閱讀提示:如果你想讀懂本文,最好對LSTM神經網絡模型的體系結構有一個直觀的瞭解。本文將介紹時間卷積網絡如何朝着序列建模的方向發展——股票趨勢預測。
文章概述
- FTS深度學習背景
- 值得注意的FTS數據預處理實踐
- 時間卷積網絡結構
- 時間卷積網絡在FTS中的應用實例
- 基於TCN的知識驅動股票走勢預測與解釋

1.背景
金融時間序列(FTS)建模是一項有着悠久歷史的實踐,它在20世紀70年代初首次對算法交易產生了革命性的變化。這兩種做法都受到有效市場假說(EMH)的質疑。有效市場假說自1970年首次發表以來一直備受爭議,因爲它假設股票價格是不可預測的。如下所述,這並未限制嘗試通過使用線性、非線性和基於ML的模型對FTS建模的研究。
由於金融時間序列具有非平穩、非線性、高噪聲等特點,傳統的統計模型難以對其進行高精度的預測。因此,儘管還遠遠不夠完善,但近年來還是有越來越多的人嘗試將深度學習應用於股市預測。
2013
《基於SVM的股市趨勢預測方法》:提出了一種利用支持向量機建立兩部分特徵選擇與預測模型的股票預測方法,並證明該方法比傳統方法具有更好的泛化能力。
研究報告:https://ieeexplore.ieee.org/document/6706743
2014
《人工神經網絡模型預測證券市場的股價》:提出了一種利用誤差反向傳播的前饋多層感知器來預測股票價格的人工神經網絡。結果表明,該模型能夠對一個典型的股票市場進行預測。
研究報告:https://arxiv.org/abs/1502.06434
2017
「進入LSTM——有關將LSTM神經網絡應用於時間序列數據的研究激增。
《具有重新定義標籤的時間加權LSTM模型,用於庫存趨勢預測》:在2017 IEEE第29屆人工智能工具國際會議上的LSTM神經網絡中加入時間加權函數,其結果優於其他模型。
2018
《基於注意力機制的長短期記憶神經網絡股價預測》:將卷積神經網絡(CNN)與遞歸神經網絡(RNN)相結合,提出了一種新的結構&深廣域神經網絡(DWNN)。結果表明,與一般RNN模型相比,DWNN模型的預測均方誤差降低了30%。
研究報告:https://journals.plos.org/plosone/article/file?id=10.1371/journal.pone.0227222&type=printable
《預測股票價格指數的波動性:將LSTM與多個GARCH類型模型集成的混合模型》:CNN被用來開發一個定量的選股策略來確定股票的趨勢,然後用LSTM來預測股票價格,從而促進一個混合神經網絡模型的定量擇時策略來增加利潤。
研究報告:https://www.sciencedirect.com/science/article/abs/pii/S0957417418301416
《基於LSTM神經網絡的股票價格預測》:利用LSTM神經網絡和RNN建立模型,發現LSTM可以更好地應用於股票預測。
研究報告:https://link.springer.com/chapter/10.1007/978-3-319-93351-1_32
2019
《基於情緒分析和LSTM的股票收盤價預測》:在模型分析中加入了投資者情緒傾向,並引入了經驗模態分解(EMD)與LSTM相結合的方法來獲得更準確的股票預測。基於注意機制的LSTM模型在語音和圖像識別中比較常見,但在金融領域應用較少。
研究報告:https://link.springer.com/article/10.1007/s00521-019-04504-2?shared-article-renderer
《語言模型是無監督的多任務學習者》:目前最熱門的GPT-3的前身,GPT-2的目標是設計一個多任務學習器,它結合了預訓練和有監督的微調,以實現更靈活的傳輸形式。因此,它具有1542M參數,比其他比較模型大得多。
《基於知識驅動的時間卷積網絡(KDTCN)的股市趨勢預測與解釋方法》:他們首先從財經新聞中提取結構化事件,並利用知識圖獲得事件嵌入。然後,將事件嵌入和價格值結合起來預測股票走勢。實驗證明,這種方法能夠(i)對突變的反應更快,在股票數據集上的表現優於最新的方法。
2020
《基於注意力機制的長短期記憶神經網絡股價預測》:基於近期新聞序列的混合注意力網絡預測股票走勢。具有注意機制的LSTMs由於其獨特的存儲單元結構而避免了長期依賴性,因此優於傳統LSTMs。
研究報告:https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0227222#pone.0227222.ref016
《基於時間卷積注意力的序列建模網絡》:一種結合時間卷積網絡和注意機制的基於時間卷積注意網絡(TCAN)的探索性體系結構。TCAN包括兩部分,一部分是時間注意(TA),它捕捉序列內部的相關特徵;另一部分是增強殘差(ER),它提取淺層的重要信息並傳遞到深層。
研究報告:https://arxiv.org/pdf/2002.12530.pdf
上面的時間軸僅是爲了提供對FTS在深度學習中的歷史背景的一瞥,而不是對其餘時間序列學術界在相似時間段內所做的重要工作輕描淡寫。
但是,在此值得一提的是FTS預測領域的學術出版物可能經常會產生誤導。 由於大量使用模擬器,許多FTS預測報告往往誇大其識別性能,並過度擬合其模型。這些論文中聲稱的許多性能難以複製,因爲它們無法概括所預測的特定FTS的未來變化。
2. FTS值得注意的數據預處理實踐
2.1去噪
金融時間序列數據(尤其是股票價格)會隨着季節、噪聲和自動更正而不斷波動。傳統的預測方法使用移動平均值和微分來減少預測的噪聲。然而,FTS 通常是不穩定的,並且表現出有用信號和噪聲的重疊,這使得傳統的去噪無效。
小波分析在圖像和信號處理等領域取得了令人矚目的成就。由於它具有彌補傅里葉分析缺點的能力,因此已逐漸引入經濟和金融領域。小波變換在解決傳統時間序列分析問題方面具有獨特優勢,因爲它可以分解和重構來自不同時域和頻域範圍的金融時間序列數據。
小波變換本質上使用多尺度特徵對數據集進行降噪,從而有效地將有用信號與噪聲分離。邱佳瑜,王斌,周長軍的論文《基於注意力機制的長短期記憶神經網絡股價預測》中,他們將 coif3 小波函數用於三個分解層,並通過其信噪比(SNR)和均方根誤差(RMSE)來評估小波變換的效果。 )。 SNR 越高,RMSE 越小,小波變換的去噪效果越好:
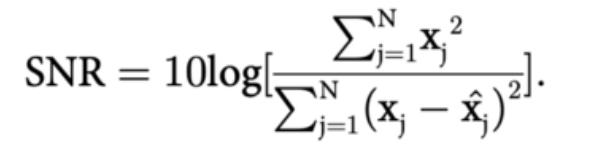
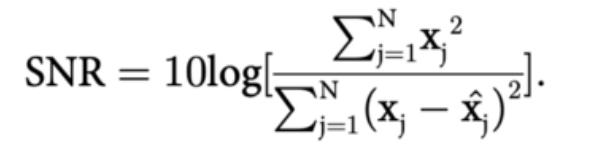
2.2數據洗牌
在FTS中,選擇哪一塊數據作爲驗證集並不是一件小事。事實上,有很多種方法可以做到這一點,對於波動性不同的股指,我們必須仔細考慮。
固定原點法是最樸素和最常用的方法。給定一定的分割大小,數據的開始是訓練集,結束是驗證集。但是,這是一種特別基本的選擇方法,對於像亞馬遜這樣的高增長股票而言尤其如此。之所以會出現這種情況,是因爲亞馬遜的股價一開始波動性很低,而且隨着股價的增長,其波動性也越來越大。
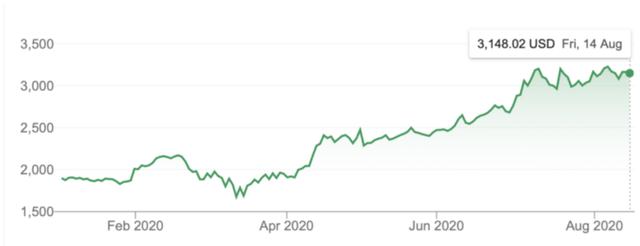
因此,我們需要針對低波動率動態模型進行訓練,該模型需要能夠處理其預測中看不見的高波動率動態模型。這確實表明,這本身是困難的,對這類股票而言,都是以業績爲代價的。因此,僅考慮這一點,我們的驗證損失和性能基準可能會產生誤導。但是,對於像英特爾這樣的波動性較小的股票(COVID危機前),這種方法是合理的。
滾動原點重新校準方法比固定原點的脆弱性稍差一些,因爲它允許通過對數據的各種不同分割進行取平均值來計算驗證損失,從而避免陷入高波動時間框架的不具代表性的問題。
最後,滾動窗口方法是最有用的方法之一,因爲它特別適用於長時間運行的 FTS 算法。實際上,該模型輸出多個滾動數據窗口的平均驗證誤差。這意味着我們獲得的最終值更能代表近期的模型性能,因爲我們在遠古時代對強或弱性能的偏見較少。


由托馬斯·霍利斯(Thomas Hollis),安託萬·維斯卡迪(Antoine Viscardi)和成恩義(Seung Eun Yi)所做的一項研究表明,滾動窗口(RW)和滾動原點重新校準(ROR)都比簡單固定原點法的性能稍好(58%和60%)。這表明,對於亞馬遜這樣的波動性股票,使用這些洗牌方法將是不可避免的。
3.時間卷積網絡(TCN)
時間卷積網絡(簡稱TCN)是卷積神經網絡的一種變體,它通過結合RNN和CNN架構的方面來進行序列建模任務。對TCN的初步經驗評估表明,簡單的卷積體系結構在各種任務和數據集上表現出比常規的遞歸網絡(如LSTM)更好的性能,同時證明了更長的有效內存。
TCN的區別特徵是:
- 體系結構中的卷積是因果關係的,這意味着從過去到將來都不會發生信息「泄漏」。
- 與RNN一樣,該體系結構可以採用任意長度的序列並將其映射到相同長度的輸出序列。 TCN具有非常長的有效歷史記錄大小(即,網絡使用非常深的網絡(帶有殘差層的增強)和擴張的卷積的組合,可以很遠地看過去進行預測)。
3.1模型架構概述
3.1.1因果卷積
如上所述,TCN 基於兩個原則:網絡產生的輸出長度與輸入長度相同,以及從將來到過去不會泄漏的事實。爲了完成第一點,TCN 使用一維全卷積網絡(FCN)架構,其中每個隱藏層的長度與輸入層的長度相同,並且添加了零填充長度(內核大小− 1)以保留後續層與以前的長度相同。爲了達到第二點,TCN 使用因果卷積,即在卷積中,時間t的輸出僅與時間t或更早的上一層中的元素卷積。
簡單地說:TCN = 1D FCN +因果卷積。
3.1.2膨脹卷積
簡單的因果卷積只能回顧網絡深度爲線性的歷史。這使得將上述因果卷積應用於序列任務,尤其是需要較長曆史的任務具有挑戰性。 Bai,Kolter和Koltun(2020)實施的解決方案是採用膨脹卷積,以實現指數級大的接收場。更正式地,對於一維序列輸入 x∈Rⁿ 和濾波器 f:{0,…,k-1}→R,對該序列元素 s 的擴張卷積運算 F 定義爲:
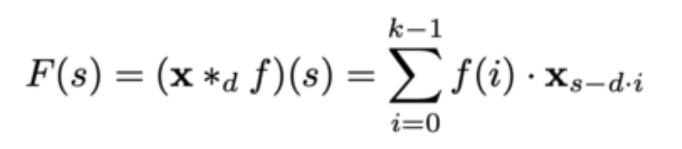
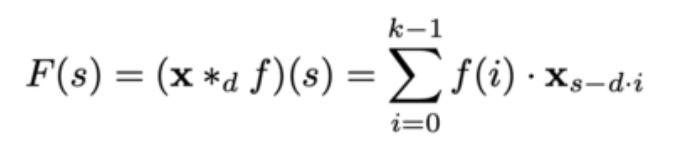
其中 d 是擴張因子,k 是濾波器大小,s-d·i 代表過去的方向。 因此,膨脹等效於在每兩個相鄰的濾波器抽頭之間引入一個固定的階躍。 當 d = 1 時,膨脹卷積減小爲規則卷積。使用較大的膨脹可使頂層的輸出代表更大範圍的輸入,從而有效地擴展了 ConvNet 的接收範圍。
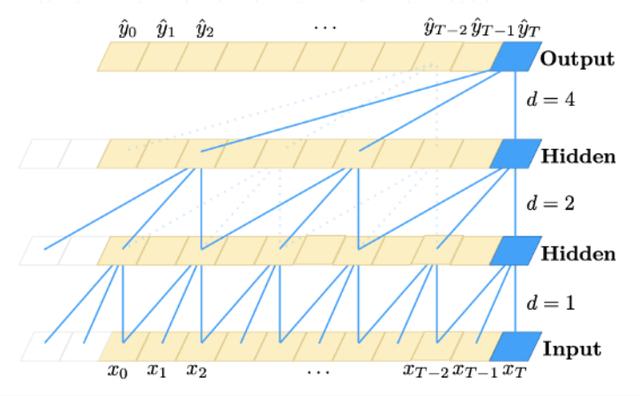
3.1.3殘餘連接
剩餘塊有效地允許層學習對身份映射的修改,而不是整個轉換,這已經被反覆證明有益於非常深層的網絡。
由於TCN的接收場取決於網絡深度 n 以及濾波器的大小 k 和擴散因子 d,因此,更深和更大的TCN的穩定化至關重要。
3.2利弊
使用TCN進行序列建模的幾個優點:
並行性。與RNN中的後繼時間的預測必須等待其前任完成之前的 RNN 不同,卷積可以並行完成,因爲每一層都使用相同的濾波器。因此,在訓練和評估中,可以在 TCN 中整體上處理一個長輸入序列,而不是像 RNN 中那樣順序處理。
靈活的接收場大小。 TCN 可以多種方式更改其接收字段的大小。例如,使用更大的膨脹因子堆疊更多的膨脹(因果)卷積層或增加過濾器尺寸都是可行的選擇。因此,TCN 可以更好地控制模型的內存大小,並且易於適應不同的域。
穩定的漸變。與循環架構不同,TCN 的反向傳播路徑與序列的時間方向不同。因此,TCN 避免了爆炸/消失梯度的問題,這是 RNN 的主要問題(並導致了LSTM和GRU的發展)。
訓練所需的內存較低。尤其是在輸入序列較長的情況下,LSTM 和 GRU 可以輕鬆地消耗大量內存來存儲其多個單元門的部分結果。但是,在 TCN 中,過濾器是跨層共享的,反向傳播路徑僅取決於網絡深度。因此,在實踐中發現,門控 RNN 可能比 TCN 佔用最多層數的內存。
可變長度輸入。就像RNN以循環方式對可變長度的輸入進行建模一樣,TCN 也可以通過滑動一維卷積內核來接受任意長度的輸入。這意味着,對於任意長度的順序數據,可以將 TCN 用作 RNN 的直接替代。
使用TCN的兩個明顯的缺點:
評估期間的數據存儲。TCN需要採用原始序列,直到有效的歷史記錄長度,因此在評估期間可能需要更多的存儲空間。
域轉移的潛在參數更改。不同領域對模型進行預測所需的歷史記錄數量可能有不同的要求。因此,當將模型從僅需要很少內存(即,較小的 k 和 d )的域轉移至需要更長內存(即,較大的 k 和 d )的域時,TCN 可能會因爲沒有足夠大的接收場。
3.3基準
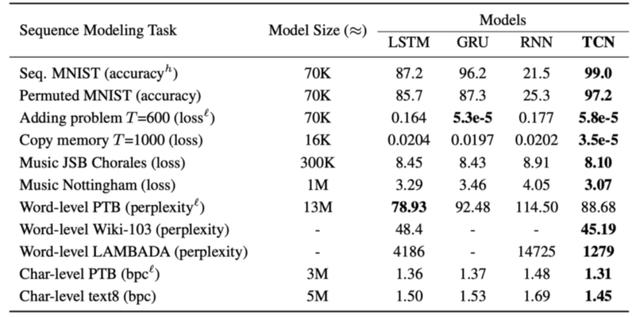
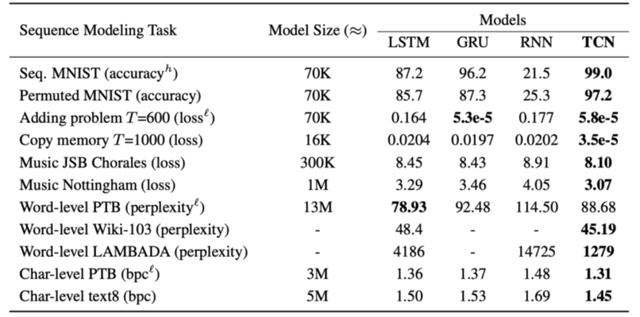
執行摘要:
結果表明,具有最小調優的通用TCN體系結構在廣泛的序列建模任務中優於規範的遞歸體系結構,這些任務通常用於對遞歸體系結構本身的性能進行基準測試。
4.基於TCN的知識驅動股票走勢預測與解釋
4.1背景
大多數股票趨勢預測中的深層神經網絡都有兩個共同的缺點:(i)現有的方法對股票走勢的突變不夠敏感;(ii)預測結果不能爲人類所理解。爲了解決這兩個問題,有人提出了一種新穎的基於知識驅動的時間卷積網絡(KDTCN),將背景知識、新聞事件和價格數據融合到深度預測模型中,解決突變情況下的股市趨勢預測和解釋問題。
爲了解決突變預測問題,將金融新聞中的事件抽取並結構化爲事件元組,例如將「英國退出歐盟」表示爲(英國,退出,歐盟)。然後事件元組中的實體和關係被鏈接到 KG,比如 Freebase 和 Wikidata。其次,將價格信息和文本信息分別連接在一起。最後,將這些嵌入內容輸入到基於TCN的模型中。
實驗表明,KDTCN 能夠(i)更快地對突變做出反應,在股票數據集上的表現優於現有的方法;以及(ii)有助於解釋預測,尤其是在突變情況下。
此外,基於具有突變的預測結果,爲了解決解釋問題,利用知識圖(KG)表示事件之間的聯繫,將事件的影響可視化。通過這樣做,我們可以解釋(i)知識驅動事件如何在不同程度上影響股市波動;(ii)知識如何幫助將事件與股市趨勢預測中的突變聯繫起來。
4.2模型架構概述
這裏提到的基本 TCN 模型體系結構是從上面的第 3 節派生而來的-一種通用的 TCN 體系結構,由因果卷積,殘差連接和膨脹卷積組成。
KDTCN體系結構概述如下所示:
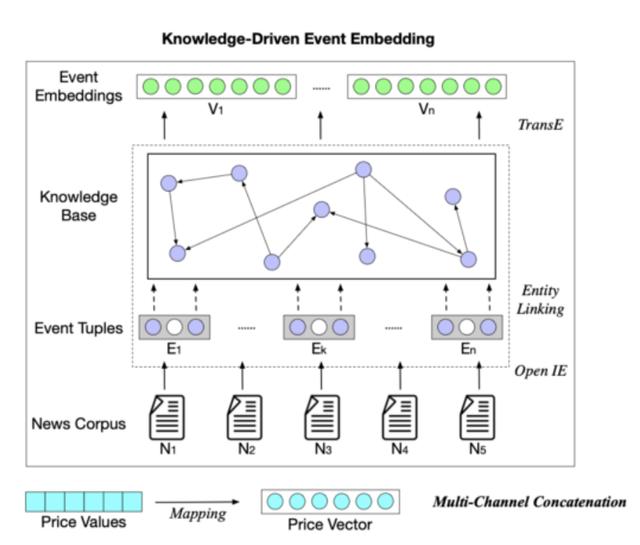
原始模型輸入爲價格值X,新聞語料庫N和知識圖G。價格值經過歸一化並映射到價格向量中,表示爲:
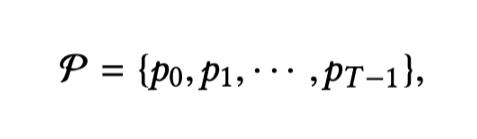
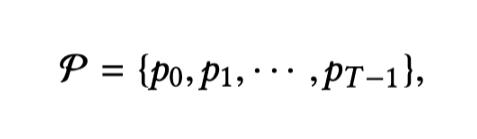
其中每個向量 pt 代表股票交易日 t 上的實時價格向量,而 T 是時間跨度。
對於新聞語料庫,新聞片段表示爲事件集 ε;然後,構造成事件元組 e =(s,p,o),其中 p 是動作/謂詞,s 是參與者/主體,o 是在其上執行動作的對象;然後,將事件元組中的每個項目鏈接到 KG,對應於 KG 中的實體和關係。最後,通過訓練事件元組和 KG 三元組獲得事件嵌入 V。
最後,將事件嵌入與價格向量相結合,輸入到基於 TCN 的模型中。
4.2.1數據集和基準
數據集:
- 時間序列價格數據X:道瓊斯工業指數每日價值記錄的價格數據集
- 文字新聞數據N:由Reddit WorldNews頻道的歷史新聞頭條組成的新聞數據集(根據投票數排名前25位)。
- 結構化知識數據G:從兩個常用的開放式知識圖(Freebase和Wikidata)的結構化數據構建的子圖。
基線:
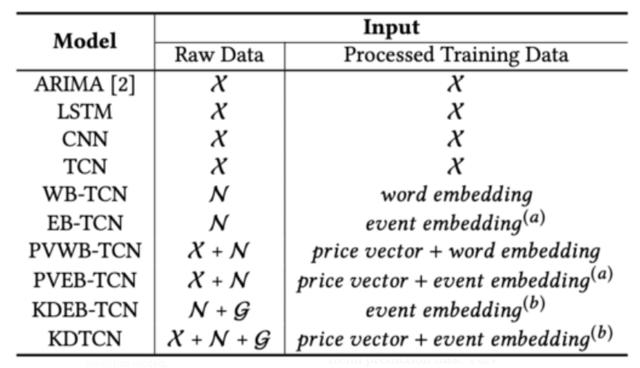
上圖描述:具有不同輸入的基準模型。 在第一列中,前綴WB表示單詞嵌入,EB表示事件嵌入,PV表示價格向量,KD表示知識驅動。 請注意,事件嵌入(a)和事件嵌入(b)分別表示不使用KG和使用KG的事件嵌入。
4.3預測評估
KDTCN的性能從三個方面進行了基準測試:(i)基本TCN體系結構的評估,(ii)不同模型輸入對TCN的影響,以及(iii)基於TCN的突然變化的模型性能。
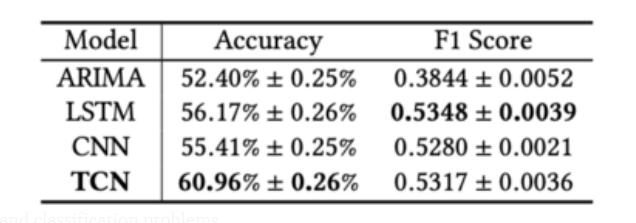
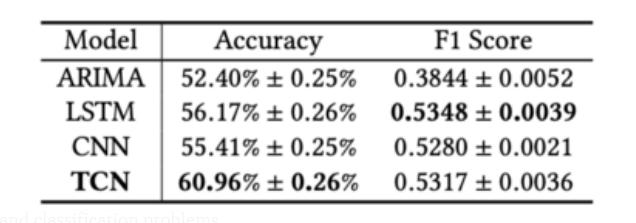
TCN基本架構:
請注意,此部分報告的所有實驗僅輸入價格值。
在股票趨勢預測任務上,TCN大大優於基線模型。與傳統的ML模型(ARIMA)或深度神經網絡(例如LSTM和CNN)相比,TCN的性能要好得多,這表明TCN在序列建模和分類問題上具有更明顯的優勢。
使用TCN的不同模型輸入:
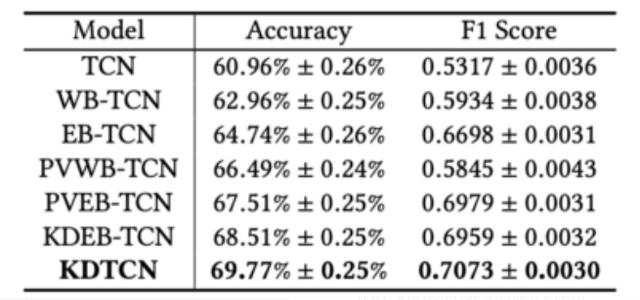
如圖所示,WB-TCN和EB-TCN均比TCN獲得更好的性能,表明文本信息有助於改善預測。
KDTCN獲得最高的準確性和F1分數,並且這樣的結果證明了模型輸入與結構化知識,財務新聞和價格值的集成的有效性。
突變的模型性能:
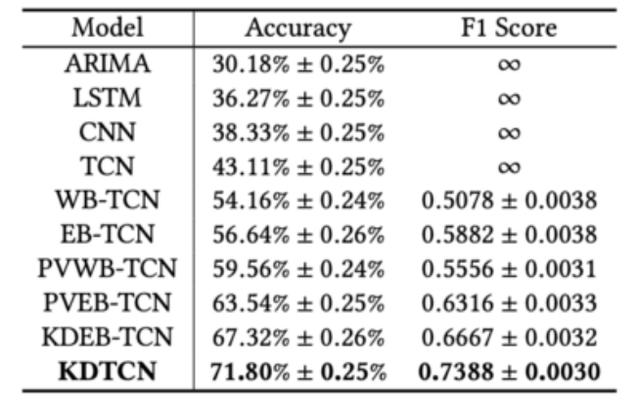
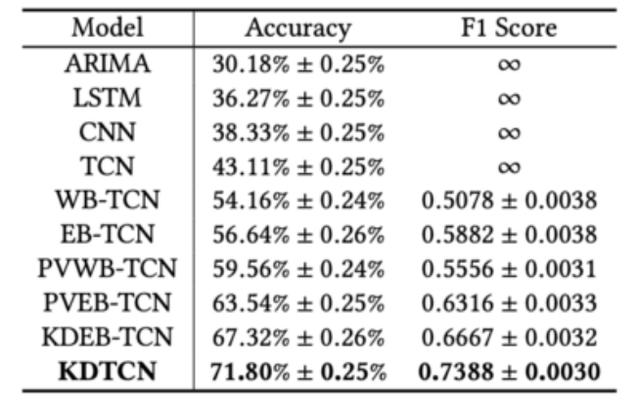
據觀察,具有知識驅動的事件嵌入輸入的模型(例如KDEB-TCN和KDTCN)可以大大優於基於數字數據和基於文本數據的模型。 這些比較結果表明,知識驅動的模型在迅速應對股市的突然變化方面具有優勢。
有關如何量化庫存波動程度的其他說明,請參見下文。
首先,通過計算兩個相鄰股票交易日之間的股票波動度D(波動)的差,得出突變的時間間隔:

其中,時間t處的 x 表示股票交易日 t 的股票價格值。 然後,將波動程度 C 的差定義爲:
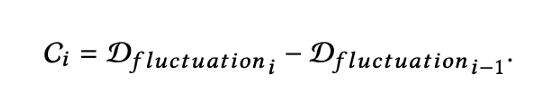
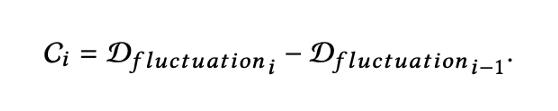
如果| Ci | 超過某個閾值,可以認爲股票價格在第i天突然變化。
4.1.4預測說明
爲何在沒有ML專業知識的情況下,知識驅動事件是導致人類突然變化的常見原因的解釋是從兩個方面完成的:(i)可視化知識驅動事件對具有突然變化的預測結果的影響,以及(ii)檢索知識的背景事實通過將事件鏈接到外部KG來驅動事件。
事件的效果可視化:
下圖的預測結果是 DJIA 指數的趨勢將下降。 請注意,相同顏色的條具有相同的事件效果,條的高度反映了效果的程度,事件受歡迎程度從左到右下降。 從直覺上講,具有較高知名度的事件應在突然變化的情況下對股票趨勢預測產生更大的影響,但並不總是如此。
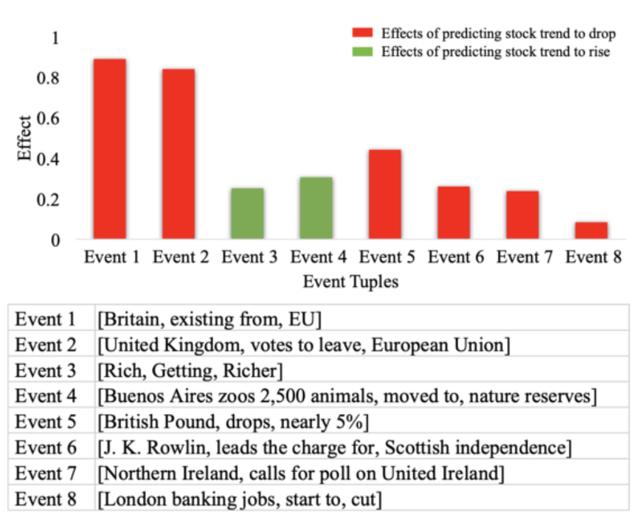
幾乎所有其他具有負面影響的事件都與這兩個事件有關,例如,(英鎊,跌幅接近5%)和(北愛爾蘭,要求對聯合愛爾蘭進行民意調查)。
儘管也有一些事件對預測股票趨勢將產生積極影響,並且具有很高的知名度,即(Rich,Getting,Richer),但總的影響是負面的。 因此,可以將股指波動的突然變化視爲事件的影響和流行的綜合結果。
鏈接到KG的事件元組的可視化:
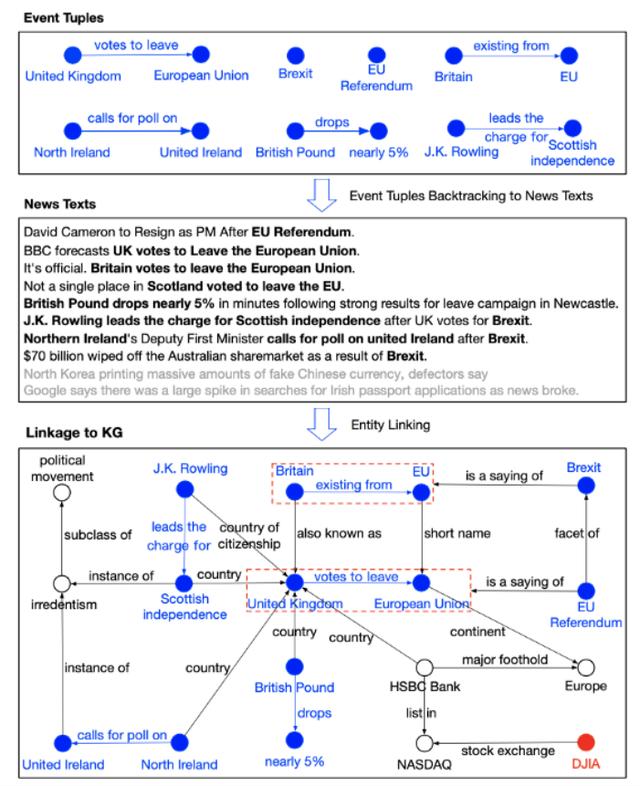
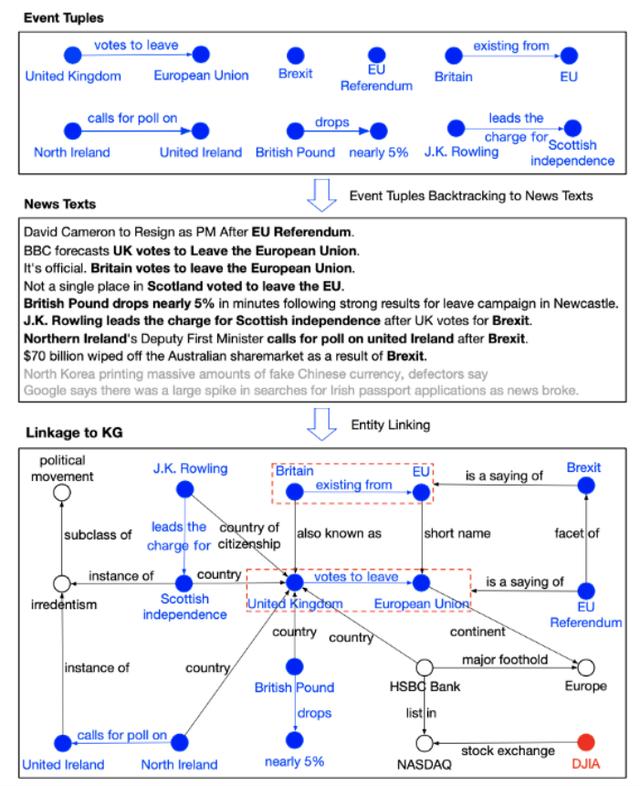
首先,搜索在股票趨勢運動中具有巨大影響或很高知名度的事件元組。 然後,回溯到包含這些事件的新聞文本。 最後,通過實體鏈接檢索關聯到事件元組的關聯的KG三元組。 在上圖中,每個事件元組都標記爲藍色,並且其中的實體鏈接到KG。
這些列出的事件元組,例如(英國,退出歐盟,英國,離開歐盟的票數),(英鎊,跌幅接近5%),(JK羅琳,負責蘇格蘭獨立) )和(北愛爾蘭,呼籲對聯合愛爾蘭進行民意調查)從字面上看並不是很重要。 但是,通過與KG的聯繫,他們可以彼此建立聯繫,並且與英國退歐和歐盟公投事件密切相關。 通過結合事件影響的解釋,可以證明知識驅動的事件是突變的常見來源。
5.結論
循環網絡在序列建模中享有的優勢可能在很大程度上是歷史的遺蹟。 直到最近,在引入諸如卷積卷積和殘差連接之類的體系結構元素之前,卷積體系結構確實還比較弱。 最近的學術研究表明,利用這些元素,簡單的卷積架構在各種序列建模任務中比LSTM等遞歸架構更有效。
此外,從上述TCN在股票趨勢預測中的應用可以看出,通過合併新聞事件和知識圖,TCN可以大大勝過規範RNN。
參考鏈接:
[1]《用於預測財務時間序列的Lstms和注意機制的比較》:https://arxiv.org/abs/1812.07699
[2]《基於注意力機制的長短期記憶神經網絡預測股票價格》:https://doi.org/10.1371/journal.pone.0227222
[3]《通過共同學習對齊和翻譯來進行神經機器翻譯》:https://arxiv.org/abs/1409.0473
[4]《基於通用卷積和遞歸網絡進行序列建模的實證評估》:https://arxiv.org/abs/1803.01271
[6]《知識驅動的趨勢預測和時間卷積網絡解釋》:https://dl.acm.org/doi/10.1145/3308560.3317701
[5]《基於時序卷積注意力的序列建模網絡》:https://arxiv.org/abs/2002.12530
--END--
注:本文非原創,由Bryan Tan發佈於towardsdatascience,
由未艾信息(http://www.weainfo.net)進行翻譯。
原文鏈接:https://towardsdatascience.com/farewell-rnns-welcome-tcns-dd76674707c8
如果你想了解更多人工智能技術,記得關注我們哈~