YoloV4訓練自定義的數據集模型
本文由林大佬原創,轉載請註明出處,來自騰訊、阿里等一線AI算法工程師組成的QQ交流羣歡迎你的加入: 1037662480
最近YoloV4成了新的吊打一切的目標檢測算法,考慮速度和精度V4的全方位能力甚至超越了EfficientDet,根據本人實測的經驗,關於v4我們可以形成一個這樣的總結:
- 精度幾乎不用懷疑,很強,比EfficientDet靠加大圖片分辨率提高檢測能力的模型要好;
- 顯存比efficientdet節省很多,efficientdetD4 900的分辨率筆記本上幾乎無法跑,而同樣的CSPDarknet的YoloV4可以在2G顯存的筆記本上跑;
- 速度很快,這個速度很快如何定義呢?EfficientDet的FLOPs是比較少,但是速度並不一定快,關於FLOPs和速度的區別大家可以看看一些比較的文章,據我所知現在社區已經有了tensorRT加速的YoloV4,速度在1080Ti上可以跑到20ms,很快了。
最後可以說V4的整體素質真的強,幾乎可以「吊打一切」。但其內部的原理其實很簡單,整個結構和yolov3沒有本質的區別。今天這篇文章就是教大家如何在darknet框架下訓練自己的yolov4模型,同時實現推理和預測。在當下其他的框架還沒有完整的比較好的復現的情況下,使用darknet訓練模型並部署不失爲一個很好的方法,現在很多yolov3的pytorch parser實際上可以讀取darknet的weights轉換成pytorch的weights。
darknet yolov4訓練自定義數據集
自定義數據集的訓練要求也很簡單。先來看看訓練的command,假設你已經編譯好了darknet:
./build_release/darknet detector train data/my_dataset.data cfg/yolov4-my_dataset.cfg backup/yolov4-my_dataset.weights -map在data裏面提供的就是圖片的路徑,每一行就是一張圖片,cfg裏面就是網絡結構的定義。那麼我們首先要準備的就是這兩個文件了,接着就可以開始訓練(請注意,如果你不是resume訓練,那麼可以從yolov4官方repo裏面下載對應的conv73的weights進行開始訓練)。
假設你的數據集是VOC格式的,我們的步驟主要分爲兩個:
- 在
scripts.py下運行一個voc_label.py的腳本(如果你的沒有分0712,可以用下面提供的),這個腳本會生成對應的labels(裏面包含的是txt格式的yolo標註),以及train.txt也就是上面的訓練圖片目錄; - 運行上面的命令開始訓練。
聽起來很簡單吧?其實也不難,最關鍵的是darknet的代碼看起來十分的穩健,只要你按照這些步驟來,就不會有錯,當然,似乎還漏掉了最後一步,修改yolov4的網絡結構,因爲這和你的類別數據有關。但這個我們放到最後,因爲有點複雜。
先來準備你的數據吧。上面說了分爲兩部,但其實你需要先把你的VOC格式標註的數據軟連接到 data下面。這樣在原始darknet的目錄下,你就有了一個data/VOC2018的文件夾,這裏面存放的是你自己標註的VOC格式的數據。
然後運行這個腳本,生成我們需要的東西:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import sys
sets=[('2018', 'train'), ('2018', 'val')]
classes = ["a", "b", "c", "d"]
# soft link your VOC2018 under here
root_dir = sys.argv[1]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open(os.path.join(root_dir, 'VOC%s/Annotations/%s.xml'%(year, image_id)))
out_file = open(os.path.join(root_dir, 'VOC%s/labels/%s.txt'%(year, image_id)), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
labels_target = os.path.join(root_dir, 'VOC%s/labels/'%(year))
print('labels dir to save: {}'.format(labels_target))
if not os.path.exists(labels_target):
os.makedirs(labels_target)
image_ids = open(os.path.join(root_dir, 'VOC{}/ImageSets/Main/{}.txt'.format(year, image_set))).read().strip().split()
list_file = open(os.path.join(root_dir, '%s_%s.txt'%(year, image_set)), 'w')
for image_id in image_ids:
img_f = os.path.join(root_dir, 'VOC%s/JPEGImages/%s.jpg\n'%(year, image_id))
list_file.write(os.path.abspath(img_f))
convert_annotation(year, image_id)
list_file.close()
print('done.')
然後你在scripts的目錄下運行一下:
python3 voc_label_aabb.py ../data/VOC2018這時候,你需要的東西就會在data下面生成。你需要的data文件就是這樣的:
classes= 4
train = data/2018_train.txt
valid = data/2018_val.txt
names = data/aabb.names
backup = backup/這些你都有了,4是你自己的類別數目。
最後我們說一下如何修改cfg網絡結構。
主要修改的點如下,按照順序來:
[net]開頭這部分:
# 2000*num_classes
max_batches = 8000
policy=steps
steps=6400,7200
你需要按照你的類別數目,修改這個max_batches, 通常就是2000x你的類別數。然後steps就是上面數字的80%和90%的分界點。- 每個yolo layer前的最後一個conv:
[convolutional]
size=1
stride=1
pad=1
# (80+5)x3=255 (4+5)x3=60
filters=27
activation=linear
修改一下filters,它的數目爲:(num_classes + 5)x3 - 最後就是yolo layer裏面的classes:
[yolo]
mask = 6,7,8
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=4
其他的不需要修改。
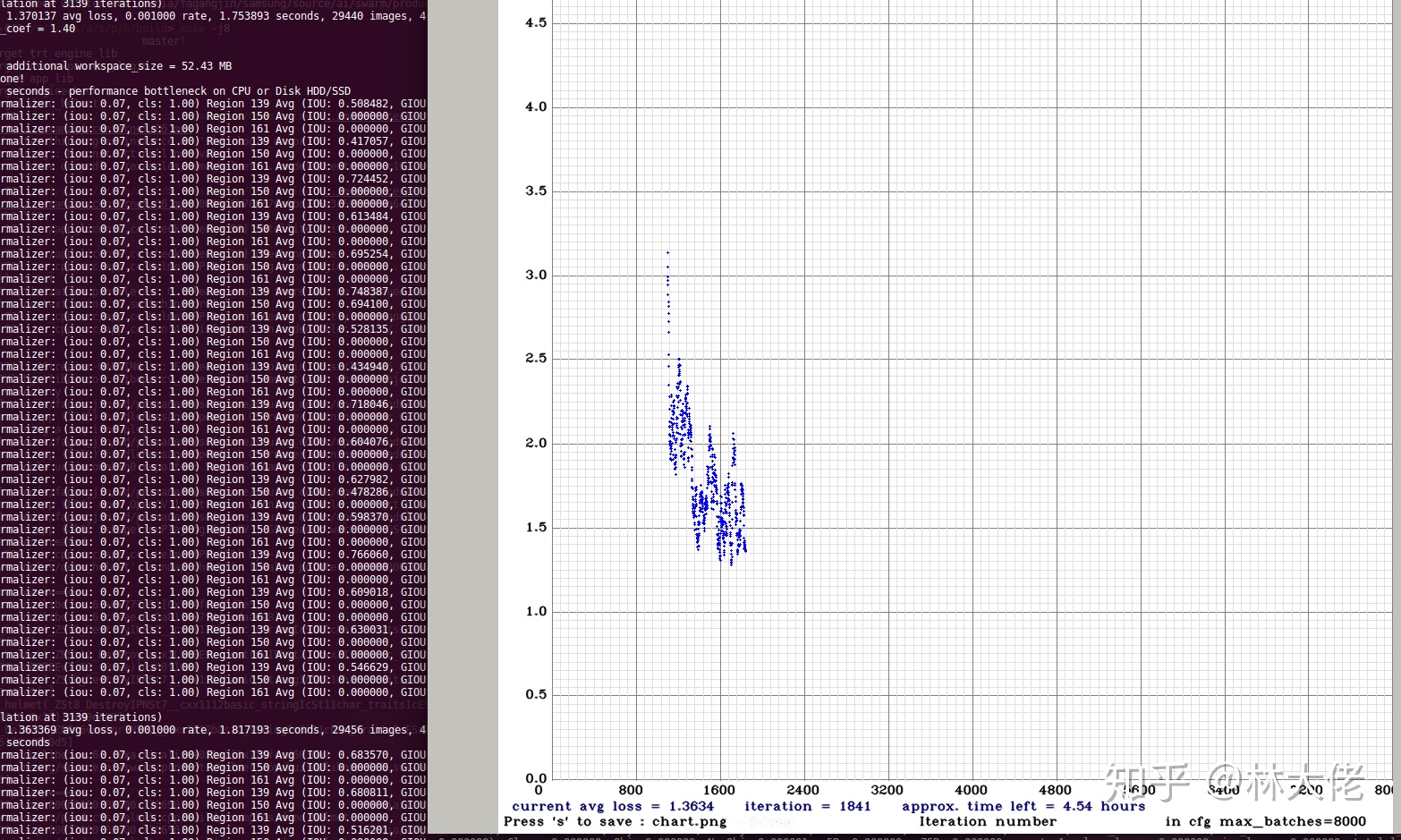
訓練結果
yolov4的訓練過程非常快,到大概1000個iter就差不多有一個可以用的結果了。自定義的數據集訓練出來也很好。
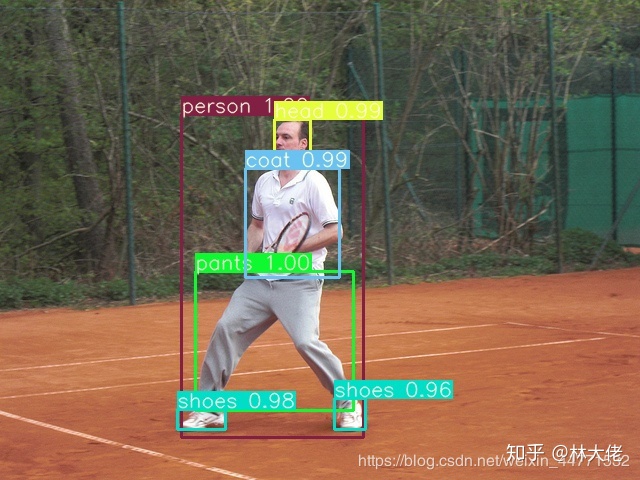
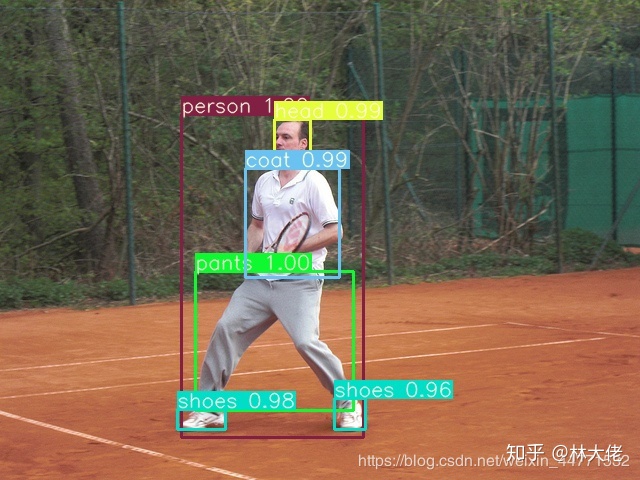
總結一下:
Yolov4是真的強,小物體檢測很穩定,同時置信度很高,這比一些anchor-free的算法要好很多。相比於efficientdet,它的置信度其實是很低的,在一些對把握度要求很高的場合,yolov4更具有優越性。
彩蛋
我們在GTX1080上測試通過TensorRT加速的YoloV4的模型,在標準版本的輸入下,採用fp32推理,其速度可以達到20ms,速度高達48fps。這對一個高精度檢測算法來說,已經很不錯了。

如果你對自定義數據集訓練yolov4有任何疑問,歡迎來社區交流:
如果你需要TensorRT加速的YoloV4,歡迎假如QQ羣與我們交流。
歡迎廣大AI愛好者加入我們的AI學習者羣,與強者同行,學習最精尖的技術:1037662480 (QQGroup)