近日,CMU 的研究人員在 arXiv 上放出了一份技術報告,介紹他們如何通過蒸餾(distillation)訓練一個強大的小模型。所提出方法使用相同模型結構和輸入圖片大小的前提下,在 ImageNet 上的性能遠超之前 state-of-the-art 的 FixRes 2.5% 以上,甚至超過了魔改結構的 ResNeSt 的結果。
這也是第一個能在不改變 ResNet-50 網絡結構和不使用外部訓練數據的前提下,將 ImageNet Top-1 精度提升到 80% 以上的工作,同時對訓練要求也不是很高,一臺 8 卡 TITAN Xp 就可以訓練了。

論文標題:
MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
論文鏈接:
https://arxiv.org/abs/2009.08453
代碼鏈接:
https://github.com/szq0214/MEAL-V2
在介紹這個工作之前,首先要簡單回顧一下它的最初版本 MEAL,其基本的也是核心的思想是將多個 teacher 網絡的知識通過蒸餾的方式壓縮進一個 student 裏面,同時它提出使用辨別器(discriminators)作爲正則模塊(regularization)防止 student 的輸出跟 teacher 過於相像,從而防止 student 過擬合到訓練集上。
MEAL 當時在 ImageNet 上就取得了 78.21% 的結果,超過原版 ResNet-50 1.7% 個點。MEAL V2 跟 MEAL 最大的區別在於監督信號的產生方式,如下圖:
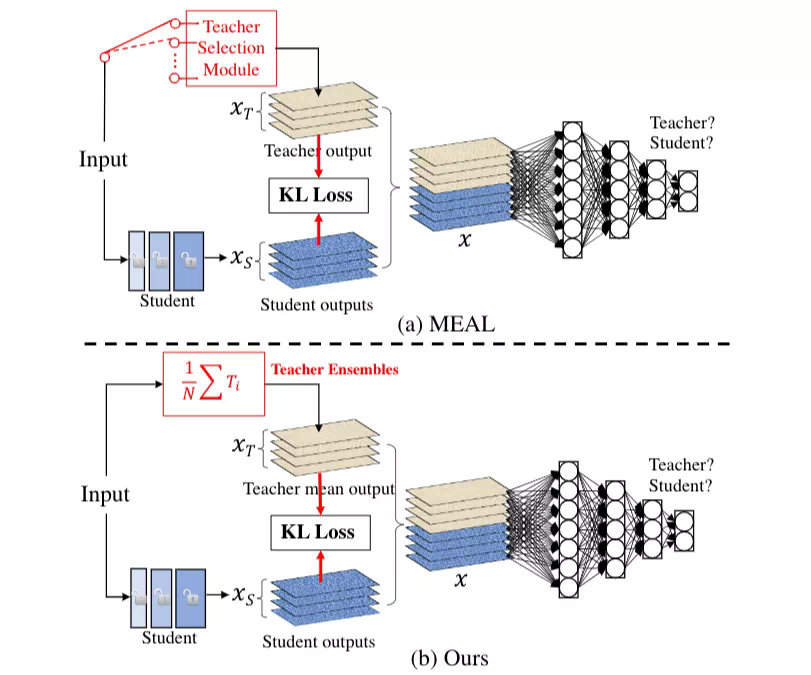
具體而言,MEAL 在每次訓練迭代的時候會通過一個 teacher 選擇模塊隨機選擇一個teacher產生監督信號,而在 V2 中,這個模塊被替換成所有 teacher 的集成,因此每次迭代 student 接收到的監督信號將會更加強大。同時,V2 簡化了 V1 裏面的中間層 loss,只保留最後一個 KL-loss 和辨別器,使得整個框架變得更加簡單,直觀和易用。
通常我們在訓練網絡的時候會用到很多技巧(tricks),但是在 MEAL V2 中,這些都是不需要的,作者羅列了他們使用到的和未使用到的一些訓練手段,如下表格所示:
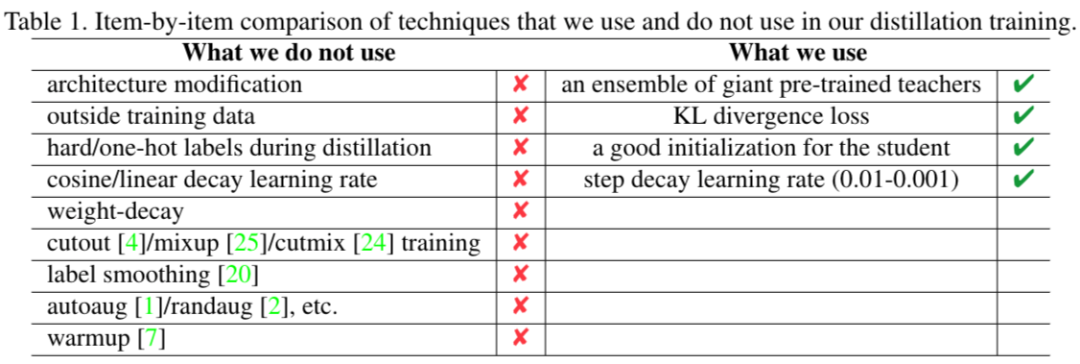
從上面表格可以看出來一些常用的數據增強和學習率調節他們都沒用到,說明這個框架非常魯棒和強大,同時也說明了這個框架其實還有很大的提升空間,比如作者進一步加入 CutMix 數據增強的方法來訓練,性能得到了進一步的提升。
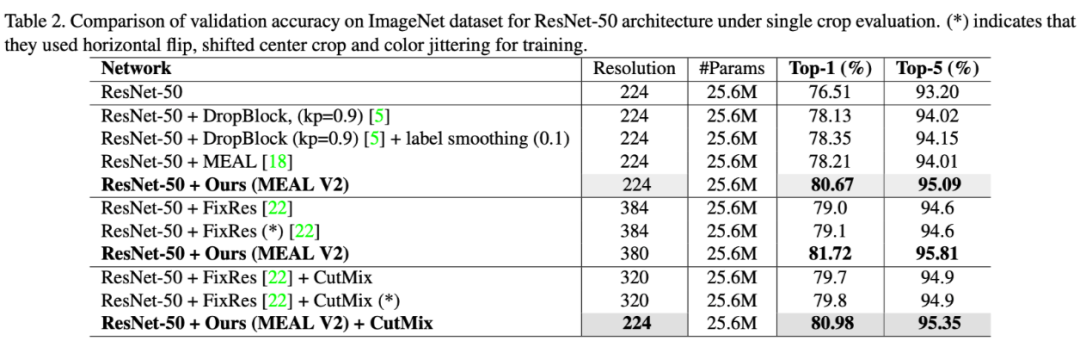
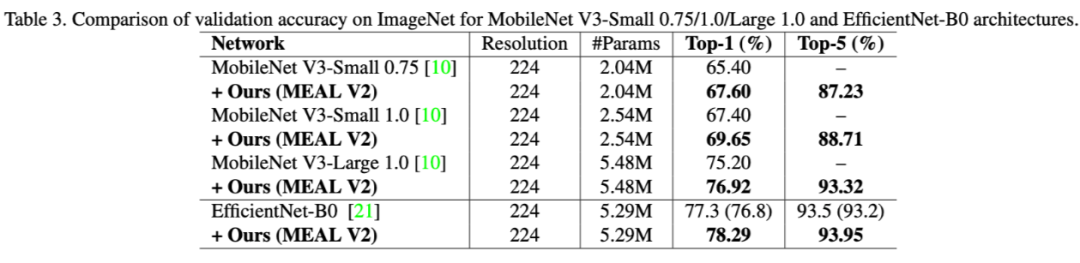
作者在論文中展示瞭如何提升不同網絡結構的性能,包括 MobileNet V3,EfficientNet-B0 等等,從表格 3 我們可以看到基本在這些網絡上都能有 2 個點以上的提升,所以 MEAL V2 整個框架其實可以看成是一個後增強的過程,即我們可以先設計和訓練一個自己的模型,然後放入 MEAL V2 的框架中進一步提升它的性能。
文章最後作者給出了一些相關的討論,包括爲什麼在做蒸餾的時候不需要使用 hard label,辨別器如何幫助優化過程等等,有興趣的同學可以去看他們的論文原文,這裏就不一一贅述了。
最後我們不得不感嘆一下,一個四五年前提出的 ResNet-50 網絡居然還能有如此巨大的潛力,性能可以被提升到超越最近很多新設計的網絡結構,作者還發現他們最強的 student 模型的性能其實跟使用的 teacher 已經非常接近了,這是一個非常神奇的地方,因爲 student 的網絡規模要比 teacher 小很多,但是它居然可以容納全部 teacher 的知識(knowledge),這也是一個值得繼續討論和研究的地方。
同時我們也不得不反思一下,是否一些新設計的網絡結構真的有那麼大的進步和貢獻,畢竟從 MEAL V2 的實驗結果來看,到目前爲止原生的 ResNet-50 的性能都還沒有完全飽和,這也促使我們更理性、客觀的去評價其他一些看上去性能很好的模型結構。
最後,Twitter 大佬 Dmytro Mishkin 也轉發了這篇文章,同時還有一些有意思的討論,關注他的人包括深度學習第四巨頭 Andrew Ng,英偉達 AI 和機器學習負責人,同時也是加州理工大學教授的 Anima Anandkumar,還有 timm 庫的作者 Ross Wightman 等等。

同時上面還有一些比較有意思的評論,比如有個 Twitter 網友就說 「I wish I had an ensemble of giant pre-trained teachers like this model in high school.」 真是太有愛了。