本文結合現有的文獻和方法以及作者自己的實踐理解,詳細闡述了圖卷積在基於骨架的動作識別方向的應用,內容祥實,值得一讀。
文章的脈絡爲:
1. 問題簡述
2. 基本概念介紹
3. 方法和思路分析
4. 文獻解讀
4.1 時空特徵的提取
4.2 更全面的空間特徵抽取策略
4.3 數據增強
4.4 綜合方法
由於篇幅較長,將分爲上下進行發佈。
人體動作識別是近年來 CV 領域的熱門研究方向,其對人機交互、智能監控等應用具有重要意義。骨架動作識別屬於動作識別的一個分支,旨在識別由骨架隨時間變化構成的時間序列所代表的動作類型,即每個樣本由連續的骨架幀構成,維度是 (T,V,C),T 表示時間,V表示關節,C 表示空間位置( XY 或 XYZ),模型需要給出樣本所屬動作類別,因此屬於多分類任務。其另一個分支是 RGB 視頻動作識別。
該任務常用的數據集是 NTU RGB+D 數據集,以及Skeleton-Kinetics(用 openpose 在Kinetics-400視頻數據集中得到 3D 骨架)數據集。
本文主要介紹近兩年來基於圖卷積的骨架動作識別相關工作,圖卷積的標準公式爲:

該公式的嚴密推導過程是從圖的傅里葉變換以及譜域分析開始的,不過可以從空域來簡單理解,即鄰接矩陣 A 乘特徵矩陣H可以聚合(sum, mean, max 等)一階鄰域特徵,自環鄰接I 可以將聚合的鄰居特徵與當前節點特徵合併,最後通過權重矩陣 W 完成通道的變換。矩陣 是度矩陣,用於對自環鄰接矩陣 (A+I) 進行對稱規範化,此外一些論文也使用隨機遊走規範化。
是度矩陣,用於對自環鄰接矩陣 (A+I) 進行對稱規範化,此外一些論文也使用隨機遊走規範化。
圖卷積的核心思想是建立圖中不同節點之間的信息交流,從而學習圖中每個節點的嵌入特徵表示,在只考慮一階鄰域的條件下,隨着網絡層數加深,每個節點的感受野都會越來越大,最終覆蓋全圖,實現信息的完全交互。
對於圖分類任務,在最後一層圖卷積後,通常會經過一層 readout 層,得到整個圖的表示,然後用這個表示來進行分類。對於骨架動作識別任務,每個樣本都由圖序列構成,因此需要在時間和空間維度同時進行 readout,通常是 pooling。
筆者認爲該任務可以從三個領域借鑑方法:
1. 骨架通常由關節(joint)和骨骼(bone)相互連接表示,具有天然的圖結構,因此可以藉助 GNN 強大的空間特徵抽取能力,來學習動作的潛在表示。事實上從 18 年開始,絕大部分骨架動作識別相關工作都是基於圖卷積網絡的。
2. 骨架序列屬於時間序列,因此可以利用時間序列建模的相關方法來獲取時間特徵,例如 GRU、LSTM、3D 卷積等。
3. 骨架動作識別與視頻動作識別都需要通過模型來提取動作的潛在特徵,特別是時空特徵的提取,因此可以相互借鑑方法。
此外,也有學者提出了其他的方法,例如可以將骨架序列轉化爲 RGB 圖片,這樣該問題就轉化爲圖像分類問題(18 年之前的主流方法),也有基於 KNN 和貝葉斯的相關方法,總之解決問題的思路方法是多元化的,不侷限於某一特定領域。在筆者閱讀相關文獻時,總結出了一些常見的改進(漲分)思路:
數據增強:原始骨架數據反映的骨架位置信息,如果對相鄰兩幀求差值,便可以得到骨架的一階動態信息,對相鄰關節求差值亦可以得到骨骼動態信息。理論上模型也能學習到這些信息,但提前計算出來並作爲輸入,可以在一定程度上提升準確率。
類鄰接矩陣策略:GCN 中使用的鄰接矩陣只包含一階鄰域,每個節點的感受野都非常有限,只有達到足夠深度,網絡層才能學習到遠端關節之間的語義信息。此外,傳統的鄰接矩陣元素只有 0 和 1 兩種值,在多數情況下很難反應關節間的相互關係。因此,設計一種不限於一階鄰域和整數值的鄰接矩陣,是許多工作的探究點。對於骨架動作識別任務,主要建立非骨骼連接的關節之間的聯繫,例如手腕和腳踝。
注意力機制:Self-attention 及其相關變體在最近幾年很火,例如由何愷明團隊提出的 non-local 模塊,在視頻行爲識別、目標檢測等任務上都取得了不錯的效果。對動作識別而言,每個動作的信息往往集中在某一個或幾個關節,而且肢節末端的關節由於運動更頻繁,幅度更大,往往具有更多的關鍵信息,因此空間注意力是值得探究的點。
圖結構拓展:通常在構建圖時,只將關節作爲圖的節點,然而骨骼(bones)與關節具有密不可分的關係,雖然視覺上骨骼通常是長條形的,但仍然可以抽象爲一個點參與圖卷積。這種做法可以顯著提升圖的分辨率以及對空間信息的表達能力。
局部劃分(part-based)方法:同一肢節或同一個區域內的關節之間運動相似度會更高,按這個規律可以將骨架分爲多個區域(part),在區域內和區域間定義不同的信息傳播方式,可以有效的提取局部和全局特徵。這種方法稱爲part-based method。
因此由於水平有限,不能寫得通俗易懂,可能會造成一些內容理解起來困難,因此建議結合原文閱讀,還請諒解。此外,在解讀文獻時,陳述順序和原文的順序會有一些出入,這是因爲不同文獻側重點不同,我會盡量按照我認爲的合理順序來分析。
此外,我會根據個人理解,從一些簡單,通俗易懂的工作開始介紹,然後再介紹相對複雜的工作,這樣有助於大家理清該領域的研究思路和方向。
時空特徵的提取
圖結構序列與視頻一樣,都兼具時間和空間特徵,因此如何在 GCN 的基礎上,設計對時空特徵的抽取方法,是構造網絡時必須考慮的問題。
DPRL: Deep Progressive Reinforcement Learning for Skeleton-based Action Recognition(CVPR,2018)
http://openaccess.thecvf.com/content_cvpr_2018/CameraReady/1736.pdf
通過強化學習幀蒸餾方法(frame distillation)來選擇最具代表性的幀,然後再通過圖卷積網絡抽取空間信息。前者是時間上的類注意力方法,後者則是空間上的特徵抽取方法,整體網絡結構如下:
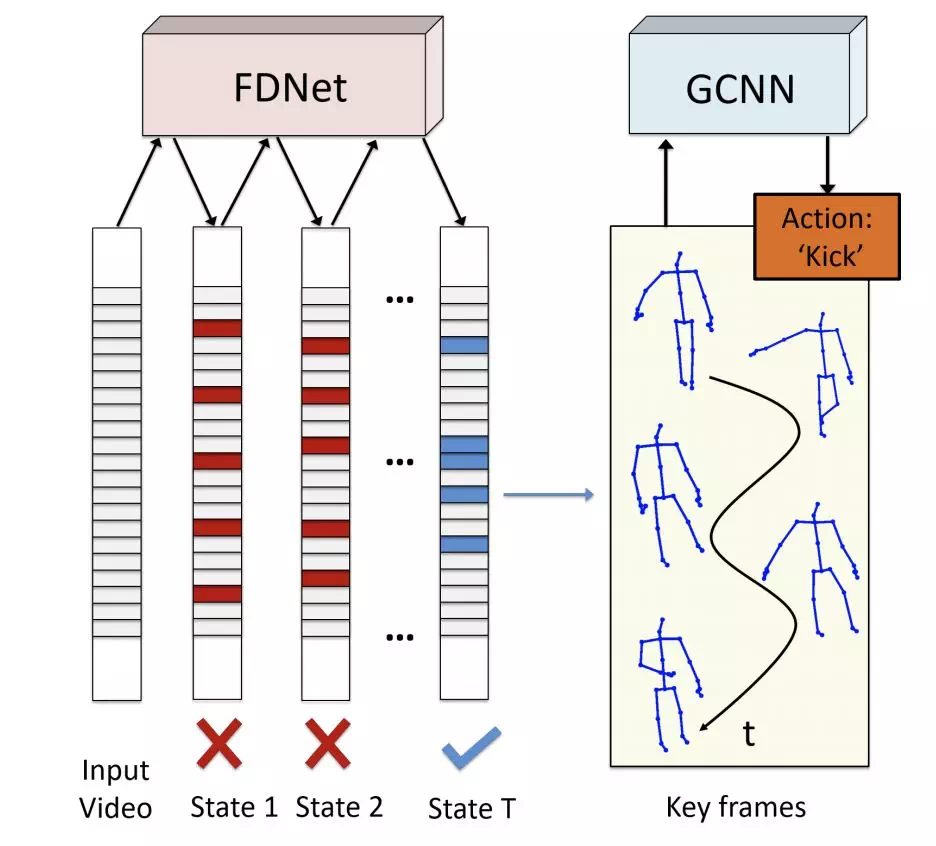
網絡結構
深度漸進式強化學習(DPRL)
幀蒸餾網絡對應中的 FDNet。樣本中不同幀所含信息不同,且許多相鄰幀往往具有大量的冗餘信息,該工作通過強化學習蒸餾方法從原始幀序列中挑選最具代表力,可識別力的幀參與圖卷積,使網絡能得到更多的有用信息,而丟棄哪些混淆度強的無用信息。具體方法在文獻中有詳細介紹。

基於強化學習的幀蒸餾網絡
類鄰接矩陣策略
這篇文章是典型的類鄰接矩陣策略。通過手工構建的非骨骼連接(下圖虛線)來強化節點之間的信息交流,提高節點的感受野對於某些動作而言,其主要運動關節在原始骨架中並不是直接相連的,例如拍手動作,這就意味着在1鄰域的情況下,需要經過多次卷積兩手之間纔會有互相得到對方的信息,如果讓他們直接相連,可以讓信息在更淺的網絡層得到交互,更深的網絡學習到的特徵信息也更加穩定準確。
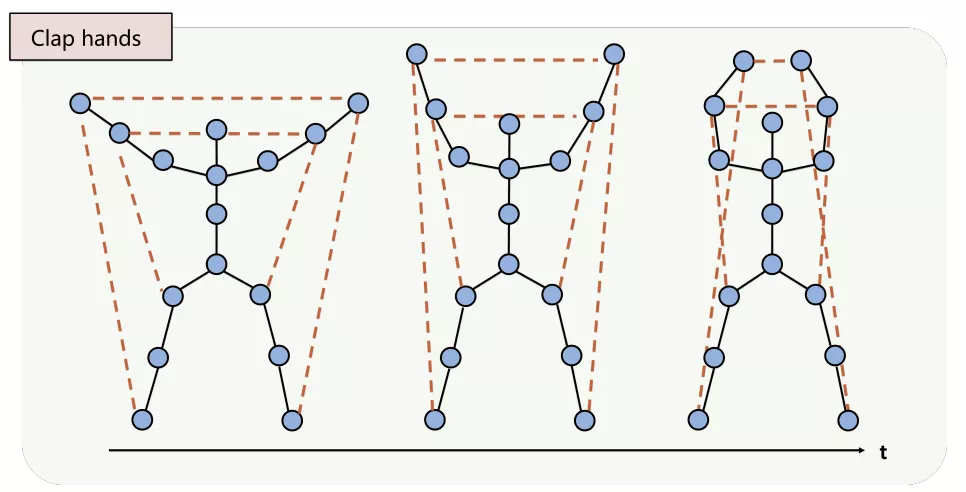
人工構建的非骨骼連接
具體地,對於固有骨骼連接,在鄰接矩陣中用一個可學習參數 α 來代表連接權重,對非固有鄰接,用可學習參數 β 來代表連接權重。
此外,在進行圖卷積時,由於輸入是圖序列,因此會對每一幀單獨進行圖卷積,然後在時間維度上進行 concate,從而得到整個圖序列的 feature map 。
實驗結果
在 NTU 數據上的實驗結果,左右兩列分別是 cross subject 和 cross view:

總結
該工作提出的幀蒸餾網絡在思想上與注意力機制一致,即挑選出有意義,感興趣的部分,而空間上的非物理連接則能有效的提高特徵聚合速度,此外自學習的鄰接矩陣參數能讓重要關節得到更多的關注。
02
ST-GCN: Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition(AAAI, 2018)
https://arxiv.org/pdf/1801.07455.pdf
一篇非常具有代表性的文章,其核心思想是通過空域上的圖卷積和時域上的常規卷積,來聚合時間和空間特徵。
時空圖卷積
借鑑了視頻動作識別中對 3D 卷積分解爲 (2+1)D 的思想,通過空間上的圖卷積來提取空間信息,通過前後相鄰幀的常規卷積來提取時間信息,通過二者的串聯疊加來逐步提取時空信息。這麼做相當於將每個節點的感受野擴大到的時空範圍。

時空圖卷積示意圖
假設 feature map 維度是(C, T, V)每個 block 由兩部分組成:
1.對每一幀的圖卷積:
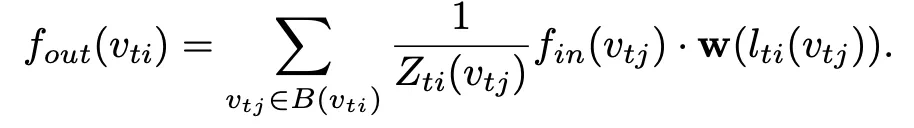
2. 在 T 維度進行的常規卷積,卷積核大小是(τ,1)。
此外圖卷積和整個 block 都包含 residual 連接。
鄰域劃分策略
節點鄰域是節點的鄰居節點的集合,體現在鄰接矩陣中。標準 GCN 對所有節點使用同一個權重矩陣,但人體運動過程中,存在關節距離重心越遠,運動幅度越大的規律,即包含的信息越多,因此本文提出將鄰域分爲三個部分:自身,近重心,遠重心,如下圖中的(d):

三種不同的鄰域劃分策略
劃分過後對每個節點而言,其鄰域會分爲三個部分,因此圖的鄰接矩陣就分爲了三個子鄰接矩陣,每個矩陣單獨享有一個卷積權重,分別進行圖卷積,最後通過加法疊加結果。這樣劃分會導致參數數量增加(擴增 3 倍),但網絡對空間特徵細節的刻畫能力也更加強。
鄰接矩陣自學習策略
通過爲鄰接矩陣賦予一個等大小的權重矩陣,可以讓網絡自動學習邊與邊之間的連接權重:

M 表示待學習的權重矩陣(全 1 初始化),Aj 表示第 j 個鄰域對應的鄰接矩陣,通過二者的 hardmard 乘積得到最終的鄰接矩陣。這種做法可以在一定程度上提高對已有物理連接的刻畫能力,但不能使 A 中的 0 值變爲非 0 值,即不能在關節間建立非物理連接。
提出新數據集
本文通過 openpose 從視頻中提取 2D 骨架序列,再將置信度作爲 z 軸,從而得到 3D 骨架序列,由此從Kinetics-400視頻行爲數據集中得到了Kinetics-skeleton 骨架行爲數據集。
實驗結果
在 NTU 數據集上的實驗結果:

在 Kinetics-skeleton 數據集上的實驗結果:
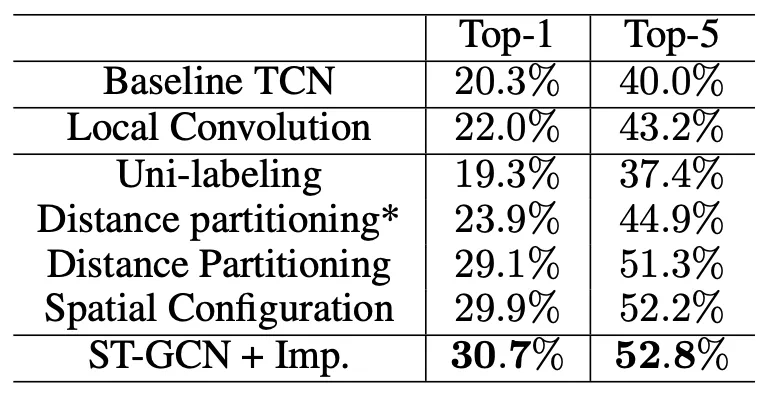
總結
本文通過線性堆疊的 GCN 和 TCN 來間接擴大每個節點的感受野,非常有助於時空信息的提取。對鄰域的經驗性劃分雖然會增加參數數量,但也能提高網絡對不同關節特徵的刻畫能力。此外,自學習的 mask 參數能讓關節連接權重更加平滑,但相較於 DPRL,本文沒有建立非相鄰關節之間的直接連接,因此遠端關節之間的信息交互會更困難。而對於 DPRL,其使用的是人工定義的非骨骼連接,因此對空間信息的刻畫能力非常有限。
更全面的空間特徵抽取策略
雖然骨架代表了物理上真實存在的關節連接,但在骨架的基礎上建立更多的非物理連接,甚至是關節的強連通圖,能提高每個節點的感受野,從而讓網絡在淺層就能學習到更多的有用信息。
HCN: Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation
https://arxiv.org/pdf/1804.06055.pdf
這篇文章提出的方法在 GCN 相關工作出現之前效果最佳,這裏簡要介紹。

HCN網絡結構示意圖
這裏輸入 Input 的大小是 T*V*C,T 是幀長度,V是節點數量,C 是輸入通道。
開始的兩層卷積是常規的通道卷積,然後將 V 和 C 維度對調,這樣接下來的卷積就會將 V作爲通道處理,而卷積對通道的操作是全連接,因此任意兩個節點都會進行加權求和。這種做法體現在圖上,相當於建立任意兩個節點之間的可學習權重連接,將圖當成強連通圖對待。因此該方法雖然沒有直接使用圖卷積,卻仍然能取得不錯的效果。
實驗結果
NTU 數據集:

02
2S-AGCN: Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition(CVPR, 2019)
https://arxiv.org/pdf/1805.07694.pdf
本文在 ST-GCN 的基礎上,提出了更加合理的鄰接矩陣策略,不僅包含自學習的鄰接矩陣,還通過 self-attention 機制爲每個樣本計算單獨的鄰接矩陣,大大增強了網絡對空間特徵的抽取能力。
數據增強
即將 bones 流作爲獨立數據流,獨立於 joint 流進行訓練。預測時結合兩個網絡的預測值,得到最終預測結果:

適應性鄰接矩陣策略
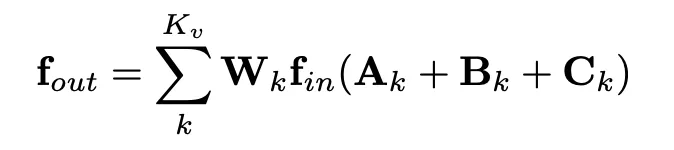
這裏的 k 表示三種不同的領域,即 ST-GCN 中的 spatial 鄰域劃分策略。鄰接矩陣由三部分構成:
Ak 是基礎鄰接矩陣,值只有 0 和 1,只包含關節間原有的直接物理連接。
Bk 是權重鄰接矩陣,初始化爲 0,由網絡自動學習。
Ck 是 attention 鄰接矩陣,計算方式爲embedded 高斯函數:


T 表示轉置。這部分主要借鑑了 「non-local neural network」 和 「attention is all you need」 中提出的self-attention 方法,但不同於何愷明的 non-local網絡,這裏是用關節的軌跡來計算兩個關節之間的attention 值,時間維度被合併到了 C 中,這麼做可以降低計算量和參數量,防止過擬合。
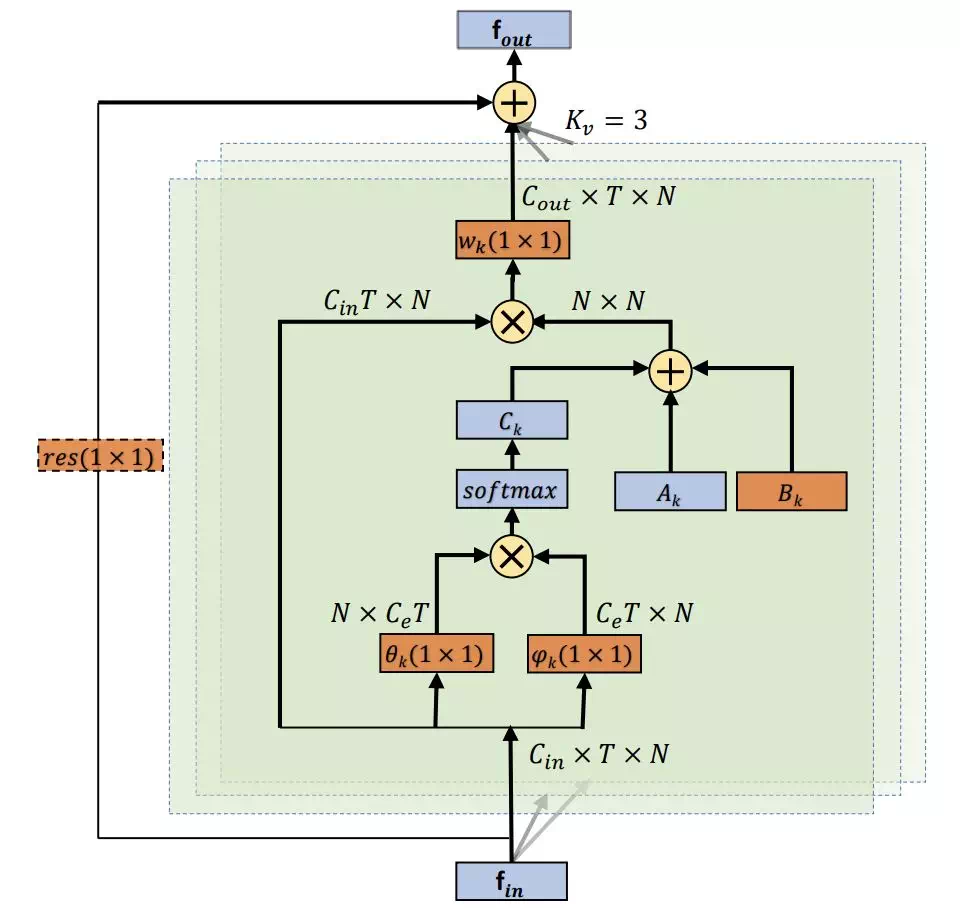
三個鄰接矩陣的整體計算過程可以用類似於 non-local 網絡中的圖例來表示:
實驗結果
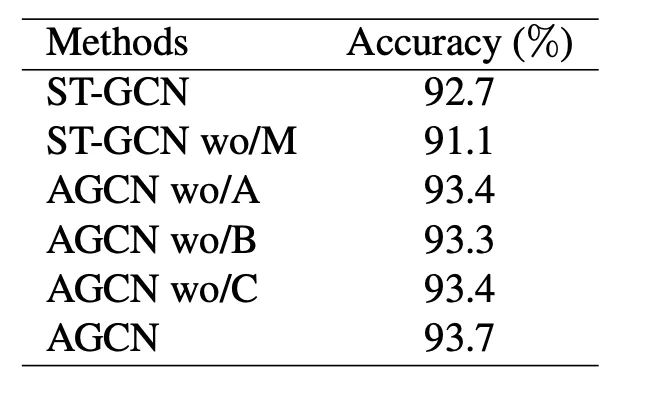
在 NTU cross view上的 Ablation 實驗:
個人認爲在 cross subject 條件下對比會比較明顯。NTU 數據集:
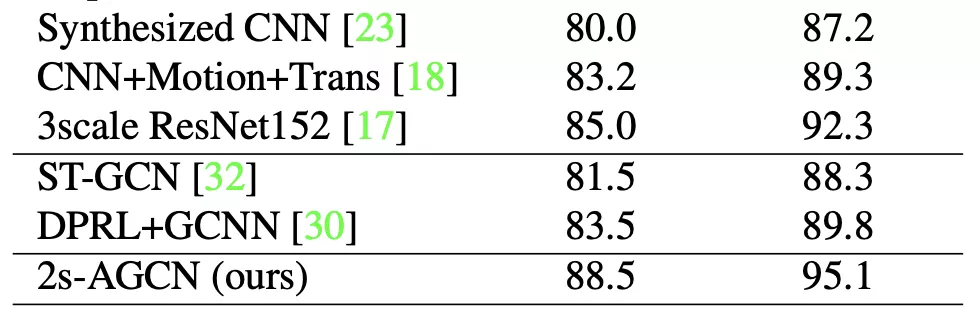
Kinetics-Skeleton 數據集:

03
DGNN:Skeleton-Based Action Recognition with Directed Graph Neural Networks
https://url.cn/5x6EUs3
在 ST-GCN 和 2S-AGCN 的基礎上進一步提高了抽取空間特徵時的細粒度。
有向圖信息傳播
在 ST-GCN 中提出的鄰域劃分策略,實際上可以概括爲不同的信息傳播方向區別對待,信息從末端關節流向中心關節和從中心關節流向末端關節應該區別對待。因此本文用有向圖來處理不同的信息方向:
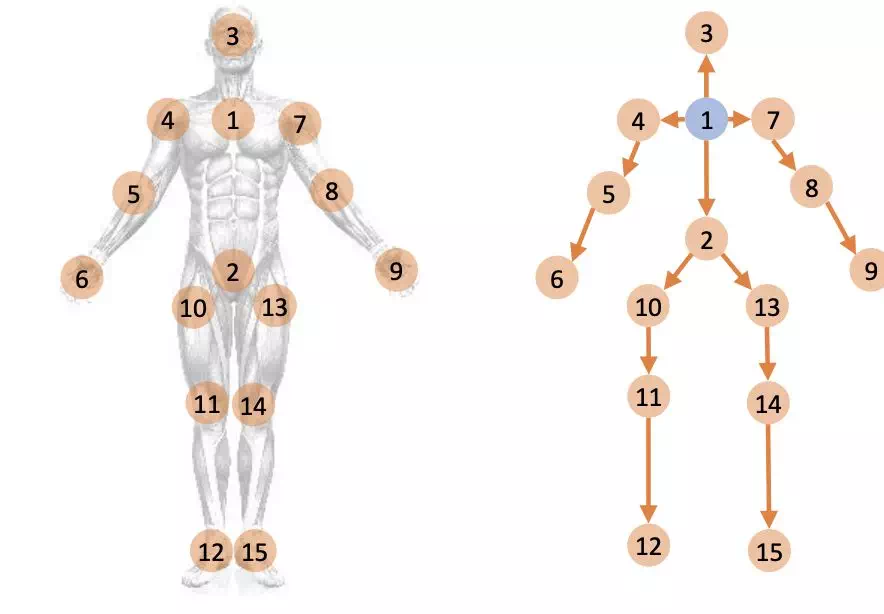
此外在,2S-AGCN 中 bones 流和 joints 流相互獨立,然而二者實際上應該具有更加緊密的聯繫,因此本文將 Bones 也作爲一種節點參與到信息流傳播中,這樣可以提高空間特徵的細粒度。這與 Sym-GNN 中的 AGC 部分有一定的相似之處。
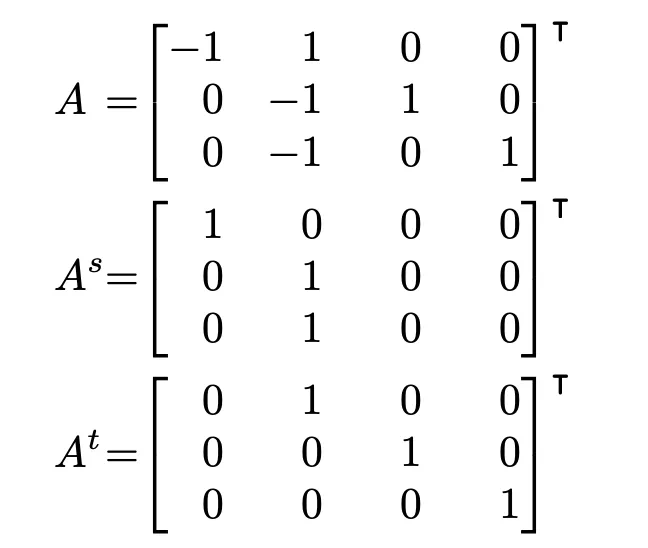
結合以上兩點,可以用關聯矩陣(incidence matrix)來表示節點和邊之間的連接關係,關聯矩陣規模是 (Nv , Ne),即節點數和邊數。關聯矩陣中1 表示節點是邊的源節點,-1 表示目標節點。進一步地可以將源節點關聯矩陣和目標節點關聯矩陣分開:
在進行信息傳播時,先分別以節點和邊爲中心聚合特徵,然後再更新節點和邊的值:

g 表示聚合函數,通過關聯矩陣圖卷積進行聚合,h 表示更新函數,這裏是 1*1 卷積(即FC 層)。假設某一層輸入通道是 Cin,輸出通道數是 Cout,則 1*1 卷積的卷積核大小爲3*Cin*Cout,要比標準圖卷積中 Cin*Cout 的卷積核大三倍。因此參數數量相對來講要多很多。
數據增強
本文將 motion 流作爲另一個獨立訓練的數據流,bone 和 joints 計算 motion 值的方法相同,即計算兩幀差值。
實驗結果
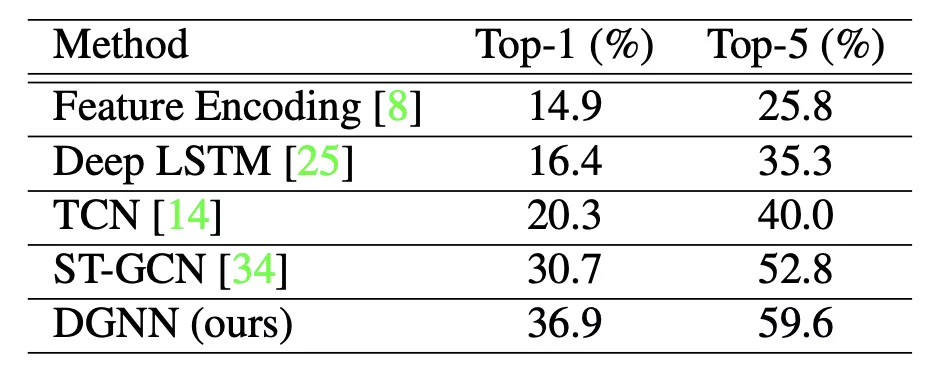
NTU 數據集:

Kinetics-Skeleton 數據集:
03
PBGCN: Part-based Graph Convolutional Network for Action Recognition(BMVC, 2019
典型的 part-based 方法,將人體骨架分爲多個子圖,定義了子圖內部和子圖之間的信息傳播方式,這樣便能更好的抽取局部關節信息,同時加快信息傳播速度。

何(geometric)特徵與動力學(kinematic)特徵
這裏的幾何信息就是骨骼特徵(包含非骨骼連接),即在空間上計算相鄰關節座標差值,動力學特徵就是運動特徵,通過計算相鄰幀對應關節的差值得到。
基於局部劃分的圖卷積(PBGC)
首先將人體骨架圖分爲多個子圖:

並且保證相鄰兩個子圖間至少有一個公共關節。然後對每個節點,首先在其所在的子圖內執行圖卷積,再執行子圖間的信息傳播:
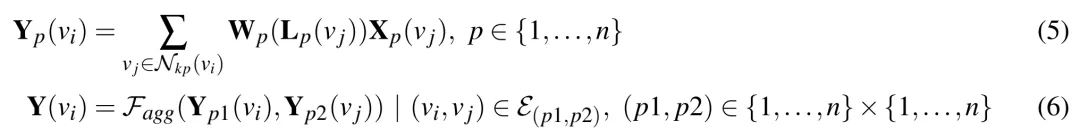
其中(5)表示在分圖p中的點vi的卷積結果,Nkp是點vi在子圖p中的鄰接節點集合,Wp表示點子圖p的權重矩陣(不與其他子圖共享),(6)表示點vi與相鄰子圖的鄰接節點之間的信息聚合。其中聚合函數定義如下:
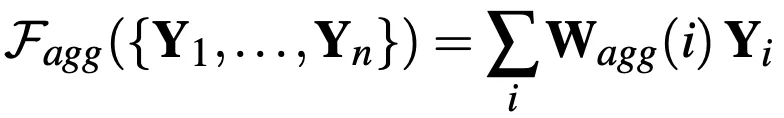
即加權平均。因此,每個點先在其所屬子圖內的鄰域進行圖卷積,再與相鄰子圖的鄰接節點進行信息聚合。
由於不同子圖之間不共享權重,因此子圖劃分策略就異常重要。本文提出了多種不同的劃分策略,可以按上下不同肢體劃分,可以按左右劃分,其中效果最好的是四部劃分:
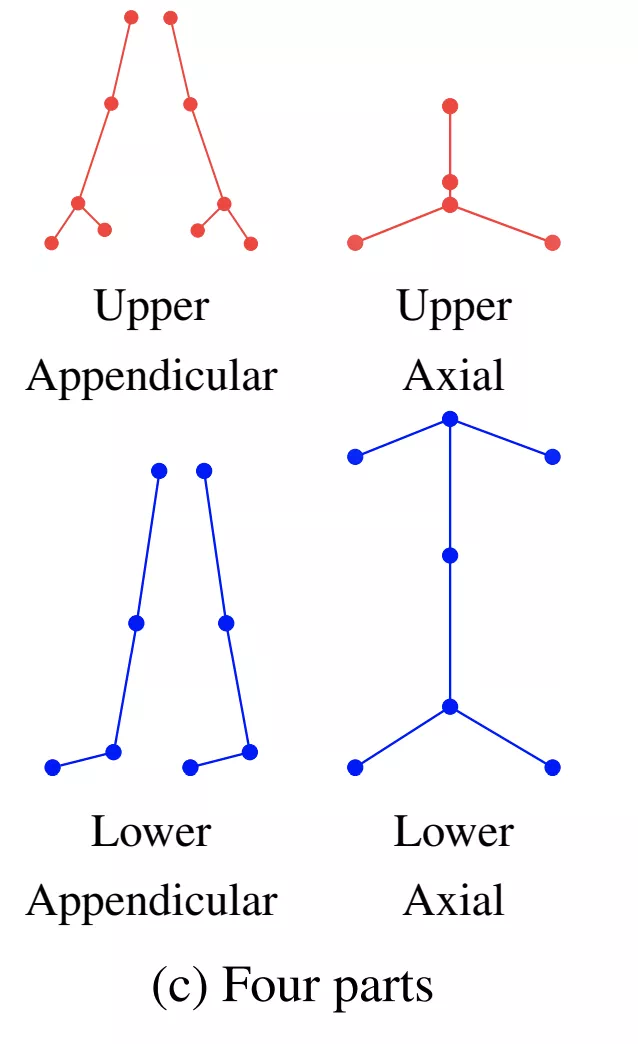
這是因爲人體骨架左右對稱,左手和右手往往具有非常相似的行爲,適合共享權重,而不同類型的肢體往往具有不同的運動特徵,因此適合劃分到不同子圖。
時空圖卷積
這部分與ST-GCN中的時空圖卷積比較相似。

公式15表示時域卷積,將每個關節與該關節前後τ幀內的值做加權求和。
04
2s-SDGCN Spatial Residual Layer and Dense Connection Block Enhanced Spatial Temporal Graph Convolutional Network for Skeleton-Based Action Recognition(ICCV 2019,workshop)
本文方法相對較簡單,即認爲空間信息重要性更強,因此在殘差連接中也進行圖卷積:
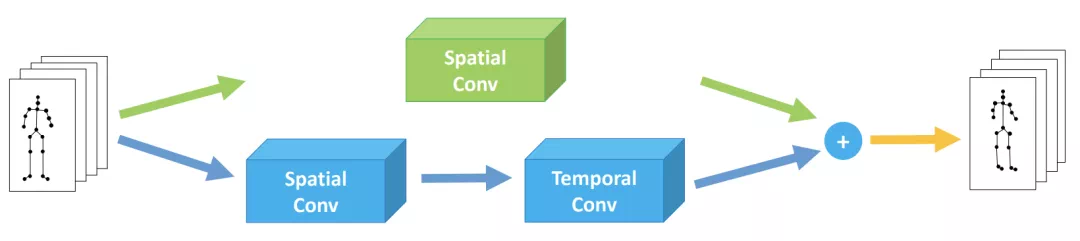
上方綠色部分是本文使用的殘差連接,而ST-GCN是用的殘差連接只有簡單的通道變換,沒有鄰接矩陣參與運算。
用公式表示如下:
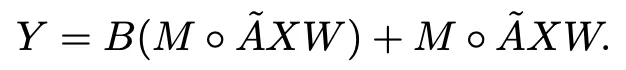
此外,還添加了dense連接(DCB):

將這兩種方法結合到一起,再嵌入到其他方法中。
05
STGR: Spatio-temporal graph routing for skeleton-based action recognition(AAAI, 2019)
本文從時間和空間的角度設計了鄰接矩陣計算方法,以計算節點之間的時間和空間關係。雖然設計了較爲複雜的鄰接矩陣策略,但效果並不如2S-AGCN。
空間圖路由子網絡
首先根據一種無參數圖劃分策略,將每一幀的原始圖劃分爲K個子圖。將每個子圖都當成強連通圖,這樣就能得到空間圖序列:
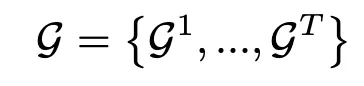
 爲1時,表示關節i與j在時刻t是相連的,爲0時表示不相連,是否相連是根據子圖劃分情況來決定的,而任意兩個子圖的節點之間都不會相連(完全隔離)。
爲1時,表示關節i與j在時刻t是相連的,爲0時表示不相連,是否相連是根據子圖劃分情況來決定的,而任意兩個子圖的節點之間都不會相連(完全隔離)。
得到了空間連接圖序列後,就要從所有圖中選出最具信息的一個,首先用7*7的卷積來聚集局部特徵,然後再全局取平均(GAP):
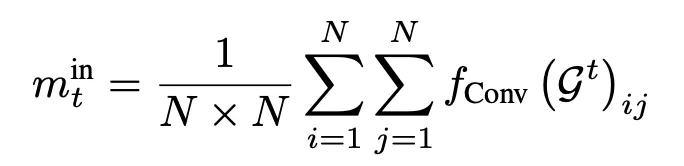
這樣就將每一時刻的圖都用一個標量值來表示:
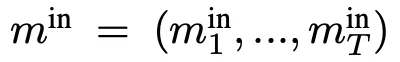
這樣 就包含了圖的所有信息,並且是一個序列。使用兩層全連接層來對m進行進一步加權:
就包含了圖的所有信息,並且是一個序列。使用兩層全連接層來對m進行進一步加權:
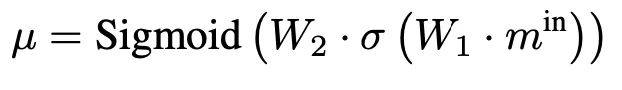
其中:

得到的μ也是一個長爲T的權重向量,將T作爲權值,回代到原圖G中,並在時間範圍做平均:
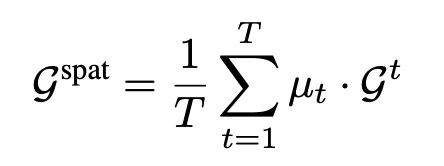
整個這一步,實際上就是對每個時刻的圖做了一次加權平均。
時間路由子網絡
首先將輸入序列用每個關節的時序軌跡來表示,這樣就得到了N個獨立的關節軌跡。接着用一個LSTM來學習每個關節軌跡的淺層表示:

將LSTM最後一個時間步的隱狀態作爲該關節軌跡的最終表示。(這裏說LSTM在不同關節軌跡間參數不共享)得到關節特徵經過編碼後的特徵序列:
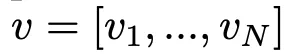
接着通過FC層轉換和向量點乘(類似於embedded高斯函數)來計算兩個關節之間的聯繫:
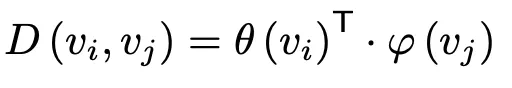
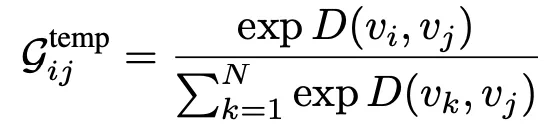
最終學習到關節之間的時域聯繫。
時空特徵融合
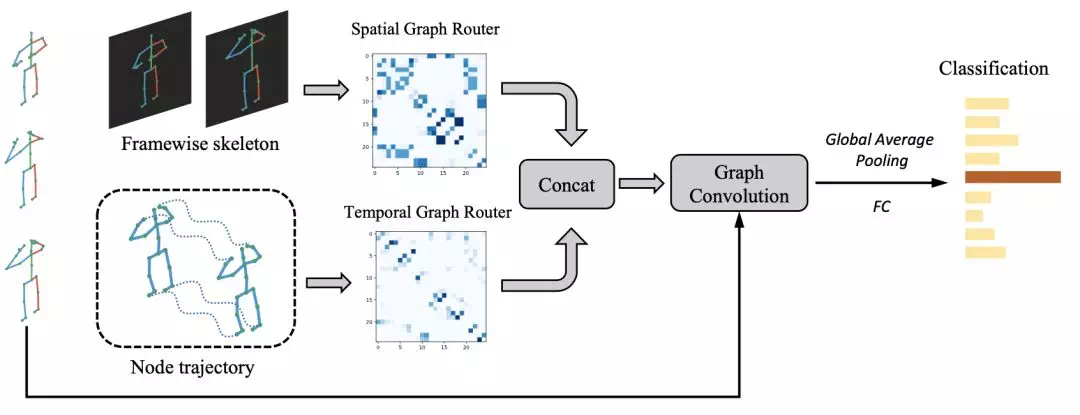
網絡結構示意圖
通過concate的方法融合學習到的圖,然後進行圖卷積。
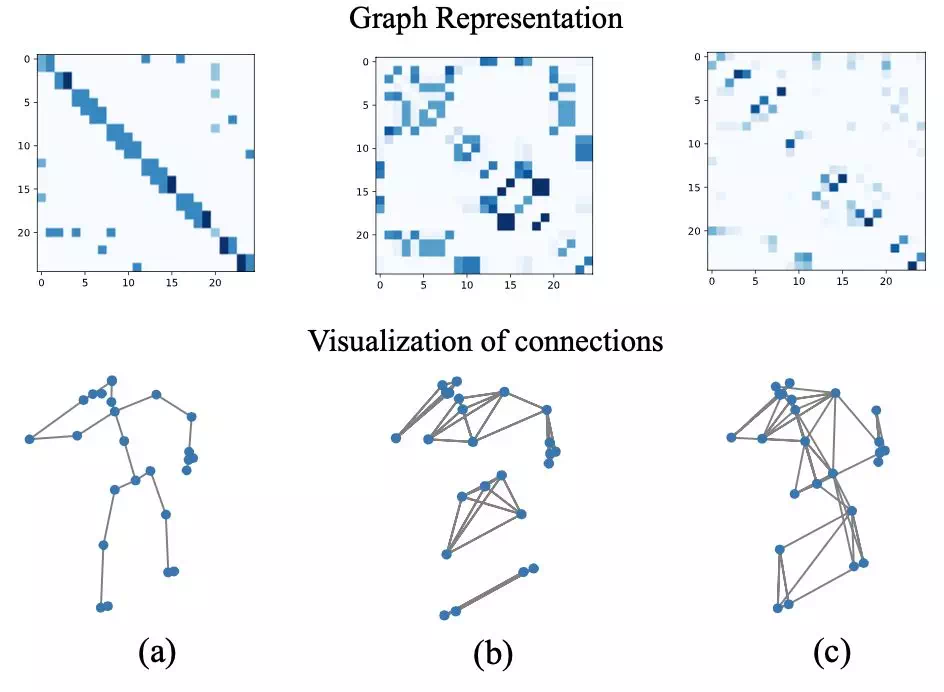
關節連接可視化
圖(a)是關節的原始關節骨骼連接,圖(b)是空間圖路由學習到的關節連接,圖(c)是時間圖路由學習到的連接。
學習到了時間和空間圖分別對應各自的鄰接矩陣,在進行圖卷積時通過加法進行特徵融合:
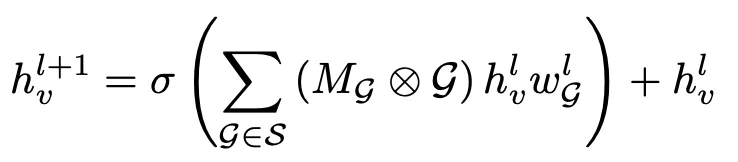
其中 。這個公式和ST-GCN很相似,只不過ST-GCN中只有三個不同的空間圖,沒有時間圖。因此本文的工作實際上就是在ST-GCN的基礎上,增加了兩個額外的鄰接矩陣策略,其他地方沒有明顯改動。優化時不僅使用分類損失函數,還使用圖稀疏損失函數,以確保圖的稀疏性:
。這個公式和ST-GCN很相似,只不過ST-GCN中只有三個不同的空間圖,沒有時間圖。因此本文的工作實際上就是在ST-GCN的基礎上,增加了兩個額外的鄰接矩陣策略,其他地方沒有明顯改動。優化時不僅使用分類損失函數,還使用圖稀疏損失函數,以確保圖的稀疏性:

06
AGC-LSTM: An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognition(CVPR,2019)
傳統的 LSTM 每一時間步的輸入都是一維向量, convLSTM 將卷積操作作爲元計算方式,從而讓LSTM 可以接受圖片時間序列作爲輸入,進一步地,本文將 GCN 作爲 LSTM 的元計算方式,從而可以讓 LSTM 可以接受圖時間序列作爲輸入。
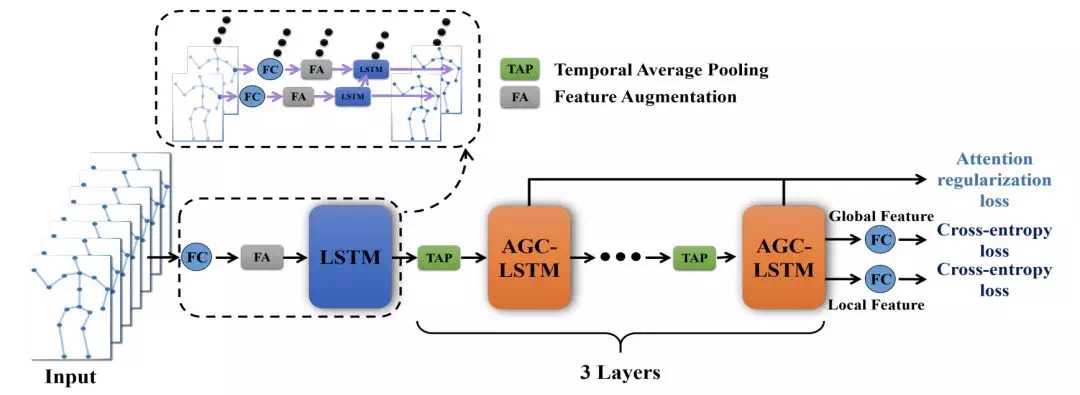
數據增強
通過求相鄰幀插值可以得到motion信息,再通過FC和將motion信息與原始數據結合,然後通過LSTM進行初步的通道擴張:
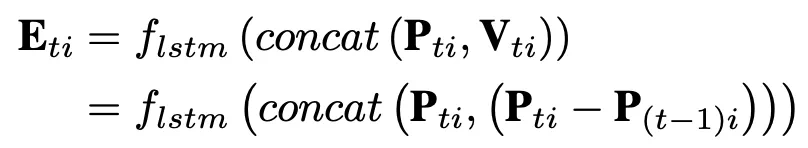
得到的Eti具有512通道數,作爲LSTM網絡的輸入。此外,本文還將part流作爲另一個數據流:
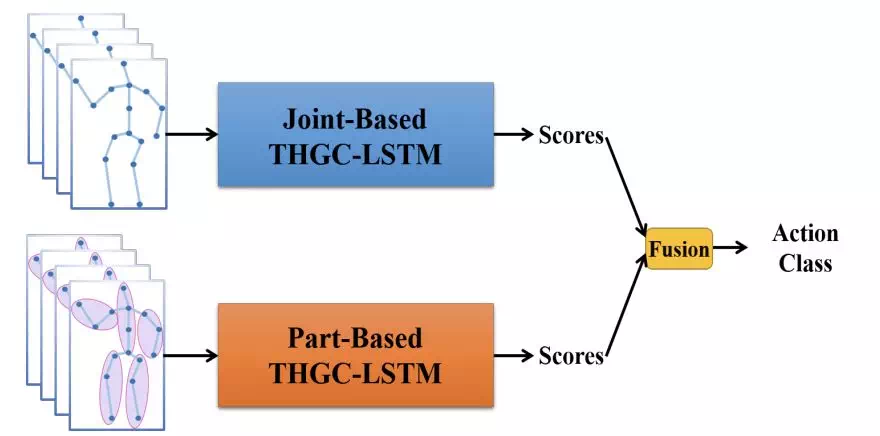
通過雙流融合來提升效果。
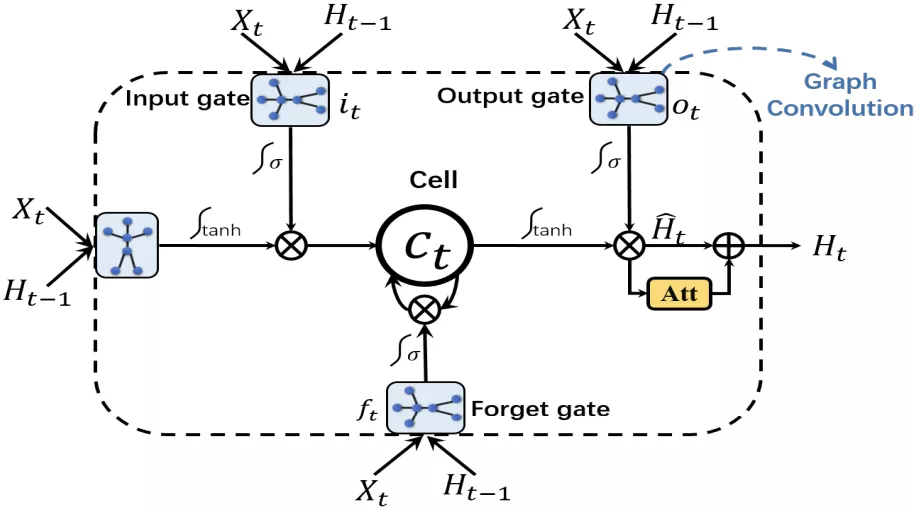
注意力增強型圖卷積LSTM網絡
和傳統LSTM一樣都具有三個門結構,輸入門,遺忘門,輸出門。但是這些門是通過圖卷積操作來計算的。單元結構和計算公式如下:

空間注意力機制
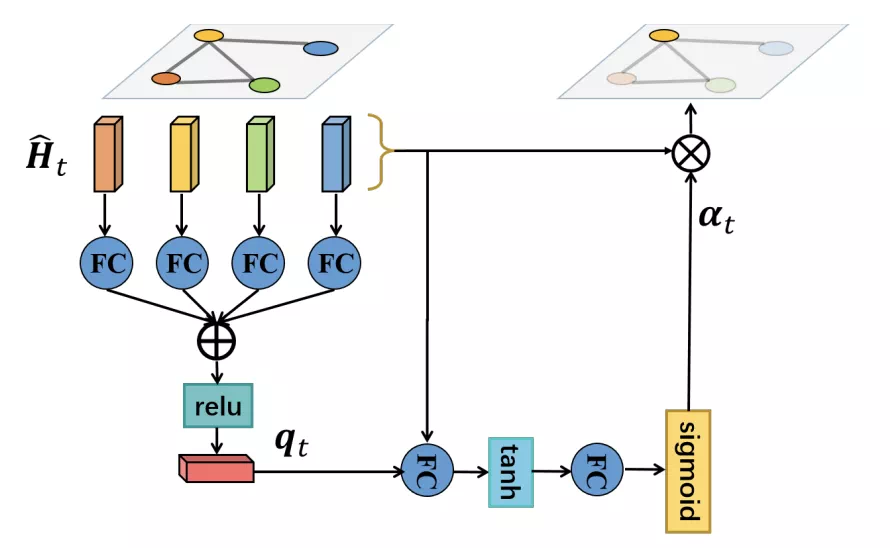
對每個時步而言,將其所有節點對應的輸出值加權求和:

然後再添加res連接:
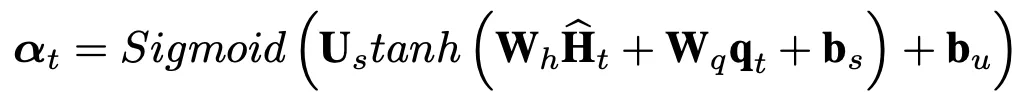
計算得到一個attention係數αt,注意αt長度是一個長度爲N(節點數)的向量,最終該時間步節點 i 的輸出值爲:
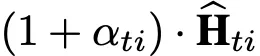
在最後一層,將不同節點的輸出聚合起來,就得到了該時間步的最終輸出值:
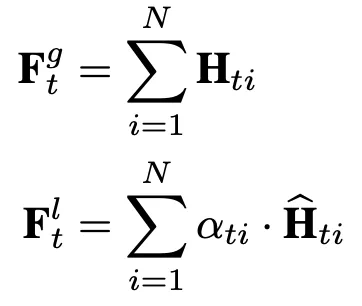
得到的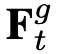 (global)和
(global)和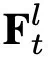 (local)用於最終的動作類別預測。
(local)用於最終的動作類別預測。
時序平均池化
在AGC-LSTM層之間進行時間維度上的池化,可以逐步提高AGC-LSTM層的時間感受野,同時也能大幅度降低計算量。
損失函數
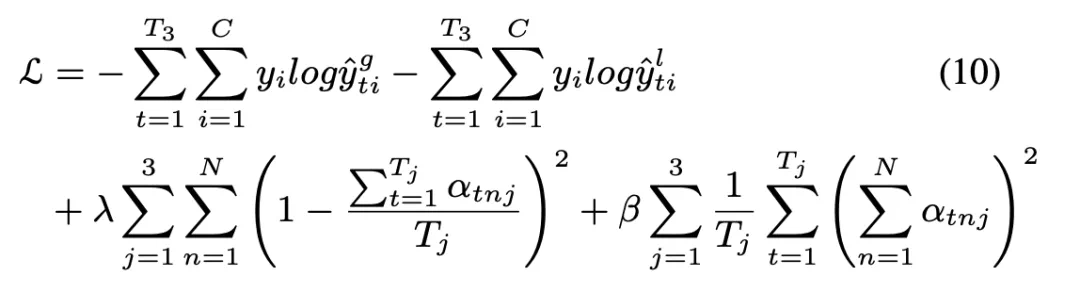
不僅對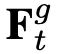 和
和 輸出進行監督,還額外對他們的 attention 值進行監督,第三項保證對不同的關節賦予的相同的注意力,第四項保證關注的關節數量是有限的。
輸出進行監督,還額外對他們的 attention 值進行監督,第三項保證對不同的關節賦予的相同的注意力,第四項保證關注的關節數量是有限的。
筆者認爲只要是多輸入網絡,不侷限於單純的關節位置,就可以看成是一種數據增強方法。從前面的一些文章中可以發現數據增強是廣泛使用的策略,這裏介紹一些以數據增強爲核心的文章。
01
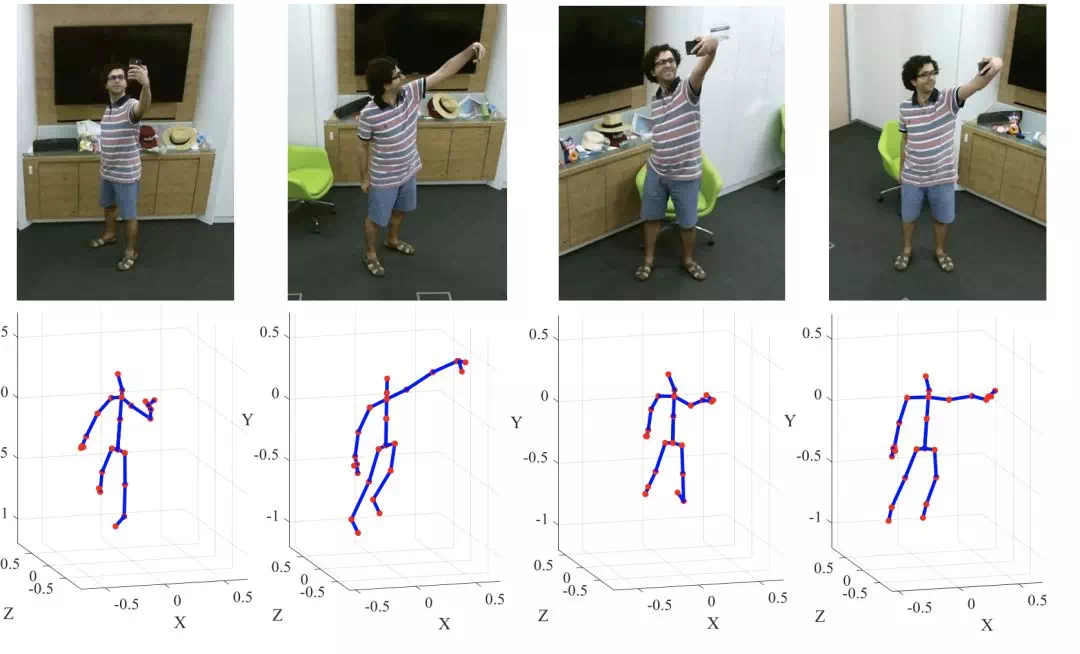
VA-fusion: View Adaptive Neural Networks for High Performance Skeleton-based Human Action Recognition(TPAMI, 2018)
光學估計和穿戴式傳感器是目前常用的兩種三維運動數據採集方法。而光學估計會受到機位和視角的影響,即對同一段動作,在不同的機位和角度下,估計得到的3D骨骼數據是有差異的:
本文提出了一種視角自動學習網絡來解決這個問題,即讓網絡自行學習最佳的攝像機視角,即對骨架進行一定的旋轉和平移,參數爲[αt, βt, γt, dt],其中前三個分別對應是三個軸的旋轉參數,dt表示位移,因此變換公式爲:

對每一幀,都有一組對應的視角變換參數。
可以分別在RNN和CNN上學習視角變換,不同的網絡對應不同的變換方法:
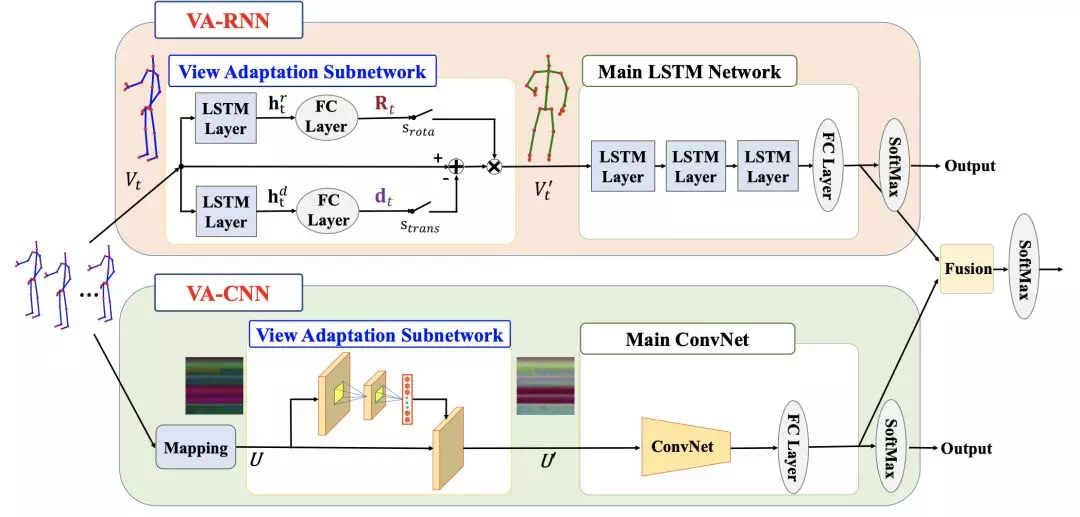
其中LSTM作爲主網絡時,通過LSTM層學習四個參數(對每一幀)在CNN作爲主網絡時,先將骨架映射爲僞RGB圖,然後通過以下公式進行座標變換:
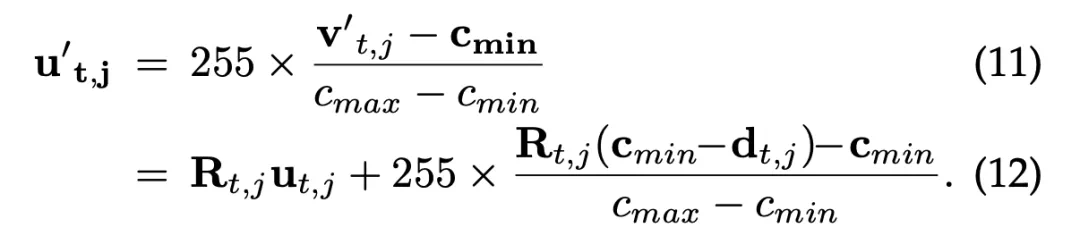
其中 R 是旋轉矩陣,由旋轉參數得到。
本文還提出了隨機旋轉骨架的數據增強方法,可以在一定程度上降低過擬合。此外,將座標原點移動到每個動作第一幀的身體中心,這樣可以讓網絡對起始位置不敏感。
02
3SCNN:Three-Stream Convolutional Neural Network with Multi-task and Ensemble Learning for 3D Action Recognition(CVPR workshop, 2019)
傳統的數據增強方法中,joint, bone, motion數據通常是獨立的,通過在網絡最後進行融合來提高識別精度。本文提出可以在網絡中段對三個特徵流做信息交互。
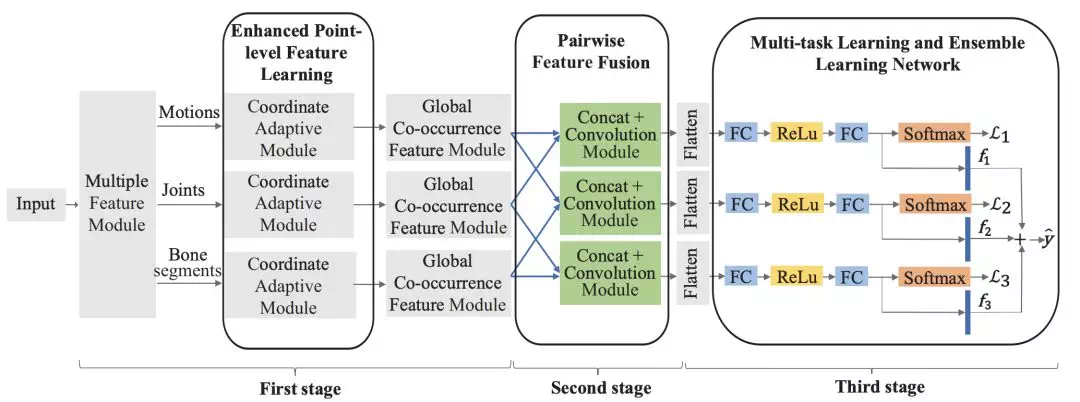
整個網絡分爲三個stage:
數據增強
從原始數據中額外生成motion 和 bone 數據,這樣就有三個數據流。
Enhanced point-level feature learning
數據特徵增強。作者認爲即便是3D骨骼數據,同一序列不同的機位下估計得到的數據仍然具有差異,因此可以將原始動作通過座標旋轉變換來增強,即coordinate adaptive module。而旋轉矩陣不是人工提前設定,而是由網絡通過FC層學習得到:
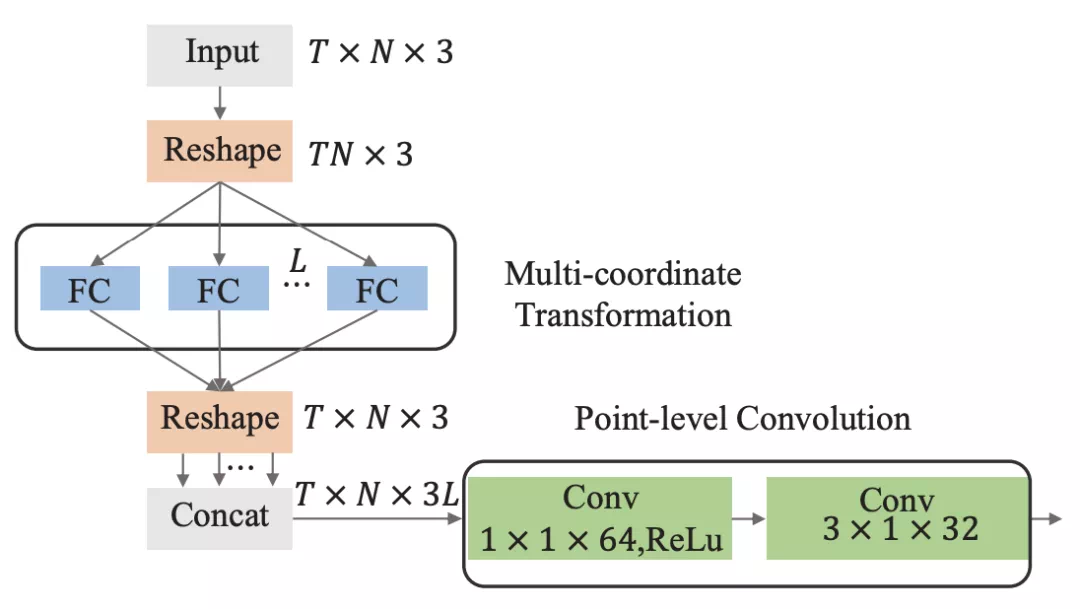
L就是旋轉矩陣的個數,即增強的數據倍數。將得到的L組增強數據在通道維度進行concat,然後再通過point-level convolution(參考HCN)進一步提取特徵。
Pairwise feature fusion
將三個數據流進行特徵融合,有兩種融合方法:

Conv block包含兩層卷積,卷積核大小都是3*3,channel爲128, 256。Concat即特徵融合,在通道維度上融合。圖(a)是不共享conv block的參數,其效果要好於圖(b)的共享參數block,但相應的參數也增多。
Ensemble
將三個數據流通過損失函數求和的方法實現相互監督:
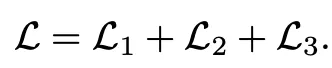
03
SGN: Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action recognition
側重於模型的效率,通過人工特徵工程來進行數據增強,從而保證網絡能在更少的層數下(相對於之前的GCN工作),仍然能達到很好的效果。
Dynamics and Semantics information
其中velocity就是同一關節前後幀之間的差值(到目前爲止,我們所瞭解到的差值有兩種:一種是時間上,相鄰幀的差值,這是一種簡單的 temporal信息,另一種是空間上,相鄰關節的座標差,稱爲bones信息,從2s-AGCN和DGNN的實驗結果來看,通過求差得到的bones信息對分類帶來的提升效果要遠高於temporal信息)。Velocity 和 position 統稱爲dynamics信息。
Frame index 和 joint type 就是 semantics 信息,用 One-hot 表示。
通過兩層FC分別將這四種信息映射到高維空間,然後再通過concate的方式進行特徵聚合:

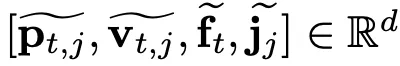
Semantic-aware graph convolution
不能只使用dynamic信息來決定關節之間的連接,因爲不同關節對的dynamics信息可能相同,而他們的連接權重應該是不同的。即便是同一個序列,其在不同幀中的關節之間的關係也可能不同。因此還需要聯合sematic信息。對於一個T幀,每幀有J個關節的序列,爲其構建一個有T*J個節點的圖。其中幀號爲t,關節號爲j的關節,其對應第J(t-1) + j 個節點。這樣便能得到一個spatio-temporal graph,可以對這個graph計算相應的鄰接矩陣,接着通過動態的圖內容自適應連接(content adaptive connections)來計算鄰接矩陣,和2S-AGCN不同的是,本文提出即便是在一個序列內,不同幀所包含的關節併發信息也不同,因此需要將自適應性細化到每一幀。計算方法類似於高斯函數:
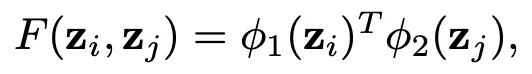
接着通過GCN和 residual 殘差連接的結合,來實現信息在關節間的傳播:
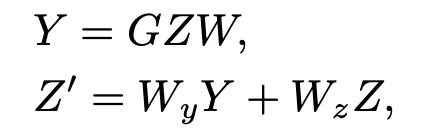
其中 G 是鄰接矩陣,所有W都是可學習的權重矩陣(變換矩陣)。自適應鄰接矩陣會將圖變成強連通圖,因此發掘的信息是全局 global 信息,而對於局部的信息(parts, local),可以用CNN來發掘。
Semantics-aware convolution
GCN主要是提取了關節之間全局關聯(global correlation)的探究,這是因爲adaptive connections讓每個關節都有一個覆蓋其他所有關節的卷積核(表現在鄰接矩陣G上),而CNN具有更小的卷積核,可以發掘關節之間的局部關聯(local correlation)模式(pattern),這和之前的那些基於parts的方法有相同的思想。
01
Sym-GNN: Symbiotic Graph Neural Networks for 3D Skeleton-based Human Action Recognition and Motion Prediction(submitted to IEEE-TPAMI,2019)
本文是CVPR 2019文章:Actional-Structural Graph Convolutional Networks for Skeleton-based Action Recognition(AS-GCN)的期刊版本。進行了一些改進,效果要比AS-GCN好一些。
本文融合使用了諸多上面已經介紹過的方法,並提出了預測和分類任務相互監督的訓練方法,可以有效提升模型對關節特徵的獲取能力。

數據增強
首先將 bone 也作爲一個獨立數據分支,通過和 joint 流融合得到預測結果。(上圖中的 Dual 和 Prime )。
其次提出通過求差值,求導操作(difference operate)獲取關節的動態信息,包括移動向量(motion),速度和加速度:
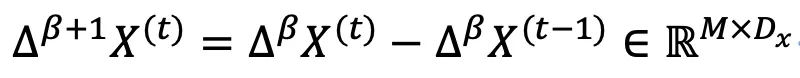
β 取0,1,2時分別對應motion,velocity和accleration。
鄰接矩陣策略
本文的鄰接矩陣策略相對其他工作要複雜一些,主要由以下兩部分構成:
1. Actional Graph Convolution(AGC)
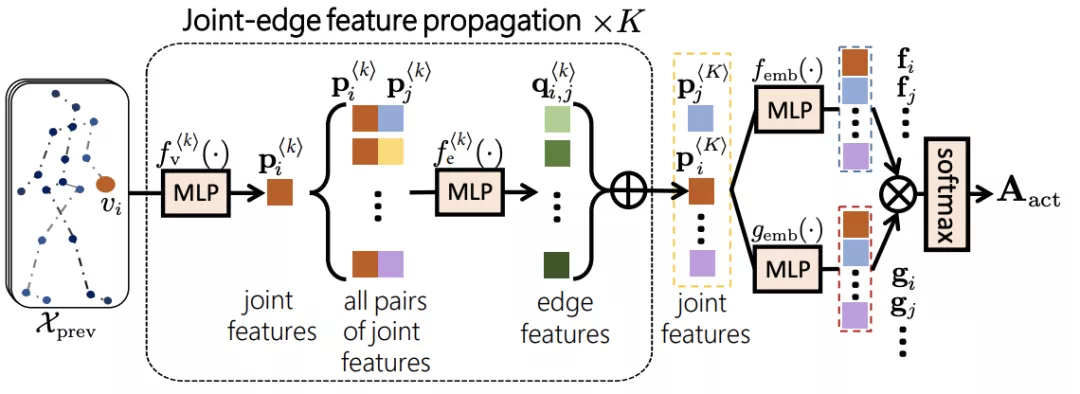
首先設計了一種信息在節點和邊之間循環傳播更新的方法,這樣做是爲了得到節點的高維特徵表示,進而用於計算鄰接矩陣,而不是直接更新節點信息:

注意,第0次迭代時,每個節點的輸入是該節點在所有幀的位置所構成的序列,即關節軌跡(node trajectory),因此以上公式不包含維度t的信息。F都表示FC層。
實際上,這樣的信息逐層傳播迭代的思想與GCN相同,但細節不同。首先始終以節點爲終點,而邊只是中間變量,其次任何兩個點之間都要進行傳播,相當於是在強連通圖下進行特徵傳播,而不侷限於關節的物理連接。多次迭代後每個節點都能充分的聚合其他所有節點的信息。且不同於ST-GCN,因爲節點在信息傳播時,是帶着時序所有信息進行傳播的。
在經過了K次迭代後,每個節點的特徵都得到了更新,此時根據embedded高斯函數來計算兩個節點之間的關聯繫數,由此得到一個新的鄰接矩陣:

f 和g分別是兩個 embedding 全連接層。學習到的鄰接矩陣類似於2S-AGCN中的 attention 鄰接矩陣,只不過embedding採用的是全連接層而不是卷積層。這部分的整體計算流程如下:
計算得到鄰接矩陣後,進行常規的圖卷積:
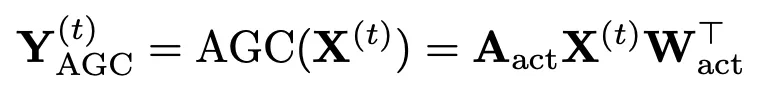
注意此時圖卷積的對象就是每一幀的數據(t上標),而不是關節軌跡。
1.2 Structural Graph Convolution(SGC)
這部分通過對基礎鄰接矩陣取不同的冪次來提升每個節點的感受野,卷積公式如下:
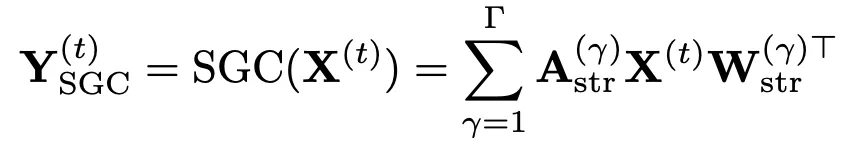
依然是對每幀進行圖卷積,其中γ表示對鄰接矩陣取γ冪次。此外,類似於ST-GCN,還爲A添加了加權權重:
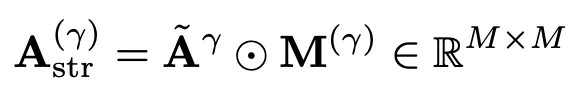
1.3 joint scale graph convolution(JGC)
對前面兩部分卷積結果加權求和:
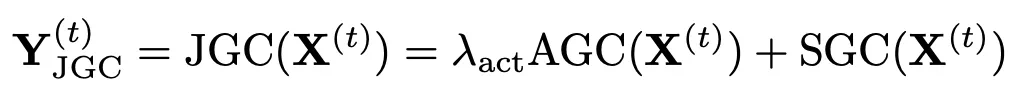
注意這裏卷積對象都是單幀圖。本文還提出了一種關節位置限制機制,來限制每一層提取的特徵的變化程度,從而提高穩定性,降低噪聲數據的影響。
時序特徵提取
joint-scale graph and temporal convolution block(J-GTC)
時序卷積就是在沿着時間維度做卷積,這部分的思想和ST-GCN相同,先進行空間上的圖卷積,再進行時間上的一般卷積,如此反覆,可以串聯地學習時空特徵:

ρ 是非線性激活函數。TC 將每個關節與其前後多幀範圍內的值進行卷積,屬於1D 卷積。
J-GTC block同時包含了batch norm,dropout,residual connection模塊。
多尺度卷積:Part-based策略
GC-LSTM將part-based流作爲獨立數據流輸入,只在最後與Joint流做特徵融合,本文加強了兩個數據流之間的信息交流,主要是在合適的位置將兩個特徵流沿節點維度進行拼接:
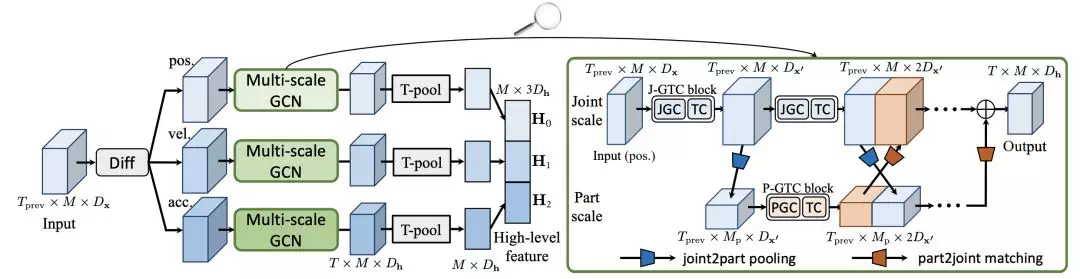
首先將人體分爲多個part,每個part內的關節取平均值,這樣每個part就變成了一個節點這麼做相當於降低了圖的分辨率。兩個數據流通過pooling和matching的方法進行特徵交互。Matching是將part scale圖的單個節點複製多次,得到joint scale圖。
分類和預測任務共同監督
同時進行動作識別和動作預測的任務(分別使用不同的任務網絡),在優化時,損失函數爲二者的加權和:

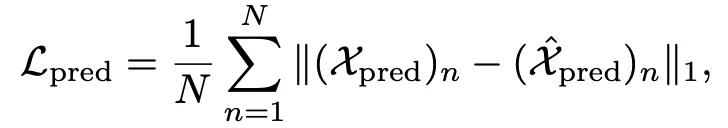
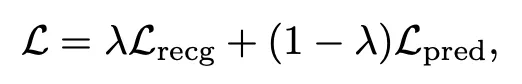
其中參數通過 multiple gradient descent algorithm 算法獲得。