關於PyTorch和TensorFlow誰更好的爭論,從來就沒有停止過。
開源社區的支持度、上手的難易度都是重要的參考。還有人說:學術界用PyTorch,工業界用TensorFlow。

然而還有一項不可忽略的因素,就是二者的實際性能。
沒關係,不服跑個分?!
最近,一位來自「Huggingface」的工程師,使用了NLP中的Transformer模型,分別在兩大平臺上測試了一組推理速度。
雖然Huggingface只是一家創業公司,但是在NLP領域有着不小的聲譽,他們在GitHub上開源的項目,只需一個API就能調用27個NLP模型廣受好評,已經收穫1.5萬星。
PyTorch和TensorFlow究竟哪個更快?下面用詳細評測的數據告訴你。
運行環境
作者在PyTorch 1.3.0、TenserFlow2.0上分別對CPU和GPU的推理性能進行了測試。
兩種不同的環境中具體硬件配置如下:
- CPU推理:使用谷歌雲平臺上的n1-standard-32硬件,即32個vCPU、120GB內存,CPU型號爲2.3GHz的英特爾至強處理器。
- GPU推理:使用谷歌雲平臺上的定製化硬件,包含12個vCPU、40GB內存和單個V100 GPU(16GB顯存)。

在測試過程中使用本地Python模塊的timeit來測量推理時間。每個實驗重複30次,然後對這30個值取平均值,獲得平均推理時間。
NLP模型的Batch Size設置爲分別設置爲1、2、4、8,序列長度爲8、64,、128、256、512、1024。
測試結果
話不多說,先上跑分結果:
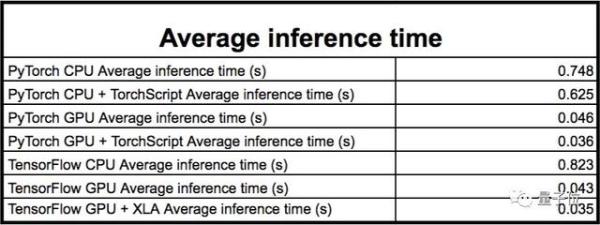
在大多數情況下,這兩個平臺都能獲得相似的結果。與PyTorch相比,TensorFlow在CPU上通常要慢一些,但在GPU上要快一些:
- 在CPU上,PyTorch的平均推理時間爲0.748s,而TensorFlow的平均推理時間爲0.823s。
- 在GPU上,PyTorch的平均推理時間爲0.046s,而TensorFlow的平均推理時間爲0.043s。
以上的數據都是在所有模型總的平均結果。結果顯示,輸入大小(Batch Size×序列長度)越大,對最終結果的影響也越大。
當輸入太大時,PyTorch會出現內存不足的情況。作者把這些部分從結果中刪除,因此這會使結果偏向PyTorch。
總的來說,PyTorch模型比TensorFlow模型更容易耗盡內存。除了Distilled模型之外,當輸入大小達到8的Batch Size和1024的序列長度時,PyTorch就會耗盡內存。
至於更完整詳細的清單,請參閱文末的Google文檔鏈接。
兩大平臺的加速工具
除了初步的測試,作者還用上兩個平臺獨有的加速工具,看看它們對模型推理速度有多大的提升。

TorchScript是PyTorch創建可序列化模型的方法,讓模型可以在不同的環境中運行,而無需Python依賴項,例如C++環境。
TorchScript似乎非常依賴於模型和輸入大小:
使用TorchScript可以在XLNet上產生永久的性能提升,而在XLM上使用則會不可靠;
在XLM上,TorchScript可以提高較小輸入時的性能,但會降低較大輸入時的性能。
平均而言,使用TorchScript跟蹤的模型,推理速度要比使用相同PyTorch非跟蹤模型的快20%。
XLA是可加速TensorFlow模型的線性代數編譯器。作者僅在基於TensorFlow的自動聚類功能的GPU上使用它,這項功能可編譯一些模型的子圖。結果顯示:
啓用XLA提高了速度和內存使用率,所有模型的性能都有提高。
大多數基準測試的運行速度提升到原來的1.15倍。在某些極端情況下,推理時間減少了70%,尤其是在輸入較小的情況下。
最後,作者還在Google文檔的列表裏還加入了「訓練」選項卡,或許不久後就能看到兩大平臺上的訓練測試對比,唯一擋在這項測試面前的障礙可能就是經費了。
傳送門
原文鏈接:
https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2