
上個月剛剛和百度、阿里巴巴宣佈合作,又幫助微軟實現了醫療影像識別的技術突破。最近,有關 AI 芯片公司 Graphcore 的新聞越來越密集。事實上,這家公司正準備在全球人工智能計算領域向傳統架構的玩家發起衝擊。
本週,Graphcore 在中國首次舉行活動,介紹了自己的最新技術和業務進展。其專門爲機器智能設計的 IPU 架構,因採用大面積片上存儲等領先技術,已經在自然語言處理、圖像分類、金融等領域展現了自己的優勢。
隨着 AI 應用落地進程加快,機器學習和深度學習代表全新計算負載逐漸成爲雲計算的重要內容。這種計算需求大規模並行化、數據呈現稀疏結構,相較於高性能計算(HPC)的需求有着很大不同——機器智能通常需要低精度的計算。
然而很大程度上,現在機器學習不得不選擇傳統架構:面向普通應用和網絡設計的處理器 CPU,以及向量處理爲核心的 GPU 一直被廣泛應用於深度學習負載中。很多 AI 芯片公司認爲,現在以 GPU 爲依託的密集計算是不可持續的,AI 模型越來越大,算力需求正呈現指數級提升,我們需要全新的方法來做 AI 計算。
Graphcore 提出的 IPU,正是面向計算圖處理而設計的處理器。
IPU 的架構直面高效率 AI 計算的瓶頸:對於芯片來說,TFLOPS 的提升一直很快,但是內存吞吐量正逐漸成爲提升的難點,在實踐中經常會出現主板內通信能力無法滿足峯值算力吞吐的現象。與 CPU、GPU 相比,IPU 採用片上內存的形式,可以做到相比常規架構 10-300 倍的性能提升,時延只有訪問外存的 1%,低到可以忽略不計。
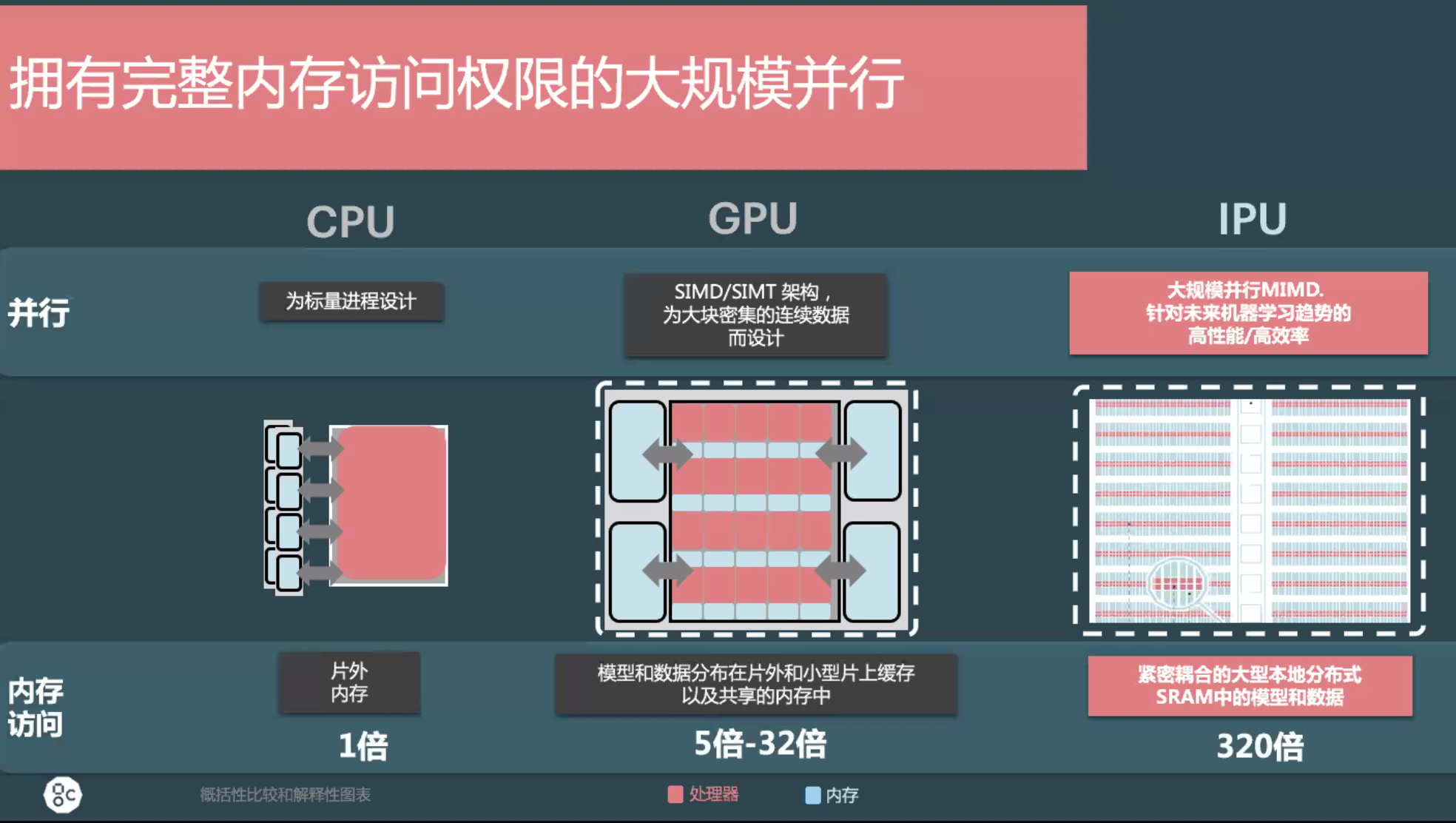
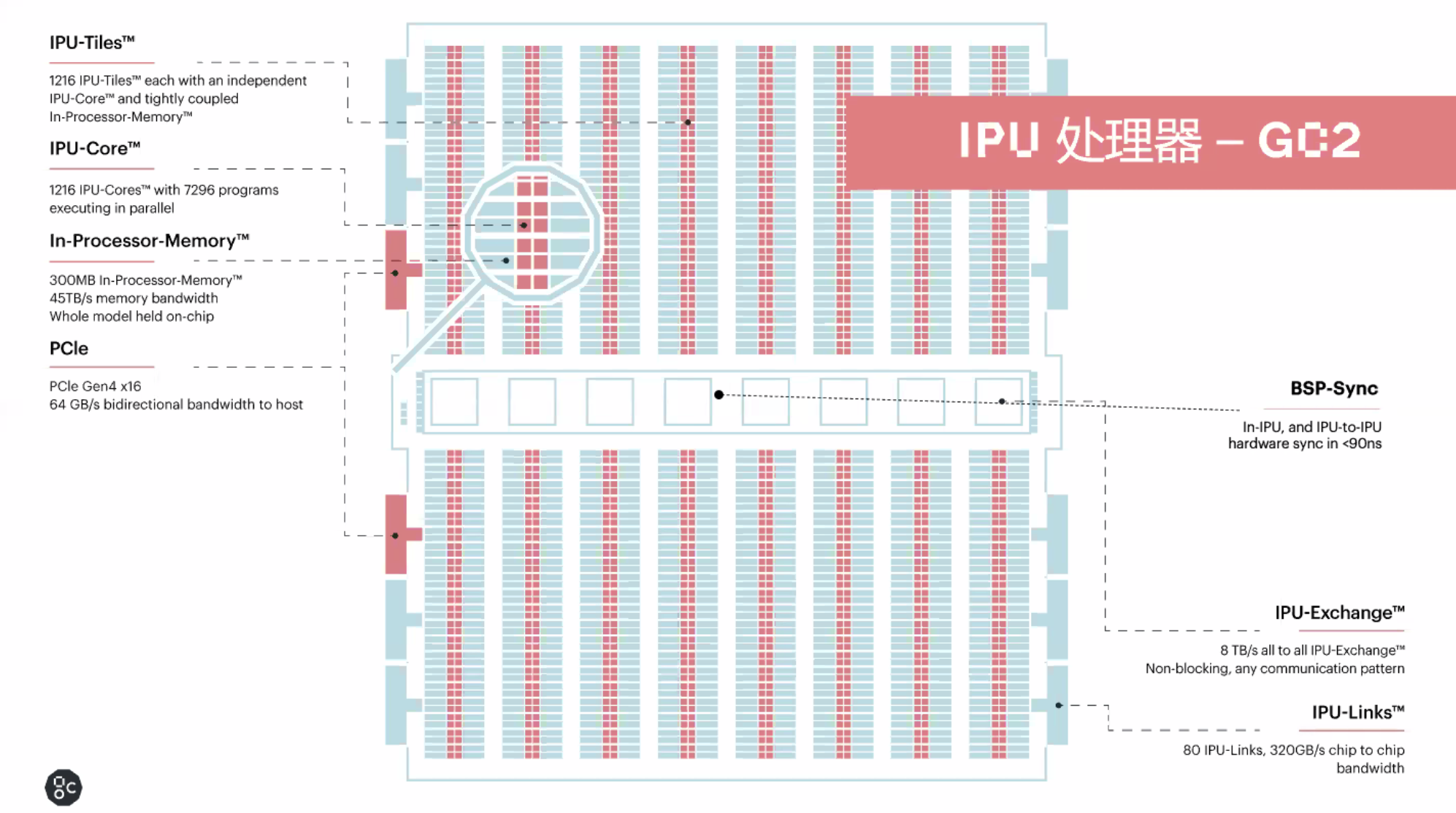
Graphcore 目前的 GC2 處理器採用臺積電 16nm 製程,內含 1216 個 IPU 核心,算力 1Peta FLOPS,支持 7296 線程並行運行,晶體管數量 236 億,功耗爲 120W。它包含高達 300MB 的處理器上存儲。所有機器學習模型都在片內進行處理,在 IPU 處理器之內,以及 IPU 之間的數據處理依靠 BSP-Sync 進行連接,延遲不到 90 納秒,而處理器核心之間的數據交換速度高達 8TB/s。
相比其他 AI 專用芯片,IPU 的通用性較高:和 GPU 一樣,Graphcore 芯片同時支持訓練和推理。
爲了解決如此大帶寬的並行挑戰,Graphcore 找到了大型計算機集羣的並行方式。IPU 是世界第一個 BSP 處理器,具有易於編程的特性:對於用戶來說,無需考慮 7200 多個線程如何分配。
強大的芯片也需要軟件的配合,Graphcore 一直在爲與 IPU 配合的 POPLAR 軟件體系投入大量精力。POPLAR 負責連接硬件與機器學習框架,同時提供大量工具,這款產品目前已實現對 TensorFlow、PyTorch 等框架提供了支持,很快還會上線對於國產 AI 深度學習平臺飛槳(PaddlePaddle)的支持。

Graphcore 表示,POPLAR 支持容器化的部署,可以在各種生態上運行,也支持虛擬化和相關安全技術。
今年 5 月,Graphcore 還推出了 POPVision 工具,支持以圖形化顯示軟件運行情況,效率調優結果等。POPLAR 文檔已經在包括 GitHub、知乎的各社區上線,這些內容可以幫助開發者把 TensorFlow 的模型用在 Graphcore 的 IPU 上。
「在 IPU 上,如果你是 TensorFlow、PyTorch 的 Python 語言開發者,改用的遷移成本非常低,」Graphcore 中國區總經理盧濤說道。「對於更高級的開發者來說,我們會盡量保持 Graphcore 軟件與 cuDNN 類似的體驗。但對於直接在 CUDA 上進行開發的人們來說,使用 POPLAR 還需要經歷重新開發的過程。」
今天爲止,基於 IPU 的應用已經覆蓋了機器學習的各個領域,開發者們也已把大多數流行模型的示例推向 GitHub,供他人使用。
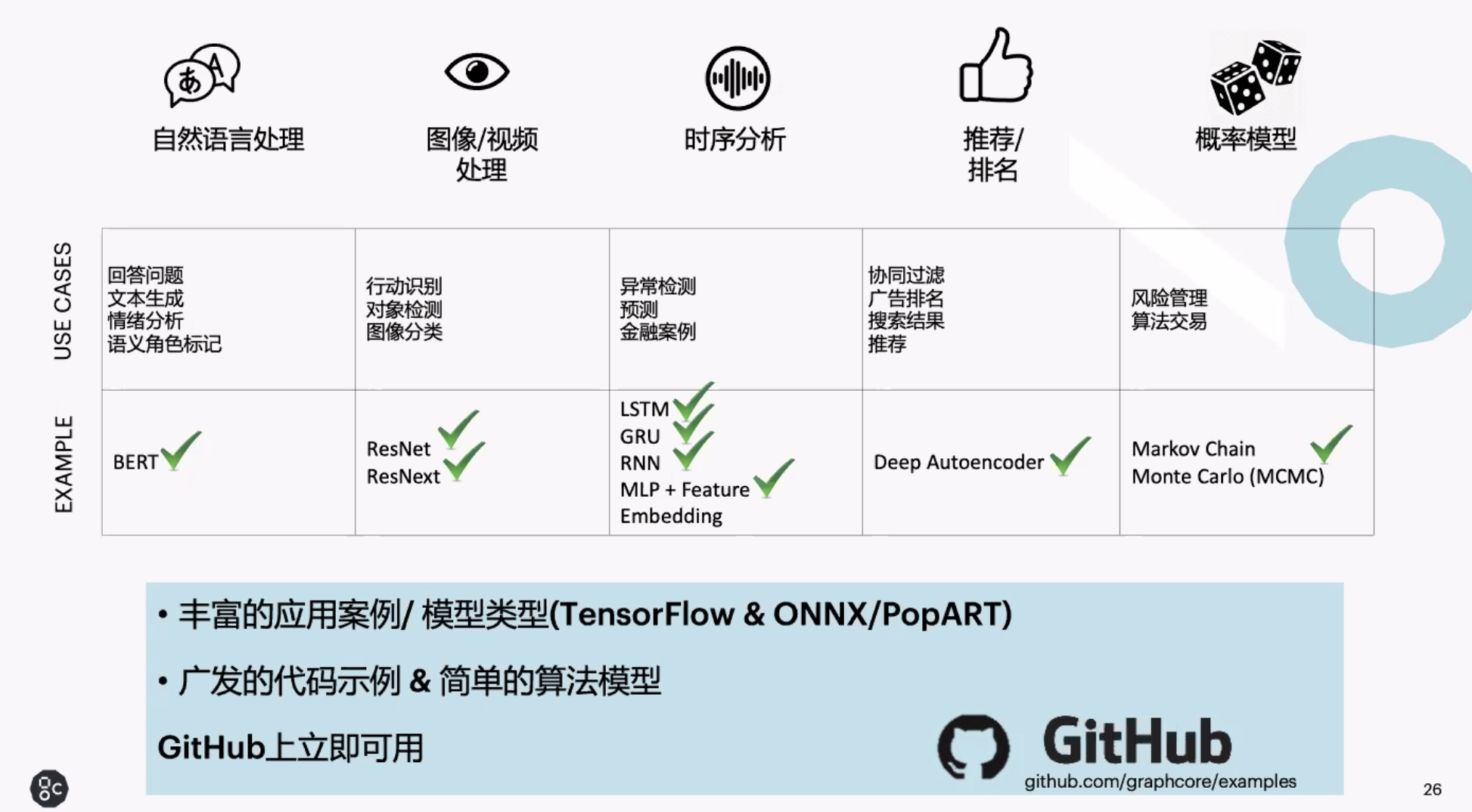
最重要的問題是:這些模型跑在 IPU 上速度如何?據 Graphcore 介紹,目前在流行算法上,IPU 可以說已經碾壓了最流行型號的 GPU。在訓練 BERT 時,8 塊 V100 GPU 需要花費 50 多個小時,而在同樣型號的服務器上使用 8 塊 IPU 只需要 30 多個小時,速度提升了 25%。而在推斷時,IPU 則有 50% 的速度提升。

更爲重要的是,IPU 的架構不僅可以提升已有模型的計算效率,還可以爲未來 AI 模型的發展打開道路。在 ResNet 這樣的圖像分類模型上,一塊 IPU 的訓練速度要比 V100 要快一倍左右,但如果是 EfficientNet 這樣採用分組卷積的模型時,IPU 的效率提升更是巨大。
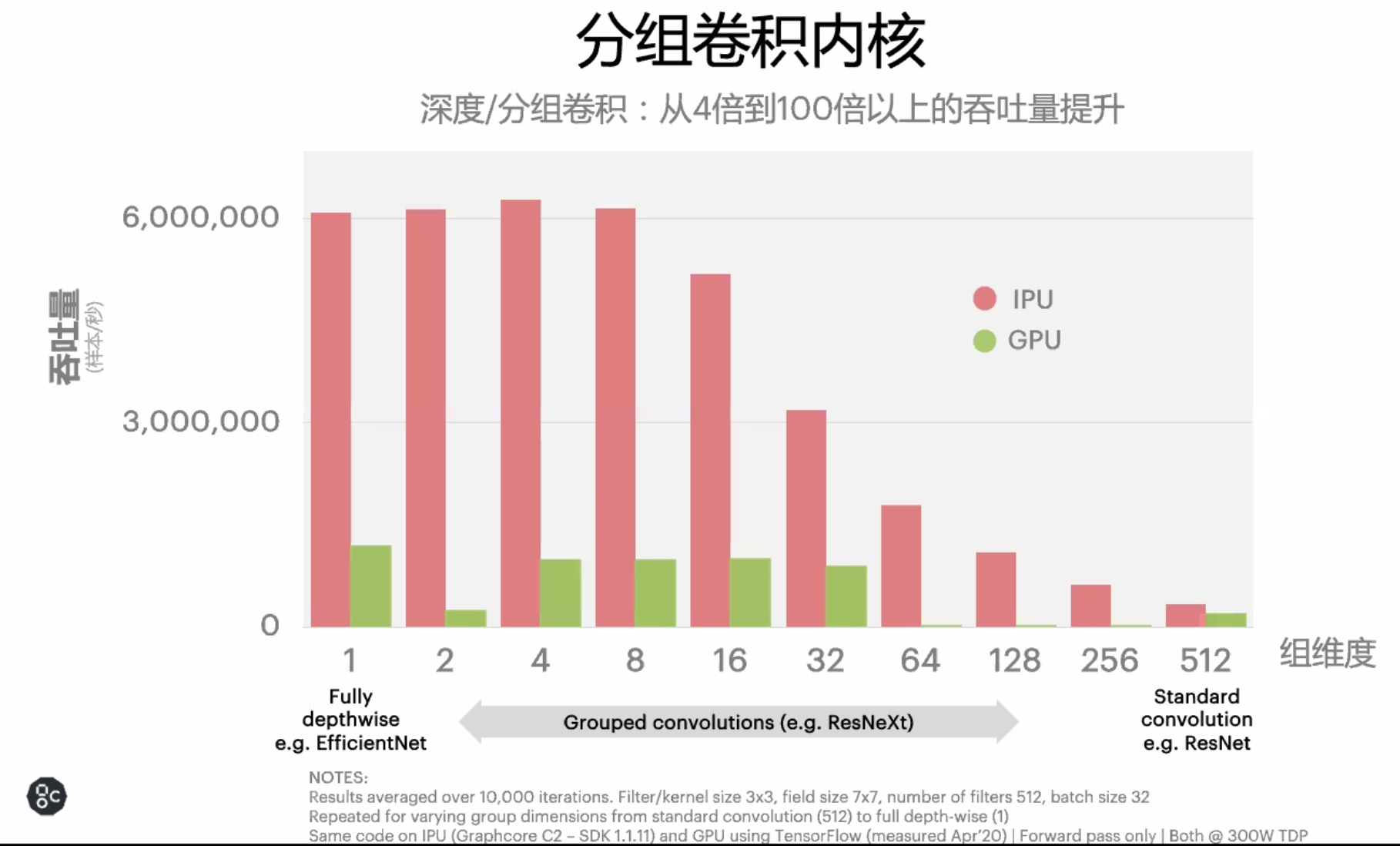
對於開發者來說,有時 GPU 無法支持極端低延時,高吞吐量需求的任務。有時一些模型在 GPU 上處理的很慢,需要開發者們花費精力提升算法,但如果不用稠密卷積,而採用分組卷積等方法,情況就會變得完全不同了。「深度學習模型在 GPU 上跑得不好並不是算法的問題,很多方法在 IPU 上就跑得非常好,」Graphcore 銷售總監朱江博士說道。
5 月份微軟提出的 SONIC 就是這樣的例子。在 EfficientNet 的基礎上,微軟研究人員針對 IPU 特點設計了 SONIC 模型,採用分組卷積等方法,其模型僅需要 430 萬參數,其推斷效果卻要比 EfficientNet 更好,而且更具泛化性。
「ResNet-50 帶有 2000 萬參數,EfficientNet 則帶有 500 多萬參數,我們認爲分組卷積將是未來的重要趨勢,」朱江表示。「現在人們正在思考將這些概念用在 NLP,特別是 BERT 上。這種思路或許爲開發者們打開了新的可能性。」
基於 IPU 的實體芯片和雲服務現在都已經上線。除了戴爾提供的整機,以及微軟 Azure 雲服務,Graphcore 在國內還在與金山雲等公司合作,即將推出基於 IPU 的雲服務。
Graphcore 一直是 AI 芯片界的明星公司,自 2016 年以來它的行動一直被業內關注。目前爲止,這家公司全球融資金額已超過 4.5 億美金,員工數量達到 450 人。
面對全球新常態,雲端的計算需求從算量到算力都有了爆發性增長,這一切似乎爲 AI 芯片提供了新的機遇。另一方面,英偉達剛剛推出的 7 納米架構安培也爲業界樹立了新的標杆。在挑戰和機遇面前,Graphcore 顯得很有信心。
「我們認爲英偉達 Tesla A100 的推出對於 Graphcore 是一個利好。新一代架構發佈之後,很多 AI 芯片創業公司都要被掃地出門,」盧濤說道。「我們相信,即使是第一代 IPU 產品在某些應用上的效果也不會輸於 A100。此外,英偉達 A100 採用了 7 納米工藝,Graphcore 現款 IPU 是 16 納米的,今年晚些時候我們也會出 7 納米的新一代產品。」