按照 NVIDIA 老闆的說法,在還沒有公司名稱的時候,所有文件都冠以兩字詞 NV 開頭,含義是 Next Version(下一版),直到某天由於公司合併,其中一位公司創辦合夥人翻查了和這個兩字詞相關的所有單詞,最終選擇了諧音「Envy」的拉丁文「invidia」(暗含視覺與羨慕的意思),於是 NVIDIA 這個名字也就被大家採納。經過二十多年的發展,寂寂無聞的 NVIDIA 已經成爲全球最受矚目的芯片公司,旗下擁有 GeForce、Quadro、Tesla、Tegra 等多個產品線。
四個產品線的分工比較明確,GeForce 主要針對遊戲消費市場、Quadro 針對專業圖形和入門科學計算領域、Tesla 針對超算市場、Tegra 針對物聯網。和相對煩囂的 GeForce、Tesla 相比,Quadro 在普通人看來雖然有點「寂寞」,但是在 NVIDIA 的營收中卻有極其重要的地位,其所屬的專業可視化業務更是實現了連續 16 個季度的增長。
正如前面所說的那樣,Quadro 是 NVIDIA 的專業圖形產品品牌,在它誕生(1999 年)的一年時間內接連創下了多個第一:全球第一款集成硬件 T&L 專業卡、第一款移動工作站、第一個 Linux 專業工作站驅動。作爲後來者,Quadro 憑藉強大的產品力,很快就將當時工作站市場佔統治地位的 3DLabs、FireGL 等品牌全部幹趴下。
自推出後 Quadro 在專業應用市場上一直保持着領先的市場份額,隨着功能和性能日益強大,基於 GPU 的專業應用也越來越受重視,Quadro 可以發揮的用武之地也越來越多。

特別是 NVIDIA 圖靈架構發佈後,不僅傳統工作站應用因爲光線追蹤內核(RT Core)的加持而顯著受益,而且在人工智能、大數據方面也因爲張量內核(Tensor Core)而得到了更進一步的拓展,此外,圖靈在多卡通信(NVLink)、視頻加速也有重大提升,爲專業應用提供了面向未來的支持。
讓人值得關注的是,NVIDIA 這次打破常規,讓 Quadro RTX 圖靈架構產品線發佈的第一個產品,足見這次 NVIDIA 對圖靈架構專業產品給與了前所未有的重視。
硬件光追加速內核
圖靈架構最重要的創新之處是首次集成了名爲 RT Core 的光線追蹤內核,光線追蹤被業界認爲是目前實現真實渲染的最強技術,它從觀察者發射出一條射線,穿過屏幕像素抵達到渲染對象,生成反射、折射、陰影等衍生射線,結合對象材質、大氣等特性,確定像素的最終顏色。
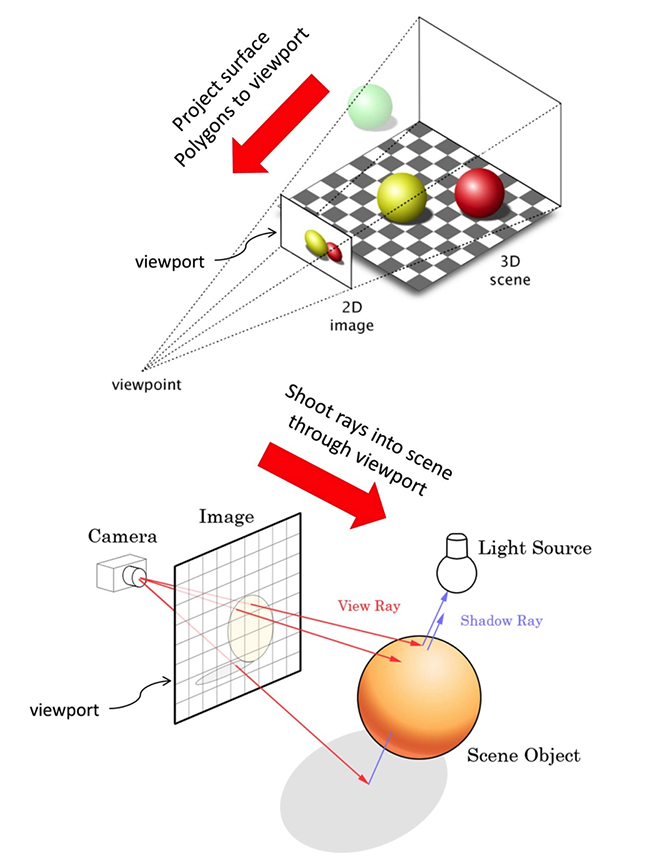
理論上,光線追蹤可以完全模擬真實世界的光照(以及聲音等)效果,但是現實世界有幾乎無數的光子在物體之間碰撞,因此,在真正的光線追蹤應用裏,一般都會使用有限的主射線(穿越像素的射線)和衍生射線,結合一些隨機算法實現在有限的計算資源下提供可接受的真實效果渲染。
在以往,光線追蹤都是以軟件方式來執行,也就是用 CPU 和 GPU 的通用計算單元來跑,由於光線追蹤是複雜的計算密集型應用,軟件方式難以實時的來呈現,所以一直以來,光線追蹤基本上都是僅限於互動操作敏感度不是很高的輸出渲染。
當然,實時光線追蹤在這個時期也是存在的,只是速度讓人很抓狂,畫面效果也得妥協,畢竟要實現實時的話,允許的計算時間是有限的。在這種生態環境下,人們願意投入的開發資源自然也不多,像 Keyshot 這類工業設計渲染器就一直只用 CPU 跑。
Quadro RTX 採用的圖靈架構改變了這個局面,它引入的 RT Core 就是把光線追蹤中最耗時的射線求交計算和三角形篩選處理,以硬件電路的方式集成到了 GPU 中,大大提高了光線追蹤計算的能耗比,結合混合渲染算法,最終實現了效率遠勝以往的實時光線追蹤性能。
增強的張量內核
張量內核(Tensor Core)是 NVIDIA 在 Volta 架構專門針對人工智能引入的混合精度計算加速單元,透過 NVIDIA 的自動混合計算精度(AMP),可以在多種深度學習框架提供自動混合加速。Quadro RTX 的圖靈架構同樣集成了張量內核,而且做了進一步的擴展,增加了 4 位整數精度支持,可以對精度需求不高的場合提供更高的吞吐量。
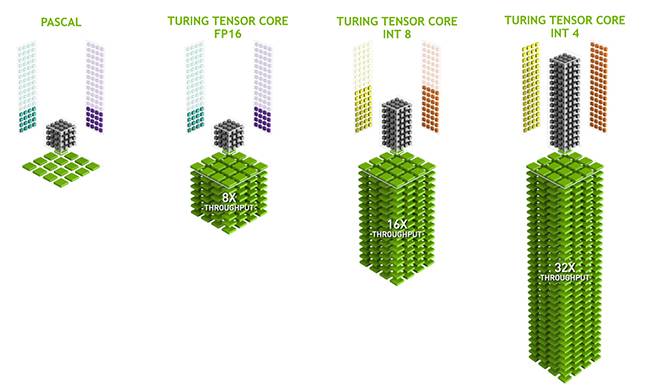
我們以基於 TU102 GPU 的 Quadro RTX 8000 爲例,它的單精度(32 位浮點)性能是 16.3 TFLOPS,但是 INT4(4 位整數)性能高達 522 TOPS,INT8(8 位整數)性能是 261 TOPS。
使用 Quadro RTX 作爲深度學習或者計算密集型計算方案既可以確保靈活而強大的性能,同時在使用成本上也較其他方案更有優勢,NVIDIA 的 NGC 容器鏡像方案可以讓用戶幾乎無須考慮平臺部署的複雜性,只要平臺安裝好 CUDA 和 Docker ,再複製粘貼幾條指令,就能快速部署各種主流深度學習框架容器鏡像,快速編寫、運行深度學習代碼。
8K 視頻編解碼
圖靈架構集成了升級過的 NVDEC 和 NVENC,支持對 HEVC 4:4:4 格式視頻的解碼以及 8K 30fps 格式視頻的 HEVC 編碼。HEVC 編碼擁有比 H.264 高 30% 以上的同畫質壓縮率,對於視頻會議、在線直播、視頻剪輯以及工作站串流等操作,新的編解碼引擎對於 Quadro RTX 用戶來說意味着更高的效率和畫質。

特別值得一提的是,圖靈的 HEVC 編碼器支持 B-Frame 壓縮,B-Frame 是參考前後幀與本幀的差別進行編碼的方式,比 P-Frame 的壓縮率更高(I-Frame 效率最低),因此 Quadro RTX 的 HEVC 編碼器在同樣的碼率可以做到更高的畫質。
高達 48 GB 板載內存
Quadro RTX 全線採用 GDDR6 內存,其中 Quadro RTX 8000 內存帶寬高達 672 GiB/s,內存容量高達 48 GiB,遠超遊戲卡版本 RTX 2080 Ti 的 11GiB,也比面向遊戲發燒玩家的 Titan RTX 高一倍,即使和 NVIDIA 目前頂尖服務器加速卡 Telsa V100S PCIe 相比,也要多 50% 的容量。

不僅於此,圖靈架構還具備名爲 NVLINK 的通用輸入輸出接口,帶寬高達 100GiB/s。在 PC 上可以用作多卡並聯總線使用,此時 NVLINK 相當於一條擴展內存總線,兩片 Quadro RTX 8000 可以快速共享彼此的內存,顯著提高多卡性能。
GPU
|
內存容量
|
採用 NVLINK 後內存容量
|
光線投射性能
|
CUDA 內核規模
|
張量內核規模
|
Quadro RTX 8000
|
48 GiB
|
96 GiB
|
10 GRays/s
|
4608
|
576
|
Quadro RTX 6000
|
24 GiB
|
48 GiB
|
10 GRays/s
|
4608
|
576
|
Quadro RTX 5000
|
16 GiB
|
32 GiB
|
6 GRays/s
|
3072
|
384
|
Quadro RTX 4000
|
8 GiB
|
不具備 NVLINK
|
6 GRays/s
|
2304
|
288
|
多屏巨幕能力
Quadro RTX 另一個比較硬核的專業應用領域是多屏應用,例如現在舞臺背景牆,很多時候都是採用了結合複雜三維、視頻處理的應用,不僅要做到多屏同步,還需要具備強大實時處理能力和良好的第三方軟件兼容性。

作爲有多年豐富經驗的多屏顯卡供應商,Quadro RTX 在多屏處理能力也是相當強勁,支持 NVIDIA Quadro Sync II 同步卡,能以 4 塊 Quadro RTX 6000 組合的方式提供 16 屏的強大同步輸出能力,如果對性能有更高需求的話,還可以用 4 塊 Quadro RTX 800 組成 32 屏輸出,如此強悍的多屏解決方案實在難以找到對手。
最後的 CPU 渲染頑固派擁抱 Quadro RTX
圖靈架構是在 2018 年 Siggraph 上發佈的,作爲一個擁有革命性的架構,尤其是集成的硬件光線追蹤加速能力,當時支持的應用並不多。隨着 Quadro RTX 等圖靈架構產品的上市,這些疑問已經一掃而空,例如在專業可視化應用領域,包括像 Keyshot 這類以前頑固的 CPU 派渲染器都紛紛加入到了全力支持圖靈架構的行列。
Luxion 的 Keyshot 是業界知名的獨立專業級實時光線追蹤和全局照明渲染器,以使用簡單、效果逼真等特點受到了很多工業設計師的青睞。在很長一段時間裏,Keyshot 都只支持 CPU 渲染模式,但是從9.0 版開始,Keyshot 開始引入了基於 NVIDIA OptiX 光線追蹤渲染框架,實現了對 GPU 加速的支持。

在 Keyshot 的實際使用中,1920x1080 的視圖(Viewport)模式下,使用純 CPU (AMD Ryzen 3900X 3.8GHz 12 核、64GB DDR4-3600 內存)渲染一個場景(從視圖開始更新到完成清晰平滑的畫面),以往或者說 CPU 方式耗時大約是 90 秒,在啓用 GPU 渲染時,使用 Quadro RTX 40000 渲染耗時只需要 3 秒左右,性能提升了接近 30 倍。
在渲染輸出(Render)模式下,3840x2160 分辨率 128 取樣,從開始到結束,同樣配置,CPU 耗時 388 秒,而 GPU 渲染只需要 35 秒,性能提高了 10 倍。
毫不妥協的阿諾渲染器
相對於 Keyshot 偏向於可視化產品製造設計不同的是,Autodesk 公司的 Arnold(阿諾。沒錯,官方介紹名字就是源自那位胳膊比你大腿還粗的州長,以示自己是一個蠻力方案,這裏的蠻力是指衍生射線的完全隨機路徑追蹤方式)則是針對可視化藝術創作的三維渲染器。
Arnold 最初是由 Solid Angle 公司創辦人 Marcos Fajardo 開發的,當時是爲多倫多 CAST 軟件公司光照設計軟件 WYSIWYG 寫的一段光照追蹤代碼,WYSIWYG 後來贏得了工程艾美獎。
到了 2004 年,索尼電影和 Arnold 展開合作,共同開發代碼,將 Arnold 作爲主要渲染器,合作成果就是 2006 年獲得奧斯卡金像獎提名的動畫電影《怪獸屋》( Monster House),這部電影是一部蠻力 Path Tracing 渲染的動畫故事片,之後還有《天降美食》、《愛麗絲漫遊仙境》等作品。
Autodesk 公司在 2016 年收購了 Solid Angle 公司,隨後將 Arnold 追加到旗下的 Maya 和 3ds Max 三維設計軟件中,而在最新的 Arnold 6 中,集成了來自 NVIDIA 的 OptiX 光線追蹤渲染框架,支持圖靈架構的 RT Core 硬件光線追蹤加速,使得 Marcos 追求的蠻力光線追蹤美學得到了強大的助力。

上圖就是在 Autodesk Maya 採用 Arnold 渲染器分別以 Quadro RTX 和 CPU(雙路 Xeon Gold 6126 2.4GHz)的性能對比,可以看到,採用了 Quadro RTX 6000 後,Arnold 的速度提高了接近 1.4 倍,結合多卡渲染的話,性能依然可以達到比較好的延伸比例,如果採用 8 片 Quadro RTX 8000 或者說 RTX Server 的話,甚至可以達到接近 17 倍的性能提升。
這意味着什麼?這意味着如果要拿 CPU 來跑這個渲染可能需要 18 臺服務器,相較之下,如果採用基於 NVIDIA Quadro RTX 的 RTX Server,一臺就能搞定。

上圖 NVIDIA 官網提供的 RTX 服務器供應商清單,對客戶來說可供的選擇還是比較多的。
使用 RTX 服務器來做渲染是有很大好處的,在單機作業的情況下,系統進行成品渲染的話,本機系統的所有資源都會調用來跑渲染處理,幾乎不能再進行其他交互操作。
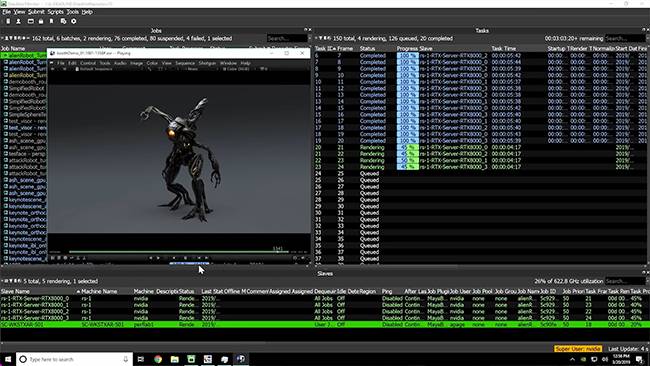
但是如果將渲染操作以隊列的方式扔到網絡中的 RTX 服務器的話,僅需將工作站處理的更新數據傳輸到服務器上(如上圖),在服務器渲染的時候,工作站的互動操作完全不受渲染影響。
人工智能輔助好萊塢
Quadro RTX 在電子藝術創作方面的性能加速當然不僅限於三維渲染,由於圖靈架構引入了 Tensor Core,使得 Quadro RTX 在一些視頻特效處理上也大放異彩,例如奧斯卡提名電影《The Irishman(愛爾蘭人)》和《Avengers: Endgame(復仇者聯盟:終局之戰)》都採用了人工智能加速實現減齡特效,成功將多位演員的銀幕年齡減少了幾十歲。


電影《愛爾蘭人》劇照,多位演員均採用了 ILM 的人工智能減齡特效
《愛爾蘭人》的劇情跨越了 60 年,化妝部門沒法自然地再現三位主演 2、30 歲的模樣,爲了保持畫面的可信性,電影沒有選擇多位不同年齡層的演員或者特效化妝技術來滿足劇情需要,而是讓演員 Robert DeNiro(76 歲,飾演角色二戰老兵 Frank "The Irishman" Sheeran,電影以 Frank 回望人生講述其黑手黨殺手生涯來展開)、Al Pacino(79 歲)、Joe Pesci(76 歲)本色演出。
攝像師透過兩臺改裝過的並行於主攝像機的 Arri mini 捕捉下人物的紅外特徵(這樣就無需在面部貼標記點了,原理就和手機上的 3D 結構光類似),然後在使用 Quadro RTX 專業卡執行人工智能技術進行減齡處理,在滿足了劇情需要的前提下實現了可信度和連貫性都非常高的畫面和角色塑造。
ILM 公司採用了演員們過往數千張照片作爲人工智能的學習對象,全流程使用 NVIDIA RTX 技術來加速這個操作,使得這部包含大量減齡處理的電影得以順利完成。

電影《復仇者聯盟之終局之戰》 終極反角 Thanos 的劇照
而電影《復仇者聯盟之終局之戰》一片中包含了 2500 組特效鏡頭,號稱史上最多特效鏡頭的電影,Digital Domain 的特效團隊使用機器學習技術爲大反派 Thanos 的演員 Josh Brolin 的表演構建了數字動畫版。
Digital Domain 採用名爲 Masquerade 的機器學習系統捕獲演員表演和表情變化的低分辨率版本,然後轉換成高分辨率 Thanos 面部,透過這個技術,顯著降低了動畫師的面部塑造工作量,縮短了後期製作時間。
圖靈架構助力抗擊新冠肺炎
人工智能技術在很多行業都有用武之地,特別是醫療方面的作用更是不容忽視。去年年底開始出現的新冠病毒(Covid-19)疫情到目前爲止依然在影響着大家的生活,在疫情大爆發的階段,病例確診能力一度成爲能否將疫情成功控制的關鍵所在。
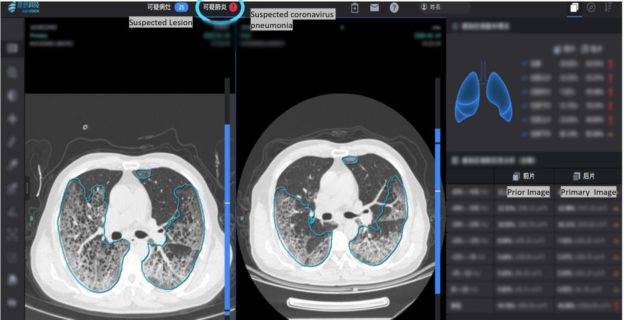
武漢中南醫院此時使用了支持 NVIDIA 圖靈 GPU 加速的人工智能軟件(由北京初創公司推想科技開發,採用了 NVIDIA 的人工智能醫療開發包),對 2000 多張 CT 影像進行了訓練。使用人工智能系統的主要優勢是速度,大多數傳統方法在面對大量處理需求的時候需要花費大量的時間,不過有了 AI 的幫忙,醫生可以快速確定追加治療方案。
目前,用於協助檢視新冠肺炎病症的 InferRead 肺炎 CT 解決方案已經爲全國超過 32 家醫院的一線醫生提供幫助。
Quadro RTX 實現全媒體全流程硬件加速
現在是快媒體爲王的時代,文字內容影響力早就被圖片、短視頻取代,而圖片、視頻創作往往是密不可分的,一個內容創作團隊使用的媒體創作工具五花八門,但是這些工具很可能都是由 Adobe 提供,例如照片衝圖用到的 Lightroom、圖片後期處理用到的 Photoshop、非線性視頻編輯用到的 Premiere Pro、視頻特效用到的 After Effect、生成三維紋理用到的 Substance 等等。NVIDIA 公司 Adobe 公司有緊密的合作關係,透過 Quadro RTX ,可以爲上述軟件提供全流程的硬件加速。
在超高分辨率視頻處理上,Quadro RTX 可以提供比目前頂級工作站 CPU 快 14 倍的加速處理(憑藉強大的通用處理性能和視頻編解碼能力),時間大大縮短。
這意味着什麼?
要知道創作人員有時候需要面對一些經常需要修改的客戶,如果修改幾遍的話,使用 CPU 跑 n 遍超高清視頻處理會讓人發瘋的,而有了 GPU 加速後,這樣的問題起碼可以輕鬆不少。
面對手機的日益流行,豎屏視頻成爲了在線短視頻的主流,而拍攝的時候可能採用的是橫構圖,如果要轉換成豎構圖的話,爲了確保拍攝主體適中位於畫面,就需要重新構圖,對於運動視頻來說,如果使用人工處理是需要消耗大量精力的,而 Quadro RTX 結合 Premiere Pro 的 AI 重構圖技術就可以實時的速度完成這個操作。
Quadro RTX 與全新的跨流程內容創作加速
全流程加速可以爲內容創作提高生產率,不過 NVIDIA 除了在硬件方面提供加速外,還提供了一個名爲 Omniverse 的開放式網絡協作平臺,可以簡化實時圖形工作室團隊的流程。
例如,使用 Maya 和 Omniverse 門戶的藝術家可以使用 UE4 和另一個藝術家合作,雙方可以看到應用程序修改的實時更新。這個情況就好像你使用 Word 修改一個文檔的時候,同事可以即時看到修改的內容,然後根據修改的內容對手頭的文檔進行及時的更新。
舉個栗子:
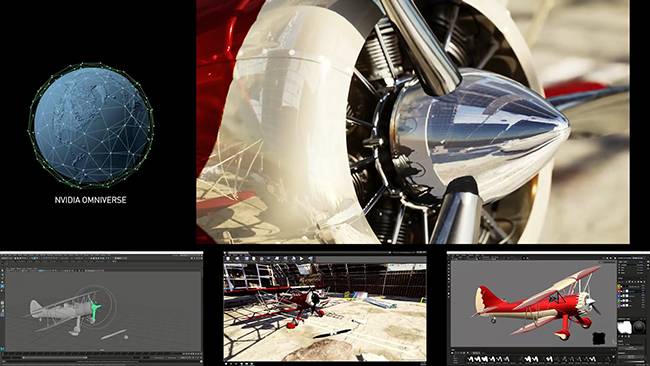
上面是一個 NVIDIA Omniverse 的應用場景,右上方的是 Omniverse Viewer 的顯示內容,下方是三個不同的設計師在分別使用 Maya(三維建模創作)、UE4(遊戲場景開發)、Adobe Substance(三維紋理處理)進行飛機建模、三維場景設計、紋理貼圖操作,三位設計師都使用了 Omniverse 平臺來進行實時電子藝術資產數據通信。
右上方的 Omniverse Viewer 可以即時呈現 UE4 設計師所做場景的實時渲染圖,三位設計師都能隨時透過 Omniverse Viewer 來觀看彼此協作的即時成果,這個工具對團隊協作效率的提升是非常巨大的。
Omniverse Viewer 採用了 Quadro RTX 的 CUDA 內核、光線追蹤內核、張量內核來實現逼真的實時渲染效果加速,世界各地的設計師、藝術家終於可以做到真正的合作無間了。
Quadro RTX 與大數據應用
大數據是最近幾年比較熱門的話題,所謂的大數據,一般是指無法用 Excel 這類辦公數據表軟件應對的海量數據,隨着互聯網的發展,信息的膨脹速度遠遠超出傳統數據處理方式能應對的能力,如何快速對大數據進行挖掘、清洗、整理並轉換成人類能明瞭、具有分析意義的圖表成爲當前蓬勃發展的新興業務。
NVIDIA 在這方面提供了一個名爲 RAPIDS 的解決方案,它將之前 NVIDIA 在 CUDA 開發方面的數學庫以及專門針對大數據處理新開發的框架集合在一起,讓開發人員可以使用 Python 語言調用 Quadro RTX GPU 實現海量數據的快速處理。
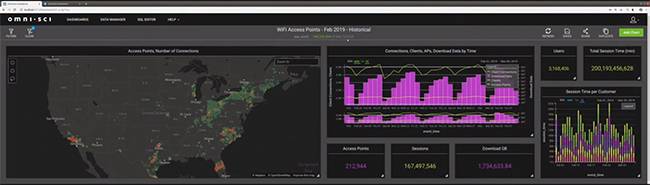
前身爲 MapD 的 OmniSci 公司就使用了 RAPIDS 對海量的 WIFI 節點數據進行處理,透過調用 Quadro RTX ,實現了對 5 億行數據的數據表的實時分析處理,最終形成一個儀表板式的動態數據圖表,這個儀表裏的地圖可以實時縮放,然後地圖中顯示的熱點分佈狀態也會即時更新。
一專多能的 Quadro RTX
Quadro 這個品牌最初是針對圖形工作站的,主要是爲了對工作站軟件中的視口(viewport)提供更快的交互渲染,專業卡的專就是指在專業圖形設計軟件上提供 viewport 加速。
在 Cg 語言推出後,NVIDIA 在 2004 年做了個名爲 Gelato 的商用 GPU 渲染器,這是 NVIDIA 首次嘗試使用 GPU 進行通用計算的開始。Gelato 在某種程度上有很大的實驗性意味,因爲當時使用 GPU 來做成品渲染的渲染器少之又少,但是正是因爲在 Gelato 的積累,使得 NVIDIA 獲得了寶貴的 GPU 通用計算開發經驗。
到了 2008 年 CUDA 發佈後,NVIDIA 推出了基於 GPU 通用計算 OptiX 光線追蹤渲染框架,經過 10 多年發展,OptiX 已經獲得業界的廣泛採用。從 Gelato 到 OptiX 再到後來遍地開花的第三方 GPU 渲染器,Quadro 系列作爲硬件基石一直伴隨左右,回過頭來看的話,「未來已來」這句話其實非常適合於 Quadro 這個產品線。

Quadro RTX 作爲圖靈架構的第一款產品推出的推出,讓人們首次實現了從 viewport 到最終幀渲染的全程加速,而 NVIDIA 一直奉行的圖形先決、兼顧通用的漸進式發展策略也被證明是成功的。
前面提到的 OmniSci 公司 WIFI 節點數據實時生成儀表盤圖表,就有地圖熱點分佈的應用;又比如新冠肺炎的肺部 CT 人工智能識別,有助於快速提高診斷和醫療方案的確定。比較特別的是,和 Tesla 不具備顯示輸出的限制相比,Quadro RTX 由於本身設計爲面向工作站,在顯示輸出方面有獨特的優勢,例如 CT 醫療影像往往需要高精度灰度顯示輸出能力,而 Quadro RTX 恰好可以滿足這方面的訴求,做到一卡多用。
可以說,在大部分情況下,Quadro RTX 在大數據、人工智能應用方面一點也不遜色於專門針對服務器加速的 Tesla 等產品,Tesla 和 Quadro 在很多特性方面都是共有的,例如 GeForce 不具備的 GPUDirect RDMA 等,相對於主要用於服務器的 Tesla 來說,你可以把放在(臺式或者移動)工作站裏的 Quadro RTX 視作「身邊的 Telsa」。
而 Quadro RTX 本身還有顯示輸出以及 USB-C VR 頭盔連接能力,加上面向工作站的硬件加速特性,使得它具有一專(圖形工作站)多能(大數據、人工智能等)的特殊定位。
最後值得一提的是,NVIDIA 今年 GTC 技術峯會由於受到疫情的影響,改爲完全線上的方式運作,網絡直播講座和課程將透過 GTC Digital 提供,GTC Digital 是免費註冊的。屆時 GTC Digital 會將大量的技術講座和課程在網上發佈,對於希望瞭解圖形、深度學習、大數據等業界最前沿發展動態的讀者來說,是非常不錯的年度盛宴。