衆所周知,當今業界性能最強(SOTA)的深度學習模型都會佔用巨大的顯存空間,很多過去性能算得上強勁的 GPU,現在可能稍顯內存不足。在 lambda 最新的一篇顯卡橫向測評文章中,開發者們探討了哪些 GPU 可以再不出現內存錯誤的情況下訓練模型。當然,還有這些 GPU 的 AI 性能。
今年的 GPU 評測相比往年有了不小的變化:因爲
深度學習技術的突飛猛進,以前 12G 內存打天下的局面不復存在了。在 2020 年 2 月,你至少需要花費 2500 美元買上一塊英偉達最新款的 Titan RTX 纔可以勉強跑通業界性能最好的模型——那到今年年底會是什麼樣就無法想象了。或許我們應該把目光轉向雲端 GPU。
截止到 2020 年 2 月份,只有以下這幾種 GPU 可以訓練所有業內頂尖的語言和圖像模型:
RTX 8000:48GB 顯存,約 5500 美元
RTX 6000:24GB 顯存,約 4000 美元
Titan RTX:24GB 顯存,約 2500 美元
以下 GPU 可以訓練大多數 SOTA 模型,但不是所有模型都能:
超大規模的模型在這一級別的 GPU 上訓練,通常需要調小 Batch size,這很可能意味着更低的準確性。
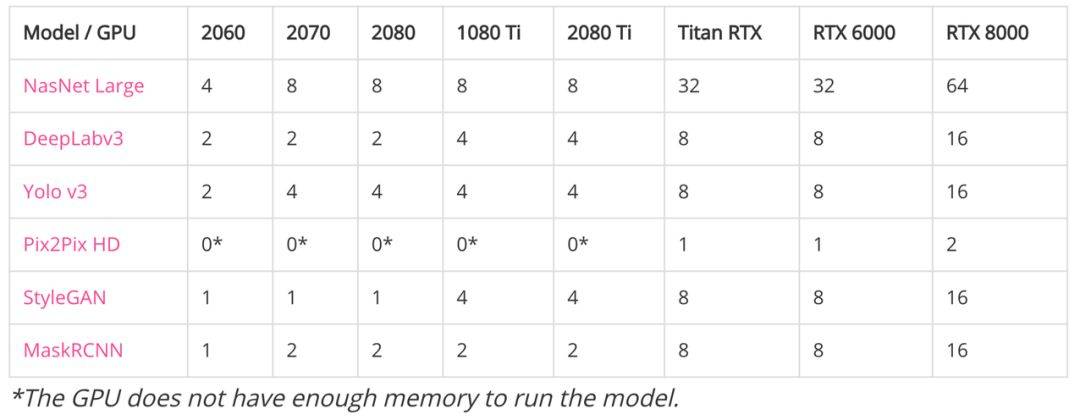
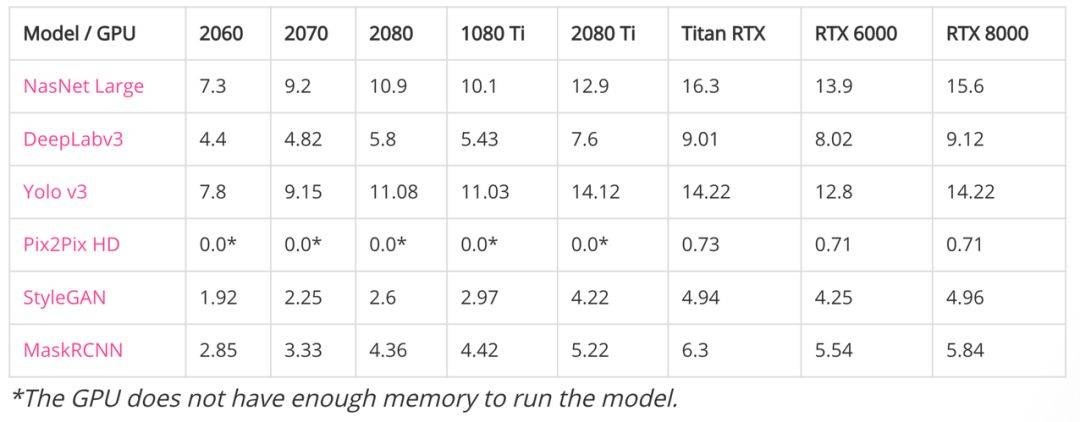
爲測試當前 GPU 性能,研究者們以 CV 和 NLP 兩個方向的頂尖模型進行了測試。處理圖像模型而言,基礎版 GPU 或 Ti 系的處理的效果都不是很好,且相互差異不大。
相較而言 RTX 的有明顯優勢且以最新版的 RTX8000 最爲突出,不難發現就目前爲止對於 GPU 能處理的批量大小基本都是以 2 的倍數來提升。相較於性能方面,總體還是以 RTX 係爲最優。
如下如果要訓練 Pix2Pix HD 模型,至少需要 24GB 的顯存,且批大小還只能是一張圖像。這主要因爲輸入圖像爲 2048x1024 的高清大圖,訓練所需的顯存與計算都非常大。
這些都是大模型,連計算最快的神經架構搜索模型 NasNet Large,之前也一直以算力需求大著稱。儘管訓練 NasNet Large 的數據集是 ImageNet,其圖像分辨率只有 331x331。
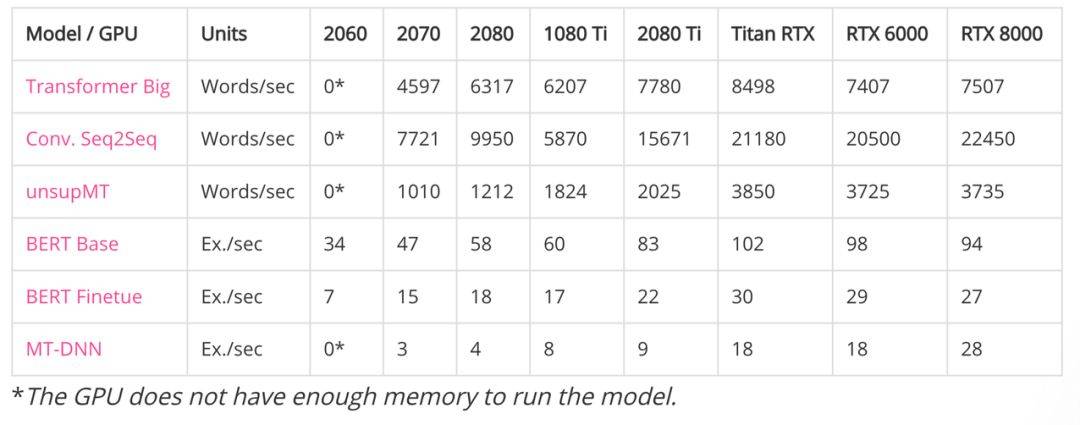
對於語言類模型而言,批量處理量方面依舊是 RTX 係爲最優。但單從性能角度而言,跟其他各款相比,Titan RTX 卻有着不錯的表現。
如下前面三個都是
機器翻譯模型,後面三個都是預訓練
語言模型。兩者的計數方式不太一樣,一條 Sequences 可能幾十到幾百個 Token。
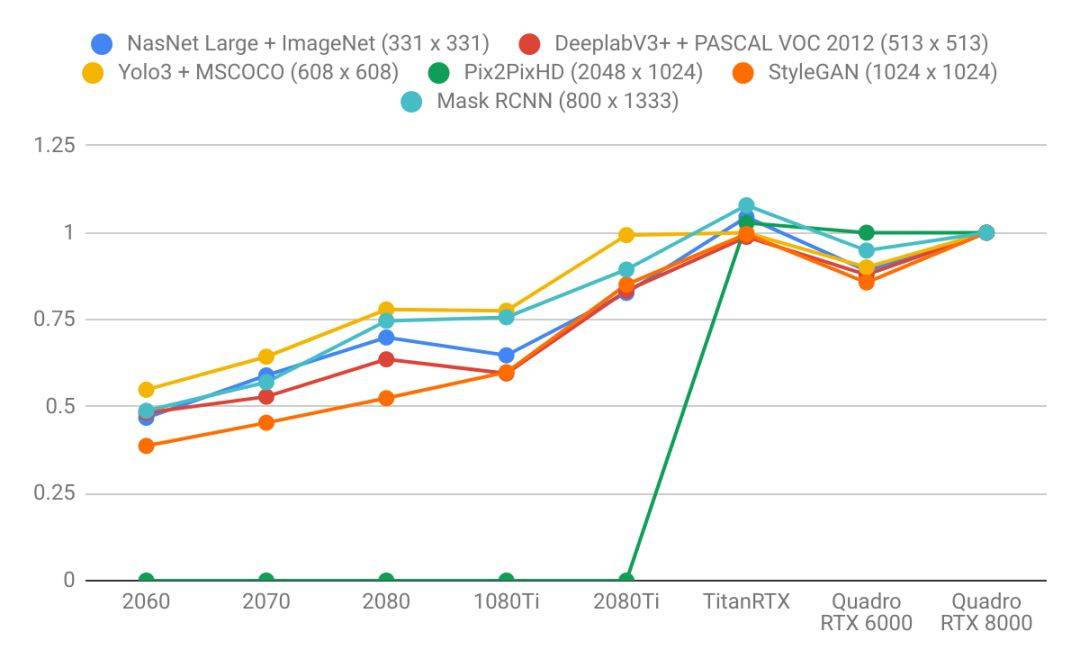
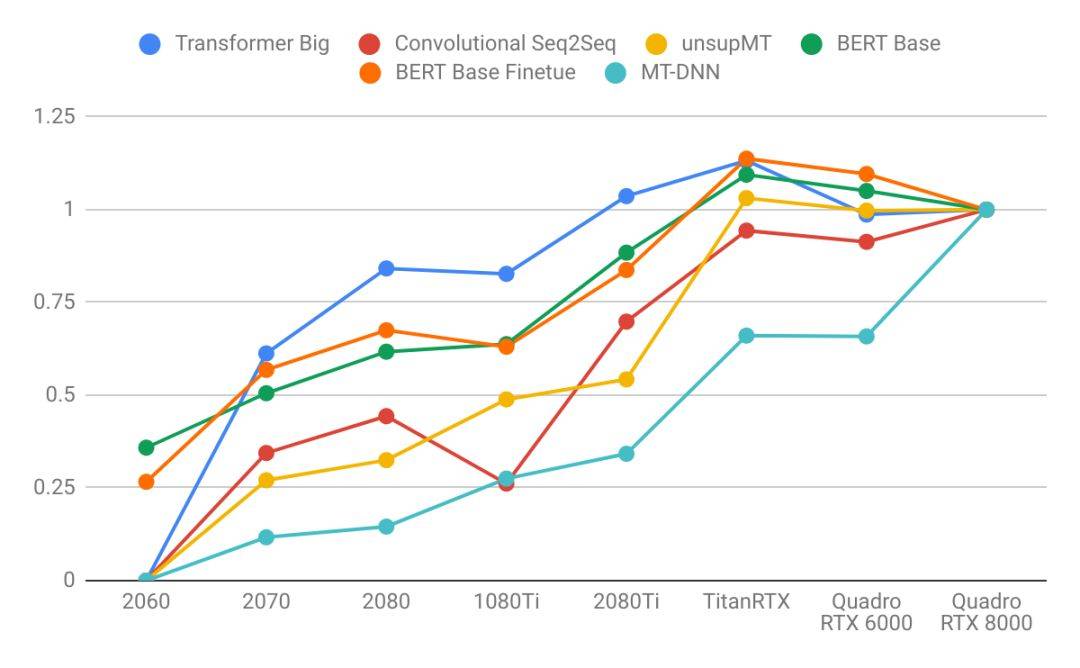
上面的性能表格可能不夠直觀,lambda 以 Quadro RTX 8000 爲
基準,將其設定爲「1」,其它 GPU 則針對該 GPU 計算出相對性能。如下所示爲不同模型在不同 GPU 上進行訓練的數據吞吐量:
對於所有測試結果,lambda 給出了測試模型與數據集。如說是 CV 中的各種任務,其採用了 ImageNet、MSCOCO 和 CityScape 等主流主數據集,模型也直接用原作者在 GitHub 上開源的代碼。如果是 NLP 中的各種任務,除了 WMT 英-德數據集,其它 GLUE
基準中的數據集也有采用。
從圖像識別、分割、檢測與生成,到
機器翻譯、
語言模型與 GLUE
基準,這些任務差不多覆蓋了 GPU 使用的絕大多數場景,這樣的測試也是比較合理了。
「舊模型」都跑不了,更別說什麼開發新模型了。看完上面的測試結果,是不是感覺「生活突然失去了夢想」?除了硬件之外,我們還可以從本次測評中觀察到近段時間
深度學習發展趨勢的變化:
語言模型比圖像模型更需要大容量顯存。注意語言模型那張圖的折線變化軌跡要比圖像模型那張更加陡峭。這表明語言模型受內存的限制更大,而圖像模型受算力的限制更大。
顯存越高,意味着性能越強大。因爲顯存越大,batch size 就越大,CUDA 核可以更加接近滿負荷工作。
更大的顯存可以按比例用更大的 Batch size,以此推之:24GB 顯存的 GPU 相比 8GB 顯存的 GPU 可以用上 3 倍的 batch。
對於長序列來說,語言模型的內存佔用增長情況不成比例,因爲注意力是序列長度的二次方。
RTX 2060(6GB):如果你想在業餘時間探索深度學習。
RTX 2070 或 2080(8GB):如果你想認真地研究深度學習,但用在 GPU 上的預算僅爲 600-800 美元。8G 的顯存可以適用於大部分主流深度學習模型。
RTX 2080Ti(11GB):如果你想要認真地研究深度學習,不過用在 GPU 上的預算可以到 1200 美元。RTX 2080Ti 在深度學習訓練上要比 RTX 2080 快大約 40%。
Titan RTX 和 Quadro RTX 6000(24GB):如果你經常研究 SOTA 模型,但沒有富裕到能買 RTX 8000 的話,可以選這兩款顯卡。
Quadro RTX 8000(48GB):恭喜你,你的投入正面向未來,你的研究甚至可能會成爲 2020 年的新 SOTA。
現在訓練個模型,GPU 顯存至少得上 8GB,對應的價格實在有點勸退。
其實,很多大企業都推出了面向研究和實驗的免費 GPU 計算資源,例如我們熟知的 Kaggle Kernel、Google Colab,它們能提供 K80 或 P100 這種非常不錯的 GPU 資源,其中 Colab 還能提供免費 TPU。國內其實也有免費 GPU,
百度的 AI Studio 能提供 Tesla V100 這種強勁算力。
這三者都有各自的優劣勢,Kaggle Kernel 與 Colab 都需要科學上網,且 Kaggle Kernel 只能提供最基礎的 K80 GPU,它的算力並不大。Colab 還會提供 T4 和 P100 GPU,算力確實已經足夠了,但 Colab 有時會中斷你的計算調用,這就需要特殊的技巧解決。
百度 AI Studio 也能提供非常強大的 V100 算力,且現在有免費算力卡計劃,每天運行環境都能獲得 12 小時的 GPU 使用時長。但問題在於,
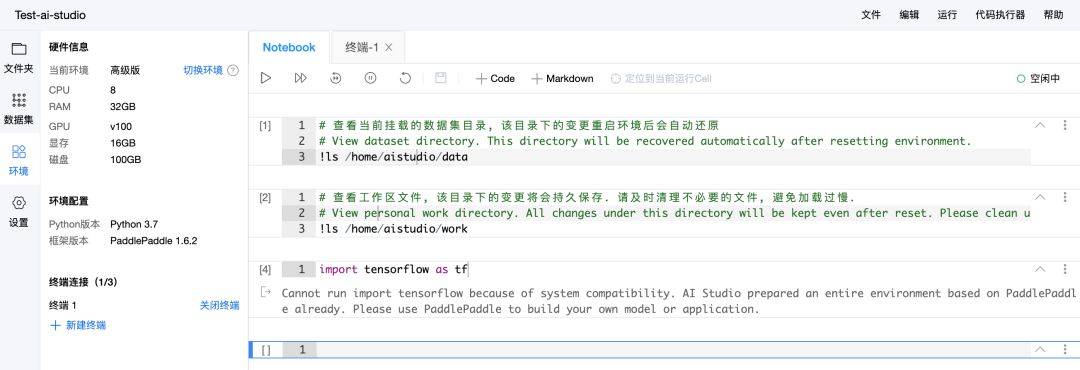
百度 AI Studio 只能調用 PaddlePaddle 框架,而不能自由選擇 TF 或 PyTorch。
很多開發者在使用 Colab 時,總會抱怨時不時的終止,抱怨每一次結束後所有包和文件都會刪除。但實際上,除了科學上網,其它很多問題都能解決。
首先最大一個問題是 Colab 會斷,但小編用過很多次,差不多每次只要保證頁面不關閉,連續運行十多個小時是沒問題的。按照我們的經驗,最好是在北京時間上午 9 點多開始運行,因爲這個時候北美剛過凌晨 12 點,連續運行時間更長一些。像 T4 或 P100 這樣的 GPU,連續運行 10 多個小時已經是很划算了,即使複雜的模型也能得到初步訓練。
那麼如果斷了呢?這就要考慮加載 Google Drive 了。Colab 非常好的一點是能與谷歌雲硬盤互動,也就是說等訓練一些 Epoch 後,可以將模型保存在雲端硬盤,這樣就能做到持久化訓練。每當 Colab 斷了時,我們可以從雲端硬盤讀取保存的模型,並繼續訓練。
如上兩行代碼可以將谷歌雲硬盤加載到遠程實例的「content/drive」目錄下,後面各種模型操作與數據集操作都可以在這個目錄下完成,即使 Colab 斷了連接,所有操作的內容也會保存在谷歌雲盤。
只要搞定上面兩個小技巧,Colab 的實用性就很強了。當然,如果讀者發現分配的 GPU 是 K80,你可以重新啓動幾次 Colab,即釋放內存和本地文件的重新啓動,每一次重啓都會重新分配 GPU 硬件,你可以「等到」P100。
此外,開發者還探索了更多的祕籍來保證 Colab 連接不會斷,例如跑一段模擬鼠標點擊的代碼,讓 Colab 斷了也能自己重連:
function ClickConnect(){console.log("Working"); document.querySelector("colab-toolbar-button#connect").click() }setInterval(ClickConnect,60000)
Colab 的 P100 已經非常不錯了,它有 16GB 的顯存,訓練大模型也沒多大問題,但 AI Studio 的 V100 更強大。AI Studio 即使不申請計算卡,每天登陸項目也能獲得 12 個 GPU 運算時,連續登陸還能有獎勵。
AI Studio 類似
Jupyter Notebook 的編輯界面也非常容易使用,且中斷運行環境後保存在磁盤裏面的文件並不會刪除,這也是 Colab 侷限的地方。但該平臺只能導入 PaddlePaddle 框架,所以對於熟悉 PaddlePaddle 框架的開發者而言,AI Studio 是最好的免費算力平臺。
我們嘗試了一下,在終端可以安裝其他框架,且進入 Python 自帶 IDE 後也能導入新安裝的框架。但是在 Notebook 界面,會顯示只能導入 PaddlePaddle。
最後,看了這麼多頂級 GPU 的性能對比,也瞭解了免費 GPU 計算資源的特性。所以,你是不是該宅在家搞一搞炫酷的
深度學習新模型與新能力?
參考內容:https://lambdalabs.com/blog/choosing-a-gpu-for-deep-learning/