幫趣
幫趣
聽聲辨位過時了!這個AI系統僅憑光回聲就能得到3D圖像
2020-08-10 15:01:18.0
藉助光回聲獲得時間信息,利用機器學習從看似噪聲的信息中挖掘模式。這項研究登上光學期刊 Optica。
利用光回聲和機器學習製作 3D 影像(左),右圖來自 3D 相機。左圖分辨率低於右圖,但它僅基於光回聲執行,且能夠展示人物的形狀。
想象一下,你閉着眼睛朝一隻動物大吼,然後根據回聲就能判斷這隻動物是貓是狗。聽起來是不是很不可思議?
來自英國格拉斯哥大學計算科學學院的研究者最近就做了一項類似的成像技術。他們通過計算光反射到一個簡單探測器所需的時間,來獲得場景的 3D 圖像。當然,僅僅依靠光提供的信息是不夠的,這項被稱爲「時域成像」(temporal imaging)的新技術還藉助機器學習方法,從噪聲中挖掘模式。
加州大學伯克利分校計算機科學家 Laura Waller 評論道:「這個系統竟然可以獲得圖像,這令我感到震驚,因爲它提取到的信息遠遠不夠。
這展示了機器學習在解決看似無解問題上的能力
。」Laura Waller 並未參與此項研究。
在傳統攝影中,環境光從物體上反射,鏡頭將其聚焦在一個由微型感光元素或像素組成的屏幕上。這幅圖像是由反射光所形成的亮點和暗點的集合。相比之下,一種名爲「飛行時間相機(time-of-flight camera,ToF camera)」的設備可以爲圖像加上深度信息,通過計算物體反射回來的一束光到達不同像素的精確時間來生成 3D 圖像。
最近幾十年來,研究人員創造了很多精妙的方式,來使用單像素檢測器捕捉圖像。爲此,他們不把物體置於均勻照明中,而是置於不同光模式的光束中,這有點類似於外包裝上的條形碼。每個模式反射物體的不同部分,這樣像素度量到的光強度隨着模式的變化而變化。通過追蹤這些變化,研究人員能夠成功重建物體的圖像。
現在,來自英國格拉斯哥大學的數據科學家 Alex Turpin、物理學家 Daniele Faccio 及其同事提出了一種使用單個像素生成 3D 圖像的新方式,但它不需要具備模式的光。
利用快如閃電般的單光子檢測器,他們描述了具備統一光的場景,並度量其反射時間。該檢測器可以精確到 1/4 納秒,計算光子數量隨着時間的變化情況。僅基於這一信息,研究人員即可重建該場景的圖像。
Waller 認爲,這一結果令人吃驚,因爲原則上場景中的物體陳設和時間信息之間不存在一對一關係。例如,當檢測器距離任意表面 3 米遠時,反射該表面的光子將在 10 納秒內到達,不管它位於表面的什麼方向。乍一看,這種模糊性似乎使問題無解。「我第一次聽到『單像素成像』的概念時,想的是『這應該奏效』。而對於這個,我想的是『應該不會有用』。」
爲了解決這一問題,Turpin 及其同事使用神經網絡,來檢測輸入和輸出之間的微妙關聯。研究人員使用光束和檢測器,錄製一兩個人在固定、不對稱的背景場景前移動的數據。同時,他們還使用 ToF 相機記錄場景的真實 3D 圖像。
上週,研究人員在光學期刊 Optica 上發表了這篇論文,表明在使用以上兩個數據集訓練神經網絡之後,神經網絡能夠自行對場景中移動的人建模。與 ToF 相機拍攝的圖像相比,時域圖像比較模糊,且缺乏細節。但是,它們能夠清晰地展示人物的形狀。
該神經網絡能夠解碼模糊信號,這要感謝訓練過程,該網絡嘗試回憶與訓練過程中見過的場景和物體類似的事物。不過這意味着該系統存在缺陷:它必須在將要觀察的場景中進行訓練。
Turpin 表示:「我們需要背景,沒有背景網絡將無法正常運轉。」在面對全新場景時,該系統可能生出錯誤的圖像,而它與訓練過程中見過的場景類似。
Turpin 表示,該時域成像系統相比普通成像系統具備多項優勢。例如,新系統速度很快,能夠以每秒 1000 幀的速率運行。Turpin 稱,這種粗糙但迅速的 3D 成像技術有很多應用場景。同時,該系統價格低廉、構造簡單。理論上,技術愛好者使用一臺普通的筆記本電腦和無線電路由器的天線,就可以監控房間。
不過,Waller 表示,目前尚不清楚這一系統的效果如何,畢竟現有的相機價格也不算昂貴。她認爲,該研究實驗提出了一個有趣的概念性問題:神經網絡是如何學習創建合理圖像的?「它的運行原理是什麼?其背後的物理學是什麼?」Waller 認爲,真正的挑戰在於,不再把神經網絡作爲黑箱,而是真正探討它的原理。
以下是論文內容的詳細介紹:
論文地址:
https://www.osapublishing.org/optica/abstract.cfm?uri=optica-7-8-900
單點 3D 成像方法詳解
這項研究採取了一種不同的方法,通過基於包含目標檢索圖像類型的數據集的先驗知識提供額外信息,並且爲這一目標訓練了一種監督式機器學習算法。
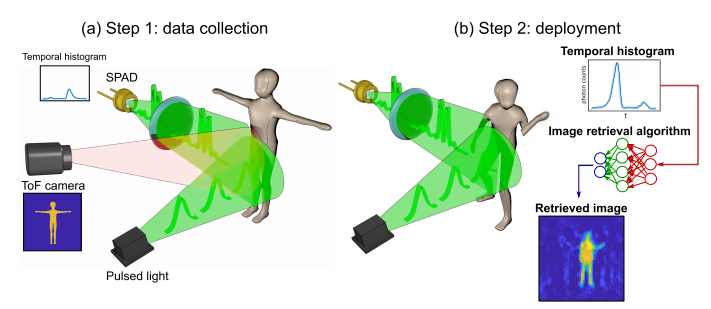
具體而言,如下圖 1 所示,這種 3D 成像方法共包含三個部分:(i) 脈衝光源,(ii) 單點時間分辨傳感器, (iii) 圖像檢索算法。利用脈衝光源對場景進行泛光照明,然後用傳感器收集由此產生的反向散射光子。
該研究通過結合使用單點 SPAD 檢測器和時間相關單光子計數(TCSPC)電子器件,將光子到達場景中不同位置物體的時間形成時間直方圖(temporal histogram,參見圖 1b),不同形狀的物體爲傳感器提供到達時間的不同分佈。
圖 1:基於單點時間分辨傳感器的 3D 成像。
該方法包括兩個步驟:a)數據收集,b)部署。在第一步中,用脈衝激光束照射場景,用單點傳感器(此處是 SPAD)採集反射光,SPAD 通過 TCSPC 提供時間直方圖。同時,ToF 相機記錄來自場景的 3D 圖像,該相機獨立於 SPAD 和脈衝激光系統運行。SPAD 時間直方圖和 ToF 3D 圖像被用來訓練圖像檢索神經網絡。步驟 2 僅在神經網絡訓練完成後進行。在該部署階段,只需使用脈衝激光源和 SPAD:僅基於時間直方圖提取 3D 圖像。
實驗結果
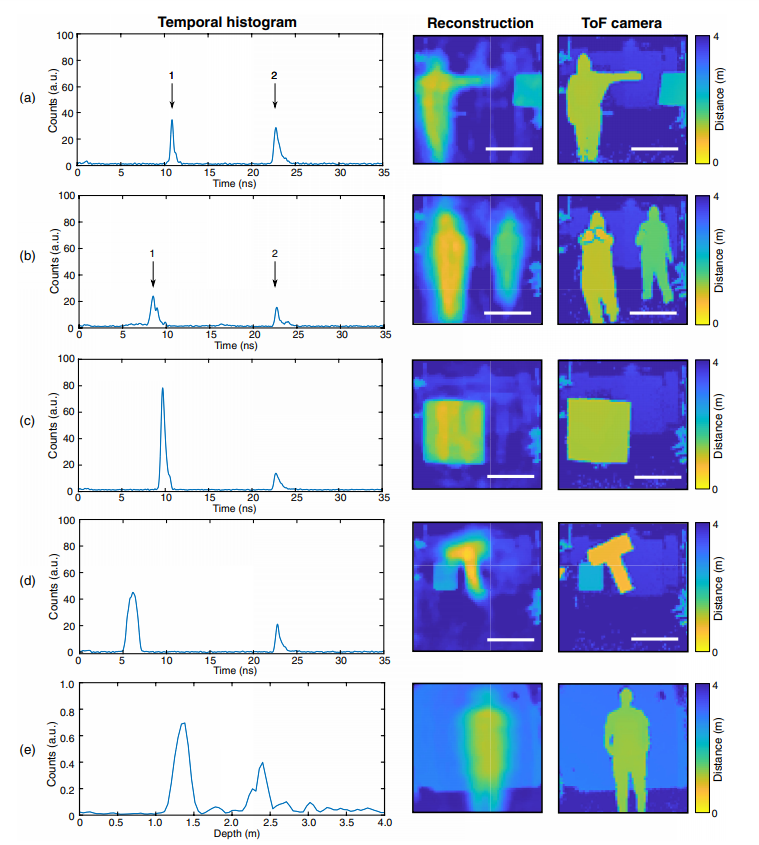
圖 3 中的實驗結果顯示了該系統在不同情況下從時間直方圖恢復 3D 圖像的性能。
第一列顯示使用 SPAD 傳感器和 TCSPC(a-d 行)或雷達收發器(e 行)記錄的時間直方圖。最後一列代表直接用 ToF 相機度量的 3D 圖像,用於與重建圖像(第二列)進行對比。彩色條描述的是顏色編碼深度圖。
詳細信息參見以下視頻:
Visualization 1。
Visualization 2。
參考鏈接:
https://www.sciencemag.org/news/2020/08/time-camera-generates-3d-images-echoes-light
文章來源:
機器之心
喜歡這篇文章嗎?快分享吧!
COPYRIGHT ©2020, BANGQU.COM |
Coupons