
在上一篇文章中我們介紹了自然語言處理的基礎問題——文本預處理的常用步驟。本文將進階講述特徵提取方面的相關算法。
如果用一句話總結目前 NLP 在特徵提取方面的發展趨勢,那就是「RNN 明日黃花,正如夕陽產業,慢慢淡出舞臺;CNN 老驥伏櫪,志在千里,如果繼續優化,還可能會大放異彩;Transformer 可謂如日中天,在特徵提取方面起着中流砥柱的作用」。至於將來,又會有什麼算法代替 Transformer,成爲特徵提取界的新晉寵兒。我想一時半會兒可能不會那麼快,畢竟算法開發可是個很漫長的過程。
現在我們就來探究一下,在 NLP 特徵提取方面,算法是怎樣做到一浪更比一浪強的。
RNN(循環神經網絡)
RNN 與 CNN(卷積神經網絡)的關鍵區別在於,它是個序列的神經網絡,即前一時刻的輸入和後一時刻的輸入是有關係的。
RNN 結構
下圖是一個簡單的循環神經網絡,它由輸入層、隱藏層和輸出層組成。

RNN 的主要特點在於 w 帶藍色箭頭的部分。輸入層爲 x,隱藏層爲 s,輸出層爲 o。U 是輸入層到隱藏層的權重,V 是隱藏層到輸出層的權重。隱藏層的值 s 不僅取決於當前時刻的輸入 x,還取決於上一時刻的輸入。權重矩陣 w 就是隱藏層上一次的值作爲這一次的輸入的權重。下圖爲具有多個輸入的循環神經網絡的示意圖:
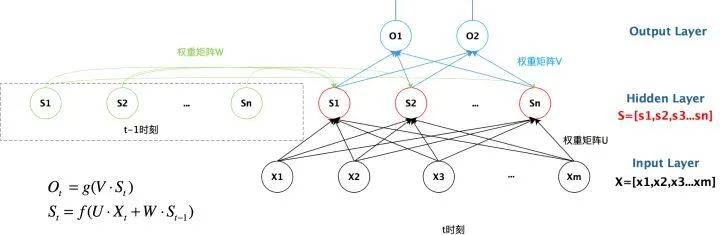
從上圖可以看出,Sn 時刻的值和上一時刻 Sn-1 時刻的值相關。將 RNN 以時間序列展開,可得到下圖:
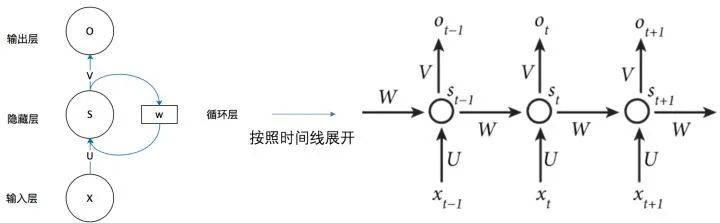
RNN 自引入 NLP 後,就被廣泛應用於多種任務。但是在實際應用中,RNN 常常出現各種各樣的問題。因爲該算法是採用線性序列結構進行傳播的,這種方式給反向傳播優化帶來了困難,容易導致梯度消失以及梯度爆炸等問題。
此外,RNN 很難具備高效的並行計算能力,工程落地困難。因爲 t 時刻的計算依賴 t-1 時刻的隱層計算結果,而 t-1 時刻的結果又依賴於 t-2 時刻的隱層計算結果……,因此用 RNN 進行自然語言處理時,只能逐詞進行,無法執行並行運算。
爲了解決上述問題,後來研究人員引入了 LSTM 和 GRU,獲得了很好的效果。
而 CNN 和 Transformer 不存在這種序列依賴問題,作爲後起之秀,它們在應用層面上彎道超車 RNN。
CNN(卷積神經網絡)
CNN 不僅在計算機視覺領域應用廣泛,在 NLP 領域也備受關注。
從數據結構上來看,CNN 輸入數據爲文本序列,假設句子長度爲 n,詞向量的維度爲 d,那麼輸入就是一個 n×d 的矩陣。顯然,該矩陣的行列「像素」之間的相關性是不一樣的,矩陣的同一行爲一個詞的向量表徵,而不同行表示不同的詞。
要讓卷積網絡能夠正常地「讀」出文本,我們就需要使用一維卷積。Kim 在 2014 年首次將 CNN 用於 NLP 任務中,其網絡結構如下圖所示:
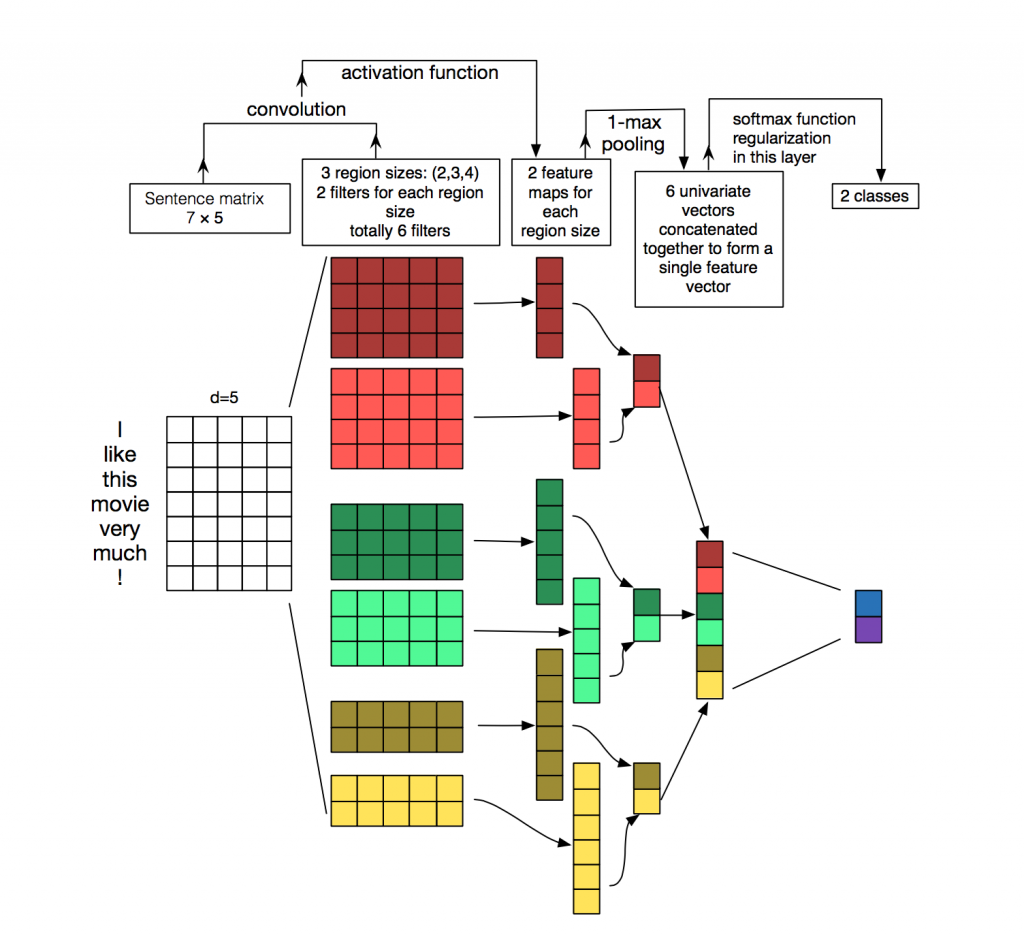
從圖中可以看到,卷積核大小會對輸出值的長度有所影響。但經過池化之後,可映射到相同的特徵長度(如上圖中深紅色卷積核是 4 × 5,對於輸入值爲 7 × 5 的輸入值,卷積之後的輸出值就是 4 × 1,最大池化之後就是 1 × 1;深綠色的卷積核是 3 × 5,卷積之後的輸出值是 5 × 1,最大池化之後就是 1 × 1)。之後將池化後的值進行組合,就得到 5 個池化後的特徵組合。
這樣做的優點是:無論輸入值的大小是否相同(由於文本的長度不同,輸入值不同),要用相同數量的卷積核進行卷積,經過池化後就會獲得相同長度的向量(向量的長度和卷積核的數量相等),這樣接下來就可以使用全連接層了(全連接層輸入值的向量大小必須一致)。
特徵提取過程
卷積的過程就是特徵提取的過程。一個完整的卷積神經網絡包括輸入層、卷積層、池化層、全連接層等,各層之間相互關聯。
而在卷積層中,卷積核具有非常重要的作用,CNN 捕獲到的特徵基本上都體現在卷積核裏了。卷積層包含多個卷積核,每個卷積核提取不同的特徵。以單個卷積核爲例,假設卷積核的大小爲 d×k,其中 k 是卷積核指定的窗口大小,d 是 Word Embedding 長度。卷積窗口依次通過每一個輸入,它捕獲到的是單詞的 k-gram 片段信息,這些 k-gram 片段就是 CNN 捕獲到的特徵,k 的大小決定了 CNN 能捕獲多遠距離的特徵。
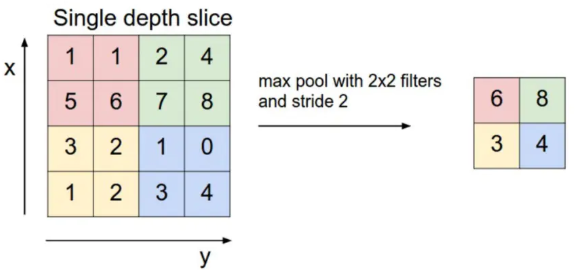
卷積層之後是池化層,我們通常採用最大池化方法。如下圖所示,執行最大池化方法時,窗口的大小是 2×2,使用窗口滑動,在 2×2 的區域上保留數值最大的特徵,由此可以使用最大池化將一個 4×4 的特徵圖轉換爲一個 2*2 的特徵圖。這裏我們可以看出,池化起到了降維的作用。
最後通過非線性變換,將輸入轉換爲某個特定值。隨着卷積的不斷進行,產生特徵值,形成特徵向量。之後連接全連接層,得到最後的分類結果。
但 CNN 網絡也存在缺點,即網絡結構不深。它只有一個卷積層,無法捕獲長距離特徵,卷積層做到 2 至 3 層,就沒法繼續下去。再就是池化方法,文本特徵經過卷積層再經過池化層,會損失掉很多位置信息。而位置信息對文本處理來說非常重要,因此需要找到更好的文本特徵提取器。
Transformer
Transformer 是谷歌大腦 2017 年論文《Attentnion is all you need》中提出的 seq2seq 模型,現已獲得了大範圍擴展和應用。而應用的方式主要是:先預訓練語言模型,然後把預訓練模型適配給下游任務,以完成各種不同任務,如分類、生成、標記等。
Transformer 彌補了以上特徵提取器的缺點,主要表現在它改進了 RNN 訓練速度慢的致命問題,該算法採用 self-attention 機制實現快速並行;此外,Transformer 還可以加深網絡深度,不像 CNN 只能將模型添加到 2 至 3 層,這樣它能夠獲取更多全局信息,進而提升模型準確率。
Transformer 結構
首先,我們來看 Transformer 的整體結構,如下是用 Transformer 進行中英文翻譯的示例圖:
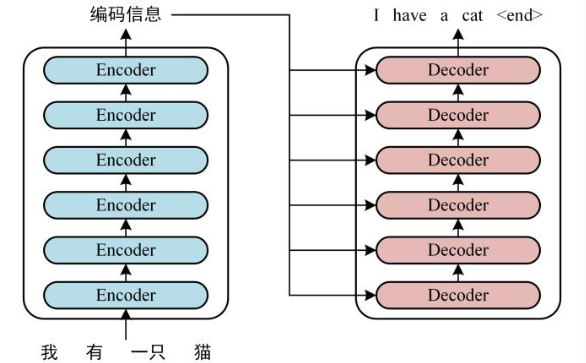
我們可以看到,Transformer 由兩大部分組成:編碼器(Encoder) 和解碼器(Decoder),每個模塊都包含 6 個 block。所有的編碼器在結構上都是相同的,負責把自然語言序列映射成爲隱藏層,它們含有自然語言序列的表達式,但沒有共享參數。然後解碼器把隱藏層再映射爲自然語言序列,從而解決各種 NLP 問題。
就上述示例而言,具體的實現可以分如下三步完成:
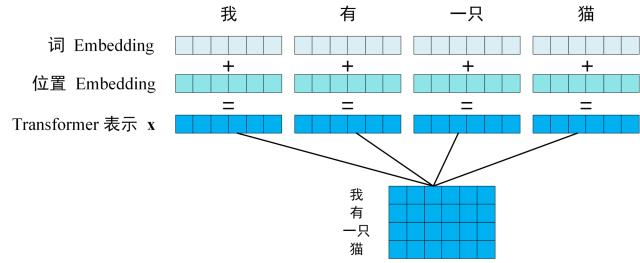
第一步:獲取輸入單詞的詞向量 X,X 由詞嵌入和位置嵌入相加得到。其中詞嵌入可以採用 Word2Vec 或 Transformer 算法預訓練得到,也可以使用現有的 Tencent_AILab_ChineseEmbedding。
由於 Transformer 模型不具備循環神經網絡的迭代操作,所以我們需要向它提供每個詞的位置信息,以便識別語言中的順序關係,因此位置嵌入非常重要。模型的位置信息採用 sin 和 cos 的線性變換來表達:
PE(pos,2i)=sin(pos/100002i/d)
PE (pos,2i+1)=cos(pos/100002i/d)
其中,pos 表示單詞在句子中的位置,比如句子由 10 個詞組成,則 pos 表示 [0-9] 的任意位置,取值範圍是 [0,max sequence];i 表示詞向量的維度,取值範圍 [0,embedding dimension],例如某個詞向量是 256 維,則 i 的取值範圍是 [0-255];d 表示 PE 的維度,也就是詞向量的維度,如上例中的 256 維;2i 表示偶數的維度(sin);2i+1 表示奇數的維度(cos)。
以上 sin 和 cos 這組公式,分別對應 embedding dimension 維度一組奇數和偶數的序號的維度,例如,0,1 一組,2,3 一組。分別用上面的 sin 和 cos 函數做處理,從而產生不同的週期性變化,學到位置之間的依賴關係和自然語言的時序特性。
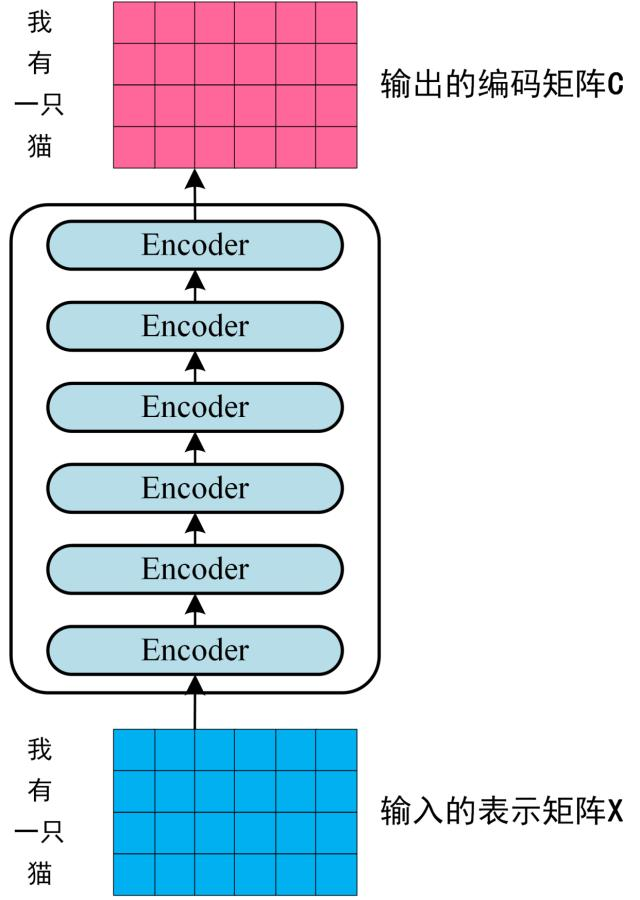
第二步:將第一步得到的向量矩陣傳入編碼器,編碼器包含 6 個 block ,輸出編碼後的信息矩陣 C。每一個編碼器輸出的 block 維度與輸入完全一致。
第三步:將編碼器輸出的編碼信息矩陣 C 傳遞到解碼器中,解碼器會根據當前翻譯過的單詞 1~ i 依次翻譯下一個單詞 i+1,如下圖所示:

Self-Attention 機制
下圖展示了 Self-Attention 的結構。在計算時需要用到 Q(查詢), K(鍵值), V(值)。在實踐中,Self-Attention 接收的是輸入(單詞表示向量 x 組成的矩陣 X)或者上一個 Encoder block 的輸出。而 Q, K, V 正是基於 Self-Attention 的輸入進行線性變換得到的。
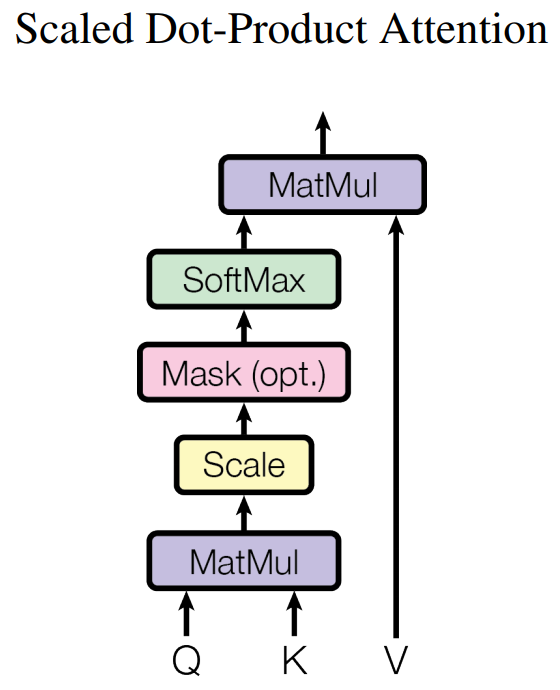
那麼 Self-Attention 如何實現呢?
讓我們來看一個具體的例子(以下示例圖片來自博客 https://jalammar.github.io/illustrated-transformer/)。
假如我們要翻譯一個詞組 Thinking Machines,其中 Thinking 的詞向量用 x1 表示,Machines 的詞向量用 x2 表示。
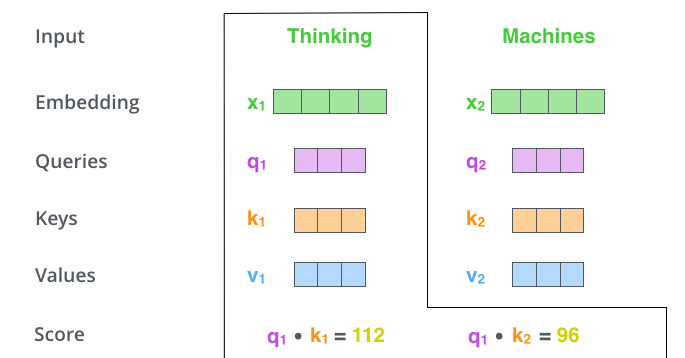
當處理 Thinking 這個詞時,需要計算它與所有詞的 attention Score,將當前詞作爲 query,去和句子中所有詞的 key 匹配,得出相關度。用 q1 代表 Thinking 對應的 query vector,k1 及 k2 分別代表 Thinking 和 Machines 的 key vector。在計算 Thinking 的 attention score 時,需要先計算 q1 與 k1 及 k2 的點乘,同理在計算 Machines 的 attention score 時也需要計算 q_2 與 k1 及 k2 的點乘。如上圖得到了 q1 與 k1 及 k2 的點乘,然後進行尺度縮放與 softmax 歸一化,得到:
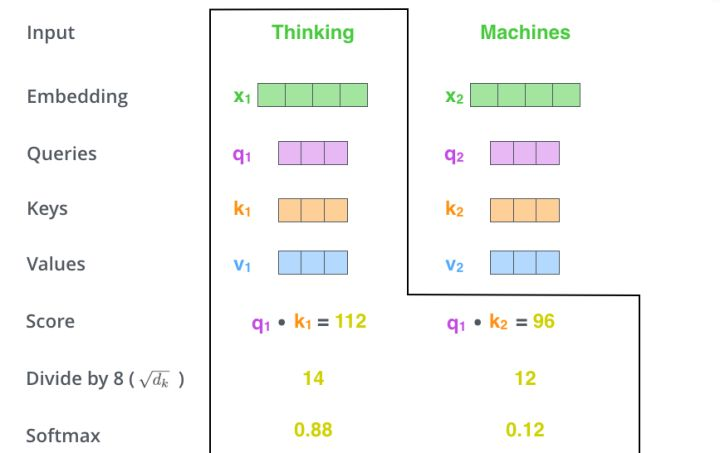
顯然,當前單詞與其自身的 attention score 最大,其他單詞根據與當前單詞的重要程度得到相應的 score。然後再將這些 attention score 與 value vector 相乘,得到加權的向量。
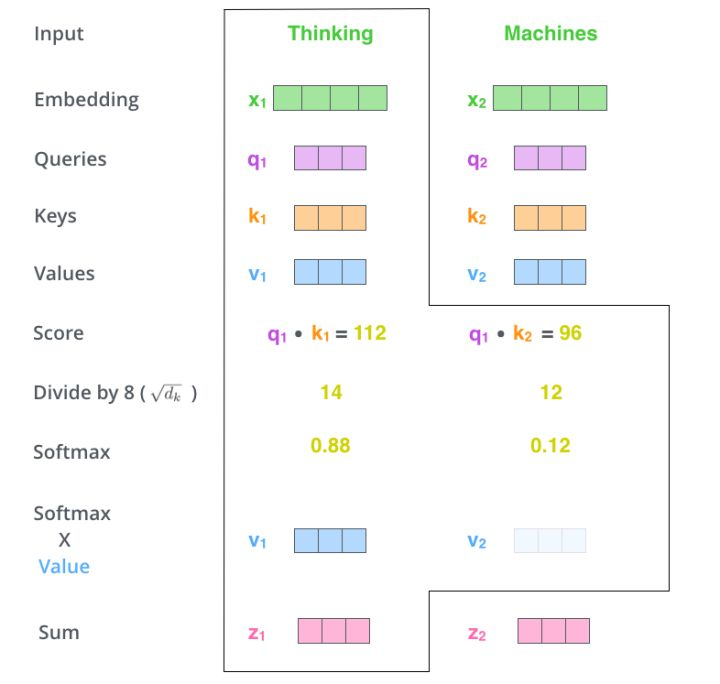
如果將輸入的所有向量合併爲矩陣形式,則所有 query, key, value 向量也可以合併爲矩陣形式表示。以上是一個單詞一個單詞的輸出,如果寫成矩陣形式就是 Q*K,經過矩陣歸一化直接得到權值。
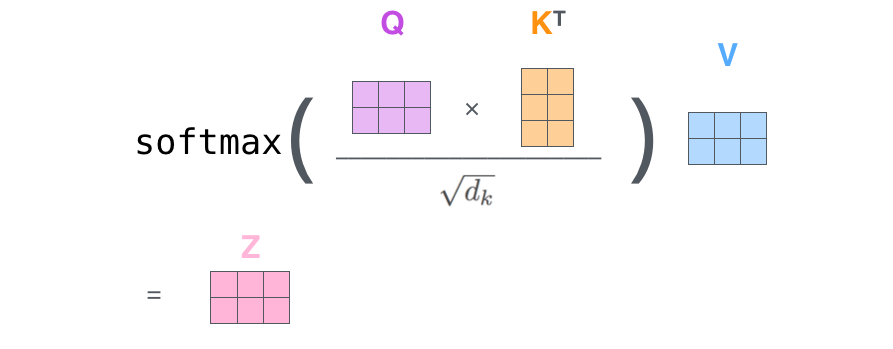
總結
RNN 在並行計算方面存在嚴重缺陷,但其線性序列依賴性非常適合解決 NLP 任務,這也是爲何 RNN 一引入 NLP 就很快流行起來的原因。但是也正是這一線性序列依賴特性,導致它在並行計算方面要想獲得質的飛躍,近乎是不可能完成的任務。而 CNN 網絡具有高並行計算能力,但結構不能做深,因而無法捕獲長距離特徵。現在看來,最好的特徵提取器是 Transformer,在並行計算能力和長距離特徵捕獲能力等方面都表現優異。
在之後的文章中,我們將繼續介紹 NLP 領域的相關內容,敬請期待。
參考鏈接:
http://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf
https://www.sohu.com/a/299824613_814235
https://zhuanlan.zhihu.com/p/30844905
https://baijiahao.baidu.com/s?id=1651219987457222196&wfr=spider&for=pc
https://www.cnblogs.com/sandwichnlp/p/11612596.html
https://zhuanlan.zhihu.com/p/54356280
https://www.jianshu.com/p/d2df894700bf