OpenAI突然釋出新模型!基於GPT-4訓練,可以幫助下一代GPT訓練。
CriticGPT,用於給程式碼挑Bug時能找到75%以上,而相比之下人類只能找到不到25%。
它還可以給Bug寫「銳評」,在60%的情況下人類訓練師更喜歡有CriticGPT幫助下的批評。
有網友開玩笑說,「只會批評的GPT,這不是我前妻麼」。

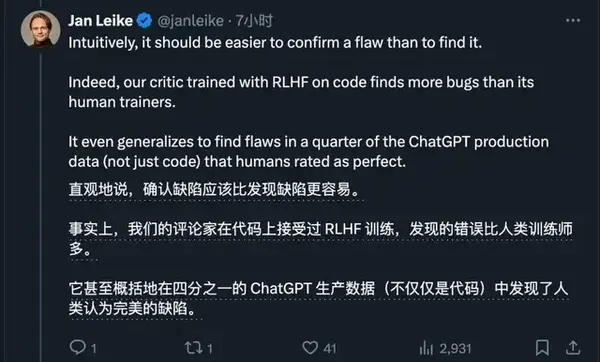
但這項研究最重要之處在於,CriticGPT挑錯能力可以泛化到程式碼之外。
比如在RLHF訓練中給AI的輸出挑錯,而且已經進入OpenAI內部訓練流程。

更好的RLHF就能訓練出更強的模型,更強的模型又能通過更好地挑錯來增強RLHF訓練……
論文結論中赫然寫道:在真實世界資料中挑錯誤上,AI還可以繼續進步,人類智慧已經到頭了。

左腳踩右腳上天,難道真的被這幫人給搞出來了

這是一篇來自被解散的超級對齊團隊的「遺作」,由前負責人Jan Leike帶隊。
而Leike本人已經跳槽去了隔壁Anthropic,繼續做這類研究。

基於GPT-4,改進GPT-4
OpenAI官網文章變相承認了,GPT-4之後這麼久沒有大的改進,還真的遇到一些瓶頸:
隨著AI能力變強,它犯的錯也不那麼顯眼了,人類訓練師都難以發現不準確之處。
人類給不出反饋,那RLHF「人類反饋強化學習」就無從談起了。

CriticGPT正是爲了應對這一挑戰而生。
CriticGPT基於GPT-4,也接受了RLHF訓練出,但特別之處在於訓練資料中包含大量的錯誤輸入。
具體來說,分為三步:
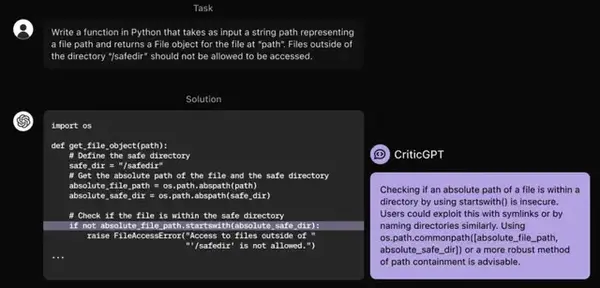
- 讓人類標註員在ChatGPT生成的程式碼裡故意植入一些微妙的bug。
- 標註員扮演程式碼審查員的角色,寫下他們對這些bug的評論。
- 用這些資料來訓練CriticGPT,讓它學會如何發現和指出程式碼中的問題。
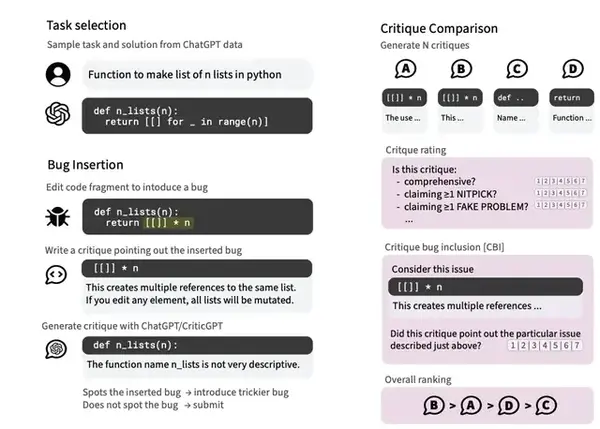
最後,OpenAI還使用了一種「強制取樣束搜尋」(FSBS)的技術,允許CriticGPT在生成評論時既能保持全面,又能減少」幻覺」和「雞蛋裏挑骨頭」現象。
具體來說,FSBS會強制模型生成多個不同的評論片段,用獎勵模型對這些片段進行評分,最後根據評分和一個長度修正因子來選擇最佳的評論組合。
通過調整長度修正因子,可以在評論的全面性和準確性之間找到最佳平衡點,既不會錯過重要問題,又不會過度挑剔。

等一下,推理時搜尋,這不正是和傳聞中的Q*一個思路,這次居然寫到了論文裡。
可能是看外部團隊(如顏水成)按這一思路的研究已經夠多了,就不再藏著掖著了

說回到CriticGPT,取得了哪些結果呢?
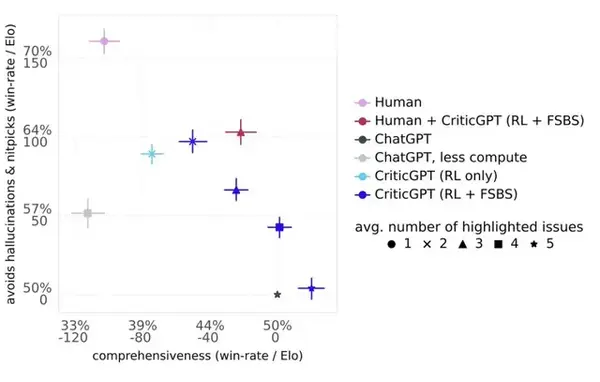
- 在發現人為插入的bug方面,人類稽覈員平均只能找到25%,而CriticGPT的成功率高達75%以上
- 在評估自然出現的Bug時,有63%的情況下人類更傾向於選擇CriticGPT的評論而非人類評論
- CriticGPT的評論被認為比ChatGPT的更全面,更少出現」幻覺」和無關緊要的挑剔
- 在評估非程式碼任務時,成功識別出數百個在ChatGPT訓練資料中被人類認為是」完美」的錯誤。
不過CriticGPT也不是十全十美,它也會有」幻覺」問題,指出一些實際上不存在的問題。
目前,人類和CriticGPT組隊工作效果最好:既能發現大部分問題,又能避免AI的」幻覺」。
RLHF上限不再是人類
對於CriticGPT,負責這項研究的Jan Leike也補充了他自己的一些看法。
RLHF是創造出ChatGPT的核心技術之一,但隱患在於人類能力就是RLHF的天花板。
當需要AI去解決人類無能為力的任務時,人類給不出相應反饋,AI也就無法改進了。
CriticGPT的成功,意味著超級對齊團隊設想中的可擴充套件監督,也就是用弱模型監督訓練更強的模型,終於有希望了。
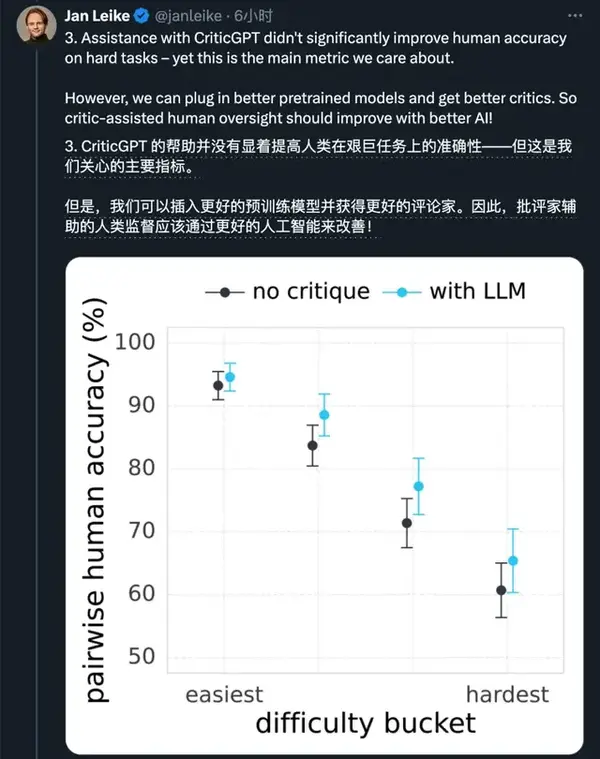
不過他也透露,目前CriticGPT並沒有幫助人類顯著提高艱難任務上的準確性,但是框架有了只要有更好的預訓練模型就能不斷改進。
為什麼先從程式碼任務開始入手呢?
一方面,程式碼任務有現實意義,做出來的模型可以直接用上。
另一方面,程式碼可以清晰明確的評估,比開放式對話更客觀,更容易評估CriticGPT發現的問題是否真實和重要。
結果CriticGPT在程式碼上訓練,卻不僅能挑程式碼Bug,還給1/4的ChatGPT生產資料挑出了問題。
最後,由於原OpenAI超級對齊團隊已經解散,已經跳槽的Jan Leike插入了一條Anthropic招聘廣告:
想做後續研究的請去隔壁。
也是讓人不得不感嘆硅谷是真的沒有競業協議。
One More Thing
同日,谷歌釋出了開源大模型Gemma 2,OpenAI趕緊甩出一條訊息來狙擊,這都第幾次了。

對於甩出來的不是Sora公測或者GPT-4o完整語音、視訊模式,也有很多人不滿。
有網友提了個更好的主意:
做個ReleaseGPT,專門用來發布承諾好的更新吧。
不過這次OpenAI久違的放出了論文,也還算有一些誠意。
論文地址:
https://cdn.openai.com/llm-critics-help-catch-llm-bugs-paper.pdf
參考連結:
[1]https://openai.com/index/finding-gpt4s-mistakes-with-gpt-4/
[2]https://x.com/janleike/status/1806386442568142995
—完—
@量子位 · 追蹤AI技術和產品新動態