介紹
本文與配套的Domino項目,簡要介紹瞭如何使用spaCy和相關庫在Python中處理自然語言(有時稱爲「文本分析」)。業界的數據科學團隊時常處理大量文本數據,這也是機器學習中使用的四大數據類別之一,通常是人爲生成的文本,但也不全是這樣。
想想看:商業世界的「操作系統」是如何運行的? 通常,有合同(銷售合同、工作協議、合作關係),發票,保險單,規章制度和其他法律條文等等。所有這些都被表示爲文本。
你可能會遇到一些縮寫詞:自然語言處理(NLP),自然語言理解(NLU),自然語言生成(NLG),簡單地說,分別是「閱讀文本」、「理解意義」、「輸出文本」。這些任務越來越多地重疊,而且很難分類。
spaCy框架——以及越來越多的插件和其他集成(包)——爲各種各樣的自然語言任務提供了支持。它已經成爲Python中最廣泛使用的工業級自然語言庫之一,並且擁有相當大的社區,因此,隨着該領域的快速發展,它爲科研進展進展的商業化提供了足夠地支持。
開始
我們已經在Domino中配置了默認的軟件環境,以包含本教程所需的所有包、庫、模型和數據。請查看Domino項目以運行代碼。

如果您對Domino的計算環境如何工作感興趣,請查看說明頁面。
說明頁面https://support.dominodatalab.com/hc/en-us/articles/115000392643-Environment-management
現在讓我們加載spaCy並運行一些代碼:
import spacynlp = spacy.load("en_core_web_sm")
該nlp變量現在是您通向所有spaCy的入口,並裝載了en_core_web_sm英文模型。接下來,讓我們通過自然語言解析器來運行一個小「文檔」:
text = "The rain in Spain falls mainly on the plain."doc = nlp(text)for token in doc:print(token.text, token.lemma_, token.pos_, token.is_stop)
The the DET Truerainrain NOUN Falseinin ADP TrueSpainSpain PROPN Falsefalls fall VERB Falsemainlymainly ADV Falseon on ADP Truethe the DET Trueplainplain NOUN False. . PUNCT False
首先,我們從文本創建一個doc(注:spaCy中的一種數據結構)文檔,它是一個容器,存放了文檔以及文檔對應的標註。然後我們遍歷文檔,看看spaCy解析了什麼。
由於信息有點多,讀起來有點困難。讓我們將這個句子的用spaCy解析結果重新格式化爲pandas庫的 dataframe:
import pandas as pdcols = ("text", "lemma", "POS", "explain", "stopword")rows = []for t in doc:row = [t.text, t.lemma_, t.pos_, spacy.explain(t.pos_), t.is_stop]rows.append(row)df = pd.DataFrame(rows, columns=cols)df
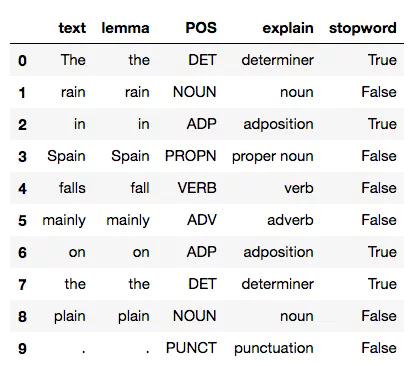
在這個簡單的例子中,整個文檔僅僅是一個簡短的句子。對於這個句子中的每個單詞,spaCy都創建了一個token,我們訪問每個token中的字段來顯示:
- 原始文本
- 詞形(lemma)引理——這個詞的詞根形式
- 詞性(part-of-speech)
- 是否是停用詞的標誌,比如一個可能會被過濾的常用詞
接下來讓我們使用displaCy庫來可視化這個句子的解析樹:
from spacy import displacydisplacy.render(doc, style="dep")
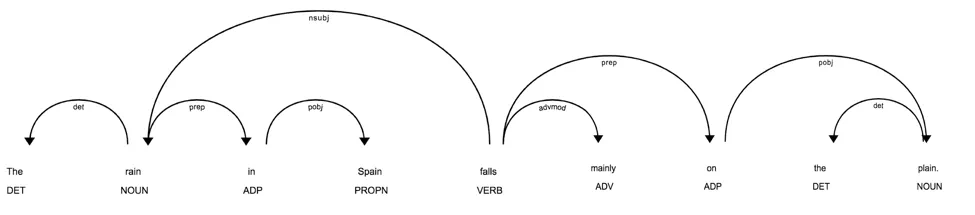
這會讓你回想起小學時候的語文課嗎? 坦率地說,對於我們這些來自計算語言學背景的人來說,這個圖表會讓我們感到開心。
我們先回顧一下,你是如何處理多個句子的?
比如,句邊界檢測(SBD)的功能,也稱爲句子分割,下例基於內置/默認的語句分析器:
text = "We were all out at the zoo one day, I was doing some acting, walking on the railing of the gorilla exhibit. I fell in. Everyone screamed and Tommy jumped in after me, forgetting that he had blueberries in his front pocket. The gorillas just went wild."doc = nlp(text)for sent in doc.sents:print(">", sent)
We were all out at the zoo one day, I was doing some acting, walking on the railing of the gorilla exhibit.I fell in.Everyone screamed and Tommy jumped in after me, forgetting that he had blueberries in his front pocket.The gorillas just went wild.
當spaCy創建一個文檔時,它使用了非破壞性標記原則,這意味着tokens、句子等只是長數組中的索引。換句話說,他們沒有將文本切分成小段。因此,每個句子都是一個span(也是spaCy中的一種數據結構)單獨,包含了它在文檔數組中的開始和結束索引:
for sent in doc.sents:print(">", sent.start, sent.end)
> 0 25
> 25 29
> 29 48
> 48 54
我們可以在文檔數組上切片,取出一個句子的tokens:
doc[48:54]The gorillas just went wild.
或者只是找一個特定的token,例如最後一句話中的動詞「went」:
token = doc[51]print(token.text, token.lemma_, token.pos_)went go VERB
此時,我們可以解析一個文檔,將該文檔分割成句子,然後查看每個句子中token的註釋。這是一個好的開始。
獲取文本
既然我們可以解析文本,那麼我們從哪裏獲得文本呢?一個便利的方法是利用互聯網。當然,當我們下載網頁時,我們會得到HTML文件,然後需要從文件中提取文本。這方面,Beautiful Soup是一個很流行的包。
首先將警告過濾掉:
import sysimportwarningswarnings.filterwarnings("ignore")
在下面的函數get_text()中,我們將解析HTML以找到所有的
標記,然後提取這些標記的文本:
from bs4 import BeautifulSoupimport requestsimport tracebackdef get_text (url):buf = []try:soup = BeautifulSoup(requests.get(url).text, "html.parser")for p in soup.find_all("p"):buf.append(p.get_text())return "\n".join(buf)except:print(traceback.format_exc())sys.exit(-1)
現在讓我們從網上獲取一些文本。我們可以對比開源倡議上開源許可的情況。
開源倡議:
https://opensource.org/licenses/
lic = {}lic["mit"] = nlp(get_text("https://opensource.org/licenses/MIT"))lic["asl"] = nlp(get_text("https://opensource.org/licenses/Apache-2.0"))lic["bsd"] = nlp(get_text("https://opensource.org/licenses/BSD-3-Clause"))for sent in lic["bsd"].sents: print(">", sent)
> SPDX short identifier: BSD-3-Clause> Note: This license has also been called the "New BSD License" or "Modified BSD License"> See also the 2-clause BSD License.…
自然語言工作的一個常見用例是對比文本。
例如,有了這些開源許可,我們可以下載它們的文本,進行解析,然後比較它們之間的相似度:(https://spacy.io/api/doc#similarity)
pairs = [["mit", "asl"],["asl", "bsd"],["bsd", "mit"]]for a, b in pairs:print(a, b, lic[a].similarity(lic[b]))
mit asl 0.9482039305669306asl bsd 0.9391555350757145bsd mit 0.9895838089575453
這很有趣,因爲BSD(https://opensource.org/licenses/BSD-3-Clause)和MIT(https://opensource.org/licenses/MIT)許可似乎是最相似的文檔。
事實上,它們是密切相關的。
無可否認,由於OSI的免責聲明,每個文檔中都包含了一些額外的文本——但是這爲比較許可證提供了一個合理的近似值。
自然語言理解
現在讓我們深入瞭解一下spaCy中的NLU特性。假設我們要解析有一個文檔,從純語法的角度來看,我們可以提取名詞塊(https://spacy.io/usage/linguistic-features#noun-chunks),即每個名詞短語:
text = "Steve Jobs and Steve Wozniak incorporated Apple Computer on January 3, 1977, in Cupertino, California."doc = nlp(text)for chunk in doc.noun_chunks:print(chunk.text)
Steve JobsSteve WozniakApple ComputerJanuaryCupertinoCalifornia
句子中的名詞短語通常提供更多的信息內容——作爲一個簡單的過濾器,可以將長文檔簡化爲更「精練」的表達。
我們可以進一步採用這種方法,並在文本中標識命名實體(https://spacy.io/usage/linguistic-features#named-entities),即專有名詞:
for ent in doc.ents:print(ent.text, ent.label_)
displacy.render(doc, style="ent")
如果你正在使用知識圖譜(https://www.akbc.ws/2019/)的應用程序和其他關聯數據(http://linkeddata.org/),那麼構建文檔中的命名實體和其他相關信息的聯繫就是一種挑戰,即文本鏈接
(http://nlpprogress.com/english/entity_linking.html)。
識別文檔中的命名實體是這類型AI工作的第一步。例如,根據上面的文本,可以將「Steve Wozniak」這個命名實體鏈接到DBpedia中的查找鏈接(http://dbpedia.org/page/Steve_Wozniak)。
一般來說,人們還可以將詞形與描述其含義的資源聯繫起來。例如,在前面的章節中,我們分析了「the gorillas just went wild」這個句子,並展示「went」這個詞的詞形是動詞go。
此時,我們可以使用一個歷史悠久的項目WordNet (https://wordnet.princeton.edu/),它爲英語提供了一個詞彙數據庫——換句話說,它是一個可計算的近義詞典。
有一個針對WordNet的spaCy集成,名爲spaCy - WordNet(https://github.com/recognai/spacy-wordnet),作者是Daniel Vila Suero(https://twitter.com/dvilasuero),他是自然語言和知識圖譜研究的專家。
然後我們將通過NLTK加載WordNet數據:
import nltknltk.download("wordnet")[nltk_data] Downloading package wordnet to /home/ceteri/nltk_data...[nltk_data] Package wordnet is already up-to-date!True
請注意,spaCy像「管道(pipeline)」一樣運行,並允許使用自定義的管道組件。這對於在數據科學中支持工作流是非常好的。在這裏,我們將添加來自spacy-wordnet項目的Wordnet註釋(器):
from spacy_wordnet.wordnet_annotator import WordnetAnnotatorprint("before", nlp.pipe_names)if "WordnetAnnotator" not in nlp.pipe_names: nlp.add_pipe(WordnetAnnotator(nlp.lang), after="tagger")print("after", nlp.pipe_names)before ['tagger', 'parser', 'ner']after ['tagger', 'WordnetAnnotator', 'parser', 'ner']
在英語中,有些詞因爲有多重含義而臭名昭著。
例如,在WordNet(http://wordnetweb.princeton.edu/perl/webwn?s=star&sub=Search+WordNet&o2&o0=1&o8=1&o1= 1&o1=1&o7&o5&o9&o6&o3&o4&h)搜索與單詞withdraw相關的詞義。
現在讓我們使用spaCy執行自動查找:
token = nlp("withdraw")[0]token._.wordnet.synsets()
[Synset('withdraw.v.01'),Synset('retire.v.02'),Synset('disengage.v.01'),Synset('recall.v.07'),Synset('swallow.v.05'),Synset('seclude.v.01'),Synset('adjourn.v.02'),Synset('bow_out.v.02'),Synset('withdraw.v.09'),Synset('retire.v.08'),Synset('retreat.v.04'),Synset('remove.v.01')]
token._.wordnet.lemmas()
[Lemma('withdraw.v.01.withdraw'),Lemma('withdraw.v.01.retreat'),Lemma('withdraw.v.01.pull_away'), Lemma('withdraw.v.01.draw_back'), Lemma('withdraw.v.01.recede'),Lemma('withdraw.v.01.pull_back'), Lemma('withdraw.v.01.retire'),…
token._.wordnet.wordnet_domains()
['astronomy','school','telegraphy','industry','psychology','ethnology','ethnology','administration','school','finance','economy','exchange','banking','commerce','medicine','ethnology', 'university',…
同樣,如果你使用的是知識圖譜,那麼可以將來自WordNet的那些「詞義」鏈接與圖算法一起使用,以幫助識別特定單詞的含義。還可以通過一種稱爲「摘要」的技術來爲較大的文本段生成摘要。這些內容超出了本教程的範圍,但它是目前工業中一個有趣的自然語言應用。
反過來說,如果你預先知道某個文檔是關於某個特定領域或主題集的,則可以約束WordNet返回的含義。在下面的例子中,我們來考慮金融和銀行領域數據的NLU結果:
domains = ["finance", "banking"]sentence = nlp("I want to withdraw 5,000 euros.")enriched_sent = []for token in sentence: # get synsets within the desired domains synsets = token._.wordnet.wordnet_synsets_for_domain(domains) if synsets: lemmas_for_synset = [] for s in synsets: # get synset variants and add to the enriched sentence lemmas_for_synset.extend(s.lemma_names()) enriched_sent.append("({})".format("|".join(set(lemmas_for_synset)))) else: enriched_sent.append(token.text)print(" ".join(enriched_sent))
I (require|want|need) to (draw_off|withdraw|draw|take_out) 5,000 euros .
這個例子看起來很簡單,但是,如果你修改domains列表,你會發現在沒有合理約束的情況下,結果會產生組合爆炸。想象一下,有一個包含數百萬元素的知識圖譜:您希望在可能的地方限制搜索,以避免計算每個查詢需要幾天、幾周、幾個月、幾年的時間。
有時在試圖理解文本時遇到的問題—或者在試圖理解語料庫(包含許多相關文本的數據集)時遇到的問題—會變得非常複雜,您需要首先將其可視化。這有是一個用於理解文本的交互式可視化工具:scattertext(https://spacy.io/universe/project/scattertext),由Jason Kessler主導設計。
Jason Kessler
https://twitter.com/jasonkessler
讓我們來分析一下2012年美國總統大選期間政黨大會的文本數據。注意:這個部分可能需要幾分鐘來運行,但是所有這些數據處理的結果值得等待。
import scattertext as st if "merge_entities" not in nlp.pipe_names: nlp.add_pipe(nlp.create_pipe("merge_entities")) if "merge_noun_chunks" not in nlp.pipe_names: nlp.add_pipe(nlp.create_pipe("merge_noun_chunks")) convention_df = st.SampleCorpora.ConventionData2012.get_data()corpus = st.CorpusFromPandas(convention_df, category_col="party", text_col="text", nlp=nlp).build()
一旦語料庫準備好了,就可以生成一個交互式可視化的HTML:
html = st.produce_scattertext_explorer( corpus, category="democrat", category_name="Democratic", not_category_name="Republican", width_in_pixels=1000, metadata=convention_df["speaker"])
from IPython.display import IFrame file_name = "foo.html" with open(file_name, "wb") as f: f.write(html.encode("utf-8")) IFrame(src=file_name, width = 1200, height=700)
現在我們將渲染html:一到兩分鐘進行加載;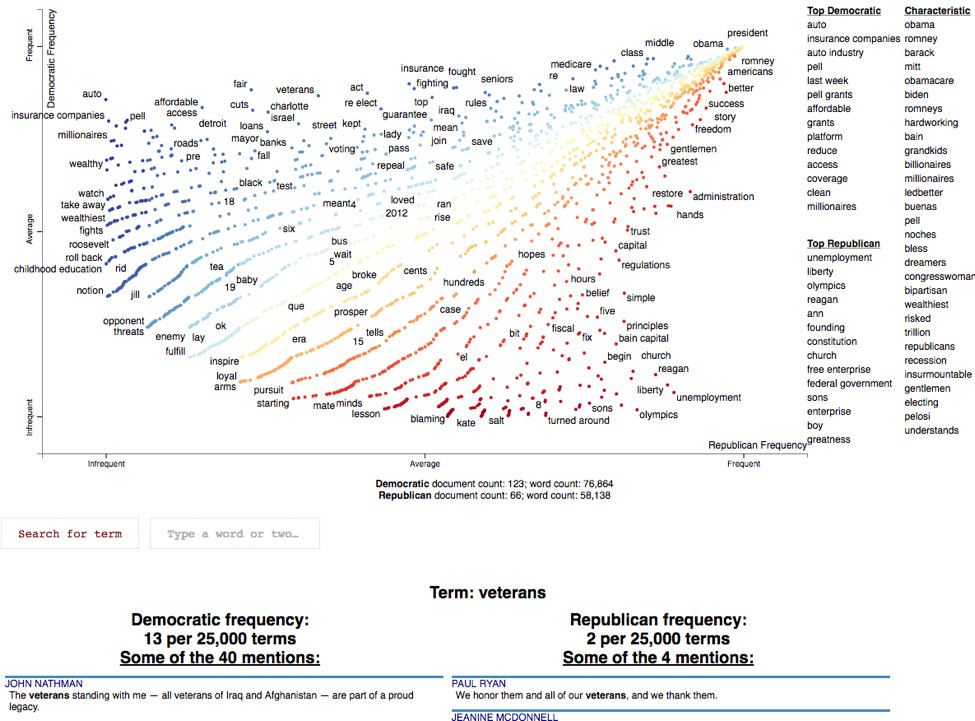
想象一下,如果你的組織中有過去三年客戶支持某個特定產品的文本。假設您的團隊需要了解客戶是如何談論該產品的? 這個scattertext庫可能會非常方便! 您可以將(k=2)聚類在NPS得分(客戶評估指標)上,然後用聚類中的前兩個分類替換民主黨/共和黨維度。
總結
五年前,如果你詢問用Python中的自然語言的開源庫,許多數據科學工作者的默認答案是NLTK(https://www.nltk.org/)。這個項目幾乎包括了所有的東西,除了一些細微的設置,還有一些相對學術的部分。
另一個流行的自然語言項目是來自斯坦福的CoreNLP (https://stanfordnlp.github)。儘管CoreNLP功能強大,但它也非常學術化,不過要將它與其他軟件集成以供生產使用是很有挑戰性的。
幾年前,自然語言的一切都開始發生了變化。spaCy的兩位主要作者——馬修•洪尼巴爾(Matthew Honnibal, https://twitter.com/honnibal)和伊內斯•蒙塔尼(Ines Montani, https://twitter.com/_inesmontani)於2015年啓動了該項目,該項目很快被業界採用。他們採用的是一種專注的方法(做需要做的,把它做好,不多也不少),這種方法能簡單、快速地集成到Python中的數據科學工作集合中,並且比其他方法執行更快、準確性更好。
基於這些,spaCy成爲了NLTK的對立面。自2015年以來,spaCy一直致力於成爲一個開源項目(即,取決於其社區的方向,集成等)和商業級軟件(而非學術研究)。也就是說,spaCy迅速地將機器學習方面的最前沿進展納入中,有效地成爲了將學術研究推廣到工業領域的渠道。
值得注意的是,隨着谷歌開始贏得國際語言翻譯比賽,用於自然語言的的機器學習自2000年中期得到了很大的發展。2017年至2018年期間,隨着深度學習的諸多成功,這些方法開始超越以前的機器學習模型,出現了另一個重大變化。
例如,經Allen AI研究提出的看到ELMo 語言嵌入模型, 隨後是谷歌的BERT,(https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html),以及最近由
百度推出的ERNIE
(https://medium.com/syncedreview/baidus-ernie-tops-google-s-bert-in-chinese-nlp-tasks-d6a42b49223d)——換句話說,搜索引擎巨頭爲我們獻上了一份基於深度學習的嵌入語言模型開源大禮的世界,目前是業界最先進的。
說到這裏,爲了緊隨自然語言的SOTA,可以關注NLP-Progress(http://nlpprogress.com/)和Papers with Cod(https://paperswithcode.com/sota)。
在過去的兩年裏,隨着深度學習技術的興起,自然語言的用例發生了巨大的變化。大約在2014年,使用Python的自然語言教程可能還在教單詞統計、關鍵字搜索或情感檢測,而且目標用例相對顯得平淡無奇。而在2019年,我們談論的是在一個產業供應鏈的優化中分析成千上萬的供應商合同文件,或者是爲保險公司分析的投保人數億份文件,又或者是大量關於財務數據披露的文件。更現代的自然語言工作傾向於在NLU,通常支持知識圖譜的構建,在NLG領域,大量類似的文檔可以被大規模地總結。
廣闊的宇宙(https://spacy.io/universe)很不錯,可以查找特定用例的深度,並查看這個領域是如何發展的。這個「宇宙」的一些選擇包括:
blackstone(https://spacy.io/universe/project/blackstone)-解析非結構化法律信息文本
kindred(https://spacy.io/universe/project/kindred) -從生物醫學文本(如Pharma)中提取實體
mordecai(https://spacy.io/universe/project/mordecai)-解析地理信息
Prodigy(https://spacy.io/universe/project/prodigy)-人機迴圈的標籤數據集註釋spacy-raspberry (https://spacy.io/universe/project/spacy-raspberry) - 樹莓派(Raspberry PI)圖像,用於在邊界設備上運行。
Rasa NLU(https://spacy.io/universe/project/rasa)聊天應用的集合
另外還有一些非常新的項目需要關注:
spacy-pytorch-transformers (https://explosion.ai/blog/spacy-pytorch-transformers)可以用來與BERT, GPT-2, XLNet,等等進行調整。
spaCy IRL 2019(https://irl.spacy.io/2019/)會議-寬大的IRL 2019(https://irl.spacy.io/2019/)會議-查看演講視頻!對於spaCy,我們可以做的還有很多——希望本教程能夠提供介紹。我們祝願你在自然語言學習方面一切順利。
對於spaCy,我們可以做的還有很多——希望本教程能夠提供介紹。我們祝願你在自然語言學習方面一切順利。
原文地址:
https://www.kdnuggets.com/2019/09/natural-language-python-using-spacy-introduction.html