YOLO之父Joseph Redmon在今年年初宣佈退出計算機視覺的研究的時候,很多人都以爲目標檢測神器YOLO系列就此終結。然而在4月23日,繼任者YOLO V4卻悄無聲息地來了。Alexey Bochkovskiy發表了一篇名爲YOLOV4: Optimal Speed and Accuracy of Object Detection的文章。YOLO V4是YOLO系列一個重大的更新,其在COCO數據集上的平均精度(AP)和幀率精度(FPS)分別提高了10% 和12%,並得到了Joseph Redmon的官方認可,被認爲是當前最強的實時對象檢測模型之一。
正當計算機視覺的從業者們正在努力研究YOLO V4的時候,萬萬沒想到,有牛人不服。6月25日,Ultralytics發佈了YOLOV5 的第一個正式版本,其性能與YOLO V4不相伯仲,同樣也是現今最先進的對象檢測技術,並在推理速度上是目前最強。
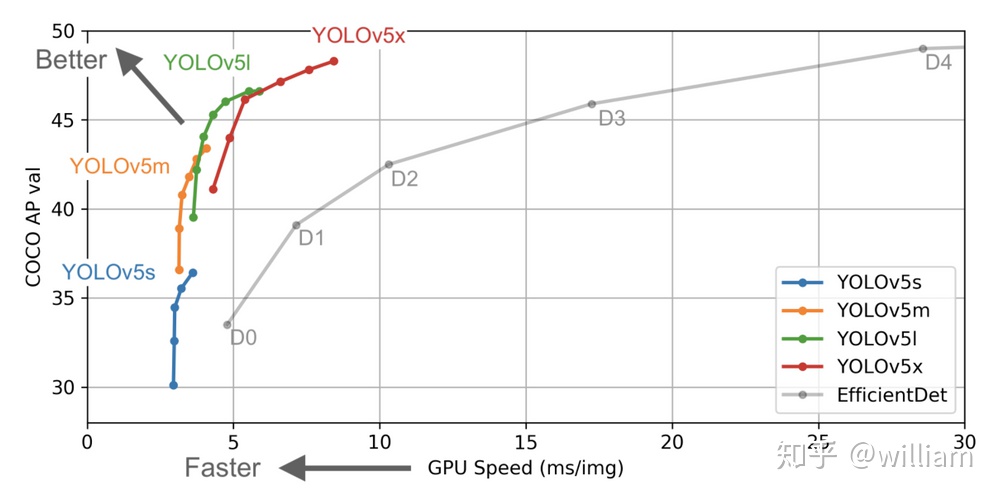
從上圖的結果可以看出,YOLO V5確實在對象檢測方面的表現非常出色,尤其是YOLO V5s 模型140FPS的推理速度非常驚豔。
YOLO V5和V4集中出現讓很多人都感到疑惑,一是YOLO V5真的有資格能被稱作新一代YOLO嗎?二是YOLO V5的性能與V4相比究竟如何,兩者有啥區別及相似之處?
在本文中我會詳細介紹YOLO V5和YOLO V4的原理,技術區別及相似之處,最後會從多方面對比兩者的性能。
Email: williamhyin@outlook.com
知乎專欄: 自動駕駛全棧工程師
我在我之前的文章中介紹了YOLO V3模型,YOLO是一種快速緊湊的開源對象檢測模型,與其它網絡相比,同等尺寸下性能更強,並且具有很不錯的穩定性,是第一個可以預測對象的類別和邊界框的端對端神經網絡。
YOLO V3原始模型是基於Darknet網絡。Ultralytics將YOLO V3架構遷移到了Pytorch平臺上,並對其自行研究和改進。Ultralytics-yolov3 代碼庫是目前已開源YOLO V3 Pytorch的最佳實現。
YOLO網絡主要由三個主要組件組成。
1)Backbone -在不同圖像細粒度上聚合並形成圖像特徵的卷積神經網絡。
2)Neck:一系列混合和組合圖像特徵的網絡層,並將圖像特徵傳遞到預測層。
3)Head: 對圖像特徵進行預測,生成邊界框和並預測類別。
下圖是對象檢測網絡的通用架構:
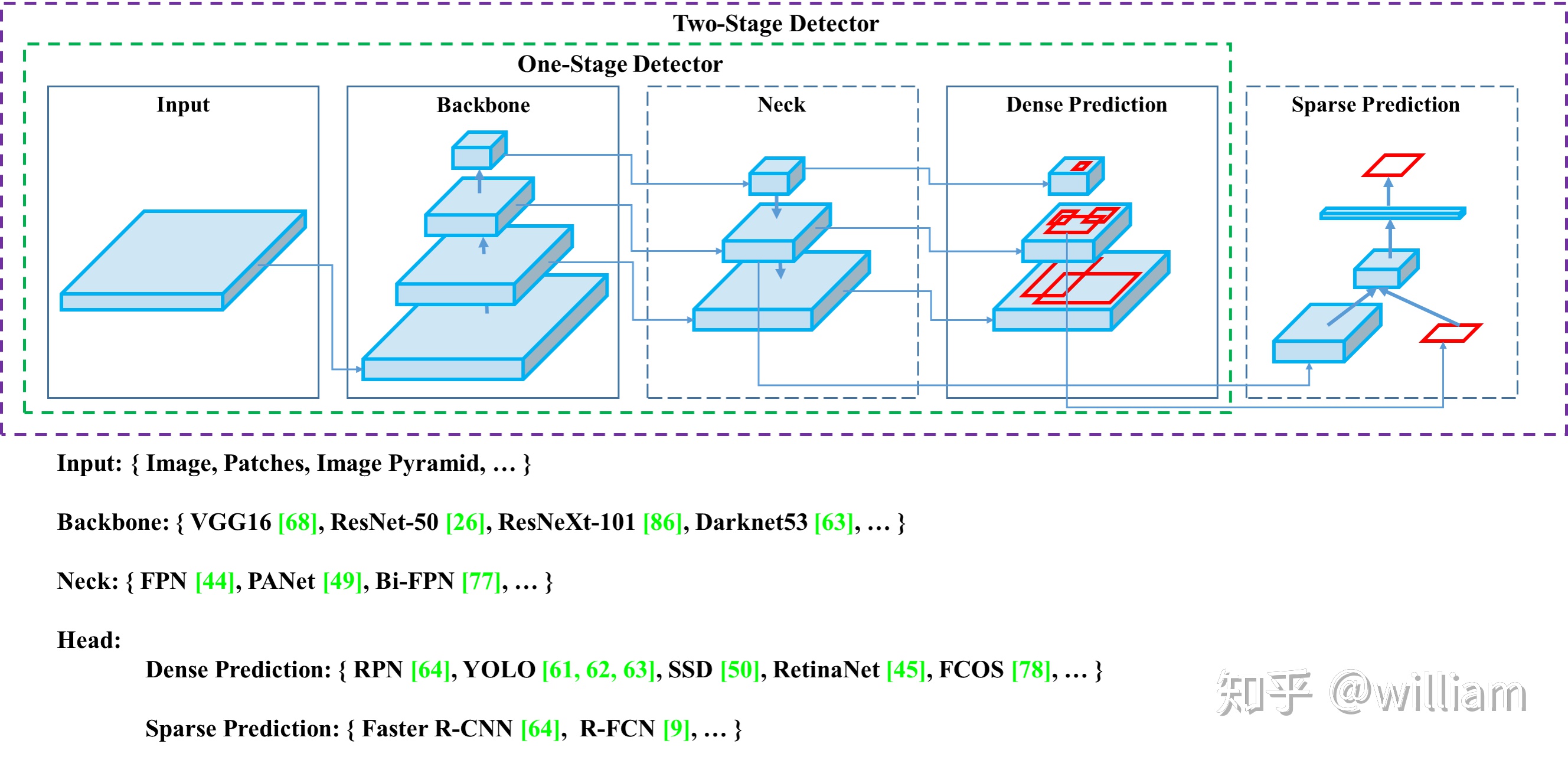
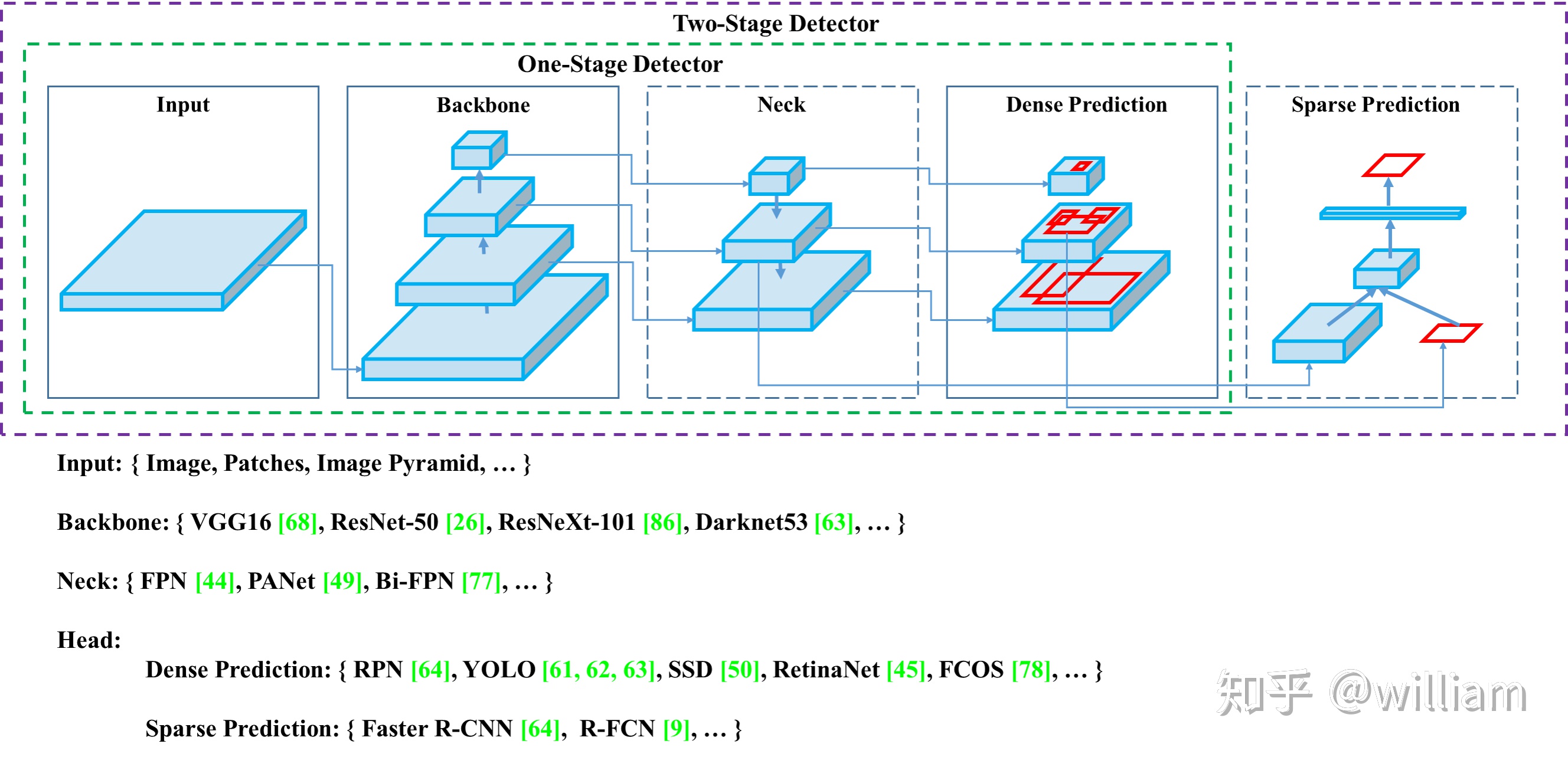
我們可以在上述每個主要組件上使用不同的技術或者組合不同的方案來實現屬於自己的最佳對象檢測框架。
實際上YOLO V5的模型架構是與V4非常相近的。在下文中,我會從下面幾個方面對比YOLO V5和V4,並簡要闡述它們各自新技術的特點,對比兩者的區別和相似之處,評判兩者的性能,並做最後總結。
- Data Augmentation
- Auto Learning Bounding Box Anchors
- Backbone
- Network Architecture
- Neck
- Head
- Activation Function
- Optimization Function
- Benchmarks
Data Augmentation
圖像增強是從現有的訓練數據中創建新的訓練樣本。我們不可能爲每一個現實世界場景捕捉一個圖像,因此我們需要調整現有的訓練數據以推廣到其他情況,從而允許模型適應更廣泛的情況。無論是YOLO V5還是V4,多樣化的先進數據增強技術是最大限度地利用數據集,使對象檢測框架取得性能突破的關鍵。通過一系列圖像增強技術步驟,可以在不增加推理時延的情況下提高模型的性能。
YOLO V4數據增強

YOLO V4使用了上圖中多種數據增強技術的組合,對於單一圖片,除了經典的幾何畸變與光照畸變外,還創新地使用了圖像遮擋(Random Erase,Cutout,Hide and Seek,Grid Mask ,MixUp)技術,對於多圖組合,作者混合使用了CutMix與Mosaic 技術。除此之外,作者還使用了Self-Adversarial Training (SAT)來進行數據增強。
在下文中我將簡單介紹以上數據增強技術。
圖像遮擋
- Random Erase:用隨機值或訓練集的平均像素值替換圖像的區域。


- Cutout: 僅對 CNN 第一層的輸入使用剪切方塊Mask。

- Hide and Seek:將圖像分割成一個由 SxS 圖像補丁組成的網格,根據概率設置隨機隱藏一些補丁,從而讓模型學習整個對象的樣子,而不是單獨一塊,比如不單獨依賴動物的臉做識別。
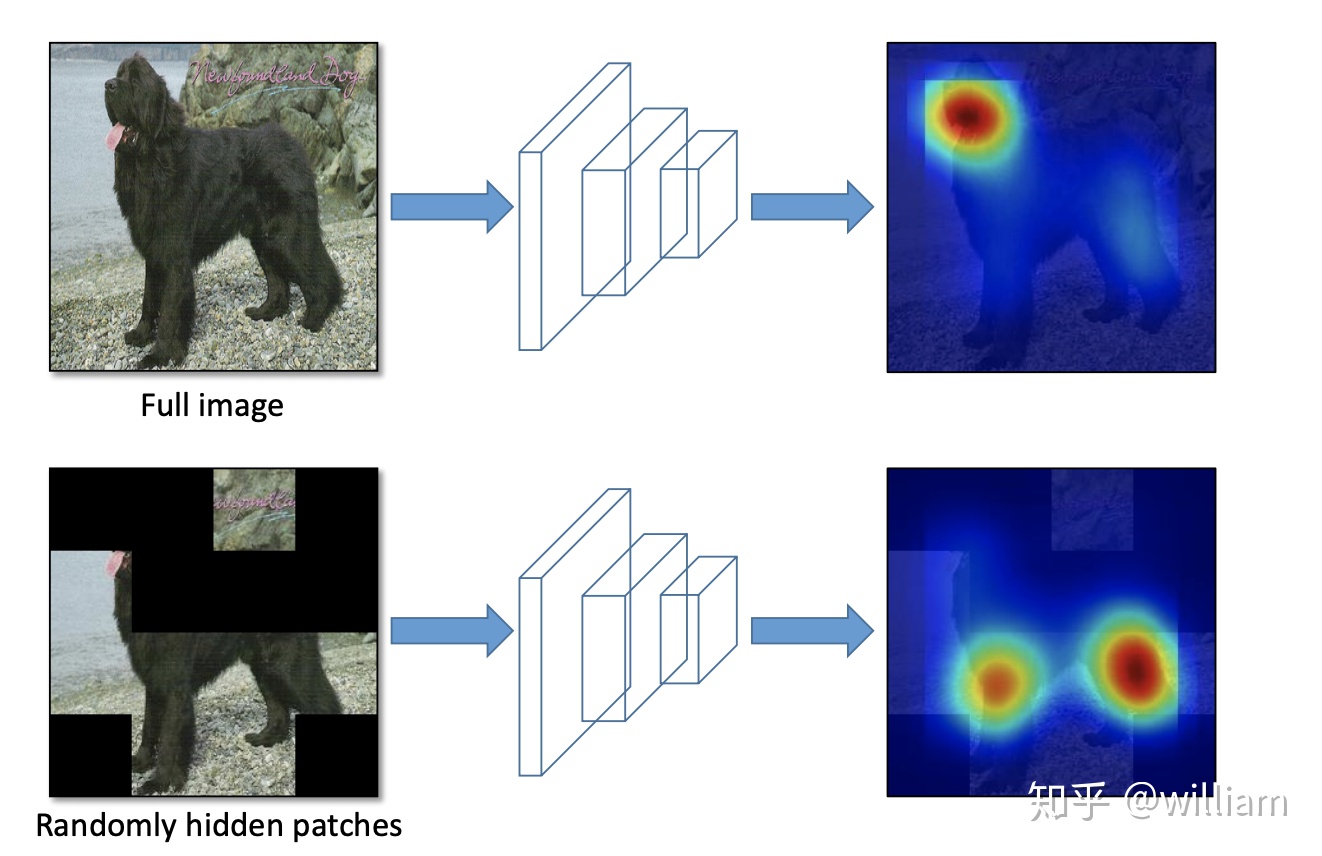
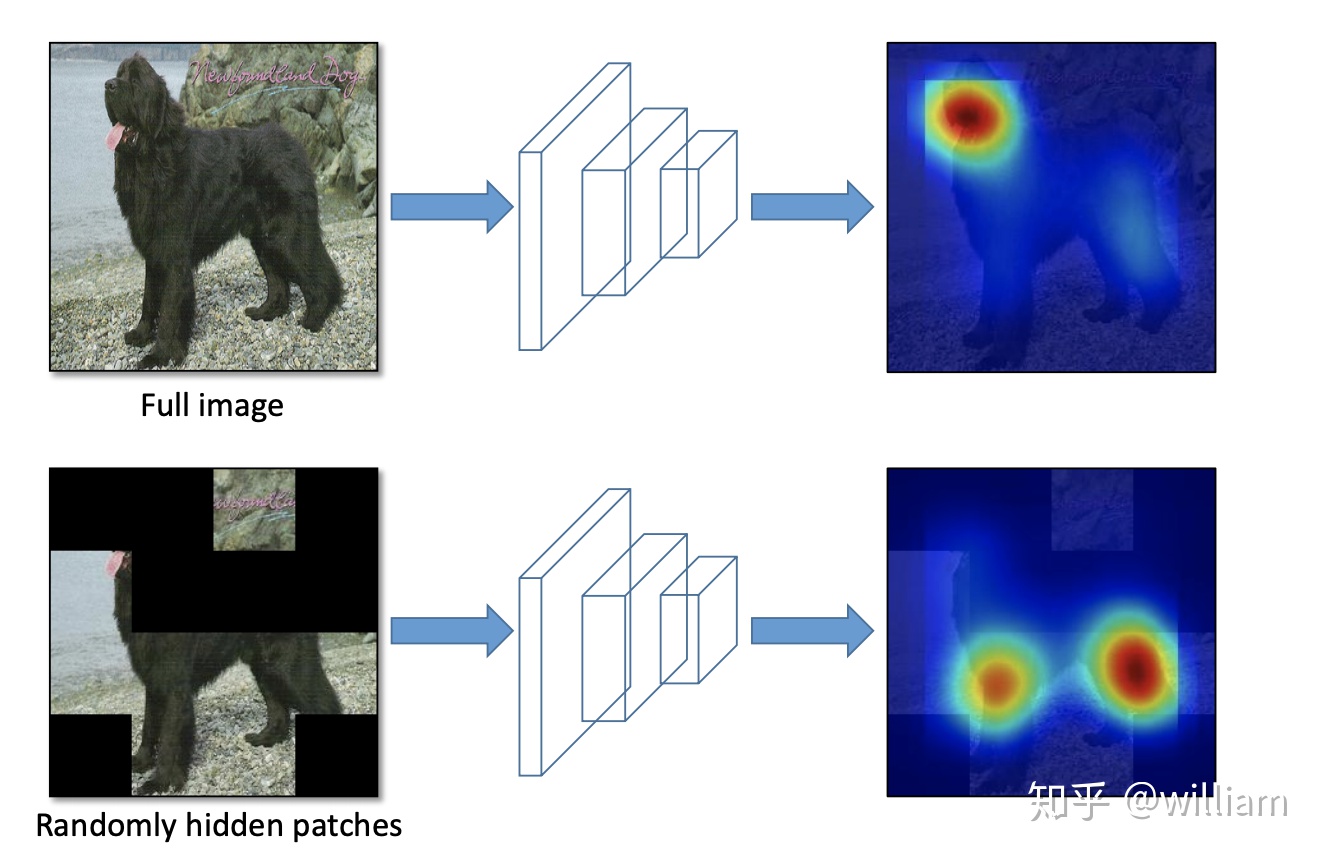
- Grid Mask:將圖像的區域隱藏在網格中,作用也是爲了讓模型學習對象的整個組成部分。

- MixUp:圖像對及其標籤的凸面疊加。

多圖組合
Cutmix:
- 將另一個圖像中的剪切部分粘貼到增強圖像。圖像的剪切迫使模型學會根據大量的特徵進行預測。

Mosaic data augmentation:
- 在Cutmix中我們組合了兩張圖像,而在 Mosaic 中我們使用四張訓練圖像按一定比例組合成一張圖像,使模型學會在更小的範圍內識別對象。其次還有助於顯著減少對batch-size的需求,畢竟大多數人的GPU顯存有限。


自對抗訓練(SAT)
- Self-Adversarial Training是在一定程度上抵抗對抗攻擊的數據增強技術。CNN計算出Loss, 然後通過反向傳播改變圖片信息,形成圖片上沒有目標的假象,然後對修改後的圖像進行正常的目標檢測。需要注意的是在SAT的反向傳播的過程中,是不需要改變網絡權值的。
使用對抗生成可以改善學習的決策邊界中的薄弱環節,提高模型的魯棒性。因此這種數據增強方式被越來越多的對象檢測框架運用。
類標籤平滑
Class label smoothing是一種正則化方法。如果神經網絡過度擬合和/或過度自信,我們都可以嘗試平滑標籤。也就是說在訓練時標籤可能存在錯誤,而我們可能「過分」相信訓練樣本的標籤,並且在某種程度上沒有審視了其他預測的複雜性。因此爲了避免過度相信,更合理的做法是對類標籤表示進行編碼,以便在一定程度上對不確定性進行評估。YOLO V4使用了類平滑,選擇模型的正確預測概率爲0.9,例如[0,0,0,0.9,0...,0 ]。
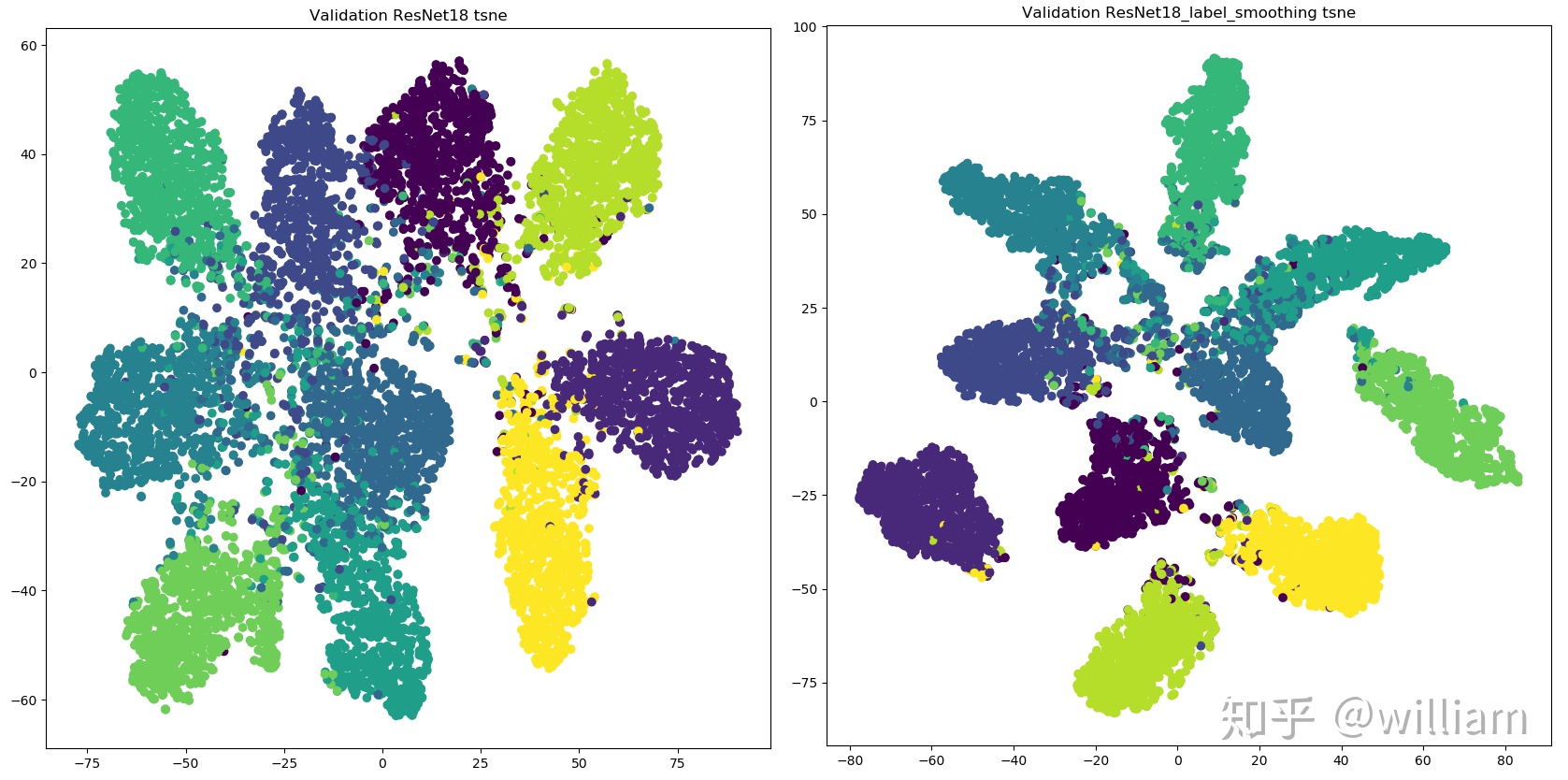
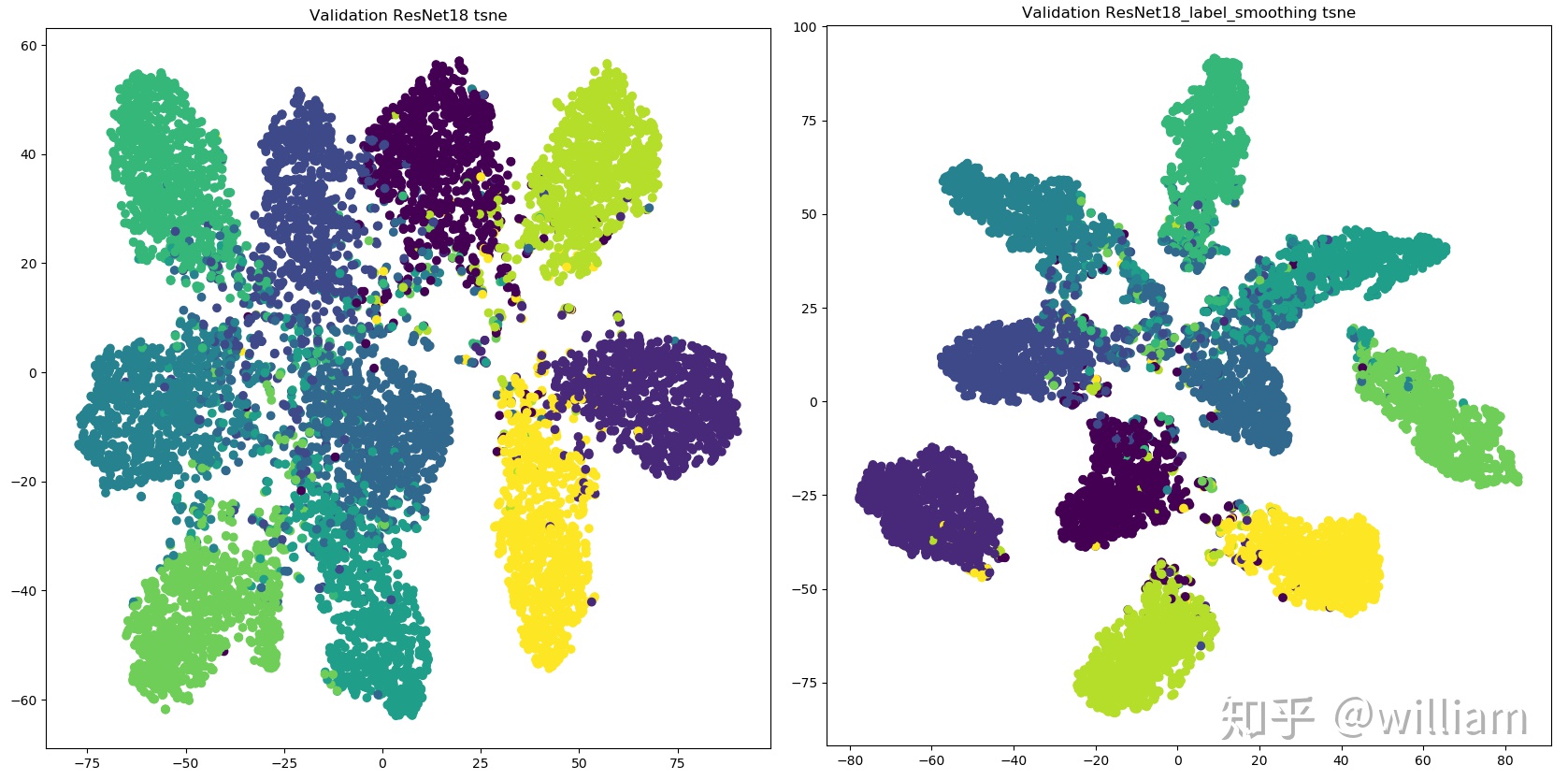
從上圖看出,標籤平滑爲最終的激活產生了更緊密的聚類和更大的類別間的分離,實現更好的泛化。
YOLO V5 似乎沒有使用類標籤平滑。
YOLO V5 數據增強
YOLO V5的作者現在並沒有發表論文,因此只能從代碼的角度理解它的數據增強管道。
YOLOV5都會通過數據加載器傳遞每一批訓練數據,並同時增強訓練數據。數據加載器進行三種數據增強:縮放,色彩空間調整和馬賽克增強。
有意思的是,有媒體報道,YOLO V5的作者Glen Jocher正是Mosaic Augmentation的創造者,他認爲YOLO V4性能巨大提升很大程度是馬賽克數據增強的功勞,也許是不服,他在YOLO V4出來後的僅僅兩個月便推出YOLO V5,當然未來是否繼續使用YOLO V5的名字或者採用其他名字,首先得看YOLO V5的最終研究成果是否能夠真正意義上領先YOLO V4。
但是不可否認的是馬賽克數據增強確實能有效解決模型訓練中最頭疼的「小對象問題」,即小對象不如大對象那樣準確地被檢測到。
下圖是我在訓練BDD100K數據時的數據增強結果。我會在我的下篇文章:YOLO V5 Transfer learning 中展示YOLO V5對象檢測框架的實測效果。

Auto Learning Bounding Box Anchors-自適應錨定框
在我之前YOLO V3的文章中,我介紹過如何採用 k 均值和遺傳學習算法對自定義數據集進行分析,獲得適合自定義數據集中對象邊界框預測的預設錨定框。
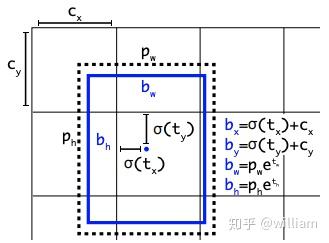
在YOLO V5 中錨定框是基於訓練數據自動學習的。
對於COCO數據集來說,YOLO V5 的配置文件*.yaml 中已經預設了640×640圖像大小下錨定框的尺寸:
# anchorsanchors: - [116,90, 156,198, 373,326] # P5/32 - [30,61, 62,45, 59,119] # P4/16 - [10,13, 16,30, 33,23] # P3/8但是對於你的自定義數據集來說,由於目標識別框架往往需要縮放原始圖片尺寸,並且數據集中目標對象的大小可能也與COCO數據集不同,因此YOLO V5會重新自動學習錨定框的尺寸。

如在上圖中, YOLO V5在進行學習自動錨定框的尺寸。對於BDD100K數據集,模型中的圖片縮放到512後,最佳錨定框爲:


YOLO V4並沒有自適應錨定框。
Backbone-跨階段局部網絡(CSP)
YOLO V5和V4都使用CSPDarknet作爲Backbone,從輸入圖像中提取豐富的信息特徵。CSPNet全稱是Cross Stage Partial Networks,也就是跨階段局部網絡。CSPNet解決了其他大型卷積神經網絡框架Backbone中網絡優化的梯度信息重複問題,將梯度的變化從頭到尾地集成到特徵圖中,因此減少了模型的參數量和FLOPS數值,既保證了推理速度和準確率,又減小了模型尺寸。
CSPNet實際上是基於Densnet的思想,複製基礎層的特徵映射圖,通過dense block 發送副本到下一個階段,從而將基礎層的特徵映射圖分離出來。這樣可以有效緩解梯度消失問題(通過非常深的網絡很難去反推丟失信號) ,支持特徵傳播,鼓勵網絡重用特徵,從而減少網絡參數數量。
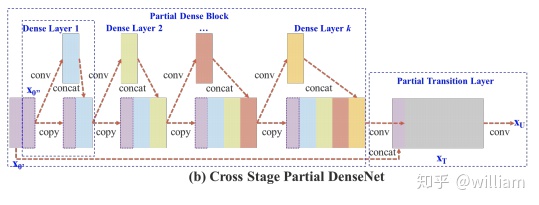
CSPNet思想可以和ResNet、ResNeXt和DenseNet結合,目前主要有CSPResNext50 and CSPDarknet53兩種改造Backbone網絡。
Neck-路徑聚合網絡(PANET)
Neck主要用於生成特徵金字塔。特徵金字塔會增強模型對於不同縮放尺度對象的檢測,從而能夠識別不同大小和尺度的同一個物體。在PANET出來之前,FPN一直是對象檢測框架特徵聚合層的State of the art,直到PANET的出現。在YOLO V4的研究中,PANET被認爲是最適合YOLO的特徵融合網絡,因此YOLO V5和V4都使用PANET作爲Neck來聚合特徵。
PANET基於 Mask R-CNN 和 FPN 框架,同時加強了信息傳播。該網絡的特徵提取器採用了一種新的增強自下向上路徑的 FPN 結構,改善了低層特徵的傳播。第三條通路的每個階段都將前一階段的特徵映射作爲輸入,並用3x3卷積層處理它們。輸出通過橫向連接被添加到自上而下通路的同一階段特徵圖中,這些特徵圖爲下一階段提供信息。同時使用自適應特徵池化(Adaptive feature pooling)恢復每個候選區域和所有特徵層次之間被破壞的信息路徑,聚合每個特徵層次上的每個候選區域,避免被任意分配。
下圖中pi 代表 CSP 主幹網絡中的一個特徵層
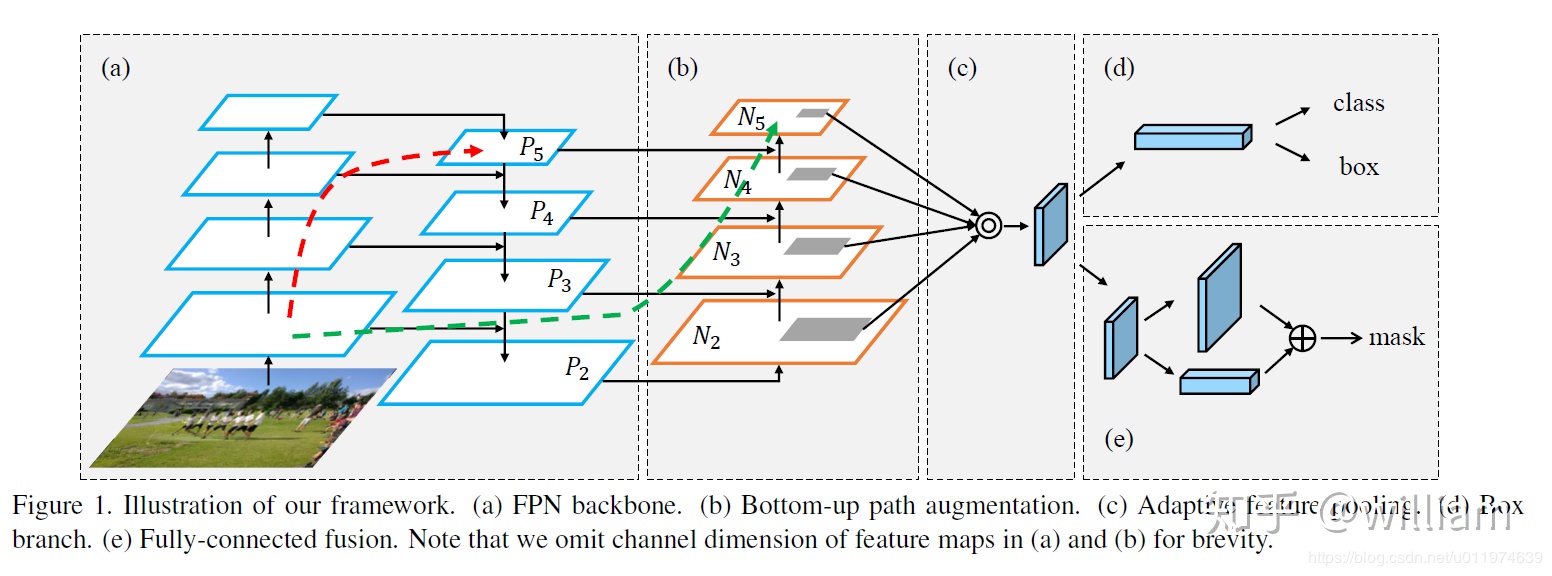
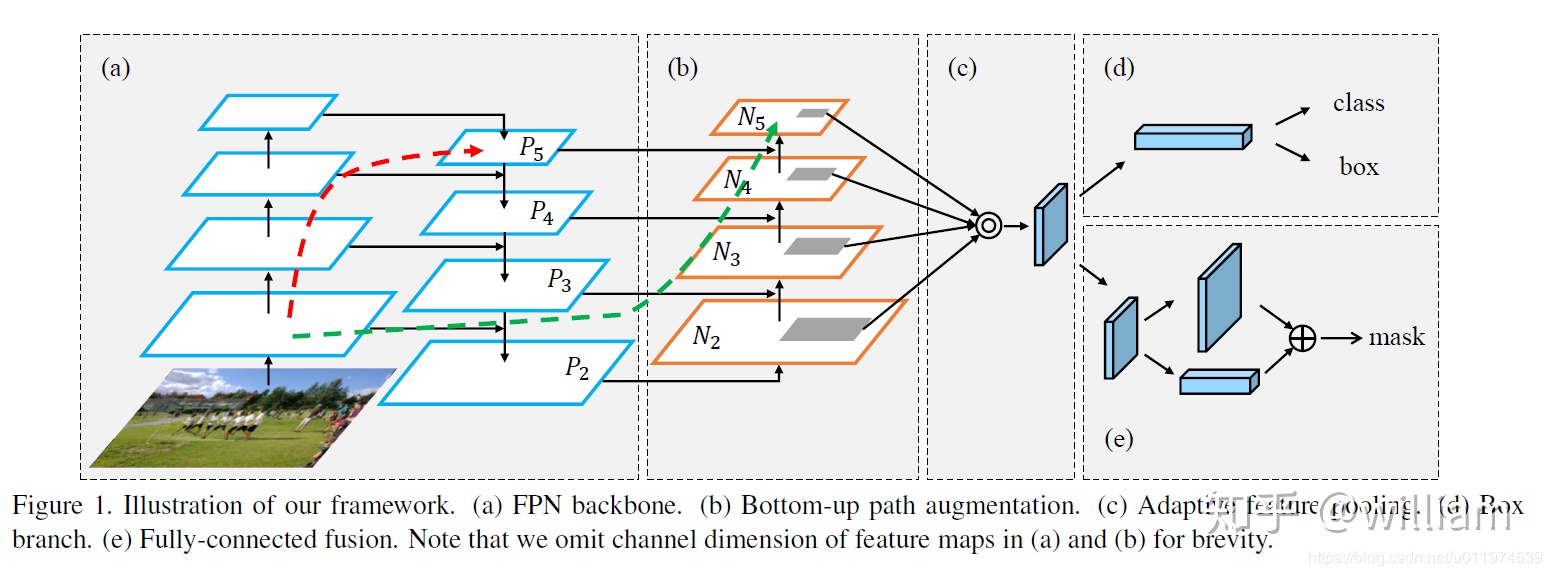
Head-YOLO 通用檢測層
模型Head主要用於最終檢測部分。它在特徵圖上應用錨定框,並生成帶有類概率、對象得分和包圍框的最終輸出向量。
在 YOLO V5模型中,模型Head與之前的 YOLO V3和 V4版本相同。
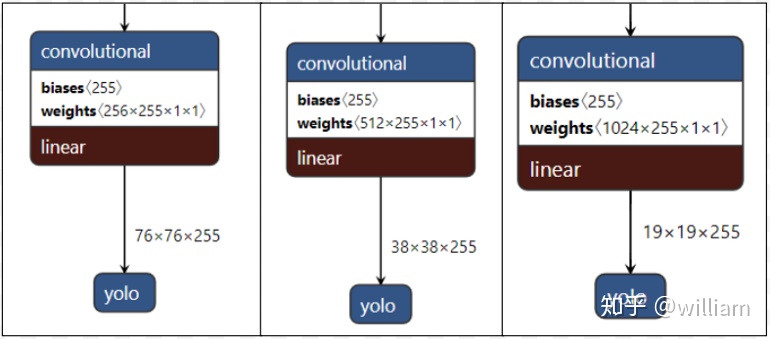
這些不同縮放尺度的Head被用來檢測不同大小的物體,每個Head一共(80個類 + 1個概率 + 4座標) * 3錨定框,一共255個channels。
Network Architecture
由於YOLO V5的作者並未放出論文,而網絡上已經存在大量YOLO V4網絡結構分析,因此本文不着重分析YOLO V5與V4的網絡結構具體細節,但它們有着相似的網絡結構,都使用了CSPDarknet53(跨階段局部網絡)作爲Backbone,並且使用了PANET(路徑聚合網絡)和SPP(空間金字塔池化)作爲Neck,而且都使用YOLO V3的Head。
我們可以通過Netron可視化YOLO V5及V4的網絡結構,但是你會發現YOLO V5的網絡結構非常簡潔,而且YOLO V5 s,m,l,x四種模型的網絡結構是一樣的。原因在於Ultralytics通過depth_multiple,width_multiple兩個參數分別控制模型的深度以及卷積核的個數。
# YOLO V5s# parametersnc: 80 # number of classesdepth_multiple: 0.33 # model depth multiplewidth_multiple: 0.50 # layer channel multiple例如*.yaml文件中,V5s的深度是0.33,而V5x的深度是1.33,也就是說V5x的Bottleneck個數是V5s的四倍。
而V5s的寬度是0.5,而V5x的寬度是1.25,表示V5s的卷積核數量是設置的一半,而V5x是設置的1.25倍,當然你也可以設置到1.5倍,搭建超巨型神經網絡。下圖中YOLO V5的yaml文件中的backbone的第一層是 [[-1, 1, Focus, [64, 3]],而V5s的寬度是0.5,因此這一層實際上是[[-1, 1, Focus, [32, 3]]。
# YOLOv5 backbonebackbone: # [from, number, module, args] [[-1, 1, Focus, [64, 3]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, BottleneckCSP, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 9, BottleneckCSP, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, BottleneckCSP, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 1, SPP, [1024, [5, 9, 13]]], ]下圖中左側爲YOLO V5s的模型右側爲YOLO V5x的模型,可以明顯看出卷積核數量不一樣,因此參數數量也不一樣。
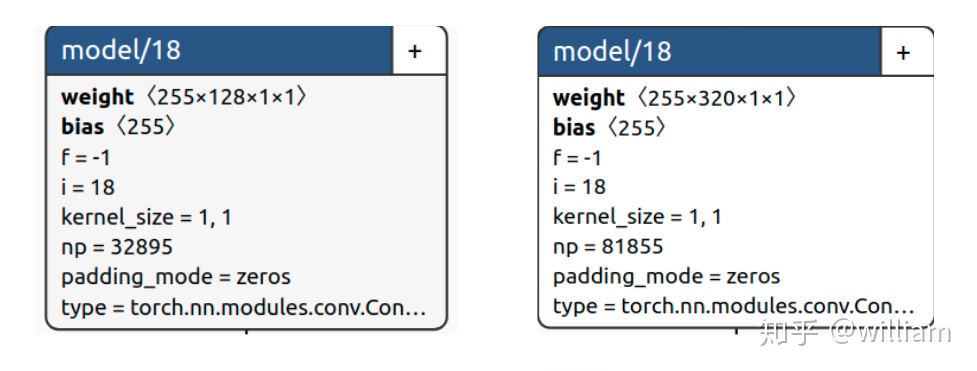
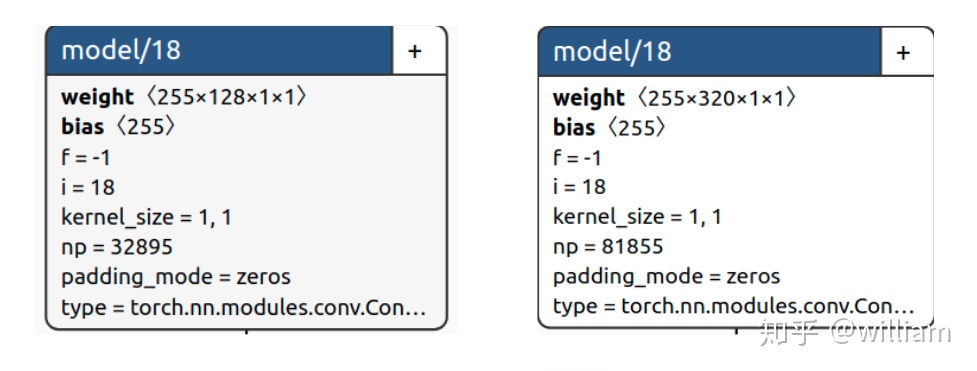
爲了方便大家瞭解YOLO V5與YOLO V4網絡結構的區別,我已經用Netron生成了YOLO V5s,YOLO V5x,YOLO V4的網絡結構圖。對於對YOLO V5s網絡結構基於代碼理解的具體分析,我會在下篇文章YOLO V5 Transfer learning 中闡述。
點擊下方鏈接可以查看各自的網絡結構大圖:
YOLO V4: https://1drv.ms/u/s!An7G4eYRvZzthI48WhoNNwWO8ElNfA?e=oG0Afh
YOLO V5s: https://1drv.ms/u/s!An7G4eYRvZzthI49NZcZHEw2Vtf-VA?e=plafXD
YOLO V5x: https://1drv.ms/u/s!An7G4eYRvZzthI47_ohzdWPz1CSrnQ?e=H2OpOO
YOLOV5S.YAML: https://1drv.ms/u/s!An7G4eYRvZzthI5A41VHiA9ncpBBfw?e=3M64Wd
Activation Function
激活函數的選擇對於深度學習網絡是至關重要的。YOLO V5的作者使用了 Leaky ReLU 和 Sigmoid 激活函數。
在 YOLO V5中,中間/隱藏層使用了 Leaky ReLU 激活函數,最後的檢測層使用了 Sigmoid 形激活函數。而YOLO V4使用Mish激活函數。
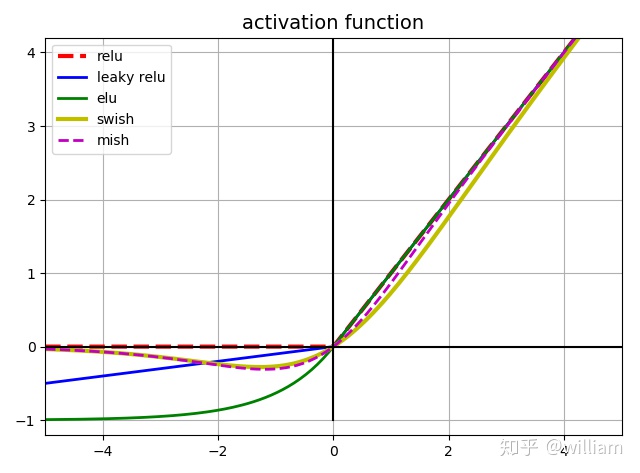
Mish在39個基準測試中擊敗了Swish,在40個基準測試中擊敗了ReLU,一些結果顯示基準精度提高了3–5%。但是要注意的是,與ReLU和Swish相比,Mish激活在計算上更加昂貴。
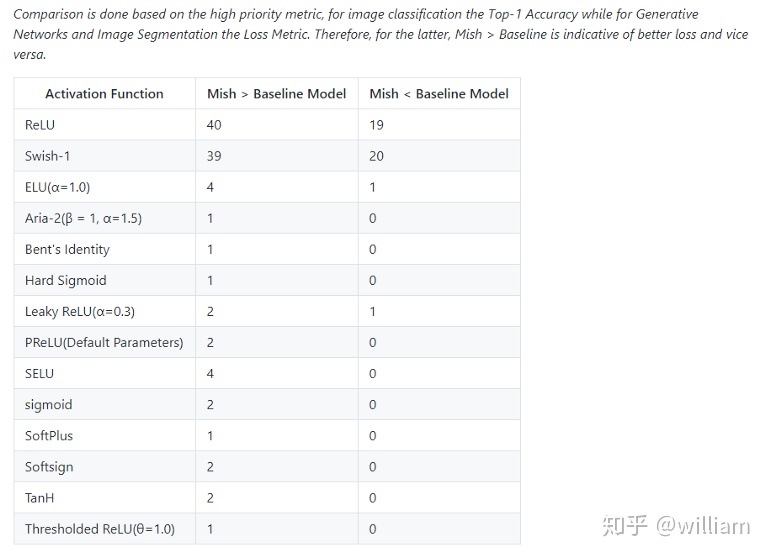
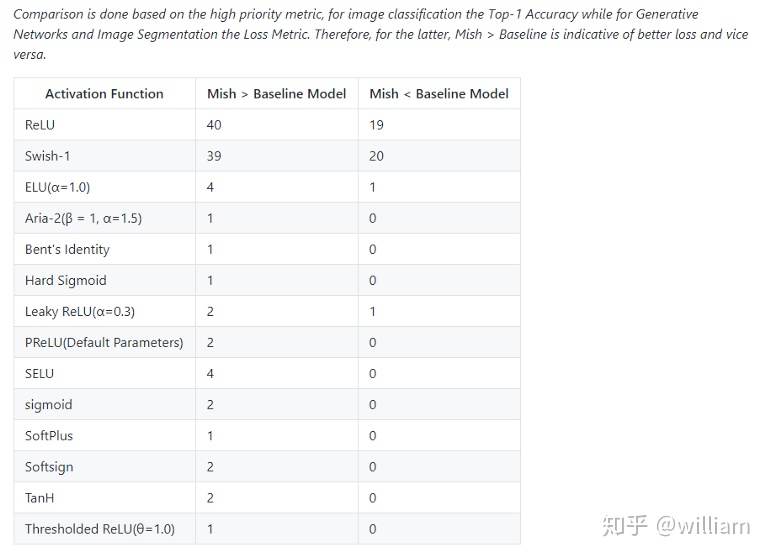
Optimization Function
YOLO V5的作者爲我們提供了兩個優化函數Adam和SGD,並都預設了與之匹配的訓練超參數。默認爲SGD。
YOLO V4使用SGD。
YOLO V5的作者建議是,如果需要訓練較小的自定義數據集,Adam是更合適的選擇,儘管Adam的學習率通常比SGD低。但是如果訓練大型數據集,對於YOLOV5來說SGD效果比Adam好。
實際上學術界上對於SGD和Adam哪個更好,一直沒有統一的定論,取決於實際項目情況。
Cost Function
YOLO 系列的損失計算是基於 objectness score, class probability score,和 bounding box regression score.
YOLO V5使用 GIOU Loss作爲bounding box的損失。
YOLO V5使用二進制交叉熵和 Logits 損失函數計算類概率和目標得分的損失。同時我們也可以使用fl _ gamma參數來激活Focal loss計算損失函數。
YOLO V4使用 CIOU Loss作爲bounding box的損失,與其他提到的方法相比,CIOU帶來了更快的收斂和更好的性能。
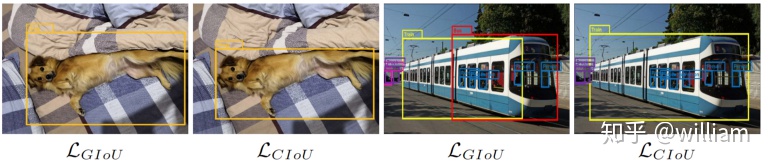
上圖結果基於Faster R-CNN,可以看出,實際上CIoU 的表現比 GIoU 好。
Benchmarks- YOLO V5 VS YOLO V4
由於Ultralytics公司目前重心都放在儘快推廣YOLO V5對象檢測框架,YOLO V5也在不停的更新和完善之中,因此作者打算年底在YOLO V5的研究完成之後發表正式論文。在沒有論文的詳細論述之前,我們只能通過查看作者放出的COCO指標並結合大佬們後續的實例評估來比較兩者的性能。
- 官方性能評估
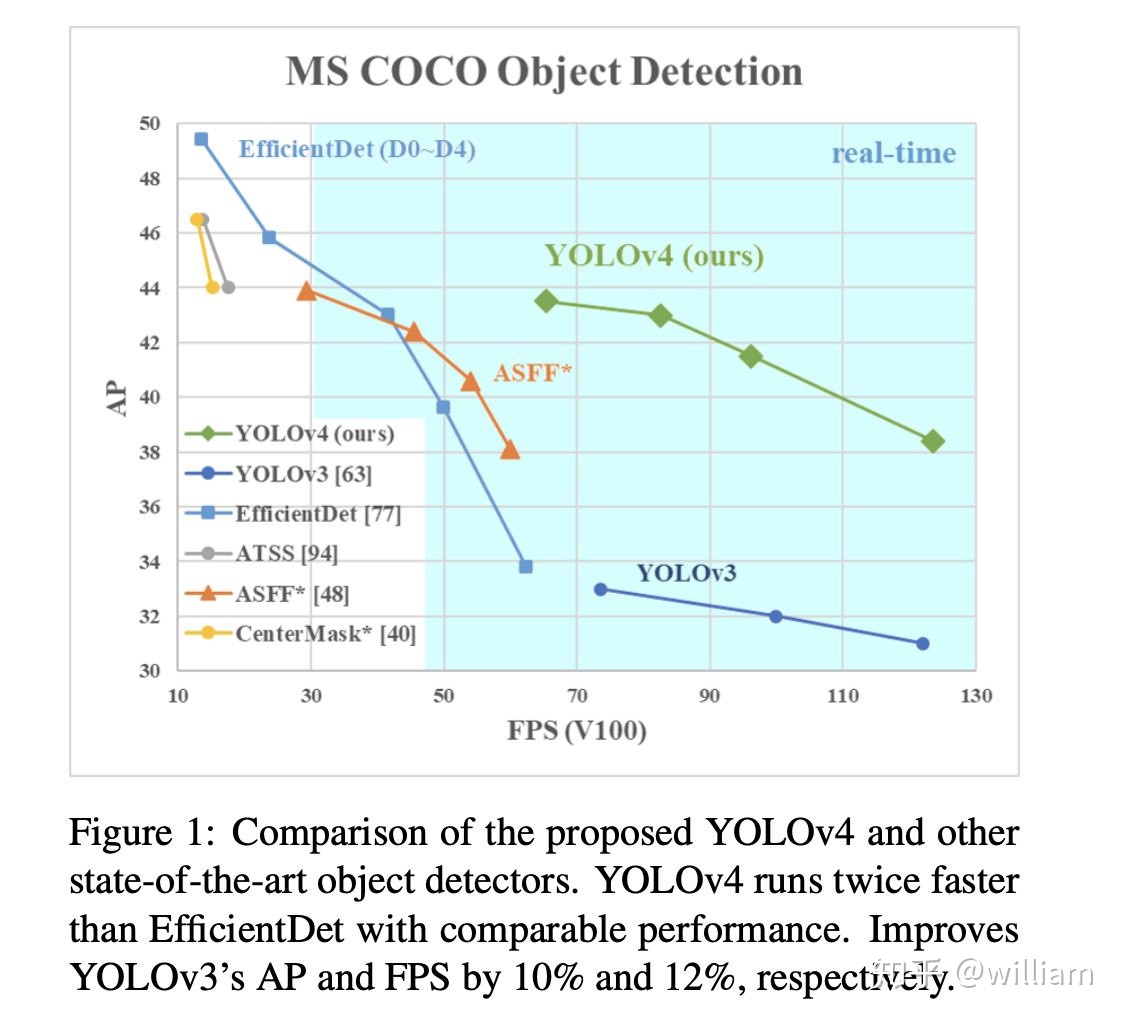
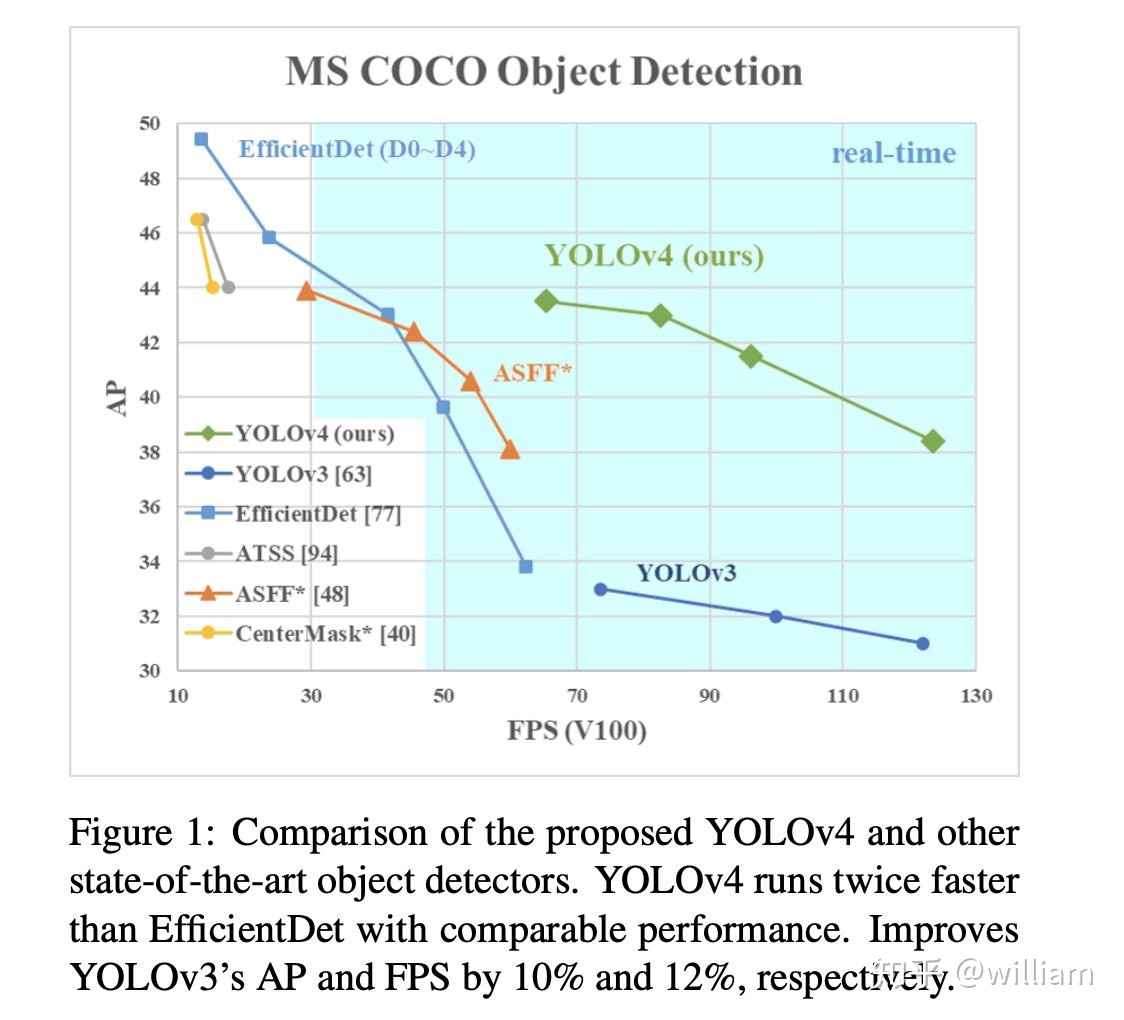
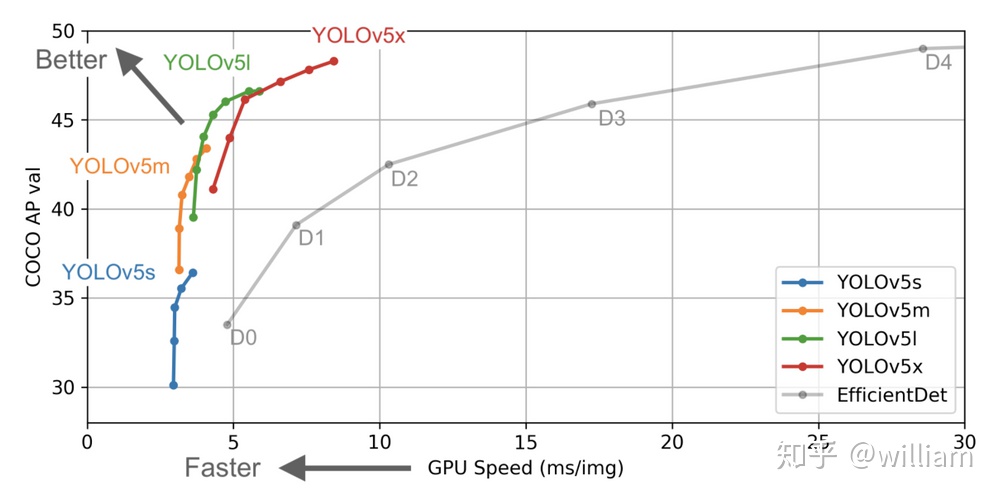
在上面的兩個圖中,FPS與ms/img的關係是反轉的,經過單位轉換後我們可以發現,在V100GPU上YOLO V5可以達到250FPS,同時具有較高的mAP。
由於YOLO V4的原始訓練是在1080TI上的,遠低於V100的性能,並且AP_50與AP_val的對標不同,因此僅憑上述的表格是無法得出兩者的Benchmarks。
好在YOLO V4的第二作者WongKinYiu使用V100的GPU提供了可以對比的Benchmarks。
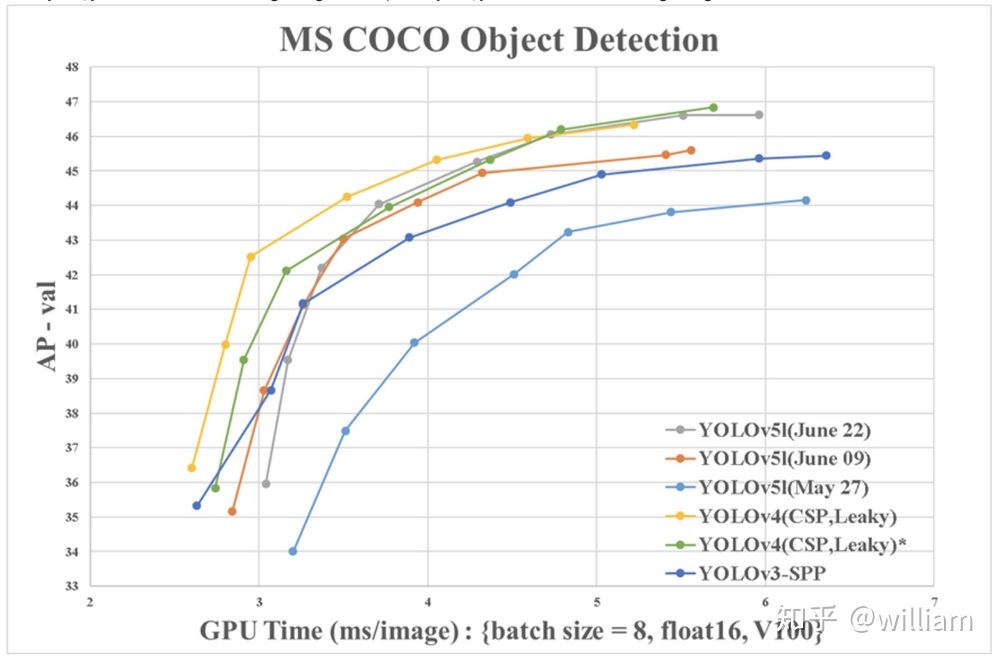
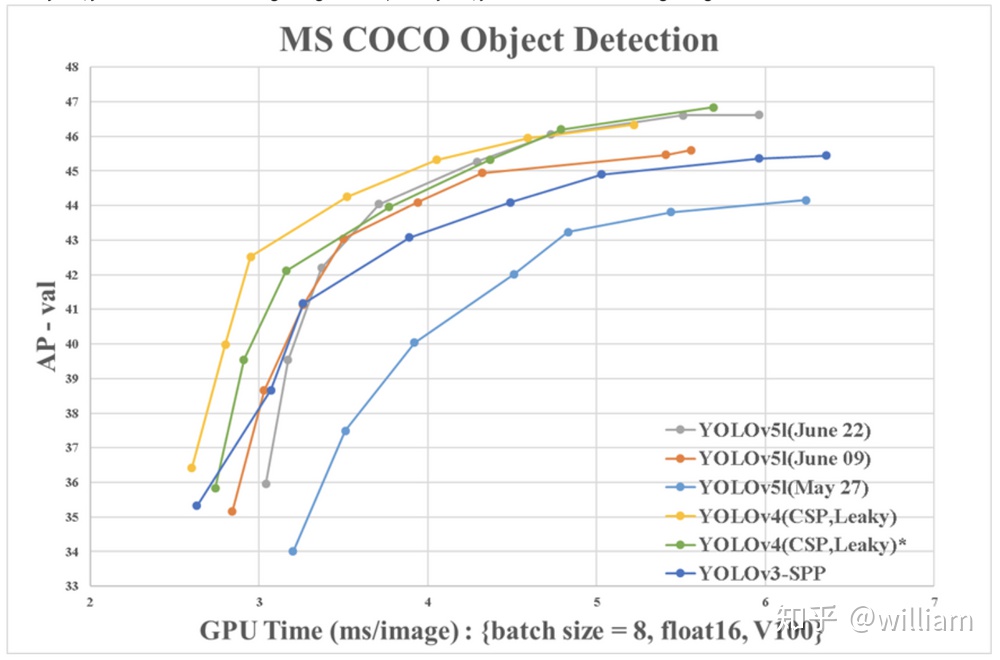
從圖表中可以看出,兩者性能其實很接近,但是從數據上看YOLO V4仍然是最佳對象檢測框架。YOLO V4的可定製化程度很高,如果不懼怕更多自定義配置,那麼基於Darknet的YOLO V4仍然是最準確的。值得注意的是YOLO V4其實使用了大量Ultralytics YOLOv3代碼庫中的數據增強技術,這些技術在YOLO V5中也被運行,數據增強技術對於結果的影響到底有多大,還得等作者的論文分析。
- 訓練時間
根據Roboflow的研究表明,YOLO V5的訓練非常迅速,在訓練速度上遠超YOLO V4。對於Roboflow的自定義數據集,YOLO V4達到最大驗證評估花了14個小時,而YOLO V5僅僅花了3.5個小時。
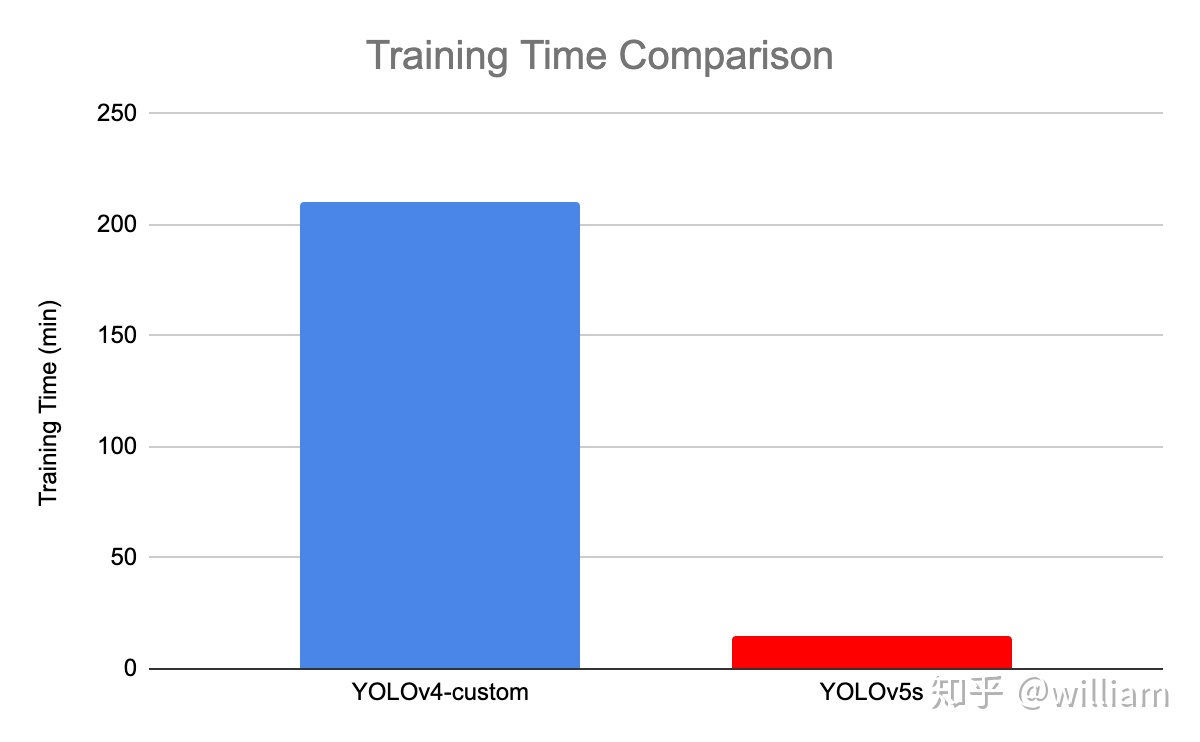
而在我自己的數據訓練過程中,YOLO V5s訓練速度遠超YOLO V4 。我會在我的下篇文章:YOLO V5 Transfer learning 中展示YOLO V5s的實測訓練速度。
- 模型大小
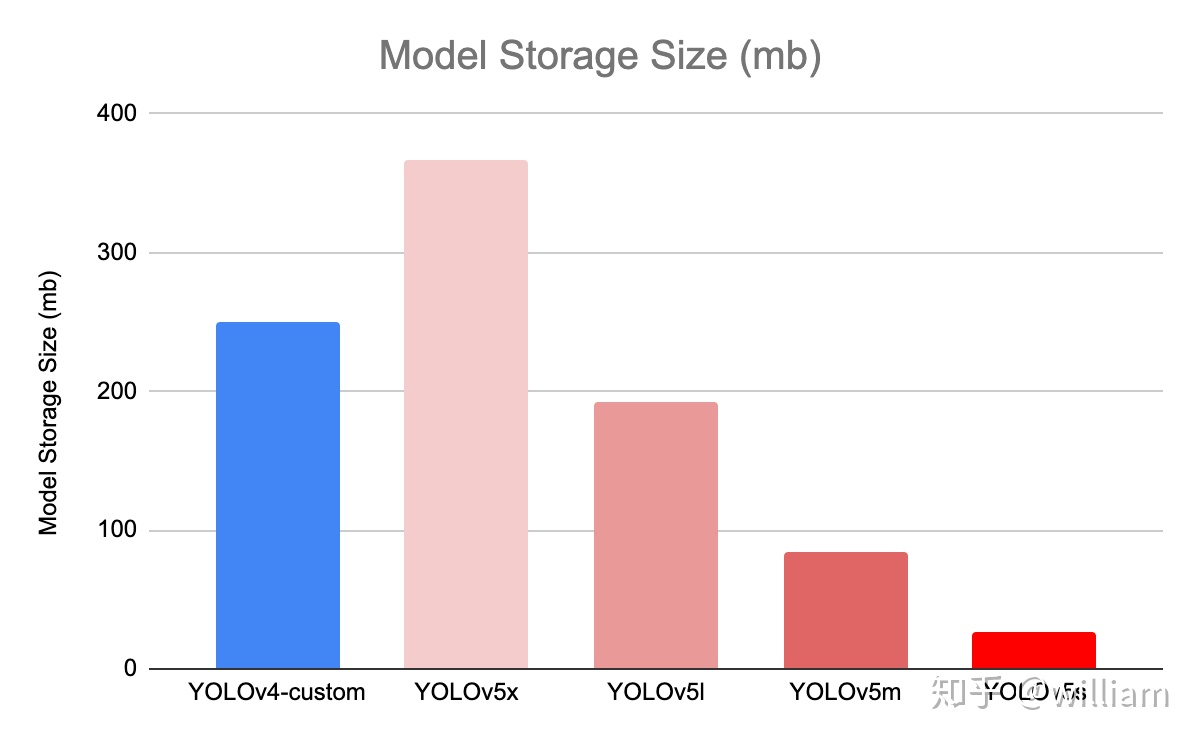
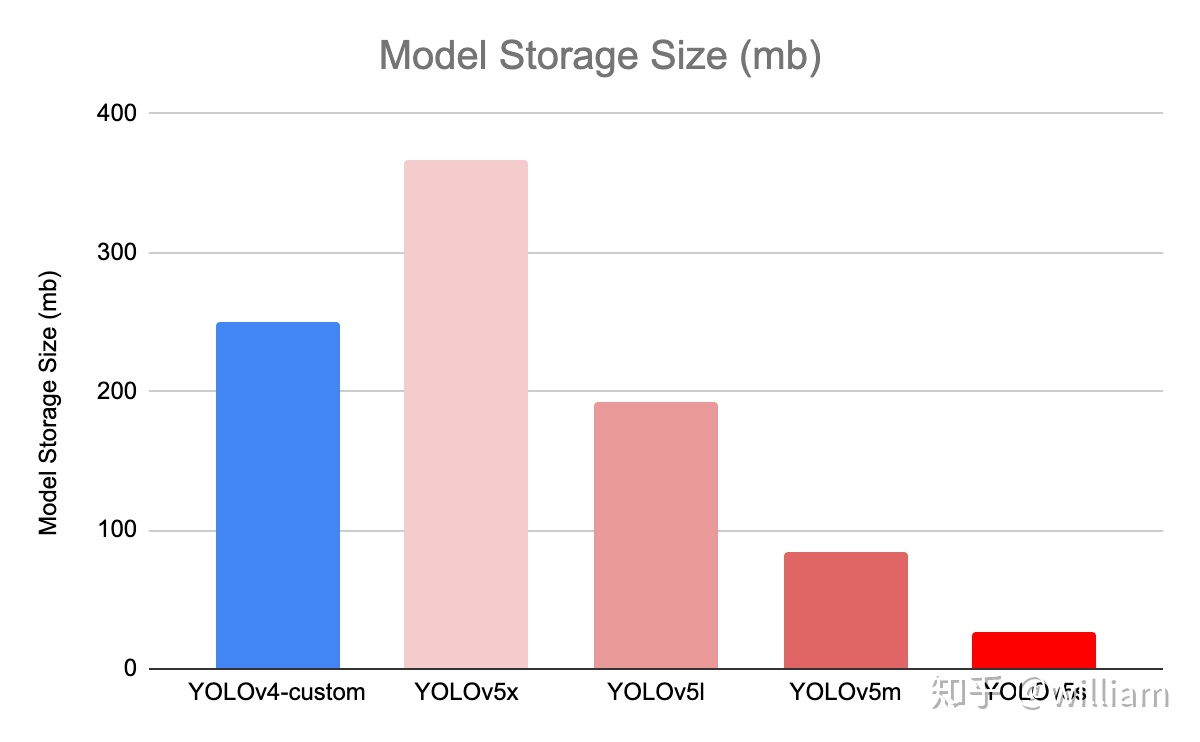
上圖中不同模型的大小分別爲: V5x: 367MB,V5l: 192MB,V5m: 84MB,V5s: 27MB,YOLOV4: 245 MB
YOLO V5s 模型尺寸非常小,降低部署成本,有利於模型的快速部署。
- 推理時間
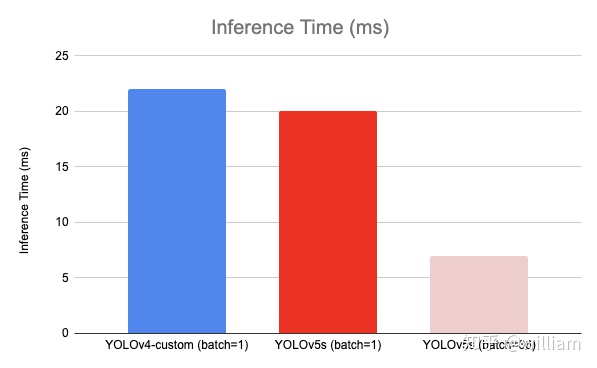
在單個圖像(批大小爲1)上,YOLOV4推斷在22毫秒內,YOLOV5s推斷在20毫秒內。而YOLOV5實現默認爲批處理推理(批大小36),並將批處理時間除以批處理中的圖像數量,單一圖片的推理時間能夠達到7ms,也就是140FPS,這是目前對象檢測領域的State-of-the-art。我使用我訓練的模型對10000張測試圖片進行實時推理,YOLOV5s 的推理速度非常驚豔,每張圖只需要7ms的推理時間,再加上20多兆的模型大小,在靈活性上堪稱無敵。但是其實這對於YOLO V4並不公平,由於YOLO V4沒有實現默認批處理推理,因此在對比上呈現劣勢,接下來應該會有很多關於這兩個對象檢測框架在同一基準下的測試。其次YOLO V4最新推出了tiny版本,YOLO V5s 與V4 tiny 的性能速度對比還需要更多實例分析。
Summary
總的來說,YOLO V4 在性能上優於YOLO V5,但是在靈活性與速度上弱於YOLO V5。由於YOLO V5仍然在快速更新,因此YOLO V5的最終研究成果如何,還有待分析。我個人覺得對於這些對象檢測框架,特徵融合層的性能非常重要,目前兩者都是使用PANET,但是根據谷歌大腦的研究,BiFPN纔是特徵融合層的最佳選擇。誰能整合這項技術,很有可能取得性能大幅超越。
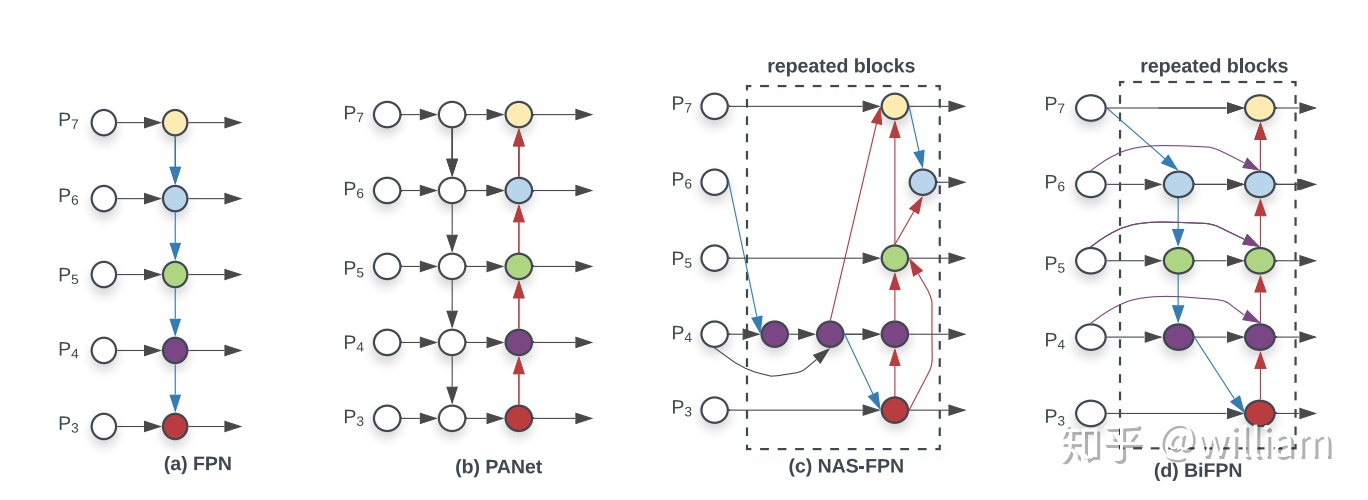
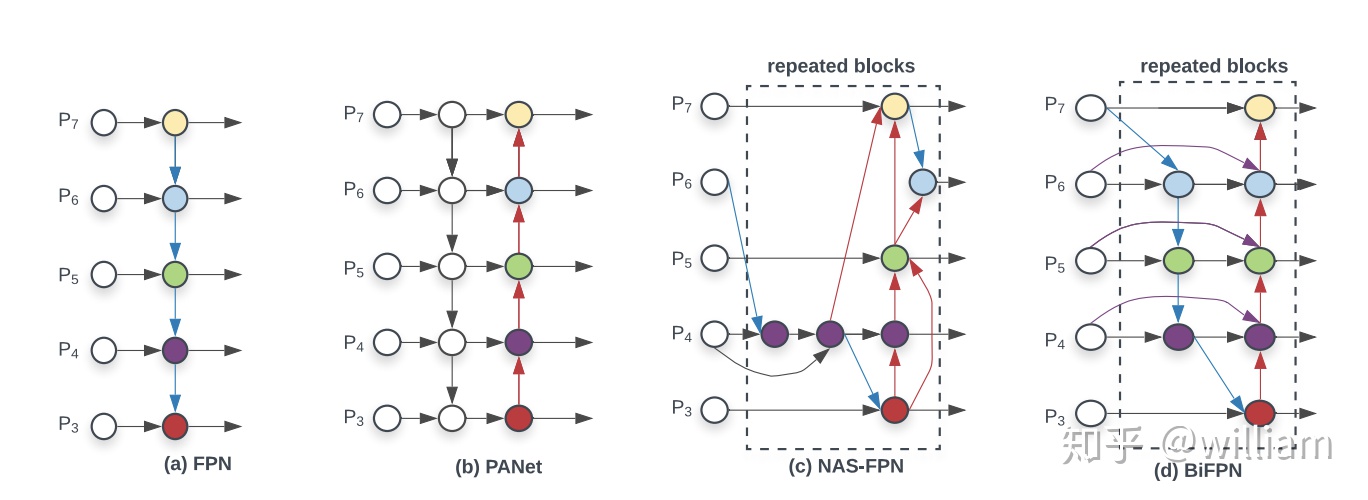
儘管YOLO V5目前仍然計遜一籌,但是YOLO V5仍然具有以下顯著的優點:
- 使用Pytorch框架,對用戶非常友好,能夠方便地訓練自己的數據集,相對於YOLO V4採用的Darknet框架,Pytorch框架更容易投入生產
- 代碼易讀,整合了大量的計算機視覺技術,非常有利於學習和借鑑
- 不僅易於配置環境,模型訓練也非常快速,並且批處理推理產生實時結果
- 能夠直接對單個圖像,批處理圖像,視頻甚至網絡攝像頭端口輸入進行有效推理
- 能夠輕鬆的將Pytorch權重文件轉化爲安卓使用的ONXX格式,然後可以轉換爲OPENCV的使用格式,或者通過CoreML轉化爲IOS格式,直接部署到手機應用端
- 最後YOLO V5s高達140FPS的對象識別速度令人印象非常深刻,使用體驗非常棒
寫在結尾:
其實很多人都覺得YOLO V4和YOLO V5實際上沒有什麼耳目一新創新,而是大量整合了計算機視覺領域的State-of-the-art,從而顯著改善YOLO對象檢測的性能。其實我覺得有的時候工程應用的能力同樣也很重要,能有兩個這麼優秀的技術整合實例供我們免費使用和學習研究,已經不能奢求更多了,畢竟活雷鋒還是少啊。先別管別人誰更強,自己能學到更多才是最重要的,畢竟討論別人誰強,還不如自己強。
最後想說的是,技術發展如此之快,究竟誰能最後拿下最佳對象檢測框架的頭銜尤未可知,而我們處在最好的時代,讓我們且行且學且珍惜。
備註:
我已經更新了:

這篇文章詳細介紹YOLO V5的網絡結構及組成模塊,並使用YOLO V5s在BDD100K自動駕駛數據集上進行遷移學習,搭建屬於自己的自動駕駛交通物體對象識別網絡。
後續我也會分享新的目標檢測技術,歡迎大家訂閱~
如果有什麼疑問,可以隨時聯繫我的個人郵箱,文章下評論可能回覆不及時。
如果你覺得我的文章對你有幫助,請幫忙點個贊~\(≧▽≦)/~
轉載請私信作者!
引用:
Responding to the Controversy about YOLOV5
YOLO V5 — Explained and Demystified