
只要輸入一次心跳的波譜。
就能判斷一個人有沒有發生心力衰竭 (CHF) ,準確率100%。
這是英國華威大學領銜的團隊,用機器學習方法做出的新成果。
還登上了影響因子2.943的Biomedical Signal Processing and Control期刊。
準確率眼看就要突破天際,高得反常識,招來了鋪天蓋地的質疑:
主要的疑點有兩個:疑似過擬合 (沒有規律硬拗出規律) ,疑似數據泄漏 (訓練集和測試集有重疊) 。
一日之間,話題在Reddit論壇的熱度已經超過了400:

那麼,來看看到底發生了什麼。
怎樣的研究
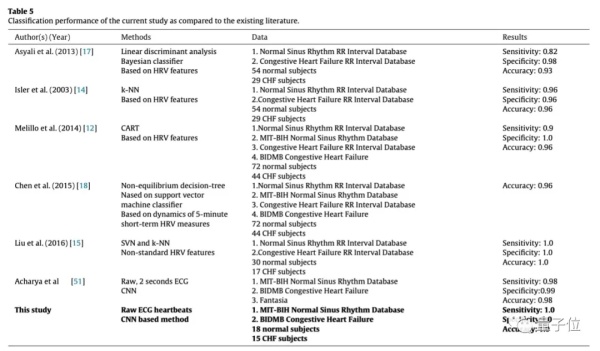
這項研究,是依靠心電圖 (ECG) 來推測,人有沒有出現充血性心力衰竭 (CHF) ,也就是人們常說的心力衰竭:
指的是心臟沒能推送足夠的血量,維持身體所需。
來自華威大學、佛羅倫薩大學以及薩里大學的科學家們,想讓AI去看看心力衰竭的心電圖波形有沒有規律可尋。
於是,團隊設計了一維的卷積神經網絡 (CNN) ,用公開的心電圖數據集,訓練它給心電圖做二分類:正常 vs 心衰。
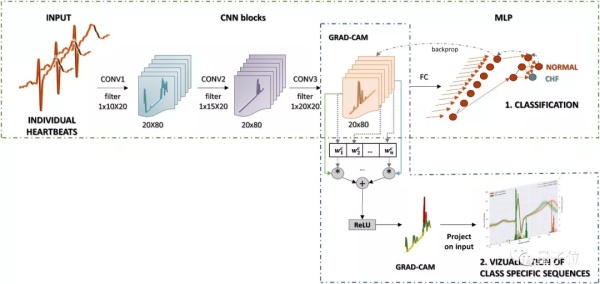
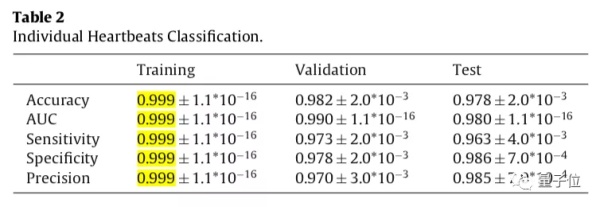
訓練完成後,團隊用490,505次心跳的數據集測試了模型,結果訓練集上的分類準確率達到了99.9%:
論文還寫到,重要的是模型發現了心衰的心電圖,有非常突出的形態特徵可以用於診斷:
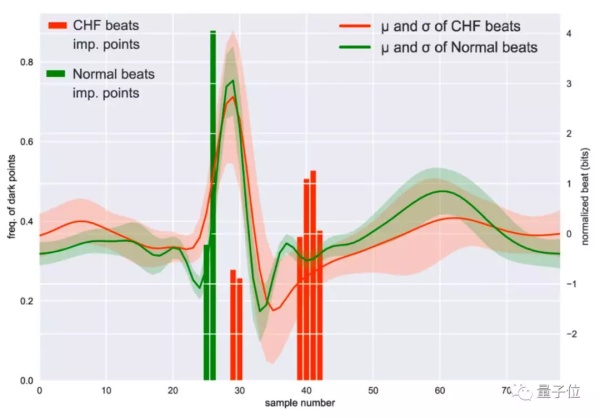
不過,研究用的數據集受到了質疑,準確率受到了質疑,連AI發現的重要特徵也受到了質疑。
實驗的漏洞
乍一看,論文的樣本數量似乎很大,論文作者採集了275,974正常的ECG心跳樣本和214,531個心臟衰竭患者的樣本,總數量達到了49萬個。
但仔細一看,其實樣本的數量是非常少的,總共也只有33個人,一個人多個的心跳不是獨立樣本。
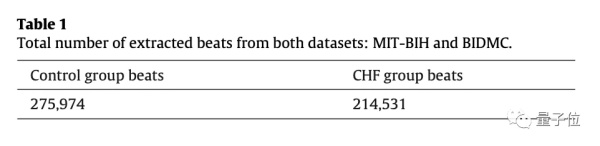
心衰患者的數據來自BIDMC數據集,每秒採樣250個樣本;正常人的數據來自MIT-BIH,每秒採樣128個樣本。
當採用兩個不同數據集時,需要對其中一組數據進行下采樣,匹配另一組數據的頻率。不過研究人員已經注意到這一點,在訓練前做了預處理,大漏洞不在這裏。
但之後的訓練過程,就令人產生了數據泄漏 (Data Leakage) 的質疑。
首先,數據集被隨機分成三個較小的子集,分別進行訓練、驗證和測試(相當於總數據的50%、25%和25%)。
每個人的心跳數據只包含在了一個數據集中,沒有在多個數據集裏重複出現。因爲作者知道,如果一個人的心跳數據,在訓練集和測試集都出現,存在交叉驗證的可能性。

但是這又帶來一個問題,測試集中只有少數幾個人的數據,這就相當於拿訓練後的模型在個別樣本上進行驗證,結果的可靠性也大打折扣。
爲了保證結果在更多的數據上進行測試,作者又想到了另一種方法,將樣本做10次隨機分割,分別進行10次訓練和評估,以減少分類結果帶來的差異性。
雖然一開始的方法避免了單次實驗的交叉驗證,但是多次實驗取平均,等於又把交叉驗證的問題帶了回來,造成了數據泄露(Data Leakage)。
然後,作者一個只有33個樣本的數據上,用了三個1D卷積神經網絡層進行擬合,準確率近乎100%,難免不讓人覺得是過擬合。
在訓練集上避免過擬合,本來是「煉丹」過程的常識,卻被作者作爲一項優點來宣傳。難怪有網友在吐槽:這是一篇門外漢寫的機器學習論文。
100%對於非機器學習領域的人來說是一件令人驚歎的事情,而專業人士看到只會說「什麼鬼」。
這篇論文還被髮表在正式期刊上,有網友感嘆:審稿人的水平哪去了,這個問題看不出來?
另外,Hacker News上還有人 (@Cass) 說,AI總結出的兩類心電圖 (正常vs心衰),根本就有問題:
看圖4 (下圖) ,正常心電圖的「平均」波形,壓根不是這樣。P太平了,Q太大了,R太鈍了,S和T之間也不應該有那個額外的波。
如果,提取的正常人平均值都能這麼混亂,得出怎樣的結果也不奇怪了。
一直被濫用
這篇論文在Reddit上引起了激烈討論。
隨着機器學習大熱,很多其他領域的研究者,也開始用機器學習模型,來執行自己領域的任務。而跨學科的研究人員,如果對機器學習的理解不足,很容易出現大問題。

比如,數據泄漏的問題,讓人想起了去年8月在Nature發表的一篇預測餘震的論文,來自谷歌和哈佛。今年,一位名叫Rajiv Shah的數據科學家用自己的實驗證明,這篇文章是「深度學習的錯誤用法」。
他一共提出了三個致命缺陷:
最大的缺陷就是數據泄漏。算法在測試集上的表現,遠遠超過訓練集。查看數據集發現,測試集和訓練集,包含許多相同的地震。把重疊部分去掉之後,模型的表現下降到了傳統方法的水平。

第二個缺陷是,用隨機森林這樣的簡單方法,也得出了相似的表現和結論。能用簡單的方法,卻用了複雜的方法,這就是消融實驗 (Ablation Studies) 沒做好。
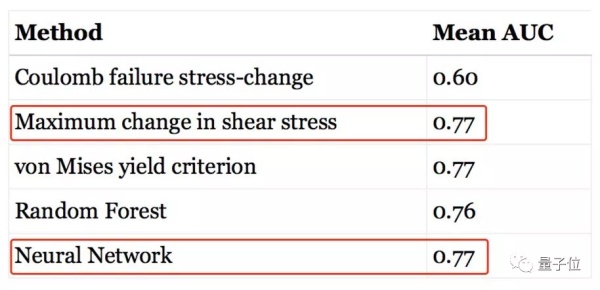
第三個缺陷是,論文中訓練用了470萬行數據,而Shah用1500行數據,就得到了幾乎一樣的表現。Shah認爲,能用少量的數據解決問題,就不該用成千上萬倍的數據量。
這次重大的質疑,引起了業內的巨大關注,甚至有許多同行都來一起找Bug:
10月2日,Nature又刊登了一篇質疑這項餘震預測的論文,證明一個神經元的預測效果比一個六層的網絡還要好,相當於否定了一年前的研究成果。

這篇後發的論文指出,僅使用兩個參數的邏輯迴歸模型,可以達到與深度學習方法相同的預測能力。
機器學習是個好工具,但在使用它們的時候,需要充分了解它的特性、使用方法和侷限性,而不是一味地套用,簡單粗暴地進行數據擬合。
目前機器學習還處在技術曲線的頂峯,等到熱潮褪去,才能知道誰是真正的乾貨。
論文地址:
https://www.sciencedirect.com/science/article/pii/S1746809419301776
— 完 —