乾明 發自 凹非寺
量子位 報道 | 公衆號 QbitAI
理科生文藝起來,可能真沒文科生什麼事了。
不信?你看下這首七言絕句:

有網友讀完之後表示:
不僅能夠寫詩,還能作詞,比如這首滿江紅:

而且,還能寫藏頭詩:

你能想象,這是完全不懂寫詩的理工生的傑作嗎?
但它就是。
這些詩來自華爲諾亞方舟實驗室新推出的寫詩AI「樂府」。
問世之處便引發了不少關注。
對於它的作品,有人稱讚:
蘊意豐富的詩,工整不乏意趣,程序做的實在牛逼,給開發人員點贊
還有人「搞事情」,表示:
一聲塞雁江南去,幾處家書海北連。莫道徵鴻無淚落,年年辛苦到燕然。要說這個 AI 寫的沒有北大中文系平均水平好我是不信的。

甚至有人說「李白看了會沉默,杜甫看了會流淚」。

當然,也有人指出問題:
很工整,不過感覺目前大多還是syntax層面的,沒有到semantics層面。稍微欠缺些靈魂。
也有「真相帝」出來發聲:
辛棄疾的流水散文式用典,老杜的沉鬱頓挫拗救法,都是AI比較難學會的。問題不是AI太厲害,而是讀者已經看不出格律詩裏面比較精密的手法了…

對於這些問題,華爲諾亞方舟實驗室語音語義首席科學家劉羣也在微博進行了答疑,披露了不少這隻AI背後的故事:
其實我們也不懂詩,我們也沒有用詩的規矩去訓練這個系統,完全是系統自己學到的。
那麼,這一AI到底是如何學的?論文已經公佈。

理工男の文藝源自GPT
與自由生成文本不同,生成中國的古詩詞是一個挑戰,通常需要滿足形式和內容兩個方面的要求。
中國的古詩詞有各種各樣的形式,比如五絕、七絕、五律、七律、滿江紅、西江月、水調歌頭等各種詞牌以及對聯,每一種都有相應的字數、押韻、平仄、對仗等規定;
內容方面雖然簡單,但要求更加難以琢磨:一首詩要圍繞着一個主題展開,內容上還要具有連貫性。
華爲提出的「樂府」系統,與當前大多數解決方案不同,不需要任何人工設定規則或者特性,也沒有設計任何額外的神經元組件。
整個研究中,需要做的就是把訓練用的詩詞序列化爲格式化的文本序列,作爲訓練數據。
然後通過對語言模型token的抽樣,生成滿足形式和內容要求的詩詞,比如絕句、律詩、詞,以及對聯等等。
而且,他們還提出並實現了一種對模型進行微調以生成藏頭詩的方法。
這背後的能量來自GPT,一個由OpenAI提出的預訓練自然語言模型,核心理念是先用無標籤的文本去訓練生成語言模型,然後再根據具體的任務通過有標籤的數據對模型進行微調。
樂府AI是首個基於GPT打造的作詩系統,而且與谷歌提出的BERT息息相關。
整體的GPT模型是在BERT的源代碼基礎上實現的,Transformer大小的配置與BERT-Base相同,也採用了BERT中發佈的tokenization 腳本和中文 vocab。
具體來說,訓練詩歌生成模型的過程如下:
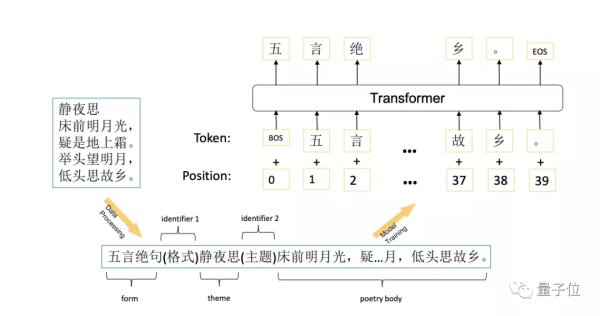
整個模型訓練過程一共有兩個階段: 預訓練和微調。
華爲的這個GPT模型,是用一箇中文新聞語料庫進行預訓練的,然後通過收集了公開可得的中國古詩詞進行微調。
如上圖所示,首先將示例詩歌轉換爲格式化序列。序列包括三個主要部分:格式、主題和詩體,中間用標識符分開。
在對聯中,因爲沒有主題,就上句爲主題,第二行爲正文。所以,在生成對聯的時候,就成了給出上聯,生成下聯的模式,也符合了「對對子」的習慣。
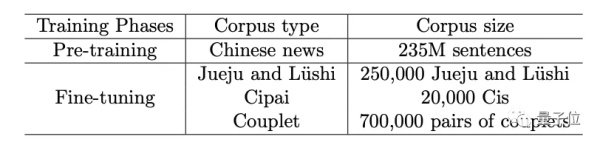
整體的數據集規模並不小,預訓練用的中文新聞語料庫,有2.35億句子。微調用的數據集有25萬絕句和律師,2萬首詞以及70萬對對聯。
預訓練是在華爲雲上完成的,使用8塊英偉達V100(16G) GPU訓練了4個echo,一共耗費了90個小時。
微調的過程是將所有詩歌序列輸入Transformer,並訓練一個自迴歸語言模型。目標是觀測任何序列的概率最大化:
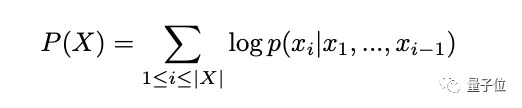
微調的過程,不需要特別長的時間,如果訓練過長,這個模型就在生成過程中,就會傾向於從語料庫中直接用原始句子了。
訓練完成後,先將要生成的詩歌的格式和主題轉化爲一個初始序列,然後將初始序列輸入到模型中,然後對詩體部分的剩餘字段按token進行解碼。
在解碼過程中,並不使用硬約束來保證格式的正確性,而是讓模型自動爲特定位置分配逗號和句號,在識別到token爲「EOS」的時候,解碼過程結束。
而且,採用截斷 top-k 抽樣策略來獲得不同的詩歌,而不是束搜索。具體是每次採樣一個Token時,首先選擇具有 top-k 最大概率的Token,然後從 top-k Token中採樣一個特定的token。
他們說,即使採用截短的 top-k 抽樣策略,生成的詩歌仍然是正確的形式。
論文中介紹稱,訓練藏頭詩的方法也是這樣,只是在格式化序列的時候方法有所不同:用每一行中第一個字符的組合來代替一首詩的原始主題:「五言絕句(格式)牀疑舉低(藏頭詩)牀前明月光,疑…月,低頭思故鄉。」
效果如何,華爲也在論文中進行了充分的展示,比如下面這四首「江上田家」,只有一首是唐朝詩人寫的,其他三首都是來自樂府AI。

從上到下,ABCD,你能辨別出來哪個是真跡嗎?(答案在文末揭曉)
誰是第一AI詩人?
中國古詩詞生成AI,華爲「樂府」並不是第一個,也不是最後一個。
在此之前,就有清華大學孫茂松團隊提出的「九歌」。

根據官方介紹,這一系統的採用深度學習技術,結合多個爲詩歌生成專門設計的模型,基於超過80萬首人類詩人創作的詩歌進行訓練學習,具有多模態輸入、多體裁多風格、人機交互創作模式等特點。
近日,也有人基於中文版的語料訓練出了中文版的GPT-2,並將其用於詩歌生成。
就在「樂府」上線的這一天,還有北京大學、國防科大等機構聯合發佈了新的作詩模型,基於無監督機器翻譯的方法,使用基於分段的填充和強化學習根據白話文生成七言律詩。
那麼,哪一個更強呢?
因爲中文版GPT-2和北京大學聯隊的系統還沒有開放體驗,參與這場「華山論劍」的就只有華爲「樂府」和清華「九歌」兩個選手。
第一輪:主題「夏日」,七言絕句
清華九歌賦詩一首:

華爲樂府賦詩是這樣的:

兩個AI都有瑕疵的地方,清華九歌一張嘴就開始說「秋來」,華爲樂府也提到了「四月」,並沒有特別的意思,顯然都與夏日有些出入。
但相比之下,華爲樂府的夏日元素也更多一些,比如荷香,夏陰等等。
第二輪:主題「長夜」,五言絕句
來自清華九歌的詩是這樣的:

不須愁獨坐,相對倍悽然?這個意境Emmm……婚姻要破裂了?
華爲樂府的作品:

直觀上來看,意境刻畫不錯,但衝擊力有所不足。
這一輪,兩個AI表現都不錯,而且都有相應的意境體現出來。相對來說, 清華九歌的情感層次更豐富一些。
第三輪,藏頭詩「神經網絡」,七言絕句
清華九歌作品是這樣的:

從押韻和意境來看,都還不錯。華爲樂府給出了這樣一首詩:

同樣,這首藏頭詩也能夠展現幾分意境。
這一輪,兩隻AI都能較確切地完成任務,給出了具有幾分意境的詩詞。
至此,經過三輪比拼,整體上來說,高下難分。其差別,在於雙方的實現方式。
清華九歌,基於多個爲詩歌生成專門設計的模型,相對來說比較複雜,在詩歌的格式上,控制比較嚴格,雖然嚴肅但作詩速度的確比較慢。
而華爲的樂府,只是基於GPT,按照劉羣的話來說,他們也不懂詩歌,並沒有用詩的規矩去訓練這個系統,完全是系統自己學到的,生成詩歌的時候速度很快。
對於樂府AI生成的詩歌水平,劉羣也頗爲謙虛:
我們找過懂詩的人看,說韻律平仄並不完全符合規矩,只是外行讀起來還比較順口而已。
至於兩種方式孰優孰劣,也不妨參考下那句老話:文無第一。
華爲諾亞方舟實驗室
華爲諾亞方舟實驗室成立於2012年,隸屬於華爲2012實驗室。
諾亞方舟爲名,也能體現出這一實驗室在華爲內部的重要性。此前,任正非也提到過,希望這些實驗室能夠成爲華爲的「諾亞方舟」。
目前,這一實驗室在深圳、香港、北京、上海、西安、北美和歐洲等城市設有分部。研究方向包括計算機視覺、自然語言處理、搜索推薦、決策推理、人機交互、AI理論、高速計算等。
關於樂府AI,華爲也在論文中標註說明,這是他們在研究GPT時的一個副產品。目前,華爲樂府AI已經在小程序EI體驗空間上線。
支持五言絕句、七言絕句、五言律詩和七言律詩,以及藏頭詩模式。作詞、對對子還沒有上線。
最後,附上一首樂府生成的七言律詩人工智能。

對了,答案選C。
相關傳送門:
樂府AI論文
GPT-based Generation for Classical Chinese Poetry
https://arxiv.org/pdf/1907.00151.pdf
清華九歌作詩網站:
http://118.190.162.99:8080/
—完—
量子位 · QbitAI