ParaDnn 能夠爲全連接(FC)、卷積(CNN)和循環(RNN)
神經網絡生成端到端的模型。研究者使用 6 個實際模型對谷歌的雲 TPU v2/v3、英偉達的 V100 GPU、以及
英特爾的 Skylake CPU 平臺進行了
基準測試。他們深入研究了 TPU 的架構,揭示了它的瓶頸,並重點介紹了能夠用於未來專業系統設計的寶貴經驗。他們還提供了平臺的全面對比,發現每個平臺對某些類型的模型都有自己獨特的優勢。最後,他們量化了專用的軟件堆棧對 TPU 和 GPU 平臺提供的快速性能改進。
論文:Benchmarking TPU, GPU, and CPU Platforms for Deep Learning
論文鏈接:https://arxiv.org/pdf/1907.10701.pdf
TPU v2 發佈於 2017 年 5 月,它是一款定製的專用集成電路(ASIC)。每個 TPU v2 設備能夠在單板上提供 180 TFLOPS 的峯值算力。一年之後 TPU v3 發佈,它將峯值性能提高到了 420 TFLOPS。雲 TPU 於 2018 年 2 月開始提供學術訪問權限。這篇論文中使用的就是雲 TPU。
英偉達的 Tesla V100 Tensor Core 是一塊具有 Volta 架構的 GPU,於 2017 年發佈。
CPU 已經被證明在某些特定的用例中會更加適合訓練,因此它也是一個重要的平臺,應該被包含在比較內容中。
這項研究表明,沒有一個平臺在所有的場景中是最佳的。基於它們各自的特點,不同的平臺能夠爲不同的模型提供優勢。此外,由於深度學習模型的快速改進和變化,
基準測試也必須持續更新並經常進行。
最近的
基準測試似乎都侷限於任意的幾個 DNN 模型。只盯着著名的 ResNet50 和 Transformer 等模型可能會得到誤導性的結論。例如,Transformer 是一個大型的全連接模型,它在 TPU 上的訓練速度比在 GPU 上快了 3.5 倍;但是,關注這一個模型並不能揭示 TPU 在超過 4000 個節點的全連接網絡上出現的嚴重的內存帶寬瓶頸。這凸顯了爲某些模型去過度優化硬件和(或)編譯器的風險。
爲了對最先進的深度學習平臺進行
基準測試,這篇論文提出了一個用於訓練的深度學習模型集合。爲了支持廣泛和全面的
基準測試研究,研究者引入了 ParaDnn 這一參數化的深度學習
基準測試組件。ParaDnn 能夠無縫地生成數千個參數化的多層模型,這些模型由全連接(FC)模型、卷積
神經網絡(CNN)以及循環
神經網絡(RNN)組成。ParaDnn 允許對參數規模在近乎 6 個數量級的模型上進行系統
基準測試,這已經超越了現有的
基準測試的範圍。
研究者將這些參數化模型與 6 個現實模型結合起來,作爲廣泛模型範圍內的獨特點,以提供對硬件平臺的全面
基準測試。表 1 總結了本文中描述的十 14 個觀察結果和見解,這些觀察和見解可以爲未來的特定領域架構、系統和軟件設計提供啓發信息。
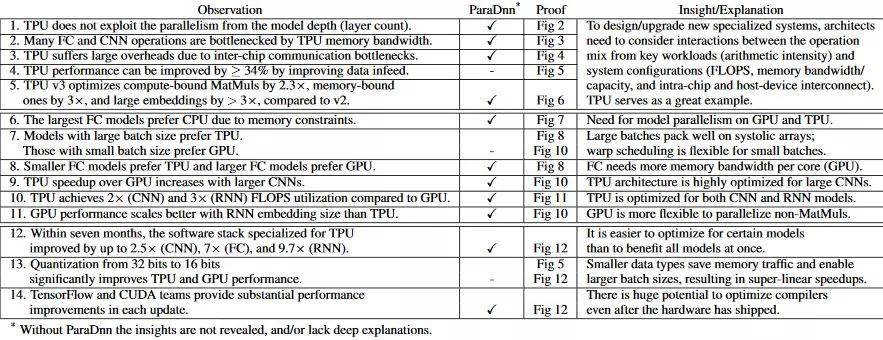
研究者特意標記了通過 ParaDnn 得到的見解。他們從論文第 4 部分開始對 TPU v2 和 v3 的架構進行深入探討,揭示了算力中的架構瓶頸、內存帶寬、多片負載以及設備-主機平衡(第 1 到 5 個觀察)。論文第五部分提供了 TPU 和 GPU 性能的全面比較,突出了這兩個平臺的重要區別(第 6 到第 11 個觀察)。最後的 3 個觀察在論文第六部分有詳細描述,探討了專用軟件堆棧和量化數據類型帶來的性能改進。
明確本研究的侷限性非常重要。這篇論文着重研究了目前的架構和系統設計中可以優化的可能性,因爲它們爲未來的設計提供了寶貴的經驗。優化的細節不屬於本文的研究範圍。例如,本文的分析只聚焦於訓練而不是推理。作者沒有研究多 GPU 平臺或 256 節點 TPU 系統的性能,二者可能會導致不同的結論。
深度學習(DL)最近的成功驅動了關於
基準測試組件的研究。現有的組件主要有兩種類型:一是像 MLPerf,、Fathom、BenchNN、以及 BenchIP 這種實際的
基準測試;二是 DeepBench、BenchIP 這類微
基準測試,但是它們都有一定的侷限。
這些組件僅包含今天已有的深度學習模型,隨着深度學習模型的快速發展,這些模型可能會過時。而且,它們沒有揭示深度學習模型屬性和硬件平臺性能之間的深刻見解,因爲
基準測試只是巨大的深度學習空間中的稀疏點而已。
ParaDnn 對這項研究現有的
基準測試組件做出了補充,它具有以上這些方法的優點,目標是提供「端到端」的、能夠涵蓋現有以及未來應用的模型,並且將模型參數化,以探索一個更大的深度
神經網絡屬性的設計空間。
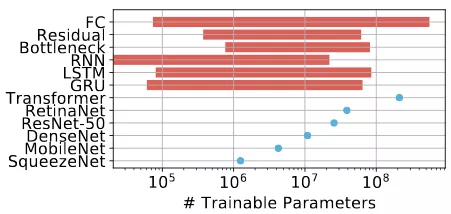
圖 1:這篇文章中所有負載的可訓練參數的數量。ParaDnn 中的模型參數範圍在 1 萬到接近十億之間,如圖所示,它要比實際模型的參數範圍更大,如圖中的點所示。
作者對硬件平臺的選擇反映了在論文提交時,雲平臺上廣泛可用的最新配置。模型的詳細指標在表 3 中。
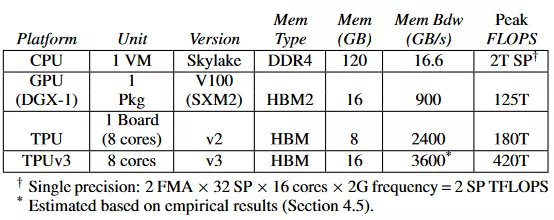
圖 2(a)–(c) 表明,這三種方法的 FLOPS 利用率是隨着 batch size 的增大而增大的。除此之外,全連接網絡的 FLOPS 利用率隨着每層節點數的增加而增大(圖 2(a));卷積
神經網絡的 FLOPS 利用率隨着濾波器的增加而增大,循環
神經網絡的 FLOPS 利用率隨着嵌入尺寸的增大而增大。圖 2(a)–(c) 中的 x 軸和 y 軸是圖 2(d)–(f) 中具有最大絕對值的超參數。
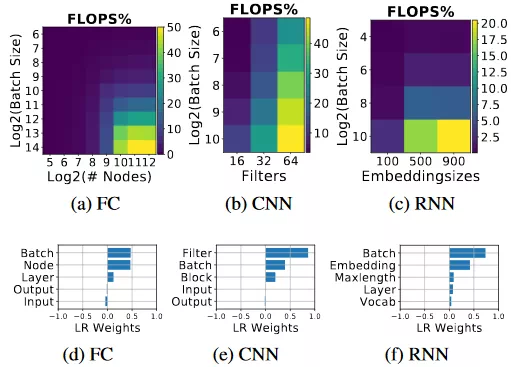 圖 2:FLOPS 的利用率及其與超參數的相關性。(a)–(c) 表示參數化模型的 FLOPS 利用率。(d)–(f) 使用線性迴歸權重量化了模型超參數對 FLOPS 利用率的影響。
圖 2:FLOPS 的利用率及其與超參數的相關性。(a)–(c) 表示參數化模型的 FLOPS 利用率。(d)–(f) 使用線性迴歸權重量化了模型超參數對 FLOPS 利用率的影響。
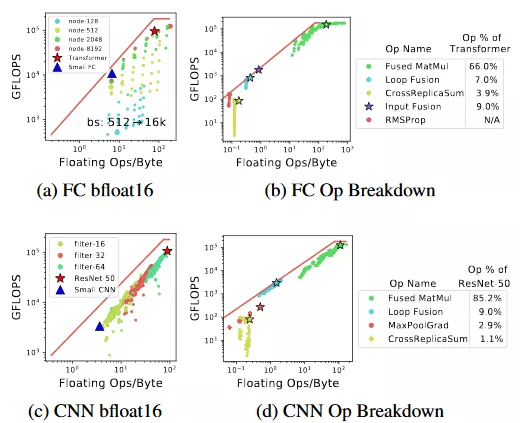
圖 3:全連接網絡和卷積神經網絡在 TPU 上的 Roofline。矩陣相乘(MatMul)運算的負載是計算密集型的。即使是 Transformer 和 ResNet-50 這樣的計算密集型模型也具有 10% 以上的內存限制運算。(a) 和 (c) 展示了參數化模型和實際模型的 roofline。(b) 和 (d) 展示了運算的分解。
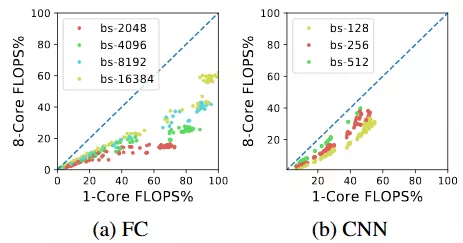
圖 4:多片系統中的通信開銷是不能忽略的,但是它會隨着 batch size 的增大而減小。
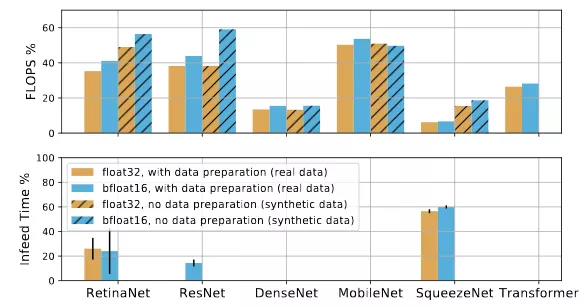
圖 5:FLOPS 利用率(頂部)和使用 float32 和 bfloat16 的實際模型在具有以及沒有數據準備情況下的喂料時間(設備等待數據的時間)(底部)。具有較大喂料時間百分比的模型(例如 RetinaNet 和 SqueezeNet)會受到數據喂入的限制。
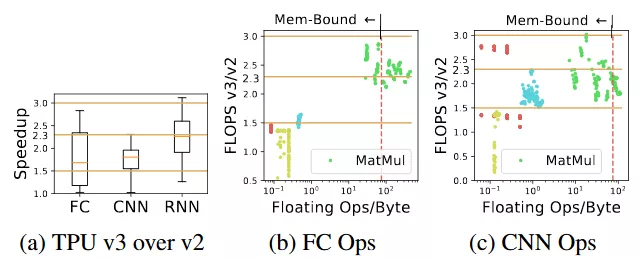
圖 6:(a) 是 TPU v3 在運行端到端模型時與 v2 相比的加速比。(b) 和 (c) 是全連接和卷積神經網絡的加速比。TPU v3 更大的內存支持兩倍的 batch size,所以如果它們具有更大的 batch size,內存受限的運算會具獲得三倍加速,如果沒有更大的 batch size,則是 1.5 倍的加速。在 v3 上計算受限的運算擁有 2.3 倍的加速。紅色的線 (75 Ops/Byte) 是 TPU v2 的 roofline 的拐點。
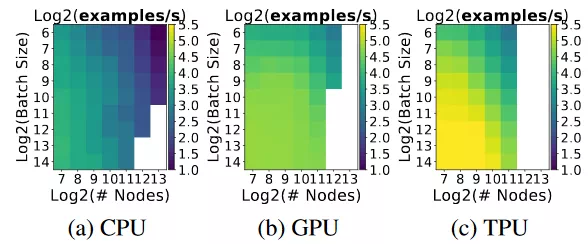
圖 7:具有固定層(64)的全連接模型的 Examples/second(樣本/秒)。Examples/second 隨着節點的增多而減小,隨着 batch size 的增大而增大。白色方塊表示模型遇到了內存不足的問題。CPU 平臺運行最大的模型,因爲它具有最大的內存。
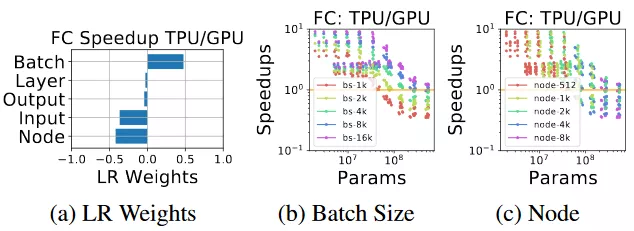
圖 8:具有大 batch size 的小型全連接模型更偏好 TPU,具有小 batch size 的大型模型更加偏好 GPU,這意味着收縮陣列對大型矩陣更好,在 GPU 上對小型矩陣做變換更加靈活。
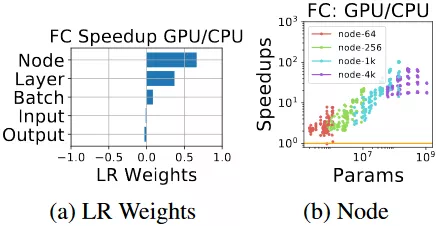
圖 9:相比於 CPU,具有大 batch size 的大型全連接模型更適合 GPU,因爲 CPU 的架構能夠更好地利用額外的並行。
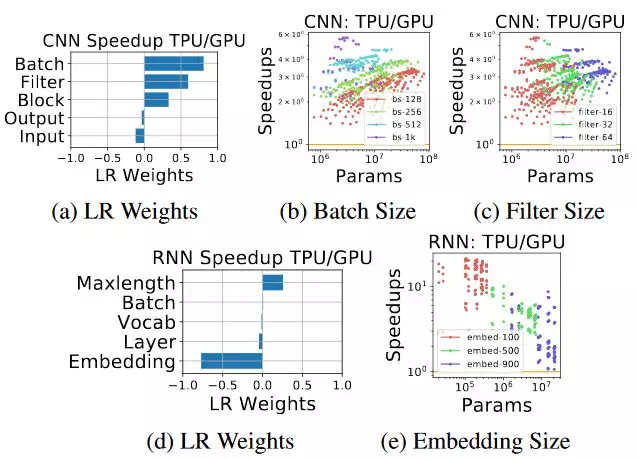
圖 10:(a)–(c):對大型卷積神經網絡而言,TPU 是比 GPU 更好的選擇,這意味着 TPU 是對卷積神經網絡做了高度優化的。(d)–(e):儘管 TPU 對 RNN 是更好的選擇,但是對於嵌入向量的計算,它並不像 GPU 一樣靈活。
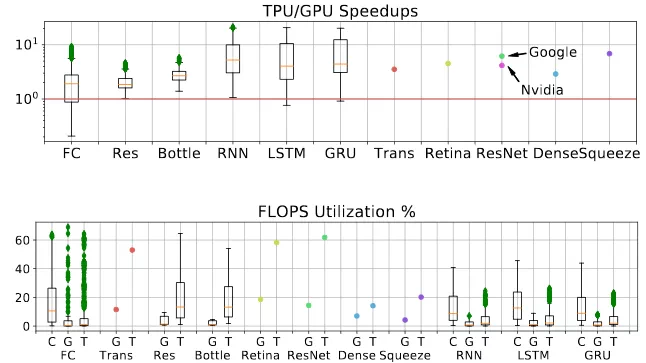
圖 11:(頂部)在所有的負載上 TPU 相對 GPU 的加速比。需要注意的是,實際負載在 TPU 上會使用比 GPU 上更大的 batch size。ResNet-50 的英偉達 GPU 版本來自於文獻 [9]。(底部)所有平臺的 FLOPS 利用率對比。
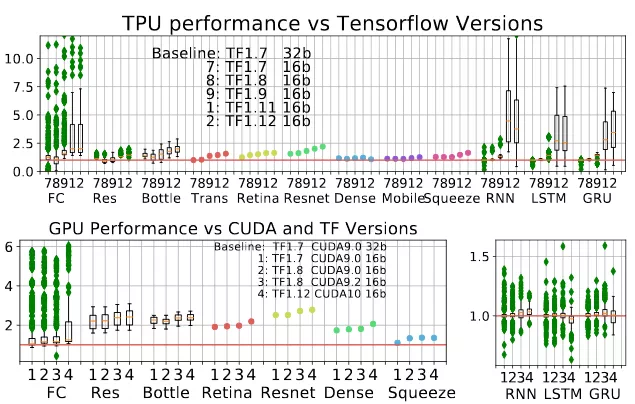
圖 12:(a)TPU 性能隨着 TensorFlow 版本更新發生的變化。所有的 ParaDnn 模型都有提升:Transformer, RetinaNet, 和 ResNet-50 提升穩定。(b)CUDA 和 TF 的不同版本上 GPU 的加速比。CUDA 9.2 對卷積神經網絡的提升要比其他 ParaDnn 模型更多,對 ResNet-50 的提升要比其他實際模型更多。CUDA 10 沒有提升 RNN 和 SqueezeNet。