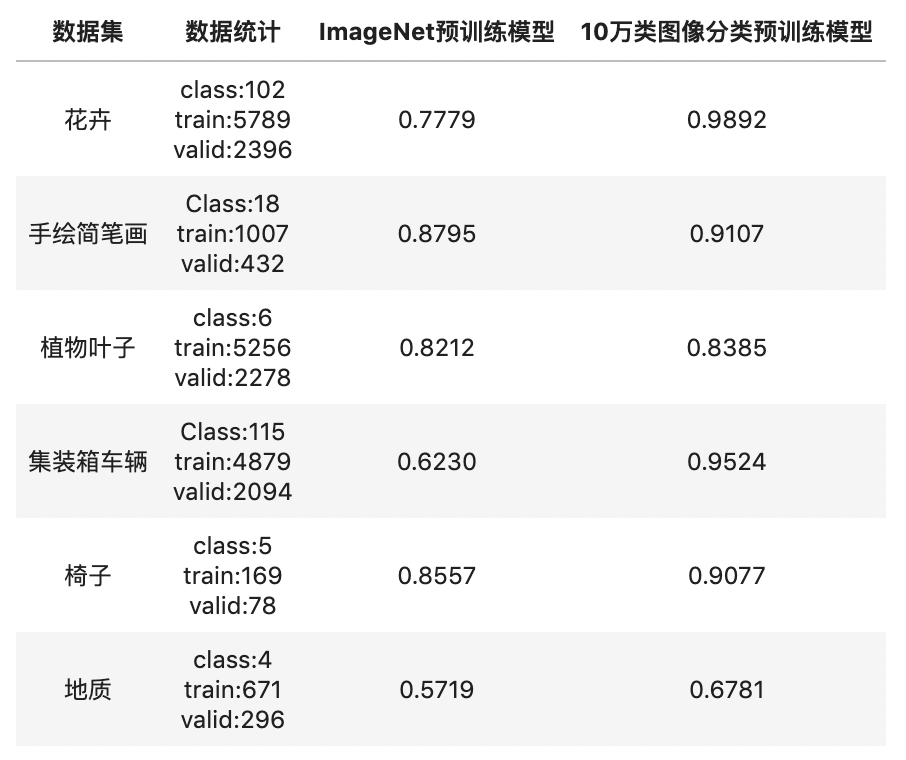
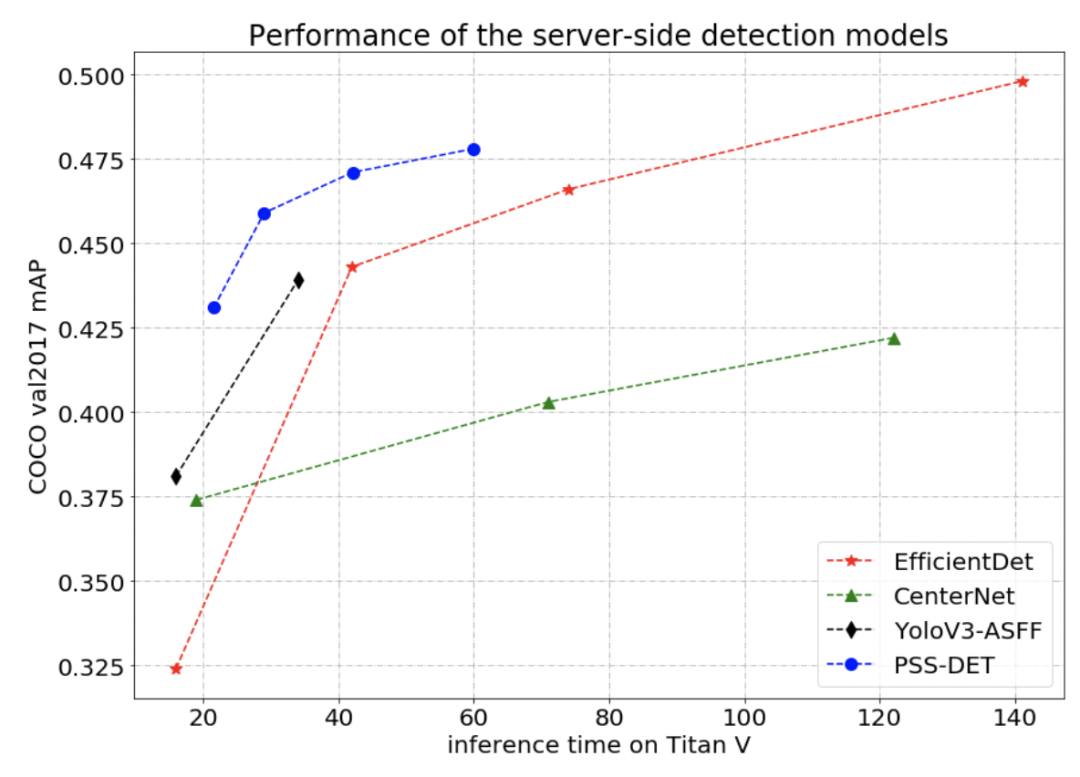
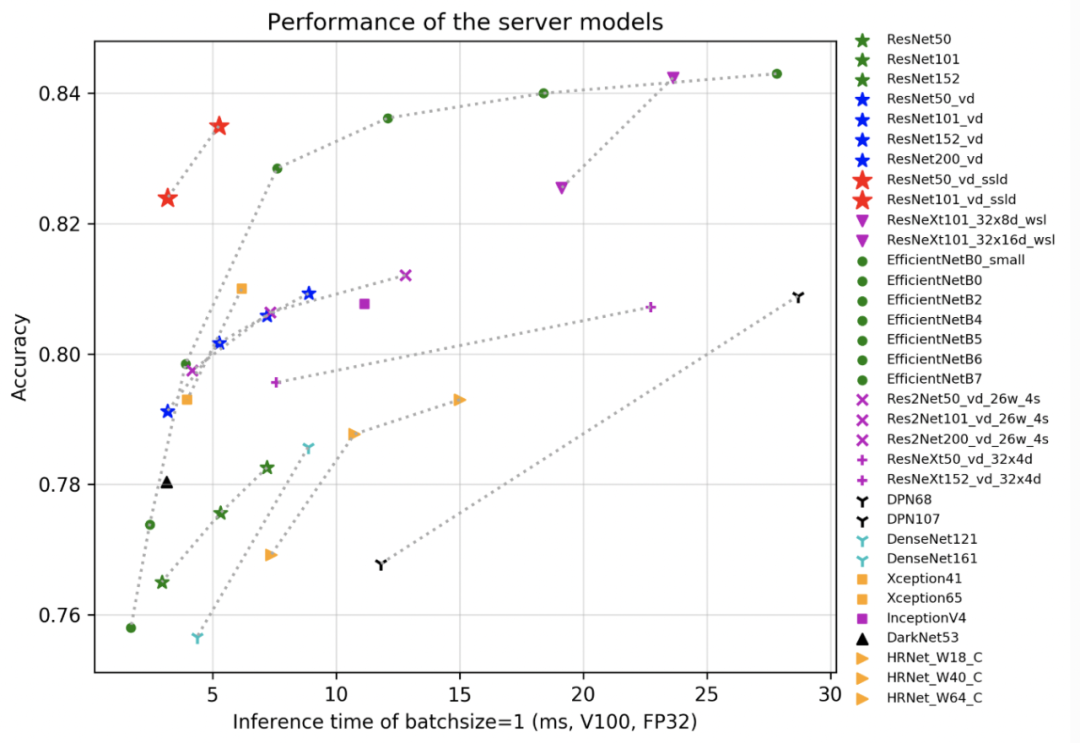
如何訓練出優秀的圖像分類模型?飛槳圖像分類套件 PaddleClas 來助力。



occlusion:識別目標被遮擋
scale:識別目標的尺度變化
deformation:識別目標變形
clutter:識別目標所處的背景嘈雜
illumination:識別目標所處環境的光照變化
viewpoint:拍攝識別目標的視角變化
object pose:識別目標的姿態變化


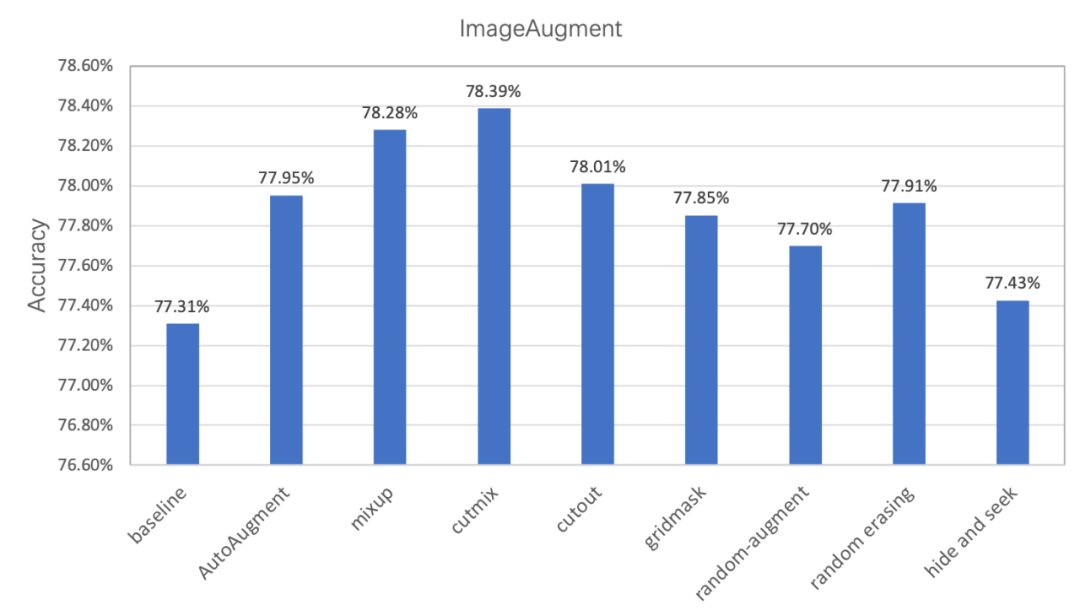
圖像變換類是指對全圖進行一些變換,包括 AutoAugment、RandAugment。
圖像裁剪類是指對圖像以一定的方式遮擋部分區域的變換,包括 CutOut、RandErasing、HideAndSeek、GridMask。
圖像混疊類是指多張圖進行混疊一張新圖的變換,包括 Mixup、Cutmix。