在開始一個新的機器學習項目時,難免要重新編寫訓練循環,加載模型,分佈式訓練……然後在Debug的深淵裏看着時間嘩嘩流逝,而自己離項目核心還有十萬八千里。

雖然這世上已經有了神器Keras,能用幾條語句就輕鬆組建一個神經網絡,但一想到它是站在Tensorflow的肩膀上,就讓人不禁想起江湖中的那句傳說:
PyTorch 真香!
那麼爲什麼不做一個PyTorch上的Keras呢?
來自Facebook的Willian Falcon小哥決定一試,他搞了個包裝器,把PyTorch中的各種通用配置全部包裝在一起。
這個PyTorch輕量級包裝器,就是PyTorch Lightning。

有了這樣一個快速研究框架,使用者只需關注核心訓練和驗證邏輯,繁瑣的工程細節通通自動化一鍵完成,既能保證核心訓練邏輯的正確性,又能保證最佳的實踐體驗。
像閃電一樣迅疾
所以,Lightning到底有多好用?
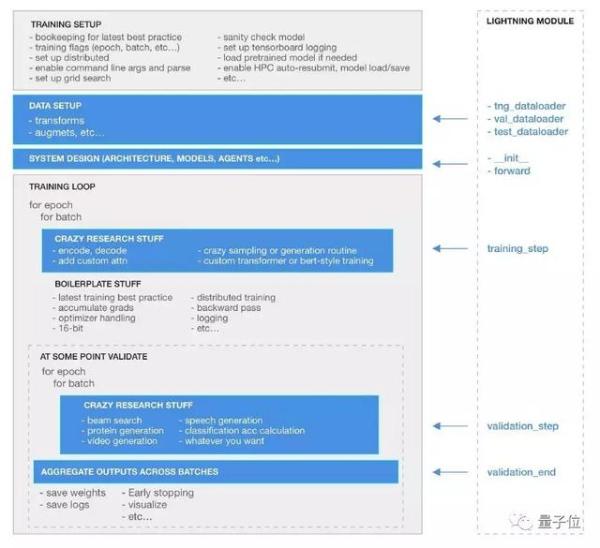
在這張圖中,灰色部分代表Lightning能自動完成的部分,而藍色的部分則能夠根據使用者的需求,被定義成任意底層模型,可以是你自己的新模型,也可以是預訓練模型,fast.ai架構等等。
舉幾個例子好了。
比如說,梯度下降。
原來,你需要這樣:
# clear last step
optimizer.zero_grad()
# 16 accumulated gradient steps
scaled_loss = 0
for accumulated_step_i in range(16):
out = model.forward()
loss = some_loss(out,y)
loss.backward()
scaled_loss += loss.item()
# update weights after 8 steps. effective batch = 8*16
optimizer.step()
# loss is now scaled up by the number of accumulated batches
actual_loss = scaled_loss / 16在Lightning裏,這一整段代碼不需要你自己敲了,只需輸入以下兩行代碼:
trainer = Trainer(accumulate_grad_batches=16)
trainer.fit(model)不僅如此,在Lightning裏,想用上單個GPU,直接調用即可:
trainer = Trainer(gpus = [0])
trainer.fit(model)使用能將內存佔用減少一半的黑科技16位精度,不費吹灰之力:
trainer = Trainer(amp_level = ’02’, use_amp = False)
trainer.fit(model)使用多個GPU進行分佈式訓練,so easy:
trainer = Trainer(gpus = [0, 1, 2, 3])
trainer.fit(model)
甚至是在1024個節點上以1024個GPU進行訓練,也是開箱即用:
trainer = Trainer(nb_gpu_nodes=128, gpus=[0, 1, 2, 3, 4, 5, 6, 7])自動化功能還遠不止這一些,以下模塊,均包含其中:

想要訓練閃電那麼快的神經網絡嗎?Lightning簡直爲此量身定做。
此外,Lightning還和Tensorboard集成在了一起,可以輕鬆實現可視化學習。
只需記錄實驗路徑:
from test_tube import Experiment
from pytorch-lightning import Trainer
exp = Experiment(save_dir='/some/path')
trainer = Trainer(experiment=exp)
...然後在該路徑運行tensorboard即可:
tensorboard —logdir /some/path
食用方法
想要使用Lightning,需要完成兩件事。
1、定義Lightning Model
這一步會花費掉比較長的時間。
Lightning Model是nn.Module的嚴格超類,它提供了與模型進行交互的標準界面。
啓用Lightning Model最簡單的方法是根據下面這個最小示例(minimal example)進行局部修改:
import os
import torch
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
import torchvision.transforms as transforms
import pytorch_lightning as ptl
class CoolModel(ptl.LightningModule):
def __init__(self):
super(CoolModel, self).__init__()
# not the best model...
self.l1 = torch.nn.Linear(28 * 28, 10)
def forward(self, x):
return torch.relu(self.l1(x.view(x.size(0), -1)))
def my_loss(self, y_hat, y):
return F.cross_entropy(y_hat, y)
def training_step(self, batch, batch_nb):
x, y = batch
y_hat = self.forward(x)
return {'loss': self.my_loss(y_hat, y)}
def validation_step(self, batch, batch_nb):
x, y = batch
y_hat = self.forward(x)
return {'val_loss': self.my_loss(y_hat, y)}
def validation_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
return {'avg_val_loss': avg_loss}
def configure_optimizers(self):
return [torch.optim.Adam(self.parameters(), lr=0.02)]
@ptl.data_loader
def tng_dataloader(self):
return DataLoader(MNIST(os.getcwd(), train=True, download=True, transform=transforms.ToTensor()), batch_size=32)
@ptl.data_loader
def val_dataloader(self):
return DataLoader(MNIST(os.getcwd(), train=True, download=True, transform=transforms.ToTensor()), batch_size=32)
@ptl.data_loader
def test_dataloader(self):
return DataLoader(MNIST(os.getcwd(), train=True, download=True, transform=transforms.ToTensor()), batch_size=32)2、擬合訓練器
訓練器能處理Lightning自動化部分的代碼核心邏輯,它會在訓練過程中提取出最佳實踐。
基本的用法是像這樣:
from pytorch_lightning import Trainermoder = LightningTemplate()trainer = Trainer()
trainer.fit(model)只要確保它的正確執行,只需一個Trainer,計算集羣(SLURM),Debug,分佈式訓練就通通不在話下了。
from pytorch_lightning import Trainer
from test_tube import Experiment
model = CoolModel()
exp = Experiment(save_dir=os.getcwd())
# train on cpu using only 10% of the data (for demo purposes)
trainer = Trainer(experiment=exp, max_nb_epochs=1, train_percent_check=0.1)
# train on 4 gpus
# trainer = Trainer(experiment=exp, max_nb_epochs=1, gpus=[0, 1, 2, 3])
# train on 32 gpus across 4 nodes (make sure to submit appropriate SLURM job)
# trainer = Trainer(experiment=exp, max_nb_epochs=1, gpus=[0, 1, 2, 3, 4, 5, 6, 7], nb_gpu_nodes=4)
# train (1 epoch only here for demo)
trainer.fit(model)
# view tensorflow logs
print(f'View tensorboard logs by running\ntensorboard --logdir {os.getcwd()}')
print('and going to http://localhost:6006 on your browser')
One More Thing
你可能會問,爲什麼要搞一個Lightning呢,用fast.ai不好嗎?
作者小哥表示,Lightning和fast.ai之間就沒什麼好比的,fast.ai面向有志於進入深度學習領域的新手,而Lightning面向的是ML領域中活躍的研究人員們。
就算真的要比,Lightning可是開箱即用的,不僅如此,在高性能計算、調試工具和可用性方面,小哥都對Lightning充滿信心。他自信地甩出了三張對比表格:

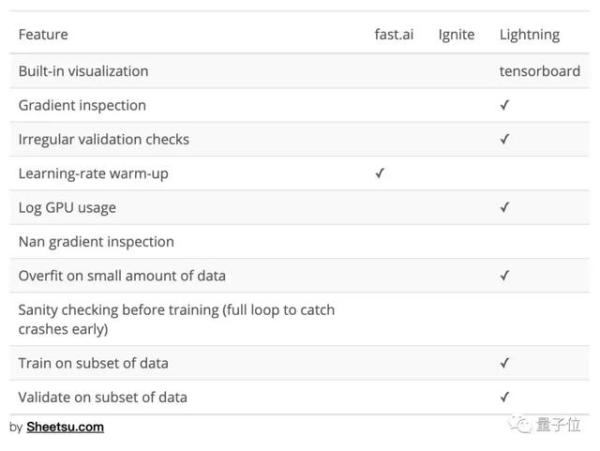
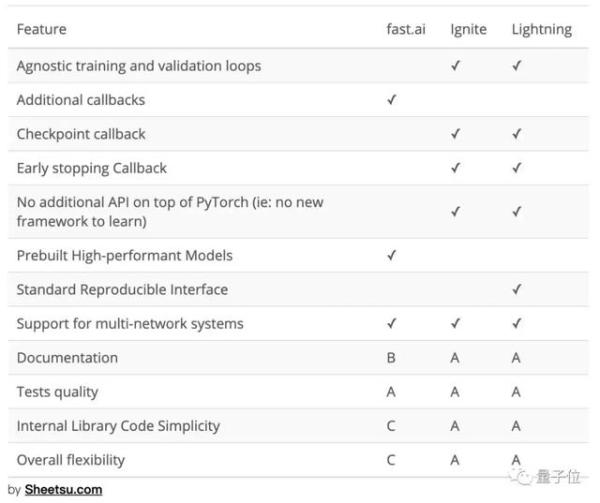
嗯,PyTorch真香!
傳送門
GitHub地址:
https://github.com/williamFalcon/pytorch-lightning