基於大模型的Agent會玩寶可夢了,人類水平的那種!
名為PokéLLMon,現在它正在天梯對戰中與人類玩家一較高下:

PokéLLMon能靈活調整策略,一旦發現攻擊無效,立刻改變行動:

PokéLLMon還會運用人類式的消耗戰術,頻繁給對方寶可夢下毒,並一邊恢復自身HP。

不過面對強敵,PokéLLMon也會「慌亂」逃避戰鬥,連續切換寶可夢:

最終對戰結果是,PokéLLMon在隨機天梯賽中取得49%的勝率,與專業玩家的邀請賽中取得56%的勝率,遊戲戰略和決策水平接近人類。
網友看到PokéLLMon的表現也很意外,直呼:
小心被任天堂封禁,這話是認真的。

甚至有網友喊話寶可夢大滿貫選手、世錦賽冠軍Wolfey Glick,來和這個AI一較高下:

這究竟是如何做到的?
PokéLLMon大戰人類
PokéLLMon由佐治亞理工學院研究團隊提出:

具體來說,他們提出了三個關鍵策略。
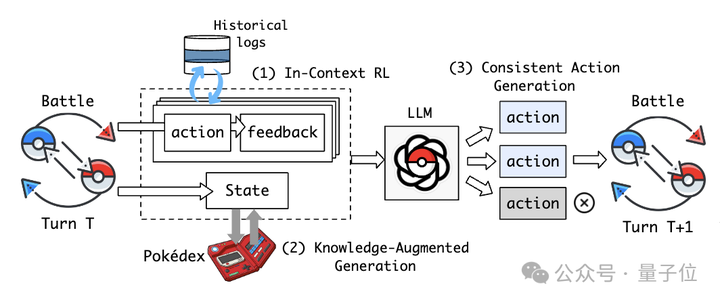
一是上下文強化學習(In-Context Reinforcement Learning)。
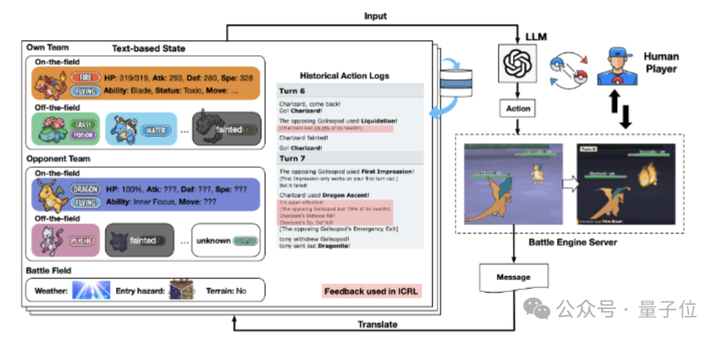
利用從對戰中即時獲得的文字反饋作為一種新的「獎勵」輸入,不需要訓練就可以線上迭代完善和調整PokéLLMon的決策生成策略。
其中反饋內容包括:回合HP變化、攻擊效果、速度優先順序、招式額外效果等。
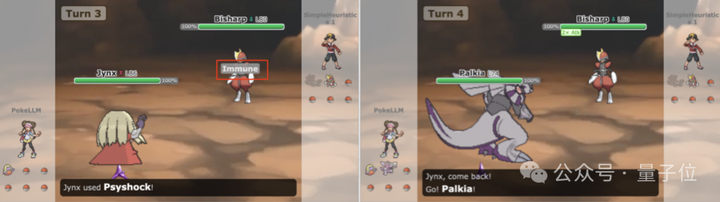
比如PokéLLMon反覆使用相同的攻擊招式,但由於對方寶可夢具有「乾燥面板」的能力,對其沒有任何效果。

在第三回閤中對戰中,通過即時上下文強化學習,PokéLLMon隨後選擇更換寶可夢。
二是知識增強生成(Knowledge-Augmented Generation)。
通過檢索外部知識源作為額外輸入,融入到狀態描述中。比如檢索型別關係、招式資料,模擬人類查詢寶可夢圖鑑,來減少未知知識導致的「幻覺」問題。
由此一來,PokéLLMon可以準確理解並應用招式效果。
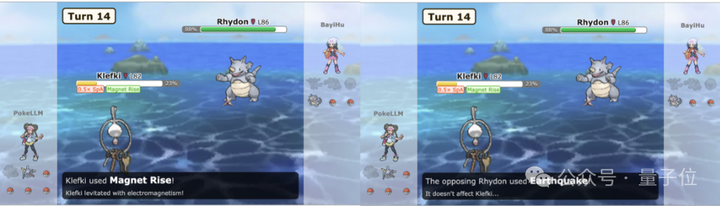
比如面對犀牛進化形態的地面攻擊,PokéLLMon未選擇更換寶可夢,而是施展「電磁飄浮」,該技能在五回合內成功抵禦地面攻擊,使犀牛的「地震」技能無效。
三是一致性動作生成(Consistent Action Generation)。
研究人員發現,當PokéLLMon面對強大對手時,思維鏈(CoT)的推理方式會導致它因「恐慌」而頻繁更換道具或寶可夢。
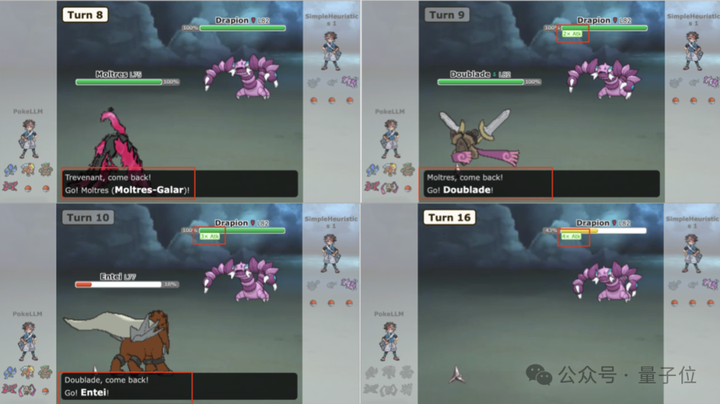
△PokéLLMon害怕,不斷切換寶可夢
而通過一致性動作生成,可以獨立多次生成行動,投票出最一致的,從而緩解「恐慌」。
值得一提的是,研究人員所用的模型自主和人類作戰的寶可夢對戰環境,基於Pokemon Showdown和poke-env實現,目前已開源。
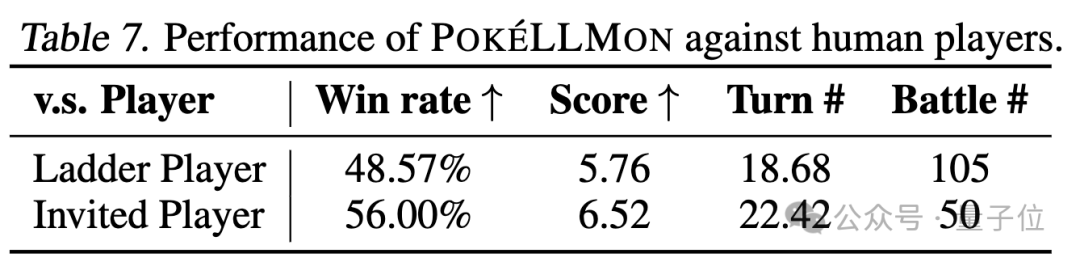
爲了測試PokéLLMon的對戰能力,研究人員用它分別與隨機天梯賽玩家和一名擁有15年經驗的專業玩家對戰。
結果,PokéLLMon與天梯隨機玩家的勝率為48.57%,與專業玩家的邀請對戰勝率為56%。
總的來說,PokéLLMon的優勢在於:能準確選擇有效招式,統一使用一個寶可夢擊倒全部對手;展現出類人的消耗戰略,使對手中毒後再拖延回血。
不過研究人員也指出了PokéLLMon的不足之處,面對玩家的消耗戰略(拖延回血)很難應對:

容易被玩家的迷惑戰術誤導(迅速切換寶可夢,巧妙使PokéLLMon浪費強化攻擊機會):

團隊簡介
三位作者均為華人學者。

論文一作胡思昊,現為佐治亞理工學院電腦科學博士生,本科畢業於浙江大學,曾在新加坡國立大學擔任研究助理。
研究興趣包括用於區塊鏈安全和推薦系統的資料探勘演算法及系統。

作者Tiansheng Huang,同爲佐治亞理工學院電腦科學博士生,華南理工大學校友。
研究興趣包括分散式機器學習、並行與分散式計算、優化演算法以及機器學習安全性。

導師劉玲,現為佐治亞理工學院計算機系教授。1982年畢業於中國人民大學,1993年於荷蘭蒂爾堡大學獲博士學位。
劉教授主導分散式資料密集系統實驗室(DiSL)的研究工作,專注於大資料系統及其分析的多個方面,如效能、安全和隱私等。
同時她也是IEEE Fellow,2012年獲得IEEE計算機學會技術成就獎,還曾擔任多個IEEE和ACM大會主席。
參考連結:
[1]https://twitter.com/_akhaliq/status/1754337188014100876
[2]https://poke-llm-on.github.io/
—完—
@量子位 · 追蹤AI技術和產品新動態