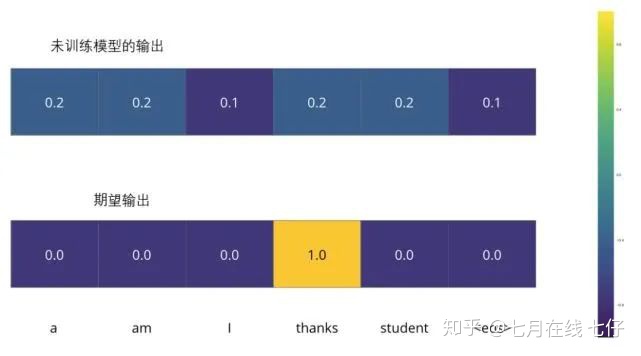
因爲模型的參數(權重)都被隨機的生成,(未經訓練的)模型產生的概率分佈在每個單元格/單詞裏都賦予了隨機的數值。我們可以用真實的輸出來比較它,然後用反向傳播算法來略微調整所有模型的權重,生成更接近結果的輸出。
你會如何比較兩個概率分佈呢?我們可以簡單地用其中一個減去另一個。更多細節請參考交叉熵和KL散度。
交叉熵:
https://colah.github.io/posts/2015-09-Visual-Information/
KL散度:
https://www.countbayesie.com/blog/2017/5/9/kullback-leibler-divergence-explained
但注意到這是一個過於簡化的例子。更現實的情況是處理一個句子。例如,輸入「je suis étudiant」並期望輸出是「i am a student」。那我們就希望我們的模型能夠成功地在這些情況下輸出概率分佈:
每個概率分佈被一個以詞表大小(我們的例子裏是6,但現實情況通常是3000或10000)爲寬度的向量所代表。
第一個概率分佈在與「i」關聯的單元格有最高的概率
第二個概率分佈在與「am」關聯的單元格有最高的概率
以此類推,第五個輸出的分佈表示「」關聯的單元格有最高的概率。

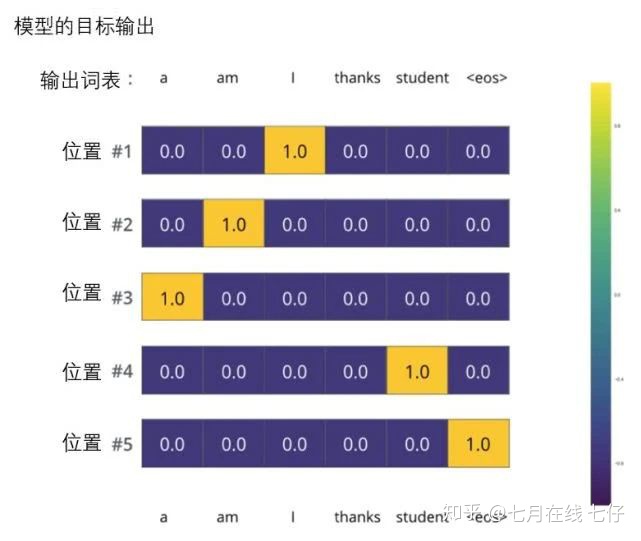
依據例子訓練模型得到的目標概率分佈:
在一個足夠大的數據集上充分訓練後,我們希望模型輸出的概率分佈看起來像這個樣子:
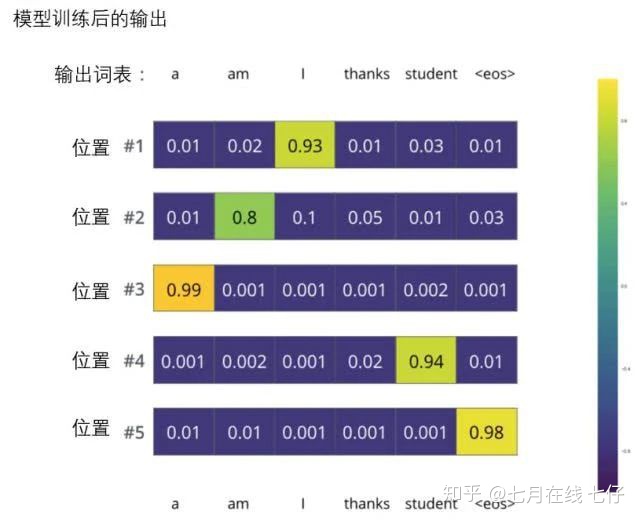
我們期望訓練過後,模型會輸出正確的翻譯。當然如果這段話完全來自訓練集,它並不是一個很好的評估指標(參考:交叉驗證,鏈接https://www.youtube.com/watch?v=TIgfjmp-4BA)。
注意到每個位置(詞)都得到了一點概率,即使它不太可能成爲那個時間步的輸出——這是softmax的一個很有用的性質,它可以幫助模型訓練。
因爲這個模型一次只產生一個輸出,不妨假設這個模型只選擇概率最高的單詞,並把剩下的詞拋棄。這是其中一種方法(叫貪心解碼)。
另一個完成這個任務的方法是留住概率最靠高的兩個單詞(例如I和a),那麼在下一步裏,跑模型兩次:其中一次假設第一個位置輸出是單詞「I」,而另一次假設第一個位置輸出是單詞「me」,並且無論哪個版本產生更少的誤差,都保留概率最高的兩個翻譯結果。
然後我們爲第二和第三個位置重複這一步驟。這個方法被稱作集束搜索(beam search)。在我們的例子中,集束寬度是2(因爲保留了2個集束的結果,如第一和第二個位置),並且最終也返回兩個集束的結果(top_beams也是2)。這些都是可以提前設定的參數。
再進一步,我希望通過上文已經讓你們瞭解到Transformer的主要概念了。如果你想在這個領域深入,我建議可以走以下幾步:閱讀Attention Is All You Need,Transformer博客和Tensor2Tensor announcement,以及看看Łukasz Kaiser的介紹,瞭解模型和細節。
Attention Is All You Need:https://arxiv.org/abs/1706.03762
Transformer博客:
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
Tensor2Tensor announcement:https://ai.googleblog.com/2017/06/accelerating-deep-learning-research.html
Łukasz Kaiser的介紹:
接下來可以研究的工作:
Depthwise Separable Convolutions for Neural Machine Translation
https://arxiv.org/abs/1706.03059
One Model To Learn Them All
https://arxiv.org/abs/1706.05137
Discrete Autoencoders for Sequence Models
https://arxiv.org/abs/1801.09797
Generating Wikipedia by Summarizing Long Sequences
https://arxiv.org/abs/1801.10198
Image Transformer
https://arxiv.org/abs/1802.05751
Training Tips for the Transformer Model
https://arxiv.org/abs/1804.00247
Self-Attention with Relative Position Representations
https://arxiv.org/abs/1803.02155
Fast Decoding in Sequence Models using Discrete Latent Variables
https://arxiv.org/abs/1803.03382
Adafactor: Adaptive Learning Rates with Sublinear Memory Cost
https://arxiv.org/abs/1804.04235