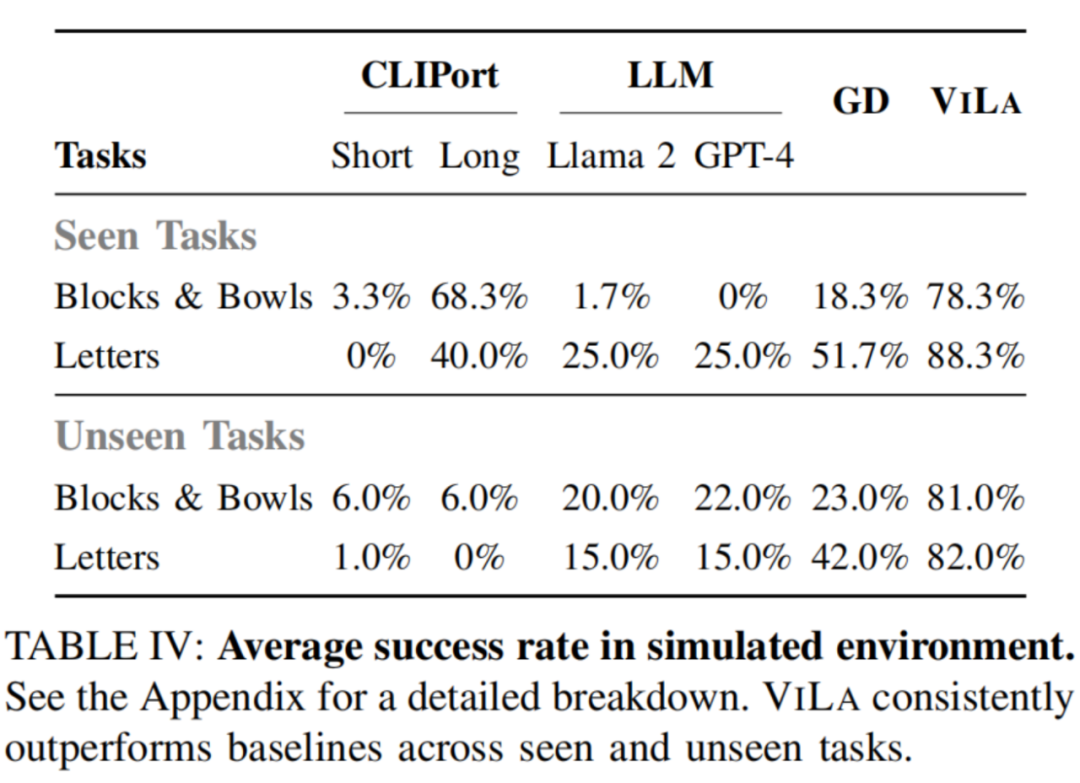
來自清華大學交叉資訊研究院的研究者提出了「ViLa」(全稱 Robotic Vision-Language Planning)演算法,其能在非常複雜的環境中控制機器人,為機器人提供任務規劃。
 【關注
機器之心視訊號,第一時間看到有趣的AI內容】
【關注
機器之心視訊號,第一時間看到有趣的AI內容】




-
論文地址:https://arxiv.org/pdf/2311.17842.pdf -
論文主頁:https://robot-vila.github.io/ -
論文視訊:https://www.youtube.com/watch?v=t8pPZ46xtuc



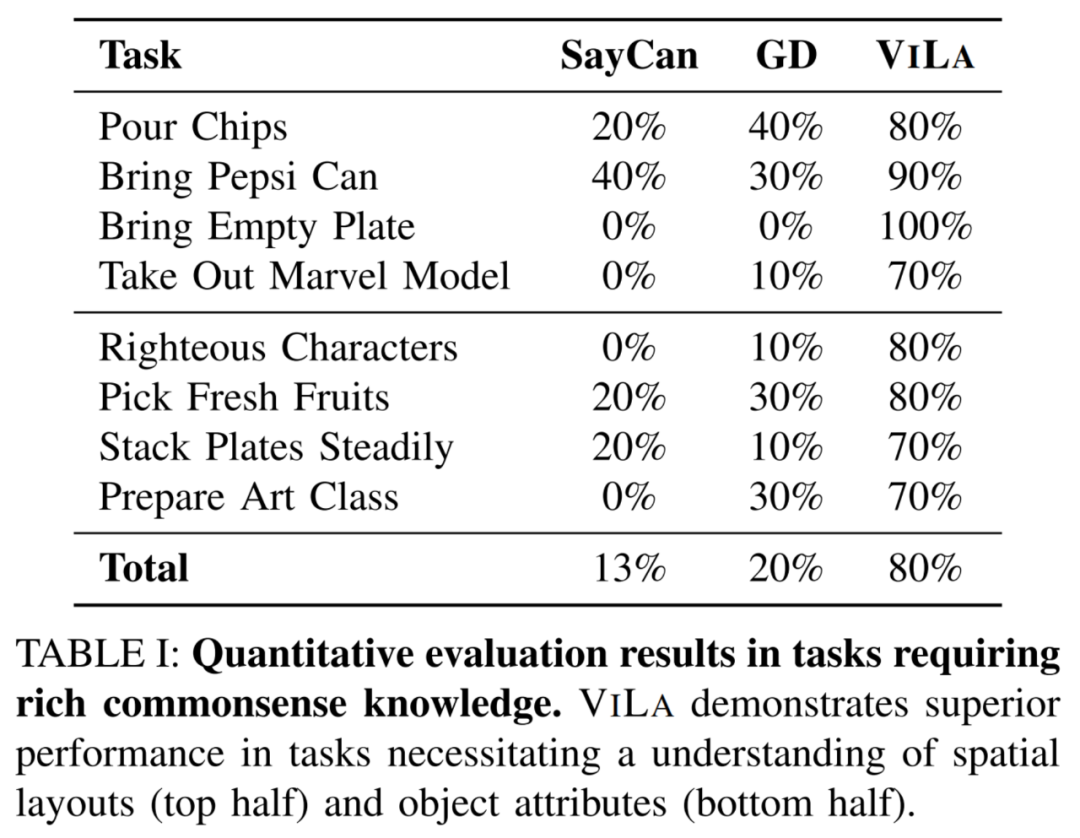

視訊中的四個任務分別表明:
-
ViLa 可以將真實圖片作為目標。 -
ViLa 可以將抽象圖片(如小孩的畫,草稿等)作為目標。 -
ViLa 可以將語言和影象的混合形式作為目標。 -
ViLa 可以發現圖片中手指指著的位置,並將其作為實際任務中的目標位置。
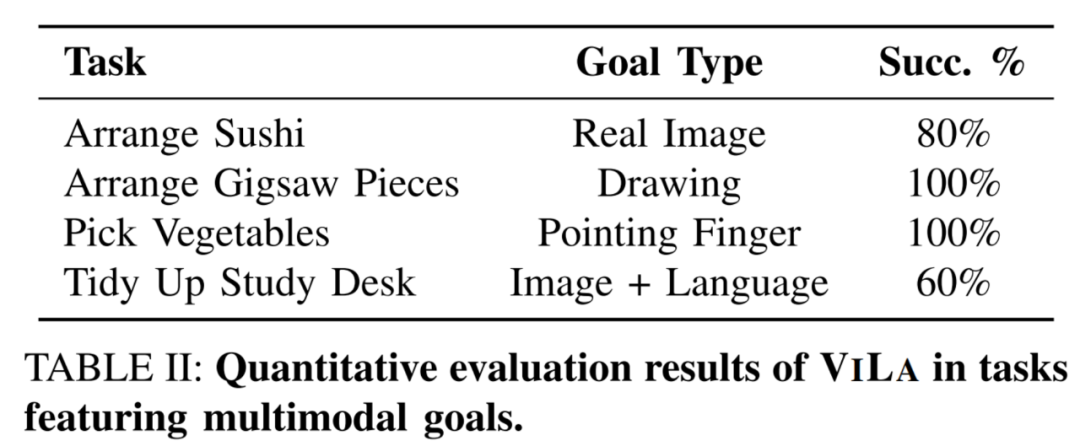

-
在 「堆木塊」 任務中,ViLa 檢測出了執行基本技能時的失敗,於是重新執行了一遍基本技能。 -
在 「放薯片」 任務中,ViLa 意識到了執行過程中人的干擾。 -
在 「找貓糧」 任務中,ViLa 可以不斷地開啟抽屜 / 櫃子來尋找貓糧,直到找到。 -
此外,ViLa 可以完成需要 人機互動的任務,等待人握住可樂罐之後才鬆開夾爪。