今年2月22日,知名的 DarkNet 和 YOLO 系列作者 Joseph Redmon 宣佈退出 CV 界面,這也就意味着 YOLOv3 不會再有官方更新了。但是,CV 領域進步的浪潮仍在滾滾向前,仍然有人在繼續優化 YOLOv3。 今日,著名的AlexeyAB版本發佈了 YOLOv4的論文。該論文提出了五大改進,二十多個技巧的實驗,可以說 YOLOv4是一項非常solid的工作。
本文首發: AIZOO 公衆號
論文題目:YOLOv4: Optimal Speed and Accuracy of Object Detection
論文鏈接:https://arxiv.org/pdf/2004.10934.pdf
開源代碼:https://github.com/AlexeyAB/darknet
首先,看一下作者論文上的效果圖,可以說在平均精度(mAP)和速度上,遠超 YOLOv3版本(文中提到 mAP 提升 10個點,速度提升12%)。
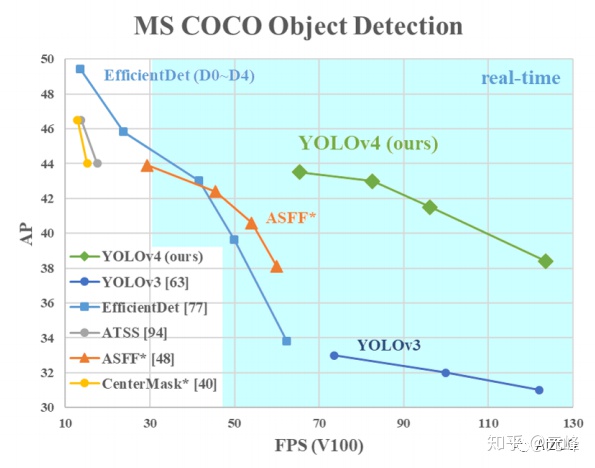
筆者仔細閱讀了該論文,可以說 YOLOv4 是做了很多紮實的(solid)的工作。下面我們首先簡單介紹一下該論文,然後詳細介紹論文提到的五大改進和二十多項最新目標檢測技巧的實驗。
1. 如何看待YOLOv4
目前,工業界常用的目標檢測算法,SSD 是 2015年發表的,RetinaNet、 Mask R-CNN、Cascade R-CNN 是 2017 年發表的,YOLOv3 是2018年發表的。時光荏苒,過去的五年,深度學習也在不斷更新,從激活函數上,到數據增強,到網絡結構,都有大量的創新。而YOLOv4這項工作, 可以說是既往開來。
如果用一個詞來評論這篇論文,那就是「良心」。這篇文章試驗對比了大量的近幾年來最新的深度學習技巧,例如 Swish、Mish激活函數,CutOut和CutMix數據增強方法,DropPath和DropBlock正則化方法,也提出了自己的創新,例如 Mosaic (馬賽克) 和 自對抗訓練數據增強方法,提出了修改版本的 SAM 和 PAN,跨Batch的批歸一化(BN),共五大改進。所以說該文章工作非常紮實,也極具創新。
而且作者也在文中多次強調,這是一個平衡精度和速度的算法,大的模型,例如Mask-RCNN和Cascade R-CNN在比賽中可以霸榜,但速度太慢;小的模型速度快,但精度又不高。另外,當今的不少模型因爲太大,需要很多GPU 進行並行訓練,而 YOLOv4 可以在一塊普通的GPU(1080Ti)上完成訓練,同時能夠達到實時性,從而能夠在生產環境中部署。
2. YOLOv4作者的思考
作者總結的 YOLOv4 三大貢獻:
- 設計了強大而高效的檢測模型,任何人都可以用 1080 Ti 和 2080 Ti訓練這個超快而精準的模型。
- 驗證了很多近幾年 SOTA 的深度學習目標檢測訓練技巧。
- 修改了很多 SOTA 的方法, 讓它們對單GPU訓練更加高效,例如 CBN,PAN,SAM等。
作者總結了近幾年的單階段和雙階段的目標檢測算法以及技巧,並 用一個圖概括了單階段和雙階段目標檢測網絡的差別,two stage的檢測網絡,相當於在one stage的密集檢測上增加了一個稀疏的預測器,或者說one stage網絡是 two stage的 RPN部分,是它的一個特例或子集。
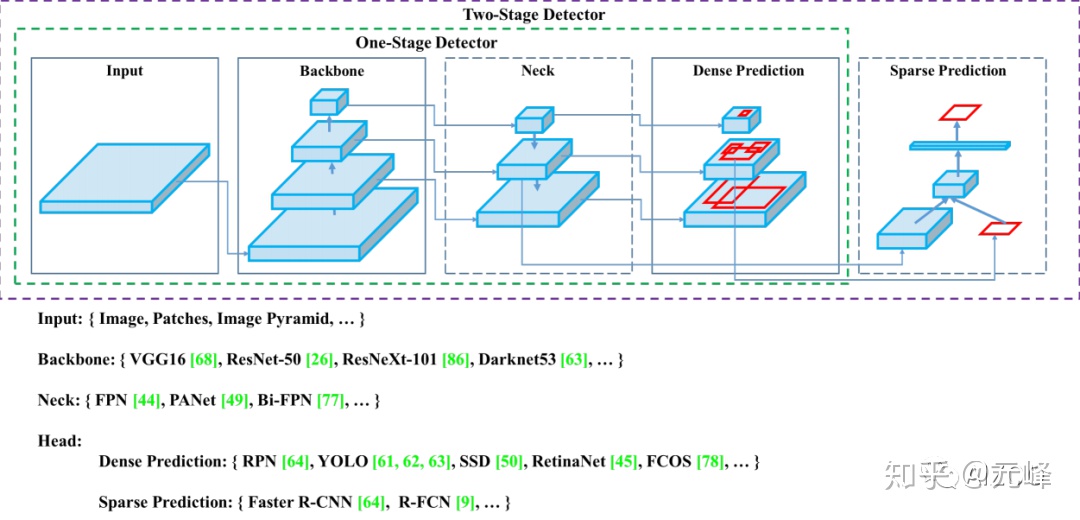
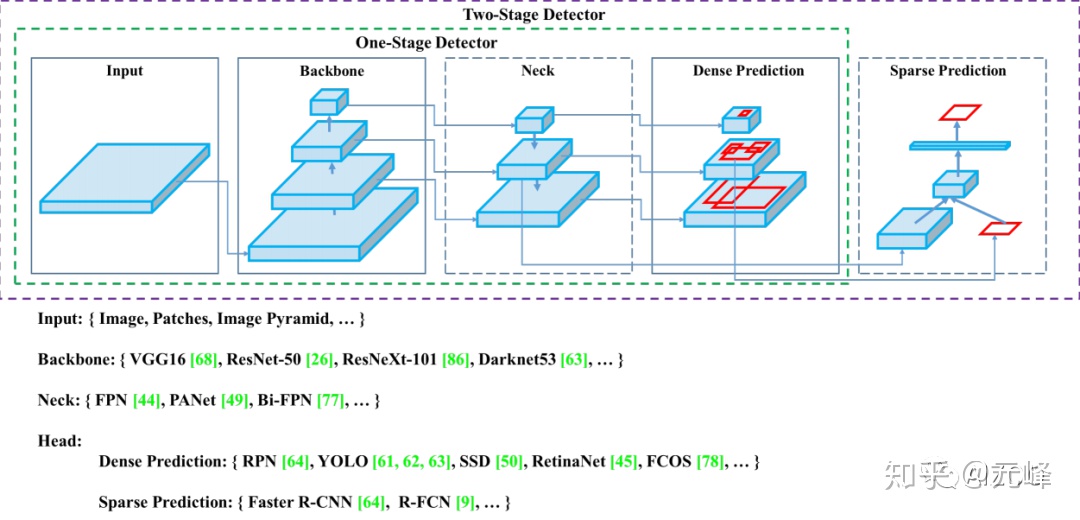
作者將那些增加模型性能,只在訓練階段耗時增多,但不影響推理耗時的技巧稱爲 ——贈品(bag of freebies),也就是白給的提高精度的方法。而那些微微提高了推理耗時,卻顯著提升性能的,叫做——特價(bag of specials),就是那些不免費,但很實惠的技巧。
bag of freebies
以數據增強方法爲例,雖然增加了訓練時間,但可以讓模型泛化性能和魯棒性更好。例如下面的常見增強方法:
- 圖像擾動,
- 改變亮度、對比對、飽和度、色調
- 加噪聲
- 隨機縮放
- 隨機裁剪(random crop)
- 翻轉
- 旋轉
- 隨機擦除(random erase)
- Cutout
- MixUp
- CutMix
下圖是作者在訓練模型時用的圖像增強方法:

另外,還有常見的正則化方法:
- DropOut
- DropConnect
- DropBlock
平衡正負樣本的方法:
- Focal loss
- OHEM(在線難分樣本挖掘)
此外,還有迴歸 loss的改進:
- GIOU
- DIOU
- CIoU
凡此種種,都是訓練時候的改進技巧,不影響推理速度,都可以稱爲贈送品。
bag of specials
特價品是指稍微增加推理的耗時,但是顯著提升性能的技巧。例如增大感受野技巧:
- SPP
- ASPP
- RFB
注意力機制:
- Squeeze-and-Excitation (SE), 增加2%計算量(但推理時有10%的速度),可以提升1%的ImageNet top-1精度。
- Spatial Attention Module (SAM),增加0.1%計算量,提升0.5%的top-1準確率。
特徵融合集成:
- FPN
- SFAM
- ASFF
- BiFPN (也就是大名鼎鼎的EfficientDet)
更好的激活函數:
- ReLU
- LReLU
- PReLU
- ReLU6
- SELU
- Swish
- hard-Swish
後處理非最大值抑制算法:
- soft-NMS
- DIoU NMS
3. YOLOv3模型設計
作者針對 GPU和 VPU 分別使用不同的組卷積策略,GPU 使用 1~8 組卷積, 對VPU則使用完全的組卷積。網絡結構採用的CSPResNeX50和CSPDarknet53。
作者提到,CSPResNeX50分類精度比CSPDarknet,但是檢測性能卻不如後者。
爲了讓模型可以在單個GPU上訓練的的更快,作者使用了以下幾個技巧:
- 獨創的數據增強方法 Mosaic (馬賽克) 和 自對抗訓練(Self Adversarial Training, SAT)
- 使用遺傳算法選擇最優超參數
- 修改版本的 SAM,修改版本的PAN和跨批量歸一化(Cross mini-Batch Normalization)
這個Mosaic,就是把四張圖片拼接爲一張圖片,這等於變相的增大了一次訓練的圖片數量,可以讓最小批數量進一步降低,讓在單GPU上訓練更爲輕鬆。


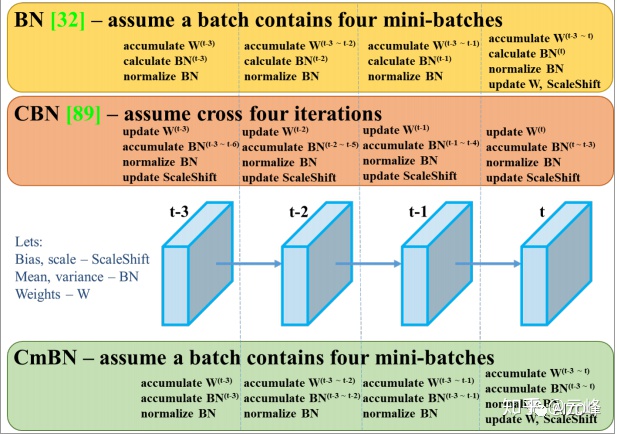
這裏的CmBN,是對CBN的改進,收集一個batch內多個mini-batch內的統計數據。BN, CBN, CmBN的區別如下圖所示:
此外,作者還將 SAM的空間注意力改爲逐點注意力,並將 PAN的快捷連接的相加改爲拼接(concatenation)。
一個完整的YOLOv4 由以下三部分組成:CSPDarknet53 (backbone) + SPP+PAN(Neck,也就是特徵增強模塊)+ YoloV3組成。
另外,YOLOv4使用了「贈送」技巧有CutMix、Mosaic 數據增強, DropBlock正則化,標籤平滑,CIoU-loss,CmBN,自對抗訓練,每個目標分配給多個anchor,(這點和v3有差別,v3版本每個目標只有一個正樣本)。
使用的「特價」技巧:Mish activation、跨階段空間連接 (CSP),多輸入權重殘差連接,SPP-block、SAM-block,PAN,DIoU-NMS。
4. 試驗結果
作者做了大量的對比消融試驗,在分類任務上,在CSPResNeXt50和CSPDarknet53上,使用不同配置的結果對比如下:



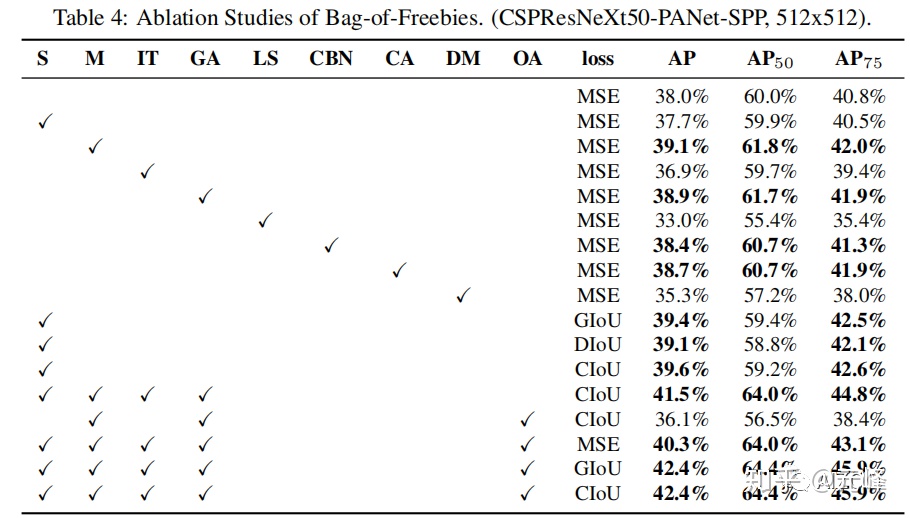
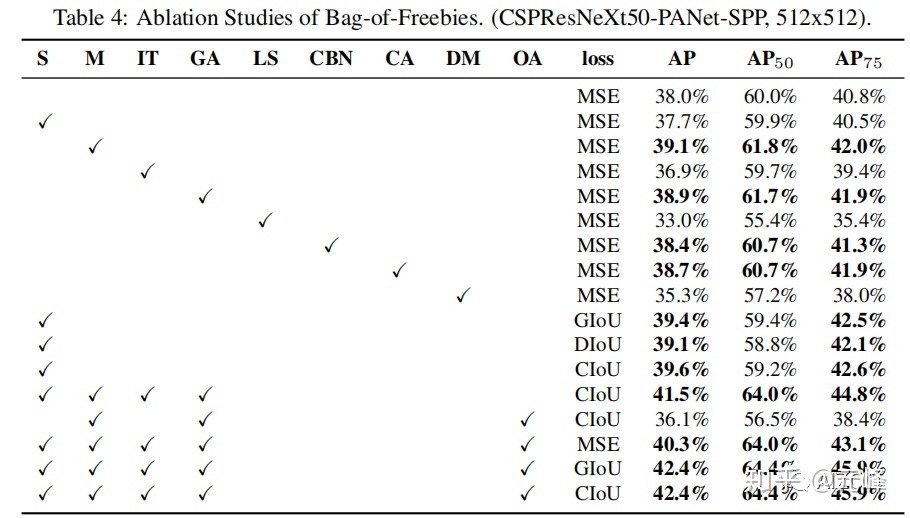
作者使用的多個技巧,在檢測任務上的對比結果如下(這裏需要讀論文對照一下每個符號的含義):
最後,是在Maxwell、Pascal、Volta三個不同系列的GPU,在COCO 數據集上的結果對比:
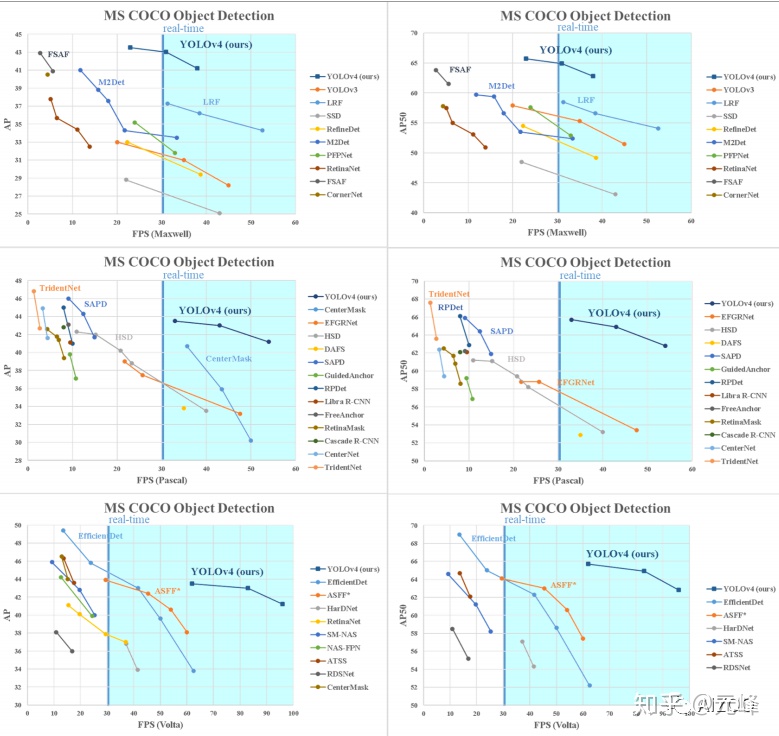
總的來說,YOLOv4是在速度和精度上trade off做的非常好的一項工作。
5. 總結
筆者本來想詳盡的介紹一下本論文,但發現這篇paper信息量太大,難以在一篇博文描述完。可以看出作者是實打實的做了很多近幾年的各種技巧的對比實驗,也做了不少方法的創新改進。可以說這是一篇花了很多功夫和精力的論文。推薦大家讀一下論文,文章寫的真的非常通俗易懂,總結了大量的技巧,甚至可以做爲目標檢測面試寶典。


精彩推薦
AIZOO開源人臉口罩檢測數據+模型+代碼+在線網頁體驗,通通都開源了
新手也能徹底搞懂的目標檢測Anchor是什麼?怎麼科學設置?[附代碼]


