編輯:Amusi
Date:2020-11-10
來源: CVer微信公衆號
原文: YOLOv5在建築工地中安全帽佩戴檢測的應用(已開源+數據集)
前言
Amusi 發現一個很棒的開源項目,利用YOLOv5進行目標檢測的"落地化"應用:安全帽佩戴檢測。

該項目使用了YOLOv5s、YOLOv5m、YOLOv5l來訓練安全帽佩戴檢測數據集,代碼和權重均已開源!安全帽佩戴檢測數據集也是開源的(共含7581 張圖像)!
項目教程也相當詳細,推薦入門練手學習!而且有意思的是,該項目和數據集的兩位作者均是中國人,點贊!
項目鏈接(文末附下載):https://github.com/PeterH0323/Smart_Construction
數據集鏈接(文末附下載):https://github.com/njvisionpower/Safety-Helmet-Wearing-Dataset
Smart_Construction
該項目是使用 YOLOv5 來訓練在智能工地安全領域中頭盔目標檢測的應用


指標
yolov5s 爲基礎訓練,epoch = 50
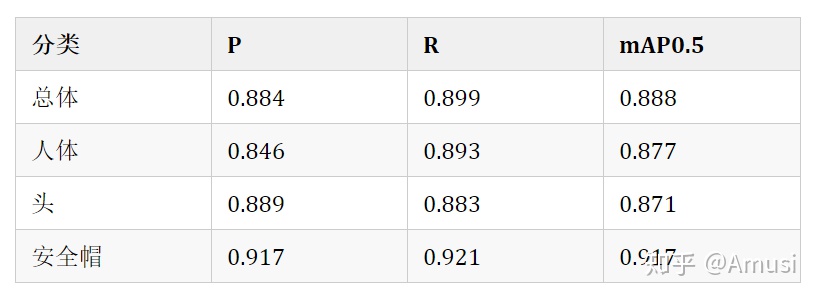
對應的權重文件:百度雲,提取碼: b981
yolov5m 爲基礎訓練,epoch = 100
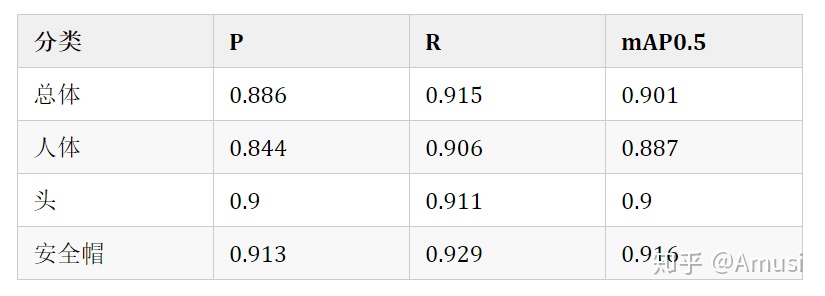
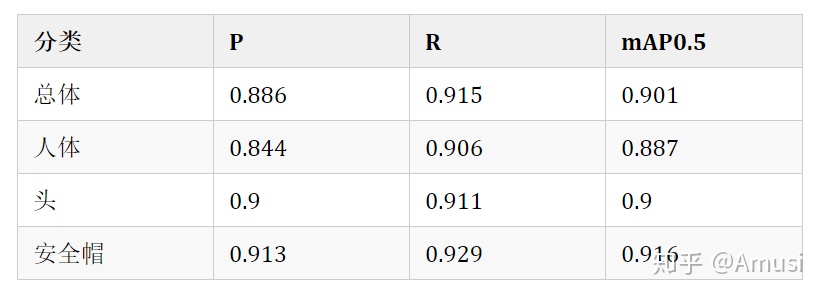
對應的權重文件:百度雲,提取碼: psst
yolov5l 爲基礎訓練,epoch = 100
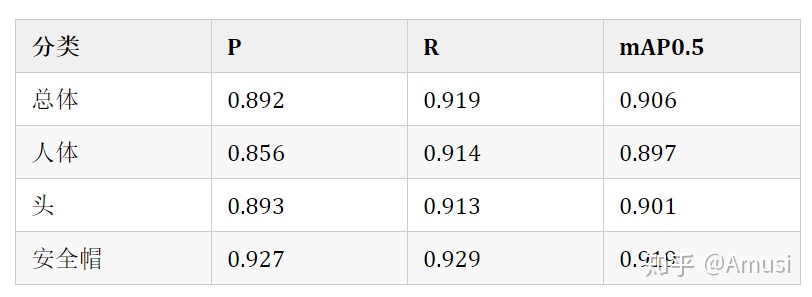
對應的權重文件:百度雲,提取碼: a66e
1.YOLO v5訓練自己數據集教程
使用的數據集:Safety-Helmet-Wearing-Dataset ,感謝這位大神的開源數據集!
本文結合 YOLOv5官方教程 來寫
環境準備
首先確保自己的環境:
Python >= 3.7Pytorch == 1.5.x
訓練自己的數據
提示:
關於增加數據集分類的方法,請看【5. 增加數據集的分類】
1.1 創建自己的數據集配置文件
因爲我這裏只是判斷 【人沒有帶安全帽】、【人有帶安全帽】、【人體】 3個類別 ,基於 data/coco128.yaml 文件,創建自己的數據集配置文件 custom_data.yaml
# 訓練集和驗證集的 labels 和 image 文件的位置train: ./score/images/trainval: ./score/images/val# number of classesnc: 3# class namesnames: ['person', 'head', 'helmet']
1.2 創建每個圖片對應的標籤文件
使用標註工具類似於 Labelbox 、CVAT 、精靈標註助手 標註之後,需要生成每個圖片對應的 .txt 文件,其規範如下:
- 每一行都是一個目標
- 類別序號是零索引開始的(從0開始)
- 每一行的座標
class x_center y_center width height格式 - 框座標必須採用歸一化的 xywh格式(從0到1)。如果您的框以像素爲單位,則將
x_center和width除以圖像寬度,將y_center和height除以圖像高度。代碼如下:
import numpy as npdef convert(size, box): """ 將標註的 xml 文件生成的【左上角x,左上角y,右下角x,右下角y】標註轉換爲yolov5訓練的座標 :param size: 圖片的尺寸: [w,h] :param box: anchor box 的座標 [左上角x,左上角y,右下角x,右下角y,] :return: 轉換後的 [x,y,w,h] """ x1 = int(box[0]) y1 = int(box[1]) x2 = int(box[2]) y2 = int(box[3]) dw = np.float32(1. / int(size[0])) dh = np.float32(1. / int(size[1])) w = x2 - x1 h = y2 - y1 x = x1 + (w / 2) y = y1 + (h / 2) x = x * dw w = w * dw y = y * dh h = h * dh return [x, y, w, h]生成的 .txt 文件放置的名字是圖片的名字,放置在 label 文件夾中,例如:
./score/images/train/00001.jpg # image./score/labels/train/00001.txt # label生成的 .txt 例子:
1 0.1830000086920336 0.1396396430209279 0.13400000636465847 0.159159163013100621 0.5240000248886645 0.29129129834473133 0.0800000037997961 0.168168172240257261 0.6060000287834555 0.29579580295830965 0.08400000398978591 0.17717718146741391 0.6760000321082771 0.25375375989824533 0.10000000474974513 0.213213218376040460 0.39300001866649836 0.2552552614361048 0.17800000845454633 0.28228228911757470 0.7200000341981649 0.5570570705458522 0.25200001196935773 0.42942943982779980 0.7720000366680324 0.2567567629739642 0.1520000072196126 0.23123123683035374
1.3 文件放置規範
文件樹如下
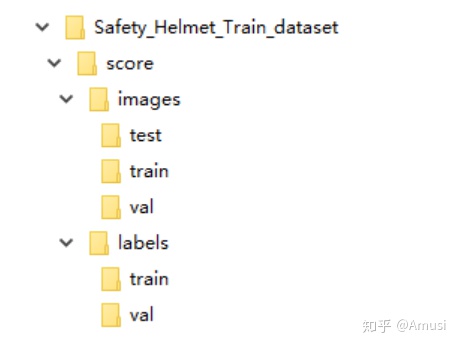
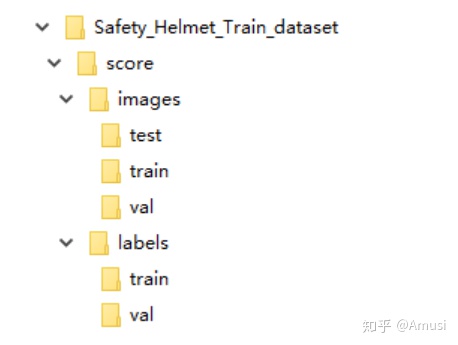
1.4 聚類得出先驗框(可選)
使用代碼 ./data/gen_anchors/clauculate_anchors.py ,修改數據集的路徑
FILE_ROOT = r"xxx" # 根路徑ANNOTATION_ROOT = r"xxx" # 數據集標籤文件夾路徑ANNOTATION_PATH = FILE_ROOT + ANNOTATION_ROOT跑完會生成一個文件 anchors.txt,裏面有得出的建議先驗框:
Best Accuracy = 79.72%Best Anchors = [[14.74, 27.64], [23.48, 46.04], [28.88, 130.0], [39.33, 148.07], [52.62, 186.18], [62.33, 279.11], [85.19, 237.87], [88.0, 360.89], [145.33, 514.67]]
1.5 選擇一個你需要的模型
在文件夾 ./models 下選擇一個你需要的模型然後複製一份出來,將文件開頭的 nc = 修改爲數據集的分類數,下面是借鑑 ./models/yolov5s.yaml來修改的
# parametersnc: 3 # number of classes <============ 修改這裏爲數據集的分類數depth_multiple: 0.33 # model depth multiplewidth_multiple: 0.50 # layer channel multiple# anchorsanchors: # <============ 根據 ./data/gen_anchors/anchors.txt 中的 Best Anchors 修改,需要取整(可選) - [14,27, 23,46, 28,130] - [39,148, 52,186, 62.,279] - [85,237, 88,360, 145,514]# YOLOv5 backbonebackbone: # [from, number, module, args] [[-1, 1, Focus, [64, 3]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, BottleneckCSP, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 9, BottleneckCSP, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, BottleneckCSP, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 1, SPP, [1024, [5, 9, 13]]], [-1, 3, BottleneckCSP, [1024, False]], # 9 ]# YOLOv5 headhead: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, BottleneckCSP, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, BottleneckCSP, [256, False]], # 17 [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, BottleneckCSP, [512, False]], # 20 [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, BottleneckCSP, [1024, False]], # 23 [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
1.6 開始訓練
這裏選擇了 yolov5s 模型進行訓練,權重也是基於 yolov5s.pt 來訓練
python train.py --img 640 --batch 16 --epochs 10 --data ./data/custom_data.yaml --cfg ./models/custom_yolov5.yaml --weights ./weights/yolov5s.pt其中,yolov5s.pt 需要自行下載放在本工程的根目錄即可,下載地址 官方權重
1.7 看訓練之後的結果
訓練之後,權重會保存在 ./runs 文件夾裏面的每個 exp 文件裏面的 weights/best.py ,裏面還可以看到訓練的效果

2. 偵測
偵測圖片會保存在 ./inferenct/output/ 文件夾下
運行命令:
python detect.py --source 0 # webcam file.jpg # image file.mp4 # video path/ # directory path/*.jpg # glob rtsp://170.93.143.139/rtplive/470011e600ef003a004ee33696235daa # rtsp stream http://112.50.243.8/PLTV/88888888/224/3221225900/1.m3u8 # http stream
3. 檢測危險區域內是否有人
3.1 危險區域標註方式
我這裏使用的是 精靈標註助手 標註,生成了對應圖片的 json 文件
3.2 執行偵測
偵測圖片會保存在 ./inferenct/output/ 文件夾下
運行命令:
python area_detect.py --source ./area_dangerous --weights ./weights/helmet_head_person_s.pt
3.3 效果:在危險區域裏面的人體會被 紅色框 選出來



4. 生成 ONNX
4.1 安裝 onnx 庫
pip install onnx
4.2 執行生成
python ./models/export.py --weights ./weights/helmet_head_person_s.pt --img 640 --batch 1onnx 和 torchscript 文件會生成在 ./weights 文件夾中
5. 增加數據集的分類
關於增加數據集分類的方法:
SHWD 數據集裏面沒有 person 的類別,先將現有的自己的數據集執行腳本生成 yolov5 需要的標籤文件 .txt,之後再用 yolov5x.pt 加上 yolov5x.yaml ,使用指令檢測出人體
python detect.py --save-txt --source ./自己數據集的文件目錄 --weights ./weights/yolov5x.ptyolov5 會推理出所有的分類,並在 inference/output 中生成對應圖片的 .txt 標籤文件;
修改 ./data/gen_data/merge_data.py 中的自己數據集標籤所在的路徑,執行這個python腳本,會進行 person 類型的合併
歡迎 star ✨✨✨
項目開源鏈接:https://github.com/PeterH0323/Smart_Construction
CVer-目標檢測交流羣
建了目標檢測微信羣,目前近450人。想要進檢測羣的同學,可以直接加微信號:CVer5555。加的時候備註一下:目標檢測+學校+暱稱,即可。然後就可以拉你進羣了。可以在羣裏交流討論2D/3D目標檢測、遙感/水下目標檢測等方向。
另外強烈推薦閱讀,Amusi 整理過的最全資料系列如下:
- GitHub:深度學習最全資料集錦
- GitHub:圖像分類最全資料集錦
- GitHub:目標檢測最全論文集錦
- GitHub:圖像分割最全資料集錦
- GitHub:目標跟蹤最全資料集錦
- GitHub:人羣密度估計最全資料集錦
- GitHub:車道線檢測最全資料集錦
- GitHub:TensorFlow最全資料集錦
- GitHub:Anchor-free目標檢測最全資料集錦
- GitHub:數據增廣最全資料集錦
- GitHub:語義分割最全資料集錦
- GitHub:人羣計數最全資料集錦
推薦大家關注計算機視覺論文速遞知乎專欄和CVer微信公衆號,可以快速瞭解到最新優質的CV論文。
推薦閱讀
CVPR 引用量最高的10篇論文!何愷明ResNet登頂,YOLO佔據兩席!
ICCV 引用量最高的10篇論文!何愷明兩篇一作論文:Mask R-CNN和PReLU
ECCV 引用量最高的10篇論文!SSD登頂!何愷明ResNet改進版位居第二
OpenCV4.4剛剛發佈!支持YOLOv4、EfficientDet檢測模型,SIFT移至主庫!
目標檢測四大開源神器Detectron2/mmDetection/darknet/SimpleDet
ECCV 2020 放榜!一文看盡10篇論文的開源項目(檢測/GAN/SR等方向)
ResNet最強改進版來了!ResNeSt:Split-Attention Networks