幫趣
幫趣
拿transformer做E2E全景分割,這個通用框架霸榜挑戰賽,南大、港大聯合提出
2021-10-19 15:00:13.0
語義分割
和
實例分割
是兩個重要且相互關聯的視覺問題,它們之間的潛在聯繫使得全景分割可以統一這兩個任務。在全景分割中,圖像信息被分成兩類:Things 和 Stuff。其中 Things 是可數的實例 (例如,人、汽車、自行車),每個實例都有一個惟一的 id,以區別於其他實例。Stuff 是指無定形和不可數的區域 (如天空、草原和雪),沒有實例 id。
Things 和 Stuff 之間的差異也導致了不同的處理方式。許多工作只是將全景分割分解爲 Things
實例分割
任務和 Stuff
語義分割
任務。然而,這種分離處理策略會增加模型的複雜性和不必要的工件。雖然一些研究考慮自底向上的
實例分割
方法,但這種方法仍然保持了類似的分離策略。還有一些方法在處理 Things 和 Stuff 任務時,試圖通過在一個統一的框架中來簡化全景分割 pipeline 來實現。
來自南京大學、香港大學、英偉達等機構的研究者提出了 Panoptic SegFormer,這是一個使用 Transformer 進行端到端全景分割的通用框架。該方法擴展了 Deformable DETR,併爲 Things 和 Stuff 提供了統一的 mask 預測工作流程,使全景分割 pipeline 簡潔高效。
論文地址:https://arxiv.org/pdf/2109.03814v1.pdf
該研究使用 ResNet-50 作爲網絡主幹,在 COCO test-dev 拆分中實現了 50.0% 的 PQ,在無需附屬條件(bells and whistles)的情況下,結果顯著優於 SOTA 方法。此外,使用性能更強的 PVTv2-B5 作爲網絡主幹,Panopoptic SegFormer 在 COCO val 和 test-dev 拆分上以單尺度輸入實現了 54.1%PQ 和 54.4%PQ 的新記錄。
論文作者之一、英偉達研究院高級研究科學家 Zhiding Yu 表示:「目前,Panoptic SegFormer 在 COCO 2020 全景分割挑戰賽中位列第一名。」
COCO 全景分割挑戰賽地址:https://competitions.codalab.org/competitions/19507#learn_the_details-overview
方法研究
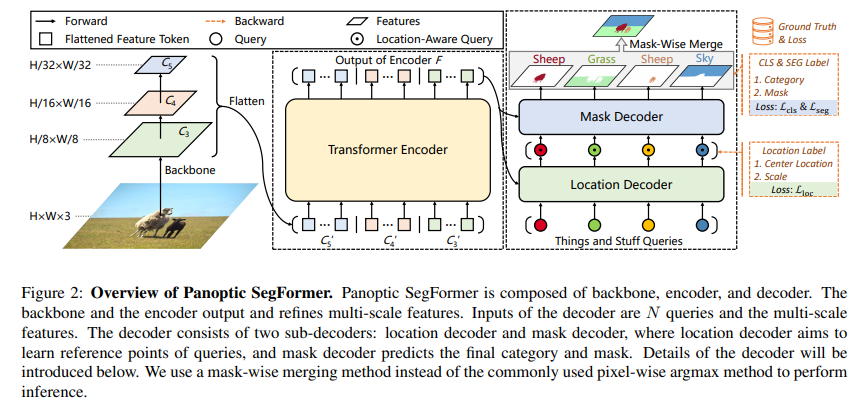
如圖 2 所示,Panoptic SegFormer 由三個關鍵模塊組成:transformer 編碼器、位置解碼器(location decoder)、掩碼解碼器(mask decoder)。其中:
(1)transformer 編碼器用於細化主幹給出的多尺度特徵圖;
(2)位置解碼器用於捕獲物體的位置線索;
(3)掩碼解碼器用於最終分類和分割。
圖 2:Panoptic SegFormer 架構。
Transformer 編碼器
分割任務中有兩個比較重要的因素:高分辨率和多尺度特徵圖。由於多頭注意力層的計算成本很高,以前基於 transformer 的方法只能在編碼器中處理低分辨率的特徵圖,這限制了分割性能。與這些方法不同,該研究使用可變形注意力層來實現 transformer 編碼器。由於可變形注意層的計算複雜度較低,因此該研究的編碼器可以將位置編碼細化爲高分辨率和多尺度特徵
映射
。
位置解碼器
在全景分割任務中,位置信息在區分具有不同實例 id 的 things 方面起着重要作用。受此啓發,該研究設計了一個位置解碼器,將 things 和 stuff 位置信息引入到可學習的
查詢
中。
具體來說,給定 N 個隨機初始化的
查詢
和由 Transformer 編碼器生成的細化特徵 token,解碼器將輸出 N 個位置
感知
查詢
。在訓練階段,該研究在位置
感知
查詢
之上應用輔助 MLP 頭來預測目標物體的中心位置和尺度,並使用位置損失 L_loc 進行監督預測。請注意,MLP 頭是一個輔助分支,在推理階段可以丟棄。
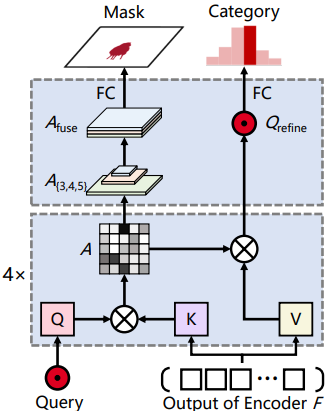
掩碼解碼器
如圖 3 所示,掩碼解碼器根據給定的
查詢
來預測物體類別和掩碼。掩碼解碼器的
查詢
Q 是來自位置解碼器的位置
感知
查詢
,掩碼解碼器的鍵 K 和值 V 是來自 transformer 編碼器的細化特徵 token F。
圖 3:掩碼解碼器架構。
Mask-Wise 推理
全景分割要求爲每個像素分配一個類別標籤(或空白)和一個實例 id(對於 stuff 忽略 id)。一種常用的後處理方法是啓發式過程,它採用類似 NMS 的過程來生成 things 的非重疊
實例分割
,稱之爲 mask-wise 策略。
對於 stuff,該研究採用基於啓發式過程的 mask-wise 策略來生成非重疊結果,而不是 pixel-wise 策略。此外,該研究平等的對待 things 、stuff ,並通過它們的置信度分數來解決所有掩碼之間的重疊,而不是在啓發式過程中(things 和 stuff 着兩者)傾向於 things,這標誌着該研究所用方法與其他方法之間的差異。Mask-Wise 推理過程如下所示:
Mask-Wise 推理過程。
實驗
該研究在 COCO 上對 Panoptic SegFormer 進行評估,並將其與 SOTA 方法進行比較。實驗提供了全景分割的主要結果和一些可視化結果。
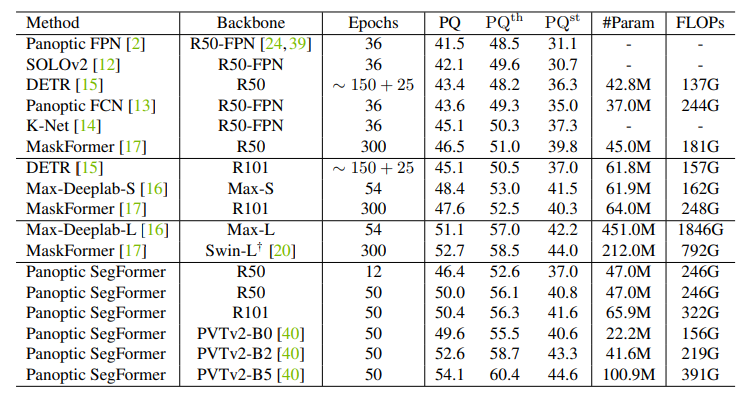
該研究在 COCO val set 和 test-dev set 上進行實驗。下表 1 和表 2 報告了 Panoptic SegFormer 與其他 SOTA 方法的對比結果。Panoptic SegFormer 在以 ResNet-50 作爲主幹和單尺度輸入的的情況下,在 COCO val 上獲得了 50.0% PQ,並且超過了之前的方法 PanopticFCN 和 DETR ,分別提高了 6.4% PQ 和 6.6% PQ。
表 1:在 COCO val set 上的實驗。Panotic SegFormer 在以 ResNet-50 爲主幹的 COCO val 上實現了 50.0% 的 PQ,超過了之前的方法。
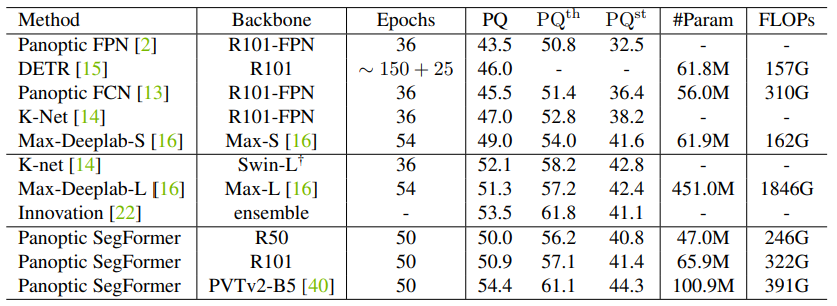
下表 2 中:在 COCO test-dev set 進行實驗,以 PVTv2-B5 作爲主幹,Panoptic SegFormer 在 COCO test-dev 上實現了 54.4% 的 PQ,超越 SOTA 方法 Max-Deeplabe-L 和競爭級方法 Innovation,分別超過 3.1% PQ 和 0.9% PQ,且
參數
和計算成本更低。
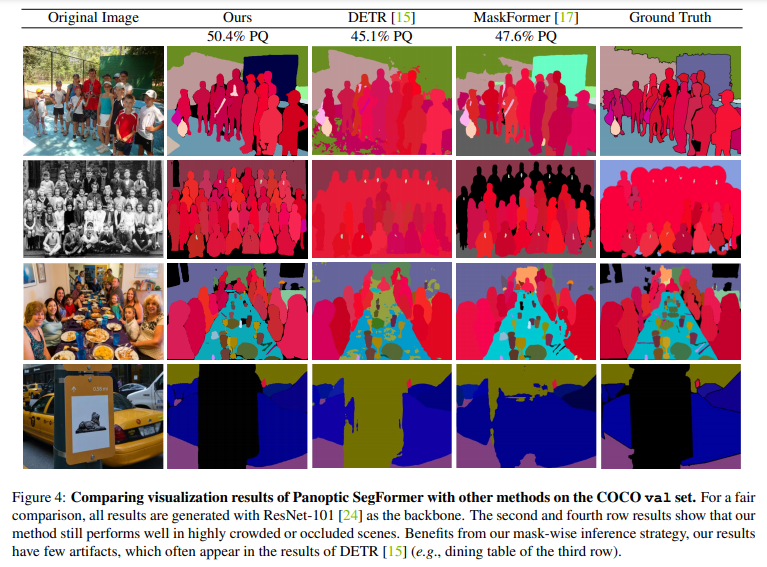
下圖 4 顯示了在 COCO val set 的一些可視化結果。這些原始圖像是高度擁擠或被遮擋的場景,但是 Panoptic SegFormer 仍然可以得到令人信服的結果。
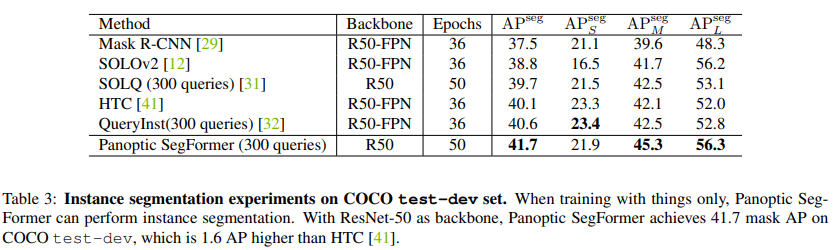
實例分割
:下表 3 爲在 COCO test-dev set
實例分割
結果。爲了公平比較,該研究使用 300 個
查詢
進行
實例分割
,並且只使用 things 數據。以 ResNet-50 作爲主幹和單尺度輸入,Panoptic SegFormer 實現了 41.7 AP,超過了之前的 HTC 和 QueryInst SOTA 方法,且分別超過了 1.6 AP 和 1.1 AP。
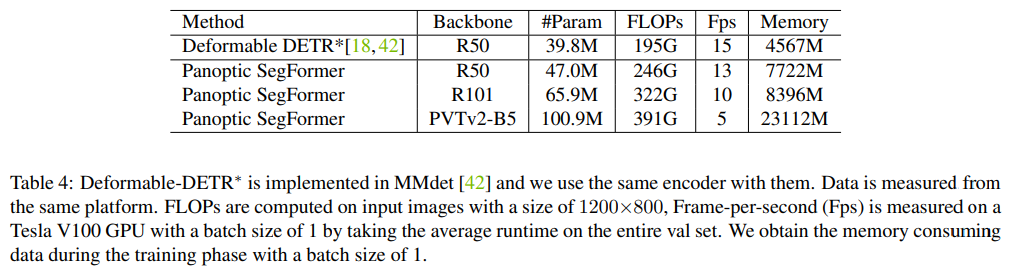
下表 4 中展示了模型複雜性和推理效率,得出 Panoptic SegFormer 在可接受的推理速度下,能夠實現 SOTA 性能全景分割。
文章來源:
機器之心
COPYRIGHT ©2020, BANGQU.COM |
Coupons