谷歌大腦負責人 Jeff Dean 和該論文的作者之一 Quoc Le 今天都在 Twitter 上介紹了這項研究工作,新方法能利用更多的未標註圖像數據,並提升最終效果。
論文地址:https://arxiv.org/abs/1911.04252


在本文中,研究者首先在標註的 ImageNet 圖像上訓練了一個 EfficientNet 模型,然後用這個模型作爲老師在 3 億無標籤圖像上生成僞標籤。然後研究者訓練了一個更大的 EfficientNet 作爲學生模型,使用的數據則是正確標註圖像和僞標註圖像的混合數據。
這一過程不斷迭代,每個新的學生模型作爲下一輪的老師模型,在生成僞標籤的過程中,教師模型不會被噪聲干擾,所以生成的僞標註會盡可能逼真。但是在學生模型訓練的過程中,研究者對數據加入了噪聲,使用了諸如數據增強、dropout、隨機深度等方法,使得學生模型在從僞標籤訓練的過程中更加艱難。
這一自訓練模型,能夠在 ImageNet 上達到 87.4% 的 top-1 精確度,這一結果比當前的 SOTA 模型表現提高了一個點。除此之外,該模型在 ImageNet 魯棒性測試集上有更好的效果,它相比之前的 SOTA 模型能應對更多特殊情況。
ImageNet 需要更多的大數據
ImageNet 已經是大數據集了,大量標註圖像已經足夠我們學習一個不錯的模型。但是它還需要更多的未標註圖像,即使有一些圖像根本不在要識別的類別之內也沒關係。當模型見過廣大的未標註數據,它才能做更好的 ImageNet 分類。
在本文中,研究者利用未標註圖像來提升當前最優 ImageNet 的精確度,並表明精確度增益對魯棒性具有非常大的影響。基於此,研究者使用了包含未標註圖像的更大語料庫,其中一些圖像並不屬於 ImageNet 的任何類別。
研究者在訓練模型的過程中使用了自訓練框架,分爲以下三步:
1)在標註圖像上訓練一個教師模型;
2)利用該教師模型在未標註圖像上生成僞標籤(pseudo label);
3)在標註和僞標註混合圖像上訓練一個學生模型。最後,通過將學生模型當做教師模型,研究者對算法進行了幾次迭代,以生成新的僞標籤和訓練新的學生模型。
噪聲讓 ImageNet 學習更有效
研究者表示,實驗說明,一項重要的方法是,學生模型在訓練中應當被噪聲干擾,而教師模型在生成僞標籤的時候不需要。這樣,僞標籤能夠儘可能逼真,而學生模型則在訓練中更加困難。
爲了干擾學生模型,研究者使用了 dropout、數據增強和隨機深度幾種方法。爲了在 ImageNet 上實現穩健的結果,學生模型也需要變得很大,特別是要比普通的視覺模型大很多,這樣它才能處理大量的無標註數據。
使用自訓練的帶噪聲學生模型,加上 3 億的無標註圖像,研究者將 EfficientNet 的 ImageNet top-1 精確度提升到了新 SOTA。
 表 1:和之前的 SOTA 模型指標的對比結果。
表 1:和之前的 SOTA 模型指標的對比結果。
帶有 Noisy Student 的自訓練到底是什麼
下圖算法 1 給出了利用 Noisy Student 方法展開自訓練的總覽圖,算法的輸入包括標註和未標註圖像。
 算法 1:Noisy Student 方法。
算法 1:Noisy Student 方法。
研究者首先利用標準交叉熵損失和標註圖像來訓練老師模型。然後,他們使用該老師模型在未標註圖像上生成僞標籤。這些僞標籤既可以是柔性的(連續分佈),也可以是硬性的(onehot 分佈)。接着,研究者訓練學生模型,該模型最小化標註和未標註圖像上的聯合交叉熵損失。最後,通過將學生和老師模型的位置互換,他們對訓練過程進行了幾次迭代,以生成新的僞標籤和訓練新的學生模型。
該算法基本上是自訓練的,這是一種半監督的方法。在本文中,研究者主要的改變是給學生模型增加了更多的噪聲源,這樣可以在移除教師模型中的噪聲後,讓它生成的僞標籤具有更好的效果。當學生模型被刻意干擾後,它實際上會被訓練成一個穩定的教師模型。當這個模型在生成僞標籤的時候,研究者不會去用噪聲干擾它。
此外,教師模型與學生模型的架構可以相同也可以不同,但如果要帶噪聲的學生模型更好地學習,那麼學生模型需要足夠大以擬合更多的數據。
實驗結果
在這一部分中,研究者描述了實驗的各種細節與實現的結果。他們展示了新方法在 ImageNet 上的效果,並對比了此前效果最佳的模型。此外,研究者還重點展示了新方法在魯棒性數據集上的卓越表現,即在 ImageNet-A、C 和 P 測試集,以及在對抗樣本上的魯棒性。
如下表 2 所示,以 EfficientNet-L2 爲主要架構的 Noisy Student 實現了 87.4% 的 Top-1 準確率,它顯著超越了之前採用 EfficientNet 的準確率。其中 2.4% 的性能增益主要有兩個來源:更大的模型(+0.5%)和 Noisy Student(+1.9%)。也就是說,Noisy Student 對準確率的貢獻要大於架構的加深。
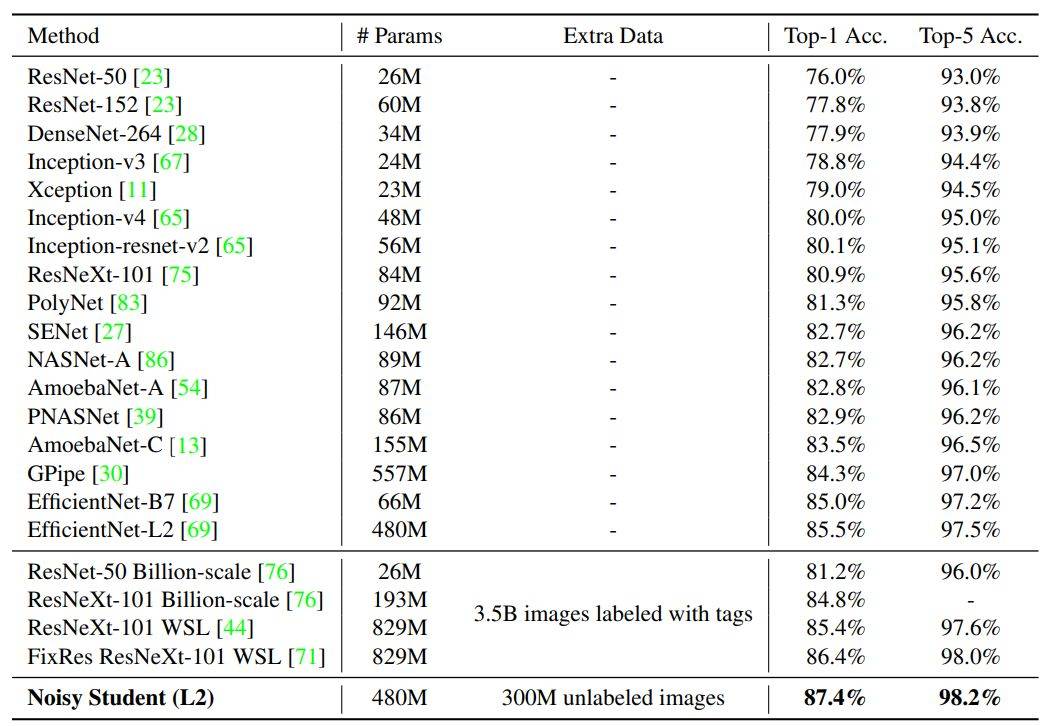 表 2:Noisy Student 與之前 SOTA 模型在 ImageNet 上的 Top-1 與 Top-5 準確率,帶有 Noisy Student 的 EfficientNet 能在準確率與模型大小上取得更好的權衡。
表 2:Noisy Student 與之前 SOTA 模型在 ImageNet 上的 Top-1 與 Top-5 準確率,帶有 Noisy Student 的 EfficientNet 能在準確率與模型大小上取得更好的權衡。
如下圖 1 所示,Noisy Student 對於不同的模型大小都能帶來 0.8% 左右的性能提升。
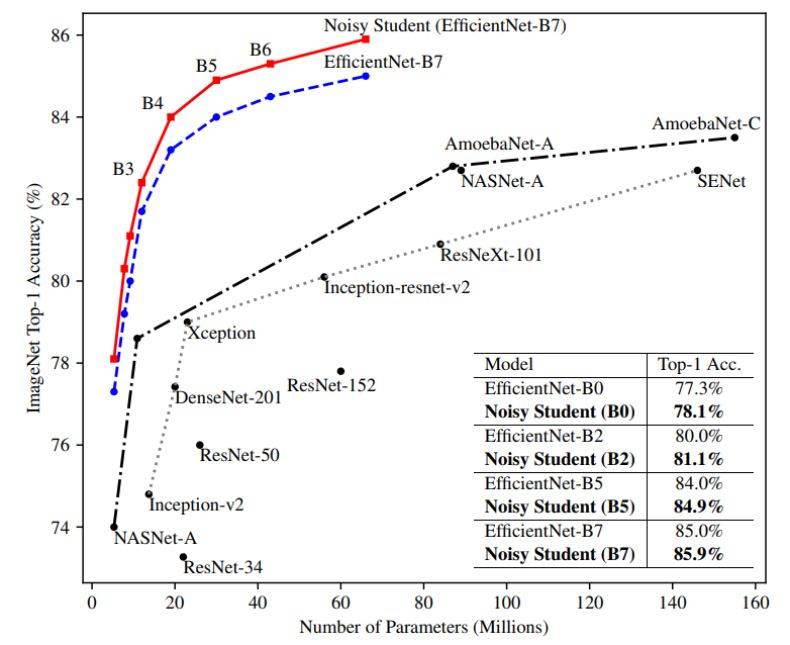 圖 1:Noisy Student 使得 EfficientNet 所有大小的模型都出現了顯著的性能提升。研究者對老師和學生模型使用了相同的架構,並且沒有執行迭代訓練。
圖 1:Noisy Student 使得 EfficientNet 所有大小的模型都出現了顯著的性能提升。研究者對老師和學生模型使用了相同的架構,並且沒有執行迭代訓練。
研究者將實現了 87.4% top-1 精確度的模型放到三個測試集中進行評估。這三個測試集分別是 ImageNet-A、 ImageNet-C 和 ImageNet-P。這些測試集包括了很多圖像中常見的損壞和干擾,如模糊、霧化、旋轉和拉伸。ImageNet-A 測試集會讓之前的 SOTA 模型精確度明顯下降。
這些測試集被認爲是「魯棒性」的基準測試,因爲它們要麼非常難,如 ImageNet-A,要麼和訓練集非常不同,如 ImageNet-C 和 P。
 表 3:ImageNet-A 的魯棒性結果。
表 3:ImageNet-A 的魯棒性結果。
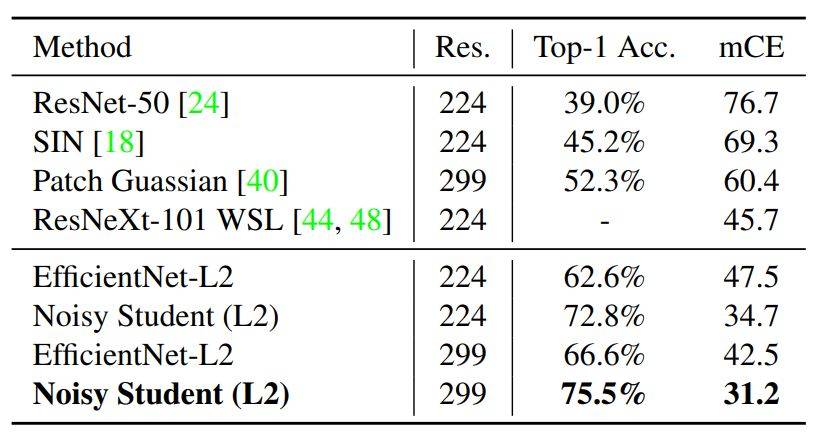 表 4:ImageNet-C 的魯棒性結果。mCE 是不同侵蝕情況下的平均錯誤率,以 AlexNet 錯誤率爲基準(數值越低越好)。
表 4:ImageNet-C 的魯棒性結果。mCE 是不同侵蝕情況下的平均錯誤率,以 AlexNet 錯誤率爲基準(數值越低越好)。
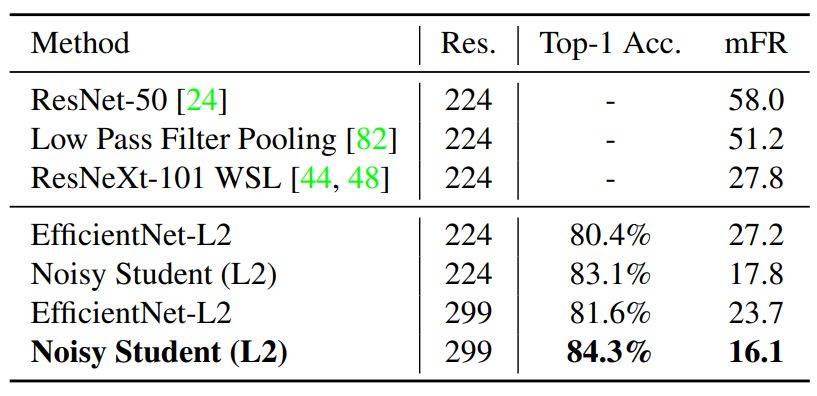 表 5:在 ImageNet-P 上的魯棒性結果,其中圖片是通過一系列干擾生成的 mFR 使用 AlexNet 爲基準,測量模型在擾動下翻轉預測的概率(數值越低越好)。
表 5:在 ImageNet-P 上的魯棒性結果,其中圖片是通過一系列干擾生成的 mFR 使用 AlexNet 爲基準,測量模型在擾動下翻轉預測的概率(數值越低越好)。
爲了直觀理解三個魯棒性基準的大幅度提升,下圖中展示了一些圖片,其中基準模型識別錯誤,而 Noisy Student 模型的預測則正確。
 圖 2:從模型穩健性基準 ImageNet-A、C 和 P 中挑選的圖片。
圖 2:從模型穩健性基準 ImageNet-A、C 和 P 中挑選的圖片。