大白在之前寫過《深入淺出Yolo系列之Yolov3&Yolov4核心基礎知識完整講解》
對Yolov4的相關基礎知識做了比較系統的梳理,但Yolov4後不久,又出現了Yolov5,雖然作者沒有放上和Yolov4的直接測試對比,但在COCO數據集的測試效果還是很可觀的。
很多人考慮到Yolov5的創新性不足,對算法是否能夠進化,稱得上Yolov5而議論紛紛。
但既然稱之爲Yolov5,也有很多非常不錯的地方值得我們學習。不過因爲Yolov5的網絡結構和Yolov3、Yolov4相比,不好可視化,導致很多同學看Yolov5看的雲裏霧裏。
因此本文,大白主要對Yolov5四種網絡結構的各個細節做一個深入淺出的分析總結,和大家一些探討學習。
版權申明:本文包含圖片,都爲大白使用PPT所繪製的,如需網絡結構高清圖和模型權重,可點擊查看下載。
本文目錄
1 Yolov5 四種網絡模型
1.1 Yolov5網絡結構圖
1.2 網絡結構可視化
1.2.1 Yolov5s網絡結構
1.2.2 Yolov5m網絡結構
1.2.3 Yolov5l網絡結構
1.2.4 Yolov5x網絡結構
2 核心基礎內容
2.1 Yolov3&Yolov4網絡結構圖
2.2 Yolov5核心基礎內容
2.2.1 輸入端
2.2.2 Backbone
2.2.3 Neck
2.2.4 輸出端
2.3 Yolov5四種網絡結構的不同點
2.3.1 四種結構的參數
2.3.2 Yolov5網絡結構
2.3.3 Yolov5四種網絡的深度
2.3.4 Yolov5四種網絡的寬度
3 Yolov5相關論文及代碼
4 小目標分割檢測
5 後語
1 Yolov5四種網絡模型
Yolov5官方代碼中,給出的目標檢測網絡中一共有4個版本,分別是Yolov5s、Yolov5m、Yolov5l、Yolov5x四個模型。
學習一個新的算法,最好在腦海中對算法網絡的整體架構有一個清晰的理解。
但比較尷尬的是,Yolov5代碼中給出的網絡文件是yaml格式,和原本Yolov3、Yolov4中的cfg不同。
因此無法用netron工具直接可視化的查看網絡結構,造成有的同學不知道如何去學習這樣的網絡。
比如下載了Yolov5的四個pt格式的權重模型:

大白在《深入淺出Yolo系列之Yolov3&Yolov4核心基礎完整講解》中講到,可以使用netron工具打開網絡模型。
但因爲netron對pt格式的文件兼容性並不好,直接使用netron工具打開,會發現,根本無法顯示全部網絡。
因此可以採用pt->onnx->netron的折中方式,先使用Yolov5代碼中models/export.py腳本將pt文件轉換爲onnx格式,再用netron工具打開,這樣就可以看全網絡的整體架構了。

如果有同學對netron工具還不是很熟悉,這裏還是放上安裝netron工具的詳解,如果需要安裝,可以移步大白的另一篇文章:《網絡可視化工具netron詳細安裝流程》
如需下載Yolov5整體的4個網絡pt文件及onnx文件,也可點擊鏈接查看下載,便於直觀的學習。
1.1 Yolov5網絡結構圖
安裝好netron工具,就可以可視化的打開Yolov5的網絡結構。
這裏大白也和之前講解Yolov3&Yolov4同樣的方式,繪製了Yolov5s整體的網絡結構圖,配合netron的可視化網絡結構查看,腦海中的架構會更加清晰。
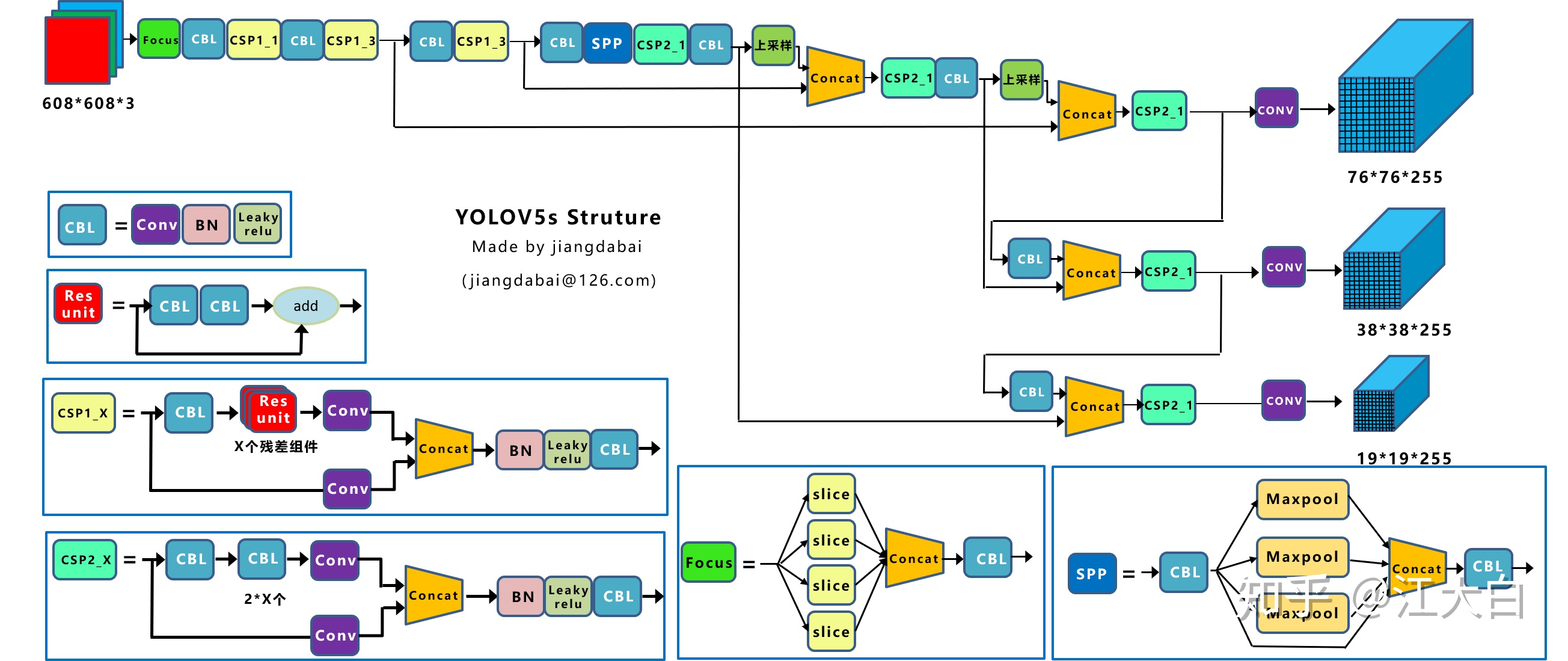
本文也會以Yolov5s的網絡結構爲主線,講解與其他三個模型(Yolov5m、Yolov5l、Yolov5x)的不同點,讓大家對於Yolov5有一個深入淺出的瞭解。
1.2 網絡結構可視化
將四種模型pt文件的轉換成對應的onnx文件後,即可使用netron工具查看。
但是,有些同學可能不方便,使用腳本轉換查看。
因此,大白也上傳了每個網絡結構圖的圖片,也可以直接點擊查看。
雖然沒有netron工具更直觀,但是也可以學習瞭解。
1.2.1 Yolov5s網絡結構
Yolov5s網絡是Yolov5系列中深度最小,特徵圖的寬度最小的網絡。後面的3種都是在此基礎上不斷加深,不斷加寬。
上圖繪製出的網絡結構圖也是Yolov5s的結構,大家也可直接點擊查看,Yolov5s的網絡結構可視化的圖片。
1.2.2 Yolov5m網絡結構
此處也放上netron打開的Yolov5m網絡結構可視圖,點擊即可查看,後面第二版塊會詳細說明不同模型的不同點。
1.2.3 Yolov5l網絡結構
此處也放上netronx打開的Yolov5l網絡結構可視圖,點擊即可查看。
1.2.4 Yolov5x網絡結構
此處也放上netronx打開的Yolov5x網絡結構可視圖,點擊即可查看。
2 核心基礎內容
2.1 Yolov3&Yolov4網絡結構圖
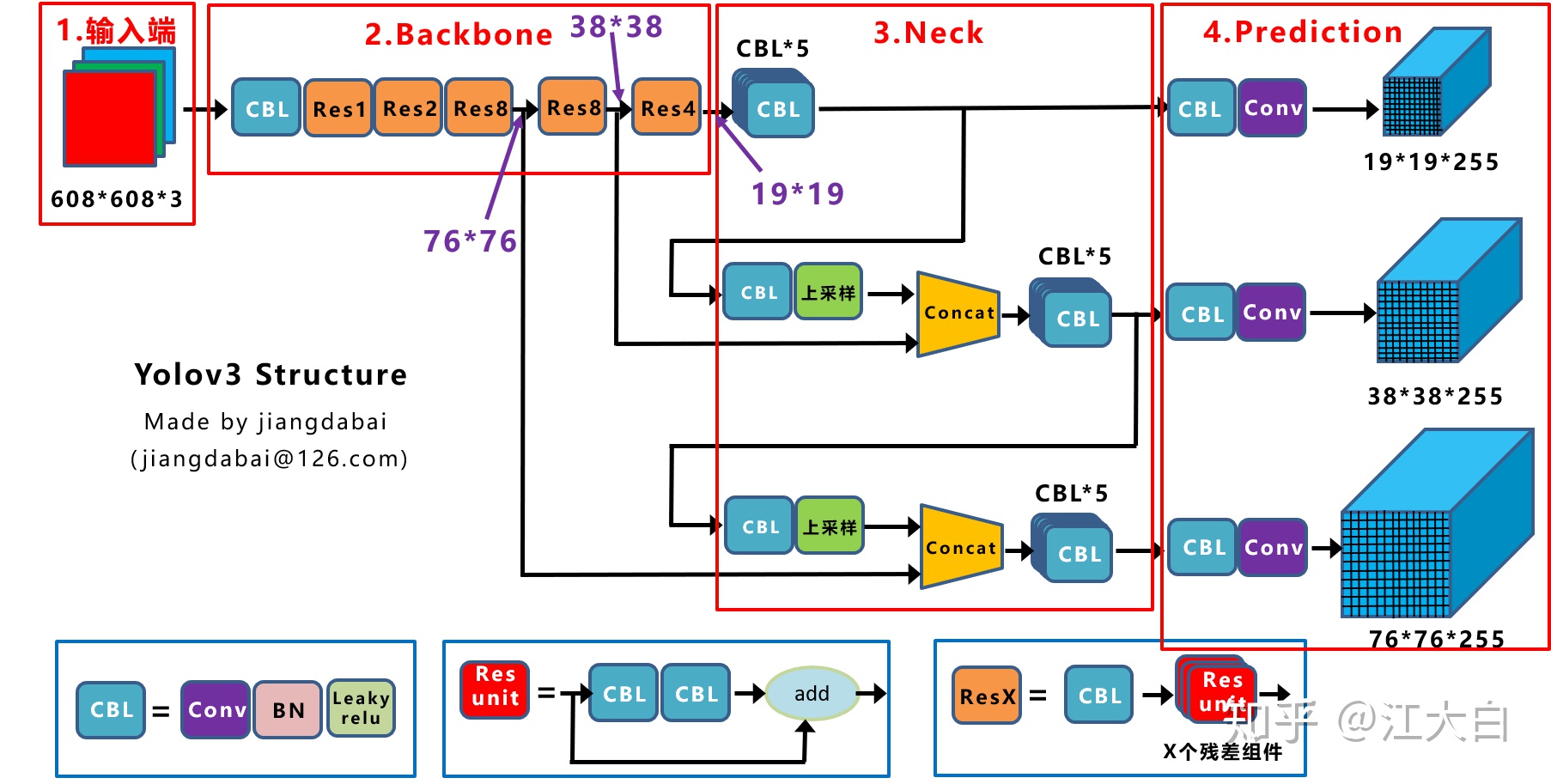
2.1.1 Yolov3網絡結構圖
Yolov3的網絡結構是比較經典的one-stage結構,分爲輸入端、Backbone、Neck和Prediction四個部分。
大白在之前的《深入淺出Yolo系列之Yolov3&Yolov4核心基礎知識完整講解》中講了很多,這裏不多說,還是放上繪製的Yolov3的網絡結構圖。

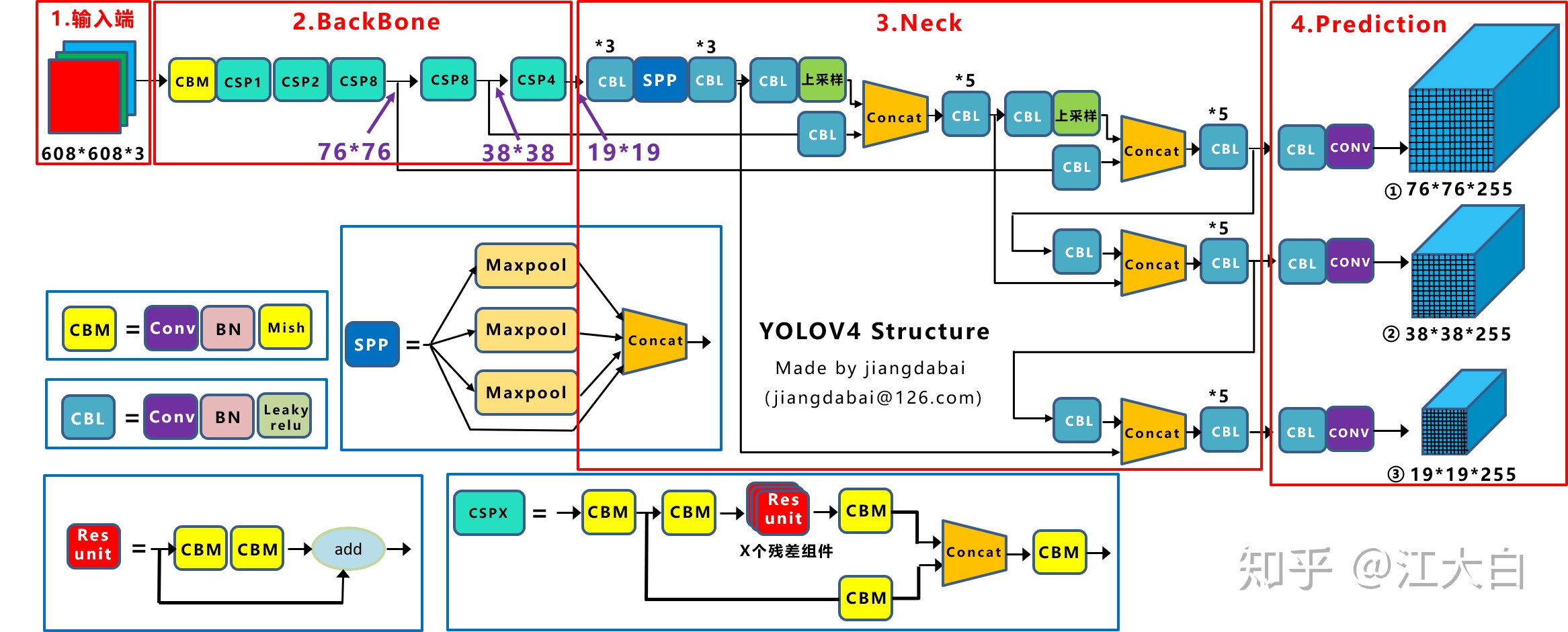
2.1.2 Yolov4網絡結構圖
Yolov4在Yolov3的基礎上進行了很多的創新。
比如輸入端採用mosaic數據增強,
Backbone上採用了CSPDarknet53、Mish激活函數、Dropblock等方式,
Neck中採用了SPP、FPN+PAN的結構,
輸出端則採用CIOU_Loss、DIOU_nms操作。
因此Yolov4對Yolov3的各個部分都進行了很多的整合創新,關於Yolov4詳細的講解還是可以參照大白之前寫的《深入淺出Yolo系列之Yolov3&Yolov4核心基礎知識完整講解》,寫的比較詳細。
2.2 Yolov5核心基礎內容
Yolov5的結構和Yolov4很相似,但也有一些不同,大白還是按照從整體到細節的方式,對每個板塊進行講解。
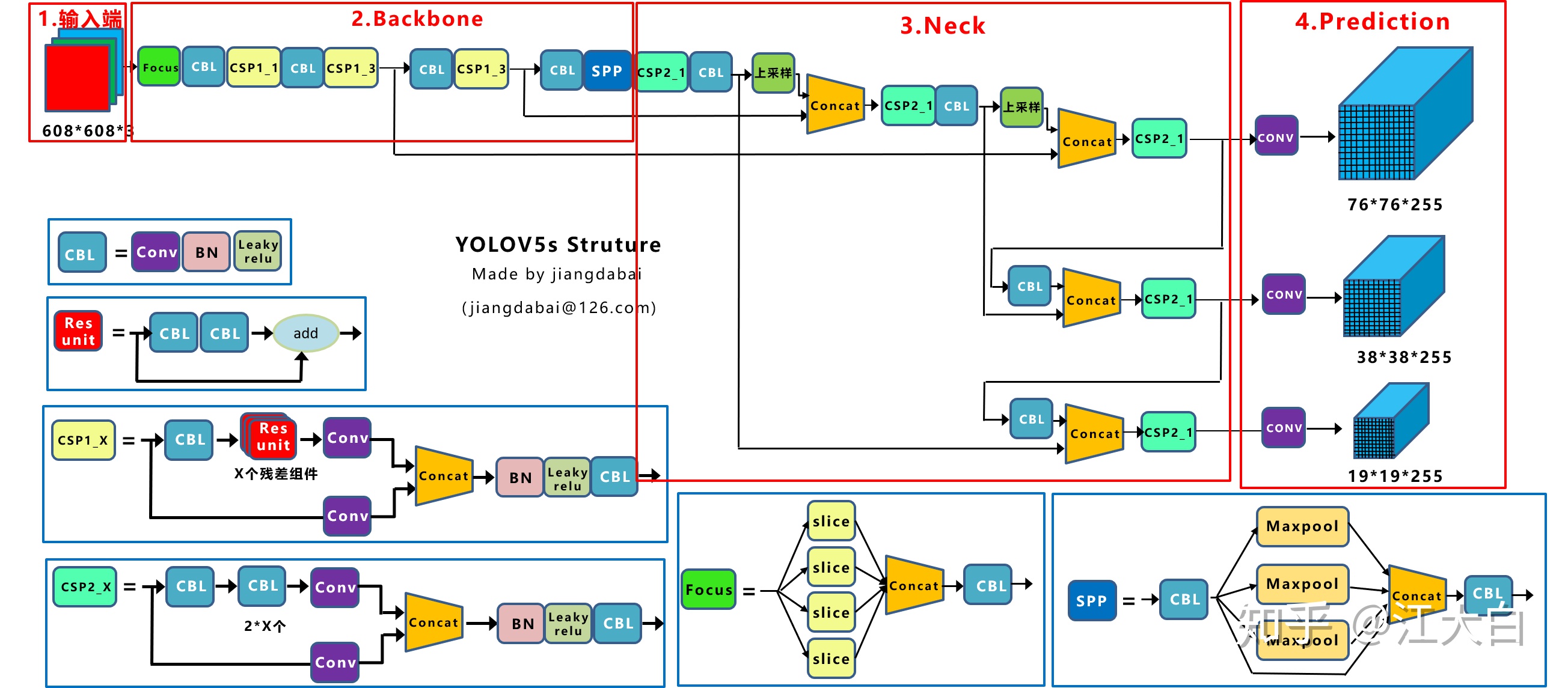
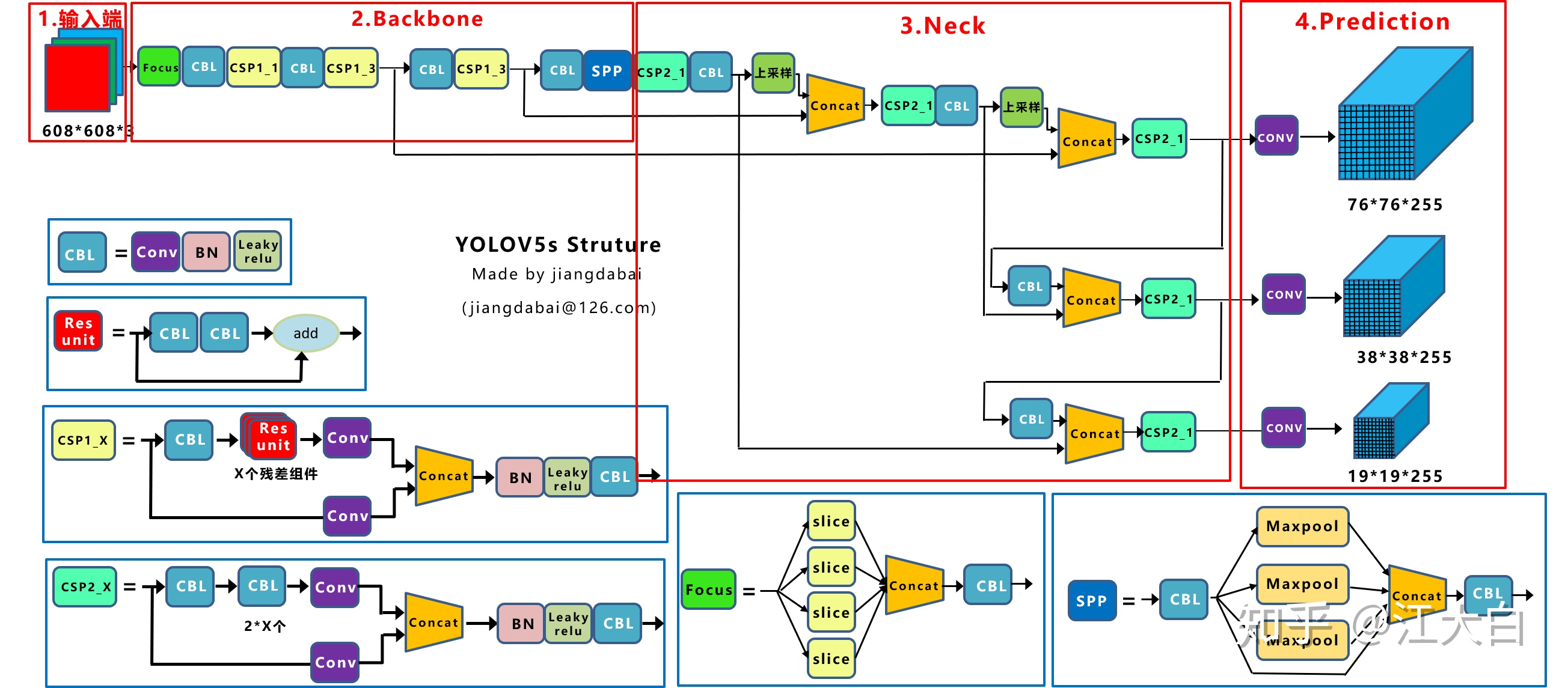
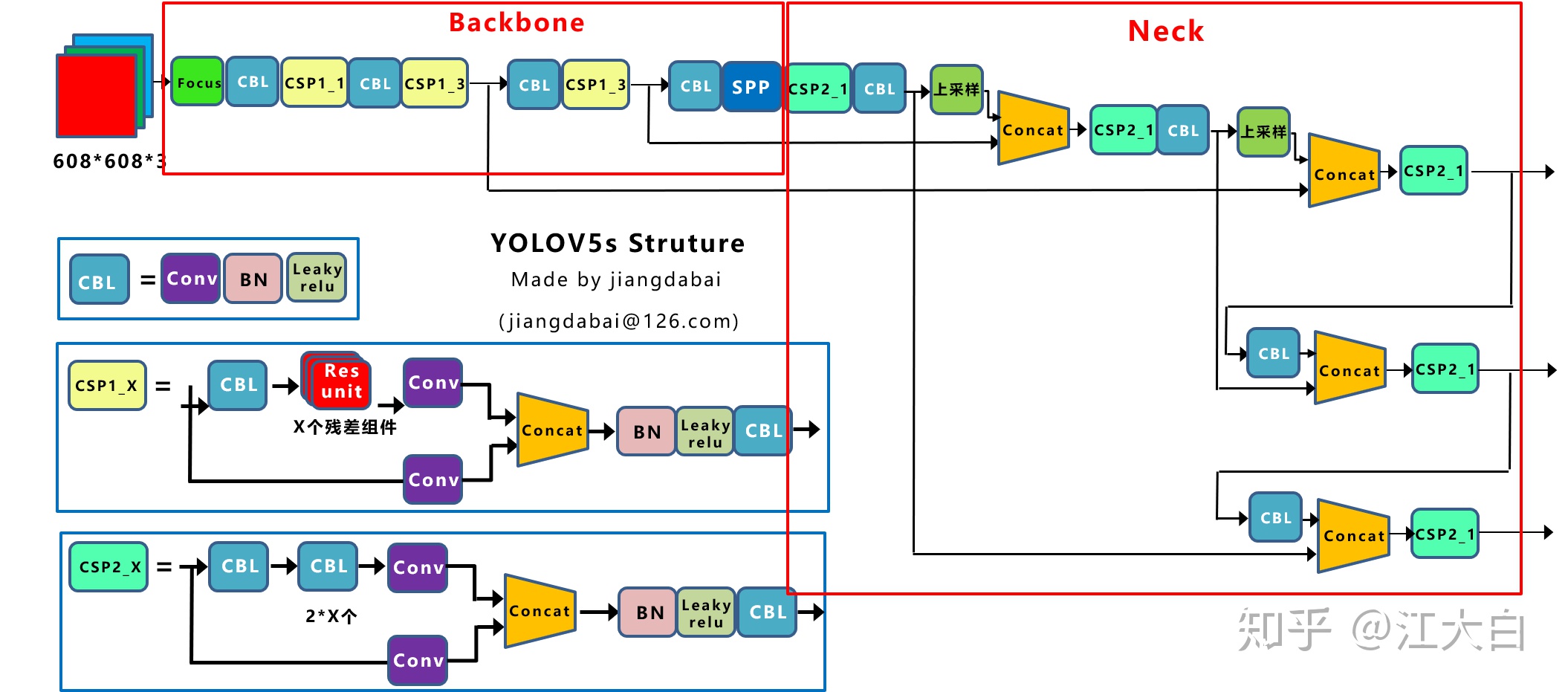
上圖即Yolov5的網絡結構圖,可以看出,還是分爲輸入端、Backbone、Neck、Prediction四個部分。
大家可能對Yolov3比較熟悉,因此大白列舉它和Yolov3的一些主要的不同點,並和Yolov4進行比較。
(1)輸入端:Mosaic數據增強、自適應錨框計算、自適應圖片縮放
(2)Backbone:Focus結構,CSP結構
(3)Neck:FPN+PAN結構
(4)Prediction:GIOU_Loss
下面丟上Yolov5作者的算法性能測試圖:
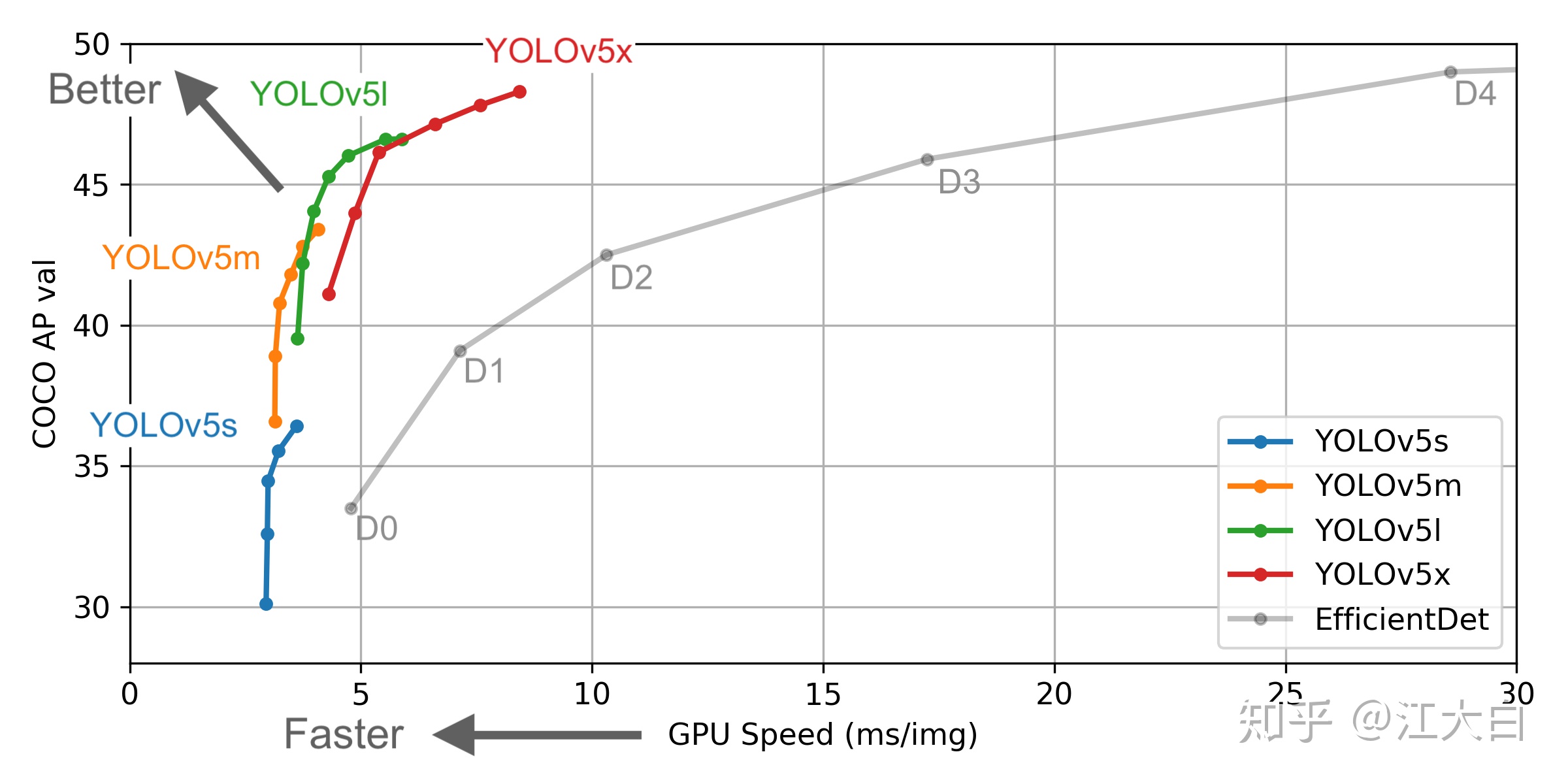
Yolov5作者也是在COCO數據集上進行的測試,大白在之前的文章講過,COCO數據集的小目標占比,因此最終的四種網絡結構,性能上來說各有千秋。
Yolov5s網絡最小,速度最少,AP精度也最低。但如果檢測的以大目標爲主,追求速度,倒也是個不錯的選擇。
其他的三種網絡,在此基礎上,不斷加深加寬網絡,AP精度也不斷提升,但速度的消耗也在不斷增加。
2.2.1 輸入端
(1)Mosaic數據增強
Yolov5的輸入端採用了和Yolov4一樣的Mosaic數據增強的方式。
Mosaic數據增強提出的作者也是來自Yolov5團隊的成員,不過,隨機縮放、隨機裁剪、隨機排布的方式進行拼接,對於小目標的檢測效果還是很不錯的。

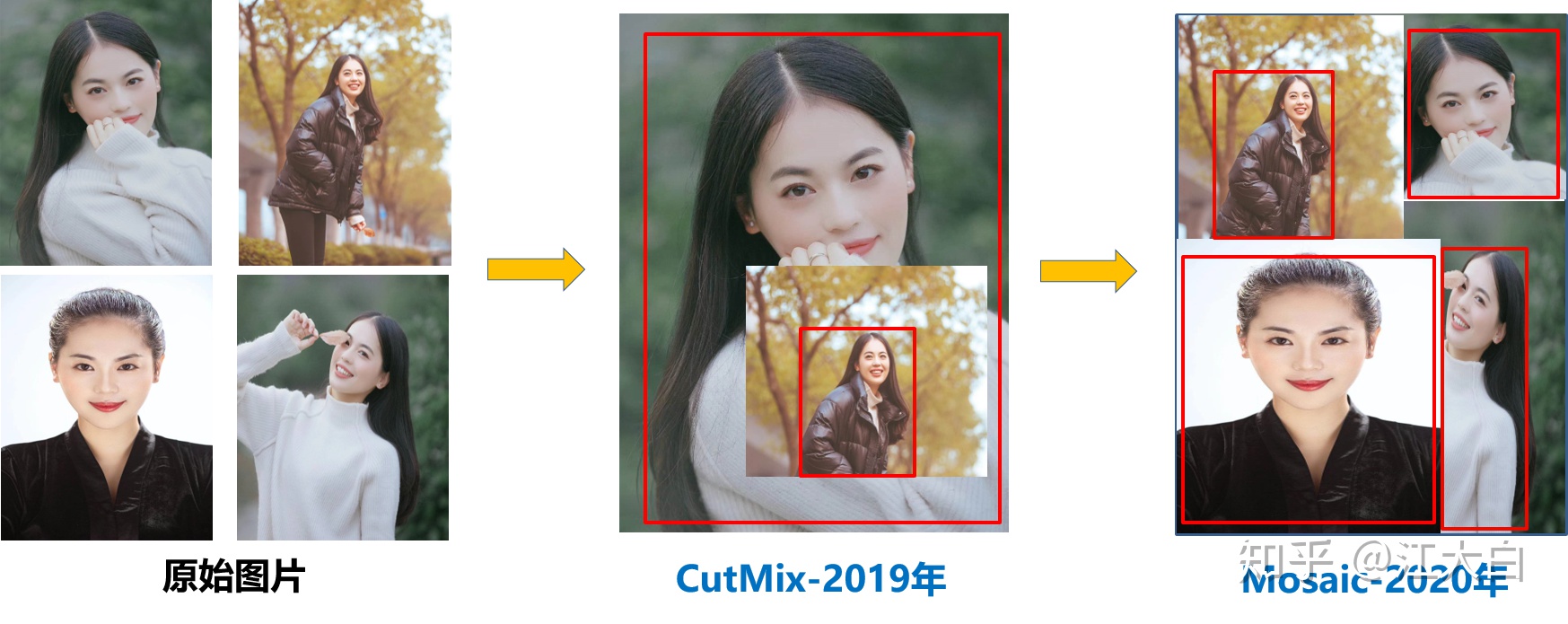
Mosaic數據增強的內容在之前《深入淺出Yolo系列之Yolov3&Yolov4核心基礎知識完整講解》文章中寫的很詳細,詳情可以查看之前的內容。
(2) 自適應錨框計算
在Yolo算法中,針對不同的數據集,都會有初始設定長寬的錨框。
在網絡訓練中,網絡在初始錨框的基礎上輸出預測框,進而和真實框groundtruth進行比對,計算兩者差距,再反向更新,迭代網絡參數。
因此初始錨框也是比較重要的一部分,比如Yolov5在Coco數據集上初始設定的錨框:

在Yolov3、Yolov4中,訓練不同的數據集時,計算初始錨框的值是通過單獨的程序運行的。
但Yolov5中將此功能嵌入到代碼中,每次訓練時,自適應的計算不同訓練集中的最佳錨框值。
當然,如果覺得計算的錨框效果不是很好,也可以在代碼中將自動計算錨框功能關閉。

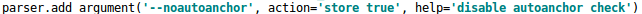
控制的代碼即train.py中上面一行代碼,設置成False,每次訓練時,不會自動計算。
(3)自適應圖片縮放
在常用的目標檢測算法中,不同的圖片長寬都不相同,因此常用的方式是將原始圖片統一縮放到一個標準尺寸,再送入檢測網絡中。
比如Yolo算法中常用416*416,608*608等尺寸,比如對下面800*600的圖像進行縮放。

但Yolov5代碼中對此進行了改進,也是Yolov5推理速度能夠很快的一個不錯的trick。
作者認爲,在項目實際使用時,很多圖片的長寬比不同,因此縮放填充後,兩端的黑邊大小都不同,而如果填充的比較多,則存在信息冗餘,影響推理速度。
因此在Yolov5的代碼中datasets.py的letterbox函數中進行了修改,對原始圖像自適應的添加最少的黑邊。


圖像高度上兩端的黑邊變少了,在推理時,計算量也會減少,即目標檢測速度會得到提升。
這種方式在之前github上Yolov3中也進行了討論:https://github.com/ultralytics/yolov3/issues/232
在討論中,通過這種簡單的改進,推理速度得到了37%的提升,可以說效果很明顯。
但是有的同學可能會有大大的問號??如何進行計算的呢?大白按照Yolov5中的思路詳細的講解一下,在datasets.py的letterbox函數中也有詳細的代碼。
第一步:計算縮放比例
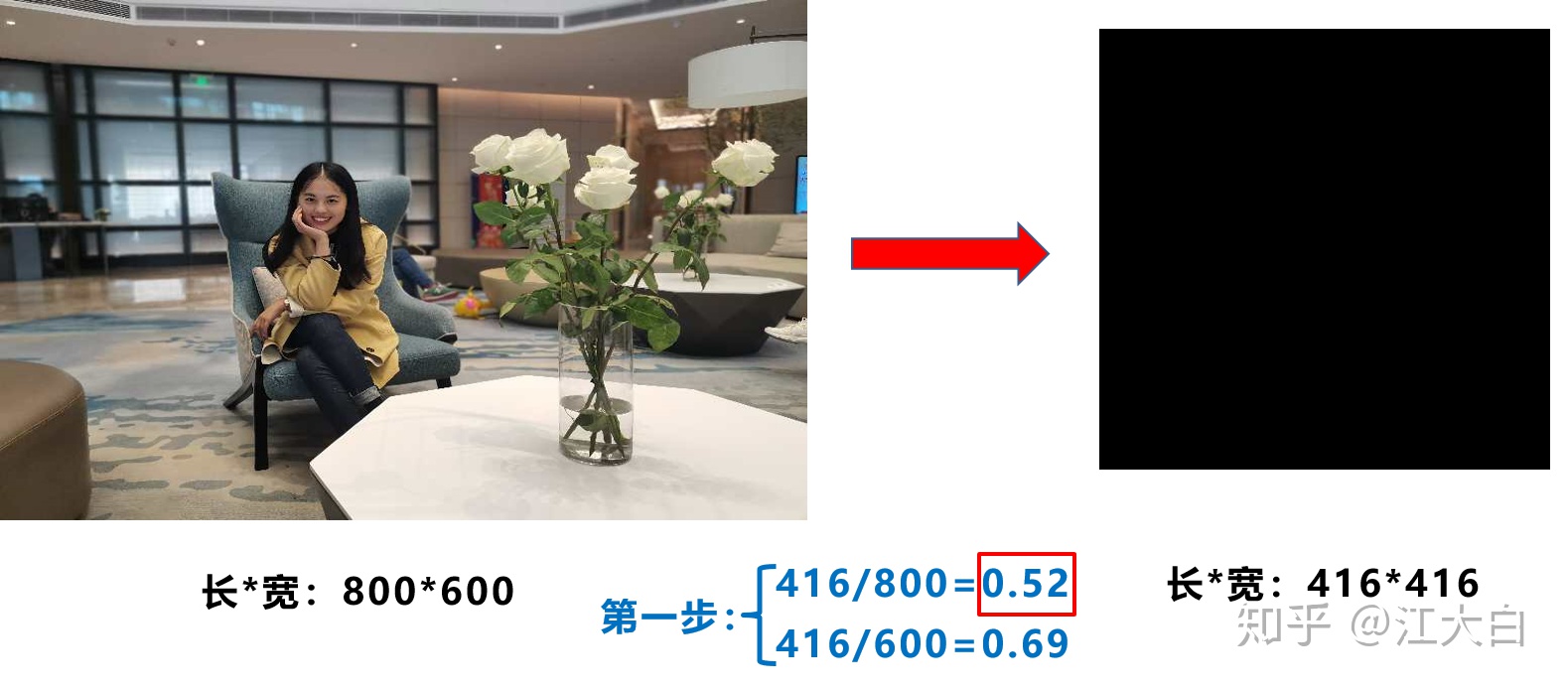
原始縮放尺寸是416*416,都除以原始圖像的尺寸後,可以得到0.52,和0.69兩個縮放係數,選擇小的縮放係數。
第二步:計算縮放後的尺寸


原始圖片的長寬都乘以最小的縮放係數0.52,寬變成了416,而高變成了312。
第三步:計算黑邊填充數值

將416-312=104,得到原本需要填充的高度。再採用numpy中np.mod取餘數的方式,得到40個像素,再除以2,即得到圖片高度兩端需要填充的數值。
此外,需要注意的是:
a.這裏大白填充的是黑色,即(0,0,0),而Yolov5中填充的是灰色,即(114,114,114),都是一樣的效果。
b.訓練時沒有采用縮減黑邊的方式,還是採用傳統填充的方式,即縮放到416*416大小。只是在測試,使用模型推理時,才採用縮減黑邊的方式,提高目標檢測,推理的速度。
2.2.2 Backbone
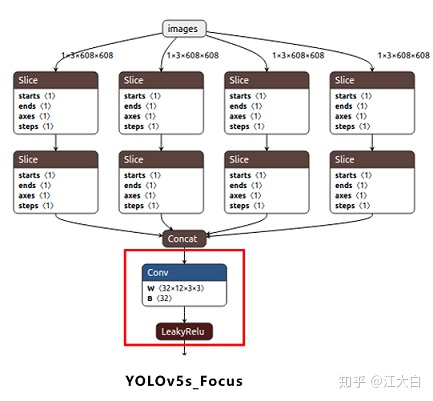
(1)Focus結構

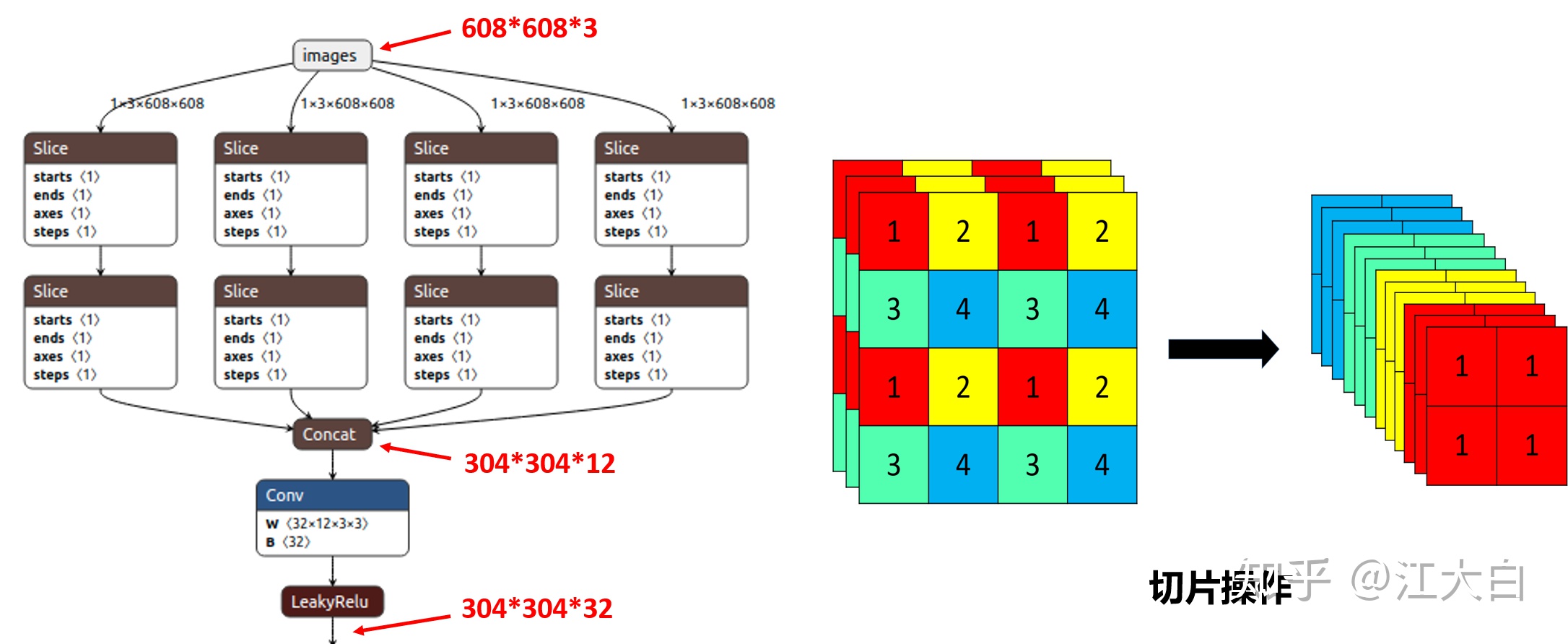
Focus結構,在Yolov3&Yolov4中並沒有這個結構,其中比較關鍵是切片操作。
比如右圖的切片示意圖,4*4*3的圖像切片後變成2*2*12的特徵圖。
以Yolov5s的結構爲例,原始608*608*3的圖像輸入Focus結構,採用切片操作,先變成304*304*12的特徵圖,再經過一次32個卷積核的卷積操作,最終變成304*304*32的特徵圖。
需要注意的是:Yolov5s的Focus結構最後使用了32個卷積核,而其他三種結構,使用的數量有所增加,先注意下,後面會講解到四種結構的不同點。
(2)CSP結構
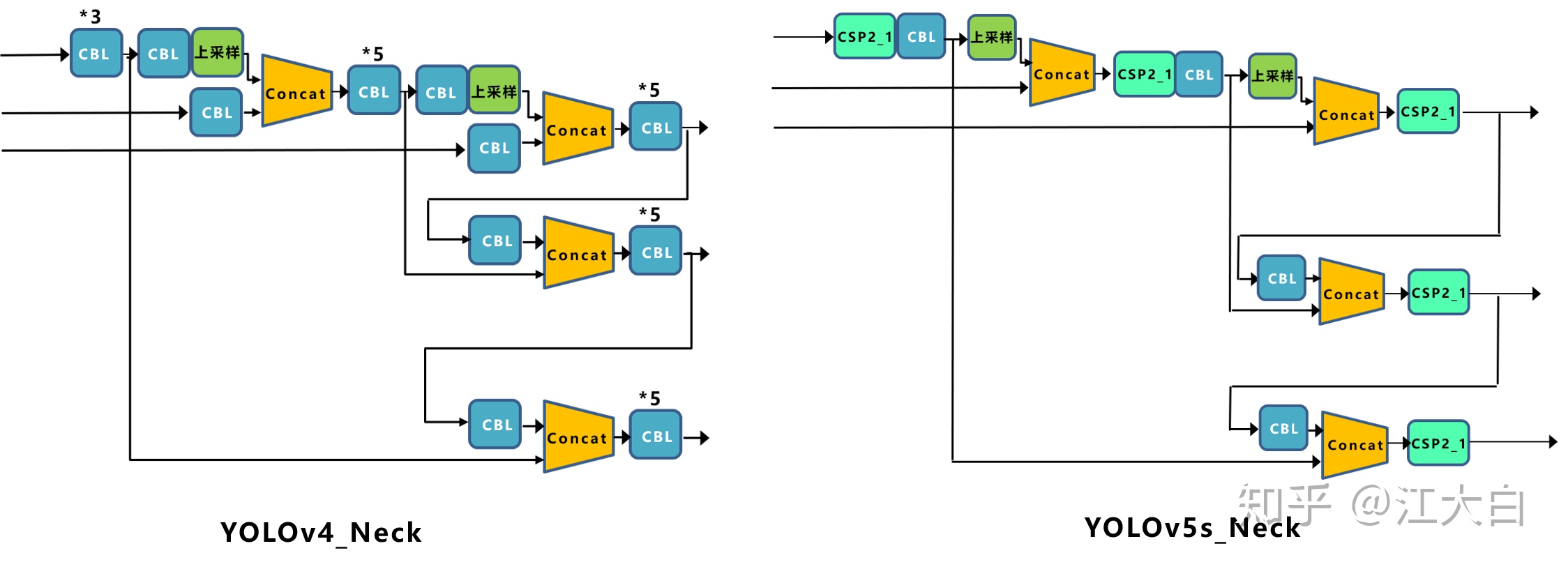
Yolov4網絡結構中,借鑑了CSPNet的設計思路,在主幹網絡中設計了CSP結構。
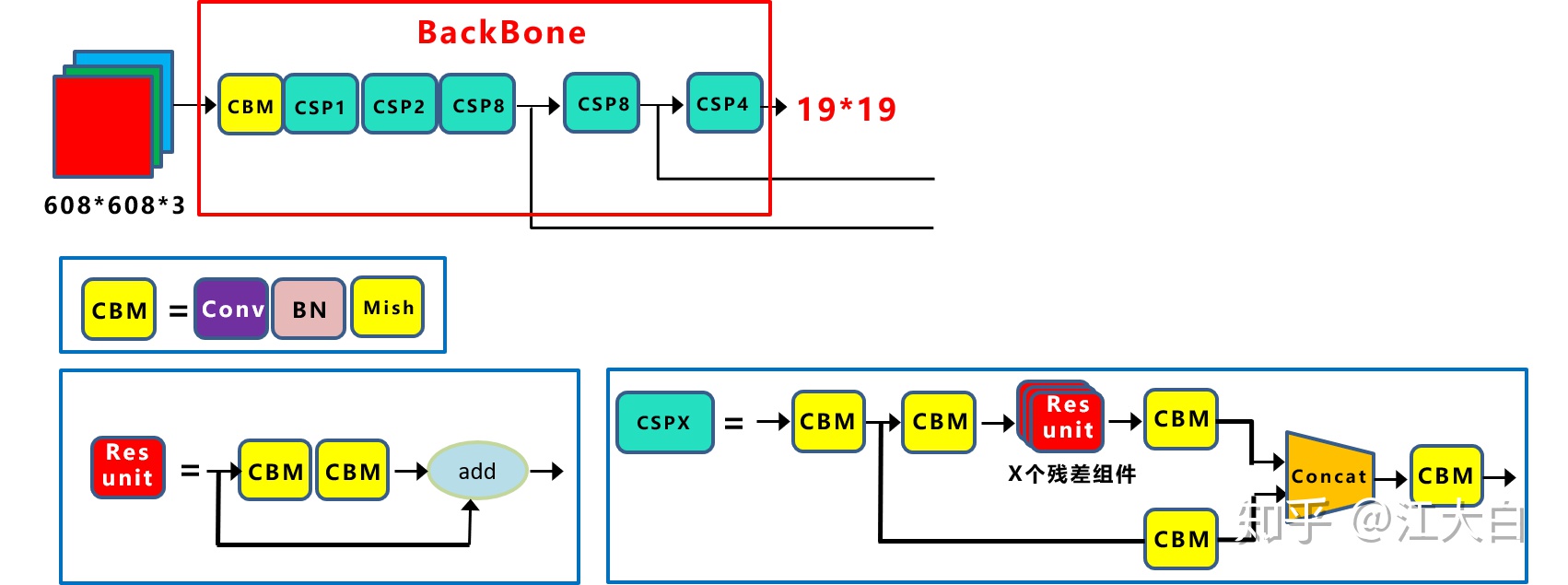
Yolov5與Yolov4不同點在於,Yolov4中只有主幹網絡使用了CSP結構。
而Yolov5中設計了兩種CSP結構,以Yolov5s網絡爲例,CSP1_X結構應用於Backbone主幹網絡,另一種CSP2_X結構則應用於Neck中。

這裏關於CSPNet的內容,也可以查看大白之前的《深入淺出Yolo系列之Yolov3&Yolov4核心基礎完整講解》。
2.2.3 Neck
Yolov5現在的Neck和Yolov4中一樣,都採用FPN+PAN的結構,但在Yolov5剛出來時,只使用了FPN結構,後面才增加了PAN結構,此外網絡中其他部分也進行了調整。
因此,大白在Yolov5剛提出時,畫的很多結構圖,又都重新進行了調整。
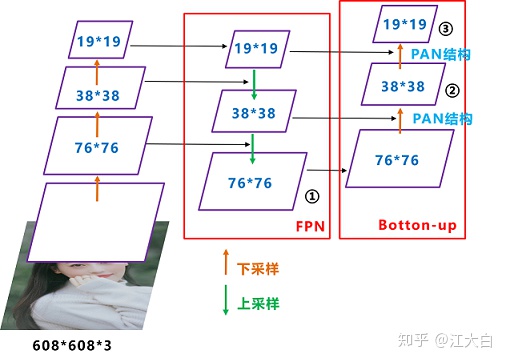
這裏關於FPN+PAN的結構,大白在《深入淺出Yolo系列之Yolov3&Yolov4核心基礎知識完整講解》中,講的很多,大家應該都有理解。
但如上面CSPNet結構中講到,Yolov5和Yolov4的不同點在於,
Yolov4的Neck結構中,採用的都是普通的卷積操作。而Yolov5的Neck結構中,採用借鑑CSPnet設計的CSP2結構,加強網絡特徵融合的能力。
2.2.4 輸出端
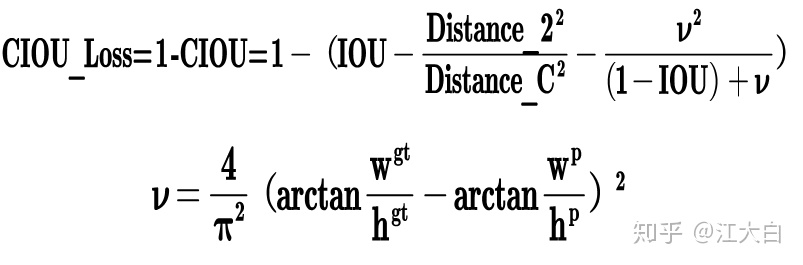
(1)Bounding box損失函數
在《深入淺出Yolo系列之Yolov3&Yolov4核心基礎知識完整講解》中,大白詳細的講解了IOU_Loss,以及進化版的GIOU_Loss,DIOU_Loss,以及CIOU_Loss。
Yolov5中採用其中的GIOU_Loss做Bounding box的損失函數。
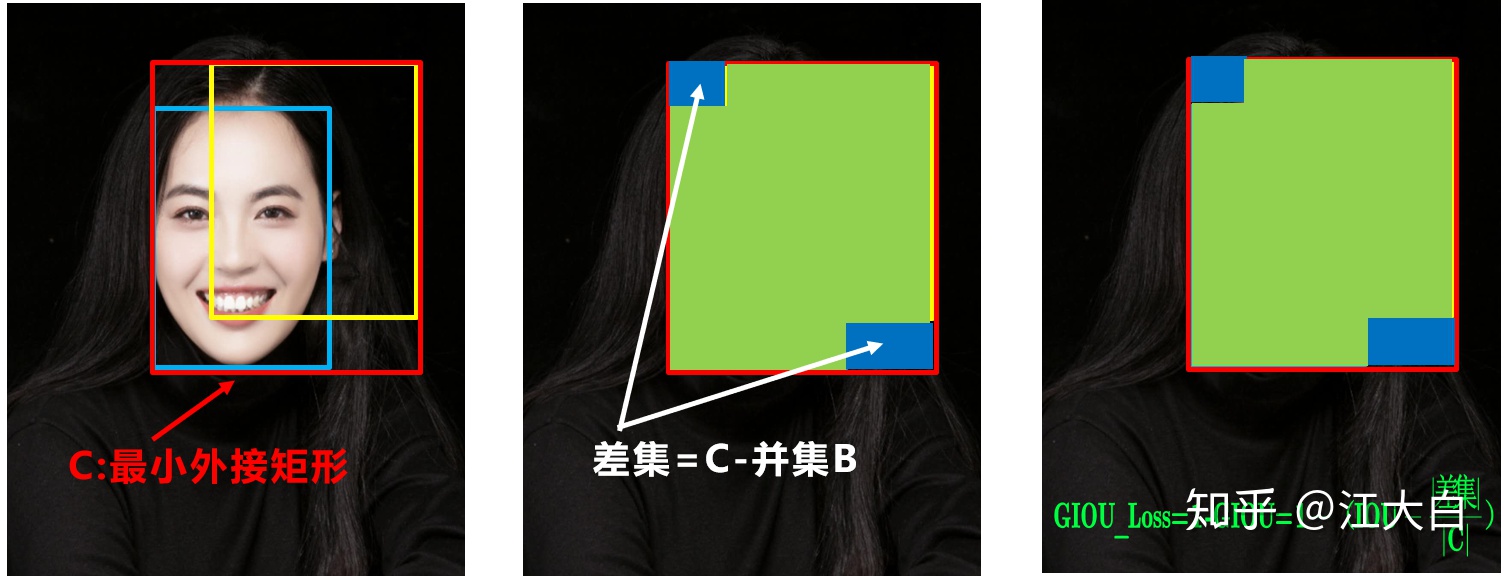
而Yolov4中採用CIOU_Loss作爲目標Bounding box的損失。

(2)nms非極大值抑制
在目標檢測的後處理過程中,針對很多目標框的篩選,通常需要nms操作。
因爲CIOU_Loss中包含影響因子v,涉及groudtruth的信息,而測試推理時,是沒有groundtruth的。
所以Yolov4在DIOU_Loss的基礎上採用DIOU_nms的方式,而Yolov5中採用加權nms的方式。
可以看出,採用DIOU_nms,下方中間箭頭的黃色部分,原本被遮擋的摩托車也可以檢出。

大白在項目中,也採用了DIOU_nms的方式,在同樣的參數情況下,將nms中IOU修改成DIOU_nms。對於一些遮擋重疊的目標,確實會有一些改進。
比如下面黃色箭頭部分,原本兩個人重疊的部分,在參數和普通的IOU_nms一致的情況下,修改成DIOU_nms,可以將兩個目標檢出。
雖然大多數狀態下效果差不多,但在不增加計算成本的情況下,有稍微的改進也是好的。


2.3 Yolov5四種網絡結構的不同點
Yolov5代碼中的四種網絡,和之前的Yolov3,Yolov4中的cfg文件不同,都是以yaml的形式來呈現。
而且四個文件的內容基本上都是一樣的,只有最上方的depth_multiple和width_multiple兩個參數不同,很多同學看的一臉懵逼,不知道只通過兩個參數是如何控制四種結構的?
2.3.1 四種結構的參數
大白先取出Yolov5代碼中,每個網絡結構的兩個參數:
(1)Yolov5s.yaml

(2)Yolov5m.yaml

(3)Yolov5l.yaml

(4)Yolov5x.yaml

四種結構就是通過上面的兩個參數,來進行控制網絡的深度和寬度。其中depth_multiple控制網絡的深度,width_multiple控制網絡的寬度。
2.3.2 Yolov5網絡結構
四種結構的yaml文件中,下方的網絡架構代碼都是一樣的。
爲了便於講解,大白將其中的Backbone部分提取出來,講解如何控制網絡的寬度和深度,yaml文件中的Head部分也是同樣的原理。

在對網絡結構進行解析時,yolo.py中下方的這一行代碼將四種結構的depth_multiple,width_multiple提取出,賦值給gd,gw。後面主要對這gd,gw這兩個參數進行講解。

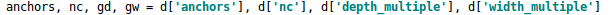
下面再細緻的剖析下,看是如何控制每種結構,深度和寬度的。
2.3.3 Yolov5四種網絡的深度
(1)不同網絡的深度
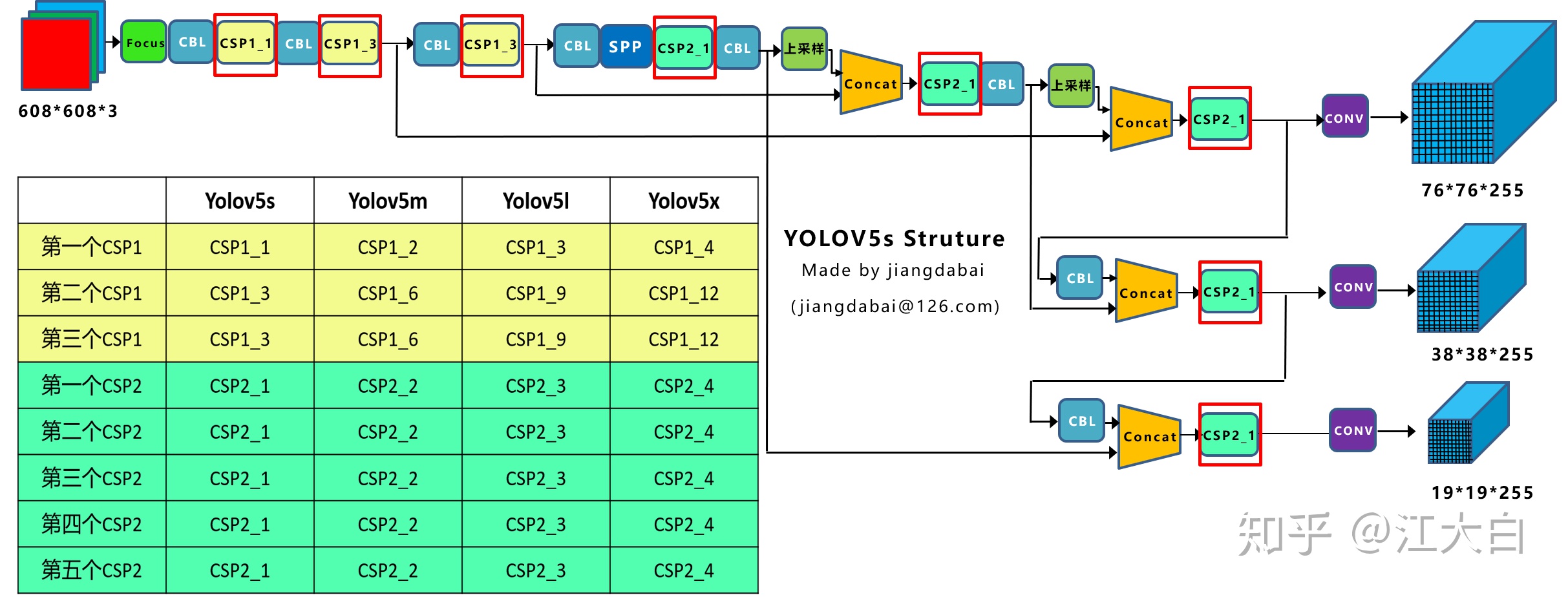
在上圖中,大白畫了兩種CSP結構,CSP1和CSP2,其中CSP1結構主要應用於Backbone中,CSP2結構主要應用於Neck中。
需要注意的是,四種網絡結構中每個CSP結構的深度都是不同的。
a.以yolov5s爲例,第一個CSP1中,使用了1個殘差組件,因此是CSP1_1。而在Yolov5m中,則增加了網絡的深度,在第一個CSP1中,使用了2個殘差組件,因此是CSP1_2。
而Yolov5l中,同樣的位置,則使用了3個殘差組件,Yolov5x中,使用了4個殘差組件。
其餘的第二個CSP1和第三個CSP1也是同樣的原理。
b.在第二種CSP2結構中也是同樣的方式,以第一個CSP2結構爲例,Yolov5s組件中使用了2*1=2組卷積,因此是CSP2_1。
而Yolov5m中使用了2組,Yolov5l中使用了3組,Yolov5x中使用了4組。
其他的四個CSP2結構,也是同理。
Yolov5中,網絡的不斷加深,也在不斷增加網絡特徵提取和特徵融合的能力。
(2)控制深度的代碼
控制四種網絡結構的核心代碼是yolo.py中下面的代碼,存在兩個變量,n和gd。
我們再將n和gd帶入計算,看每種網絡的變化結果。

(3)驗證控制深度的有效性
我們選擇最小的yolov5s.yaml和中間的yolov5l.yaml兩個網絡結構,將gd(height_multiple)係數帶入,看是否正確。

a. yolov5x.yaml
其中height_multiple=0.33,即gd=0.33,而n則由上面紅色框中的信息獲得。
以上面網絡框圖中的第一個CSP1爲例,即上面的第一個紅色框。n等於第二個數值3。
而gd=0.33,帶入(2)中的計算代碼,結果n=1。因此第一個CSP1結構內只有1個殘差組件,即CSP1_1。
第二個CSP1結構中,n等於第二個數值9,而gd=0.33,帶入(2)中計算,結果n=3,因此第二個CSP1結構中有3個殘差組件,即CSP1_3。
第三個CSP1結構也是同理,這裏不多說。
b. yolov5l.xml
其中height_multiple=1,即gd=1
和上面的計算方式相同,第一個CSP1結構中,n=1,帶入代碼中,結果n=3,因此爲CSP1_3。
下面第二個CSP1和第三個CSP1結構都是同樣的原理。
2.3.4 Yolov5四種網絡的寬度

(1)不同網絡的寬度:
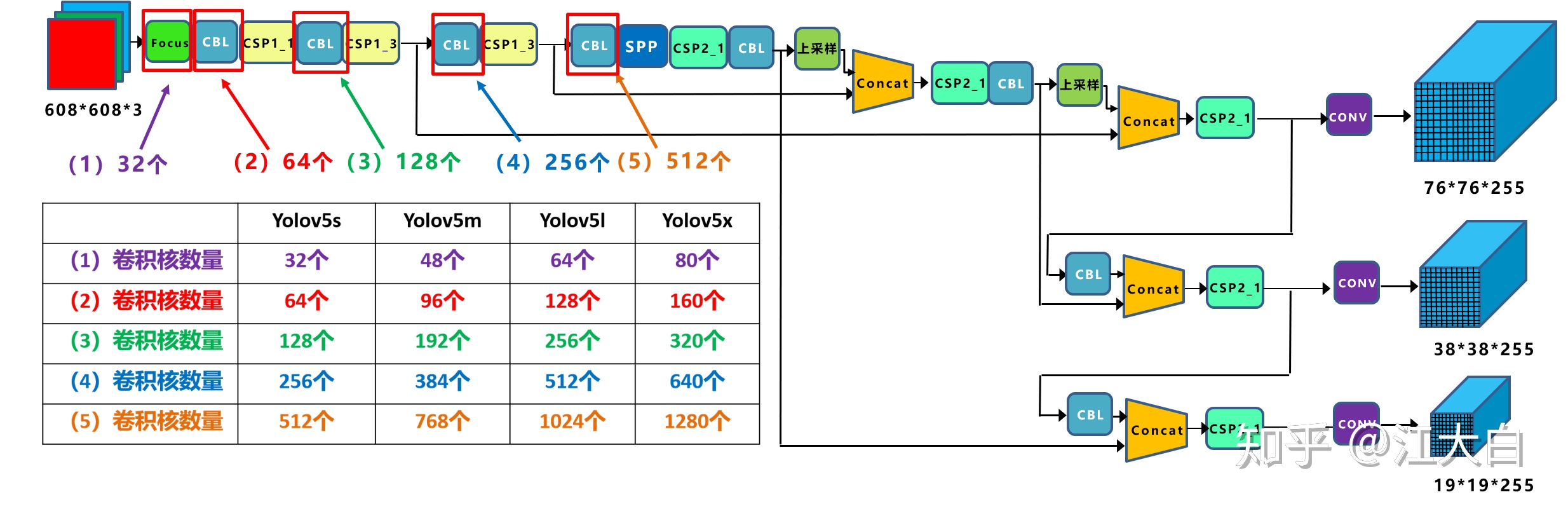
如上圖表格中所示,四種yolov5結構在不同階段的卷積核的數量都是不一樣的,因此也直接影響卷積後特徵圖的第三維度,即厚度,大白這裏表示爲網絡的寬度。
a.以Yolov5s結構爲例,第一個Focus結構中,最後卷積操作時,卷積核的數量是32個,因此經過Focus結構,特徵圖的大小變成304*304*32。
而yolov5m的Focus結構中的卷積操作使用了48個卷積核,因此Focus結構後的特徵圖變成304*304*48。yolov5l,yolov5x也是同樣的原理。
b. 第二個卷積操作時,yolov5s使用了64個卷積核,因此得到的特徵圖是152*152*64。而yolov5m使用96個特徵圖,因此得到的特徵圖是152*152*96。yolov5l,yolov5x也是同理。
c. 後面三個卷積下采樣操作也是同樣的原理,這樣大白不過多講解。
四種不同結構的卷積核的數量不同,這也直接影響網絡中,比如CSP1,CSP2等結構,以及各個普通卷積,卷積操作時的卷積核數量也同步在調整,影響整體網絡的計算量。
大家最好可以將結構圖和前面第一部分四個網絡的特徵圖鏈接,對應查看,思路會更加清晰。
當然卷積核的數量越多,特徵圖的厚度,即寬度越寬,網絡提取特徵的學習能力也越強。
(2)控制寬度的代碼
在yolov5的代碼中,控制寬度的核心代碼是yolo.py文件裏面的這一行:

它所調用的子函數make_divisible的功能是:

(3)驗證控制寬度的有效性
我們還是選擇最小的yolov5s和中間的yolov5l兩個網絡結構,將width_multiple係數帶入,看是否正確。

a. yolov5x.yaml
其中width_multiple=0.5,即gw=0.5。

以第一個卷積下采樣爲例,即Focus結構中下面的卷積操作。
按照上面Backbone的信息,我們知道Focus中,標準的c2=64,而gw=0.5,代入(2)中的計算公式,最後的結果=32。即Yolov5s的Focus結構中,卷積下采樣操作的卷積核數量爲32個。
再計算後面的第二個卷積下采樣操作,標準c2的值=128,gw=0.5,代入(2)中公式,最後的結果=64,也是正確的。
b. yolov5l.yaml
其中width_multiple=1,即gw=1,而標準的c2=64,代入上面(2)的計算公式中,可以得到Yolov5l的Focus結構中,卷積下采樣操作的卷積核的數量爲64個,而第二個卷積下采樣的卷積核數量是128個。
另外的三個卷積下采樣操作,以及yolov5m,yolov5x結構也是同樣的計算方式,大白這裏不過多解釋。
3 Yolov5相關論文及代碼
3.1 代碼
Yolov5的作者並沒有發表論文,因此只能從代碼角度進行分析。
Yolov5代碼:https://github.com/ultralytics/yolov5
大家可以根據網頁的說明,下載訓練,及測試,流程還是比較簡單的。
3.2 相關論文
另外一篇論文,PP-Yolo,在Yolov3的原理上,採用了很多的tricks調參方式,也挺有意思。
感興趣的話可以參照另一個博主的文章:點擊查看
4 小目標分割檢測
目標檢測發展很快,但對於小目標的檢測還是有一定的瓶頸,特別是大分辨率圖像小目標檢測。比如7920*2160,甚至16000*16000的圖像。

圖像的分辨率很大,但又有很多小的目標需要檢測。但是如果直接輸入檢測網絡,比如yolov3,檢出效果並不好。
主要原因是:
(1)小目標尺寸
以網絡的輸入608*608爲例,yolov3、yolov4,yolov5中下采樣都使用了5次,因此最後的特徵圖大小是19*19,38*38,76*76。
三個特徵圖中,最大的76*76負責檢測小目標,而對應到608*608上,每格特徵圖的感受野是608/76=8*8大小。

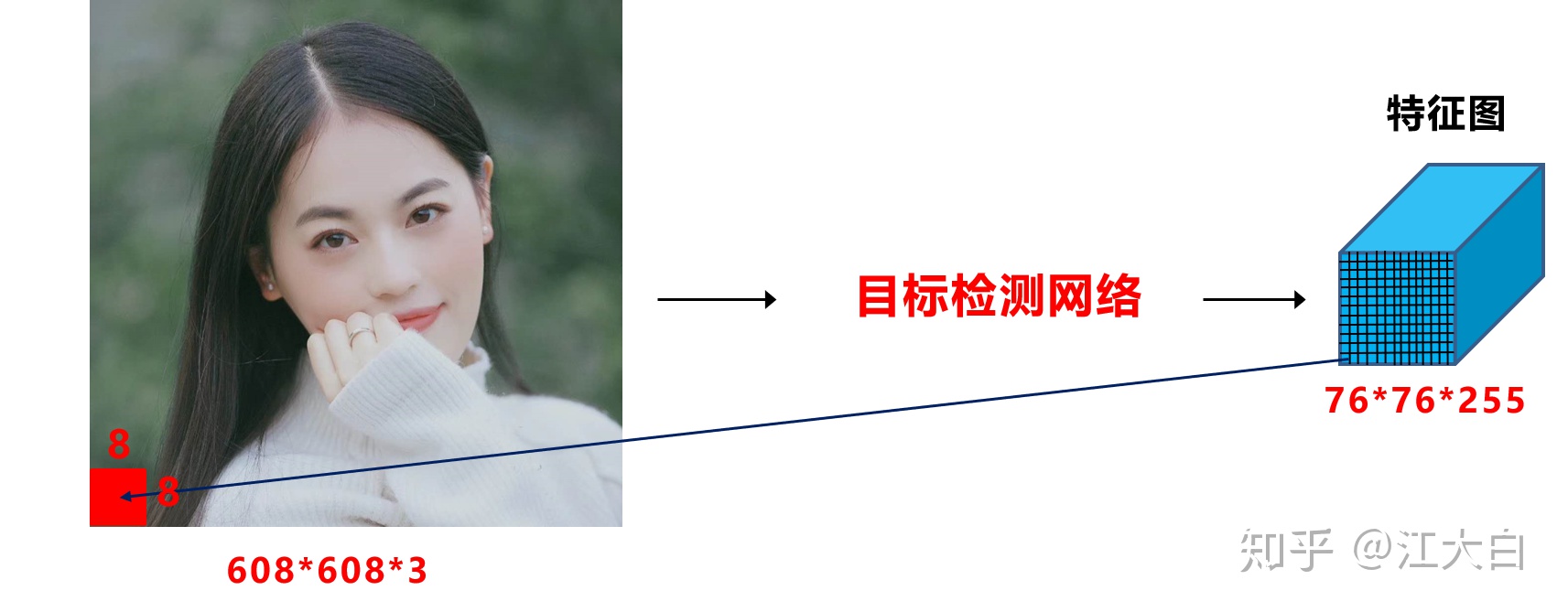
再將608*608對應到7680*2160上,以最長邊7680爲例,7680/608*8=101。
即如果原始圖像中目標的寬或高小於101像素,網絡很難學習到目標的特徵信息。
(PS:這裏忽略多尺度訓練的因素及增加網絡檢測分支的情況)
(2)高分辨率
而在很多遙感圖像中,長寬比的分辨率比7680*2160更大,比如上面的16000*16000,如果採用直接輸入原圖的方式,很多小目標都無法檢測出。
(3)顯卡爆炸
很多圖像分辨率很大,如果簡單的進行下采樣,下采樣的倍數太大,容易丟失數據信息。
但是倍數太小,網絡前向傳播需要在內存中保存大量的特徵圖,極大耗盡GPU資源,很容易發生顯存爆炸,無法正常的訓練及推理。
因此可以借鑑2018年YOLT算法的方式,改變一下思維,對大分辨率圖片先進行分割,變成一張張小圖,再進行檢測。
需要注意的是:
爲了避免兩張小圖之間,一些目標正好被分割截斷,所以兩個小圖之間設置overlap重疊區域,比如分割的小圖是960*960像素大小,則overlap可以設置爲960*20%=192像素。
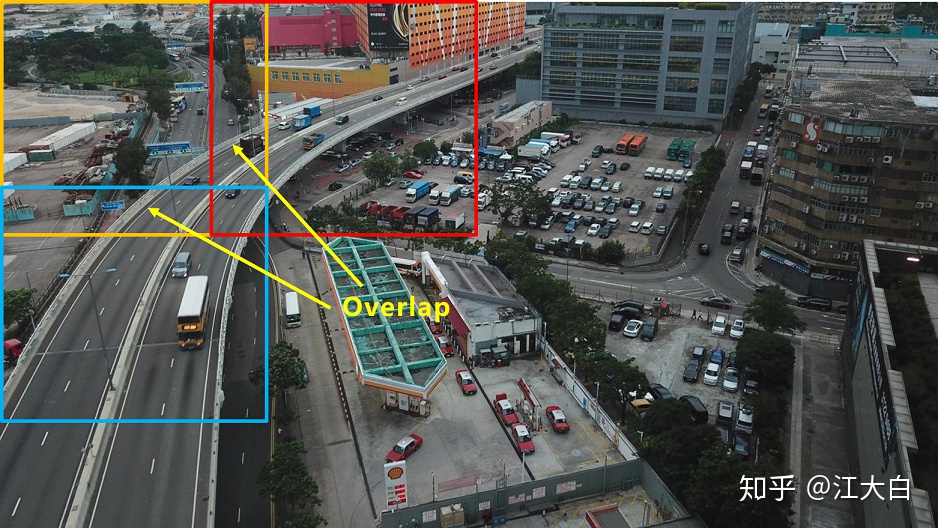
每個小圖檢測完成後,再將所有的框放到大圖上,對大圖整體做一次nms操作,將重疊區域的很多重複框去除。
這樣操作,可以將很多小目標檢出,比如16000*16000像素的遙感圖像。

無人機視角下,也有很多小的目標。大白也進行了測試,效果還是不錯的。
比如下圖是將原始大圖->416*416大小,直接使用目標檢測網絡輸出的效果:
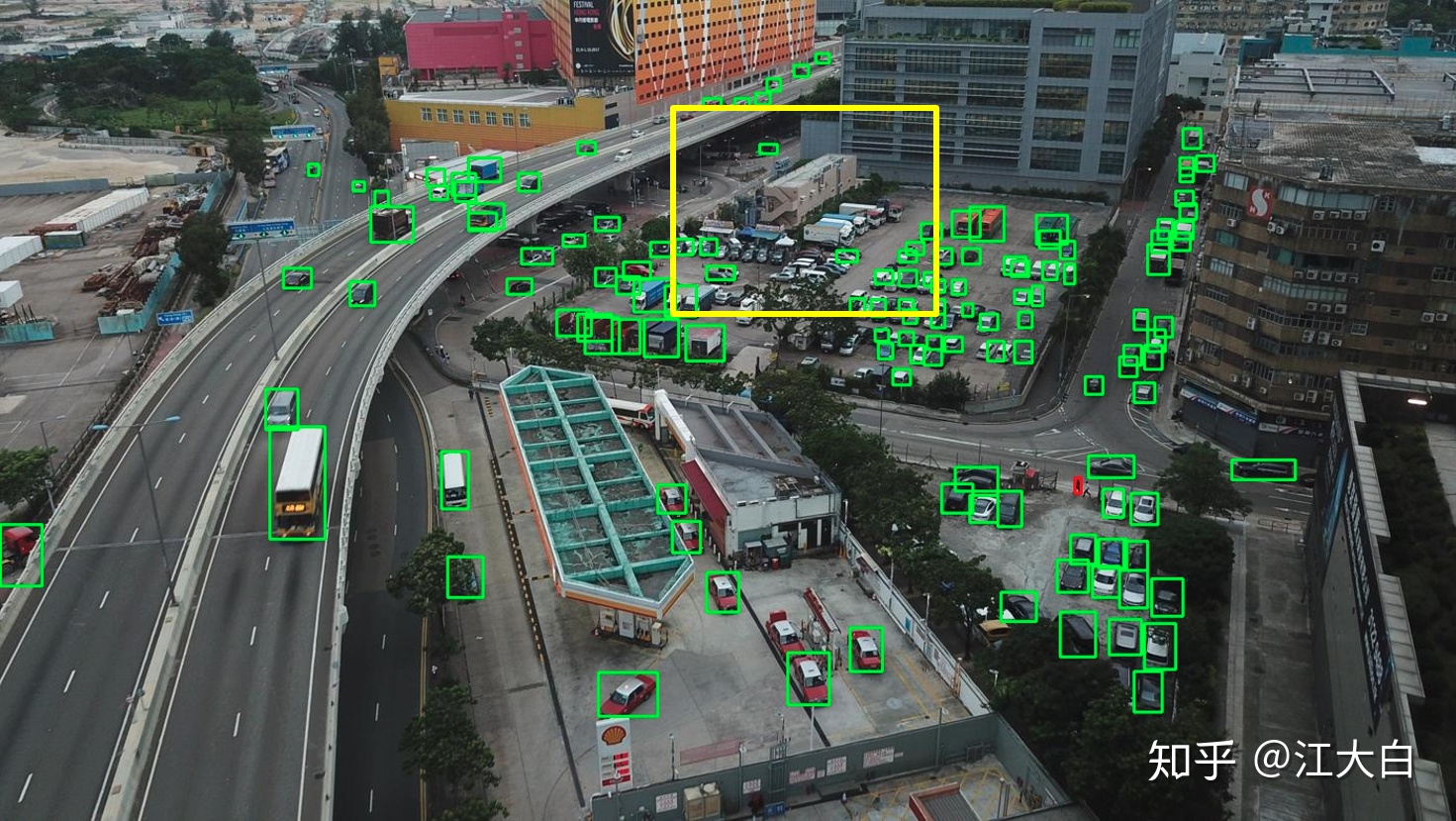
可以看到中間黃色框區域,很多汽車檢測漏掉。
再使用分割的方式,將大圖先分割成小圖,再對每個小圖檢測,可以看出中間區域很多的汽車都被檢測出來:


不過這樣的方式有優點也有缺點:
優點:
(1)準確性
分割後的小圖,再輸入目標檢測網絡中,對於最小目標像素的下限會大大降低。
比如分割成608*608大小,送入輸入圖像大小608*608的網絡中,按照上面的計算方式,原始圖片上,長寬大於8個像素的小目標都可以學習到特徵。
(2)檢測方式
在大分辨率圖像,比如遙感圖像,或者無人機圖像,如果無需考慮實時性的檢測,且對小目標檢測也有需求的項目,可以嘗試此種方式。
缺點:
(1)增加計算量
比如原本7680*2160的圖像,如果使用直接大圖檢測的方式,一次即可檢測完。
但採用分割的方式,切分成N張608*608大小的圖像,再進行N次檢測,會大大增加檢測時間。
借鑑Yolov5的四種網絡方式,我們可以採用儘量輕的網絡,比如Yolov5s網絡結構或者更輕的網絡。
當然Yolov4和Yolov5的網絡各有優勢,我們也可以借鑑Yolov5的設計方式,對Yolov4進行輕量化改造,或者進行剪枝。
5 後語
綜合而言,在實際測試中,Yolov4的準確性有不錯的優勢,但Yolov5的多種網絡結構使用起來更加靈活,我們可以根據不同的項目需求,取長補短,發揮不同檢測網絡的優勢。
希望在人工智能的道路上,和大家共同進步。
