GPT 系列可以說是人工智能領域「暴力美學」的代表作了。2018 誕生的 GPT,1.17 億參數;2019 年 GPT-2,15 億參數;2020 年 GPT-3,1750 億參數。短短一年時間,GPT 模型的參數量就呈指數級增長。
GPT-3 發佈後不久,OpenAI 即向社區開放了商業 API,鼓勵大家使用 GPT-3 嘗試更多的實驗。然而,API 的使用需要申請,而且你的申請很有可能石沉大海。那麼,除了使用官方 API 以外,我們還有沒有其他方法能上手把玩一下這個「最大模型」呢?
近日,特斯拉人工智能研究負責人、前 OpenAI 研究科學家 Andrej Karpathy 進行了嘗試。
他基於 PyTorch,僅用 300 行左右的代碼就寫出了一個小型 GPT 訓練庫,並將其命名爲 minGPT。
Karpathy 表示,這個 minGPT 能夠進行加法運算和字符級的語言建模,而且準確率還不錯。不過,在運行 demo 後,Andrej Karpathy 發現了一個有趣的現象:2 層 4 注意力頭 128 層的 GPT 在兩位數加法運算中,將 55 + 45 的結果計算爲 90,而其他加法運算則沒有問題。

目前,該項目在 GitHub 上亮相還沒滿 24 小時,但 star 量已經破千。
minGPT 項目地址:https://github.com/karpathy/minGPT
minGPT:只用 300 行代碼實現的 GPT 訓練
如果說 GPT 模型是所向披靡的戰艦,那麼 minGPT 大概算是個個頭雖小但仍能乘風破浪的遊艇了吧。

在項目頁面中,Karpathy 介紹稱:由於現有可用的 GPT 實現庫略顯雜亂,於是他在創建 minGPT 的過程中, 力圖遵循小巧、簡潔、可解釋、具有教育意義等原則。
GPT 並非一個複雜的模型,minGPT 實現只有大約 300 行代碼,包括樣板文件和一個完全不必要的自定義因果自注意力模塊。Karpathy 將索引序列變成了一個 transformer 塊序列,如此一來,下一個索引的概率分佈就出現了。剩下的複雜部分就是巧妙地處理 batching,使訓練更加高效。
核心的 minGPT 庫包含兩個文檔:mingpt/model.py 和 mingpt/trainer.py。前者包含實際的 Transformer 模型定義,後者是一個與 GPT 無關的 PyTorch 樣板文件,可用於訓練該模型。相關的 Jupyter notebook 則展示瞭如何使用該庫訓練序列模型:
play_math.ipynb 訓練一個專注於加法的 GPT;
play_char.ipynb 將 GPT 訓練成一個可基於任意文本使用的字符級語言模型,類似於之前的 char-rnn,但用 transformer 代替了 RNN;
play_words.ipynb 是 BPE(Byte-Pair Encoding)版本,目前尚未完成。
使用 BPE 編碼器、分佈式訓練和 fp16,這一實現有可能復現 GPT-1/GPT-2 的結果,不過 Karpathy 還沒有嘗試。至於 GPT-3,minGPT 可能無法復現,因爲 GPT-3 可能不適合 GPU 內存,而且需要更精細的模型並行化處理。
使用示例
Karpathy 在 minGPT 項目中提供了一些使用示例。
這些代碼非常簡單,只需 hack inline 即可,而非「使用」。目前的 API 外觀如下:
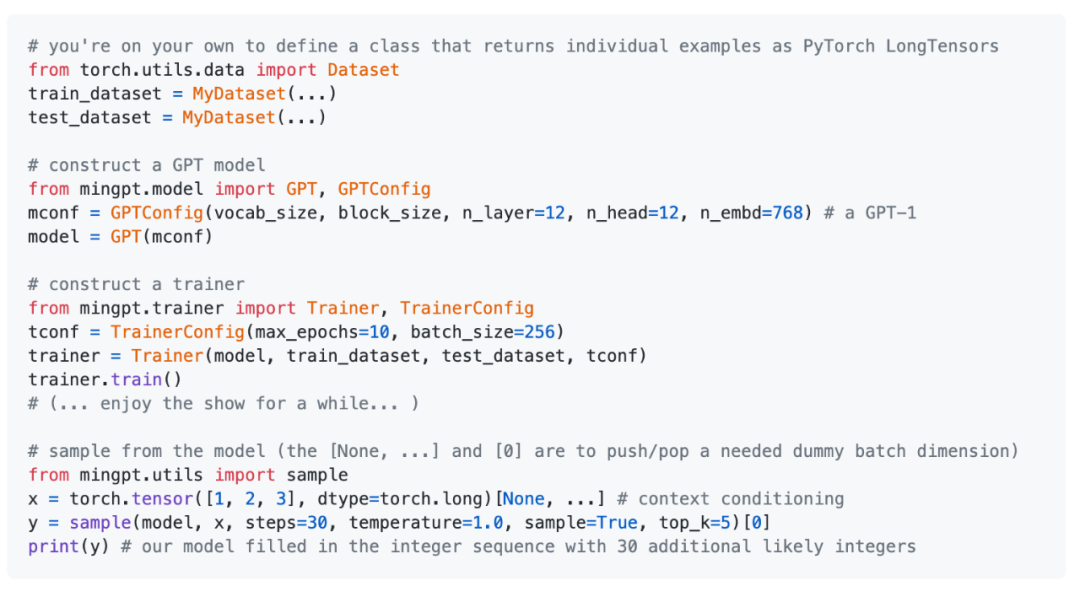
minGPT 是如何實現的?
在實現過程中,Karpathy 參考了 OpenAI GPT 官方項目,以及其他組織的示例等。
代碼
OpenAI gpt-2 項目提供了模型,但沒有提供訓練代碼(https://github.com/openai/gpt-2);
OpenAI 的 image-gpt 庫在其代碼中進行了一些類似於 GPT-3 的更改,是一份不錯的參考(https://github.com/openai/image-gpt);
Huggingface 的 transformers 項目提供了一個語言建模示例。它功能齊全,但跟蹤起來有點困難。(https://github.com/huggingface/transformers/tree/master/examples/language-modeling)
論文 + 實現說明
此外,項目作者還介紹了相關的論文和實現細節。
1. GPT-1:《Improving Language Understanding by Generative Pre-Training》
論文地址:https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
GPT-1 模型大體遵循了原始 transformer,訓練了僅包含 12 層解碼器、具備遮蔽自注意力頭(768 維狀態和 12 個注意力頭)的 transformer。具體實現細節參見下圖:

2. GPT-2:《Language Models are Unsupervised Multitask Learners》
論文地址:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
GPT-2 將 LayerNorm 移動每個子模塊的輸入,類似於預激活殘差網絡,並在最後的自注意力模塊後添加了一個額外的層歸一化。此外,該模型還更改了模型初始化(包括殘差層初始化權重等)、擴展了詞彙量、將 context 規模從 512 個 token 增加到 1024、使用更大的批大小等。具體實現細節參見下圖:

3. GPT-3:《Language Models are Few-Shot Learners》
論文地址:https://arxiv.org/pdf/2005.14165.pdf
GPT-3 使用了和 GPT-2 相同的模型和架構,區別在於 GPT-3 在 transformer 的各層上都使用了交替密集和局部帶狀稀疏的注意力模式,類似於 Sparse Transformer。具體實現細節參見下圖:

Andrej Karpathy 其人
Andrej Karpathy 是計算機視覺、生成式模型與強化學習領域的研究者,博士期間師從斯坦福大學計算機科學系教授李飛飛。讀博期間,他曾兩次在谷歌實習,研究在 Youtube 視頻上的大規模特徵學習。此外,他還和李飛飛等人一起設計、教授了斯坦福經典課程 CS231n。

2016 年,Karpathy 加入 OpenAI 擔任研究科學家。2017 年,他加入特斯拉擔任人工智能與自動駕駛視覺總監。如今,Karpathy 已經升任特斯拉 AI 高級總監。他所在的團隊負責特斯拉自動駕駛系統 Autopilot 所有神經網絡的設計,包括數據收集、神經網絡訓練及其在特斯拉定製芯片上的部署。
和教授 CS231n 時一樣,Karpathy 希望他利用業餘時間做的這個 minGPT 也能有一定的教育意義。他這種化繁爲簡的舉動得到了衆多社區成員的讚賞:
除了關於 minGPT 本身的討論之外,還有人提出:有沒有可能借助社區力量一起訓練 GPT-3?也就是說,如果成千上萬的開發者在 GPU 空閒的時候將其貢獻出來(比如夜間),最後有沒有可能訓練出一個 1750 億參數的 GPT-3?這樣的話,大家只需要分攤電費就好了。

不過,有人指出,這種分佈式訓練的想法非常有趣,但可能會在梯度等方面遇到瓶頸。

還有人調侃說,把電費衆籌一下拿來買雲服務豈不是更簡單?

參考鏈接:https://news.ycombinator.com/item?id=24189497